【TCP/IP】TCP詳解筆記
- 2021 年 6 月 22 日
- 筆記
- /label/lzm, /lable/network, linux, TCP/IP, 嵌入式
前言
本筆記記錄 TCP/IP 中的 TCP 理論。包括三次握手、四次揮手、狀態變遷、慢啟動、快重傳等等。
《TCP/IP詳解》一共三卷,其中卷二、卷三更多偏重於編程細節,而卷一更多偏重於基礎原理。
後面再發佈個支持處理多線程並發及客戶端數量限制的TCP服務端+TCP客戶端例程。
原文://www.cnblogs.com/lizhuming/p/14916605.html
17. TCP 傳輸控制協議
17.1 引言
17.2 TCP 服務
TCP提供一種面向連接的、可靠的位元組流服務。
TCP通過下列方式來提供可靠性:
- 應用數據被分割成TCP認為最適合發送的數據塊。由 TCP傳遞給IP的信息單位稱為報文段或段(segment)。
- 當TCP發出一個段後,它啟動一個定時器,等待目的端確認收到這個報文段。如果不能及時收到一個確認,將重發這個報文段。
- 當TCP收到發自TCP連接另一端的數據,它將發送一個確認。這個確認不是立即發送,通常將推遲幾分之一秒。
- TCP將保持它首部和數據的檢驗和。這是一個端到端的檢驗和,目的是檢測數據在傳輸過程中的任何變化。如果收到段的檢驗和有差錯, TCP將丟棄這個報文段和不確認收到此報文段(希望發端超時並重發)。
- TCP報文段作為 IP 數據報來傳輸,而IP數據報的到達可能會失序,因此TCP報文段
的到達也可能會失序。如果必要,TCP將對收到的數據進行重新排序,將收到的數據以
正確的順序交給應用層。 - IP數據報會發生重複,TCP的接收端必須丟棄重複的數據。
- TCP還能提供流量控制。TCP連接的每一方都有固定大小的緩衝空間。 TCP的接收端只允許另一端發送 接收端緩衝區 所能接納的數據。(窗口)
位元組流服務(byte stream service):
- 兩個應用程序通過TCP連接交換8 bit位元組構成的位元組流。TCP不在位元組流中插入記錄標識符。
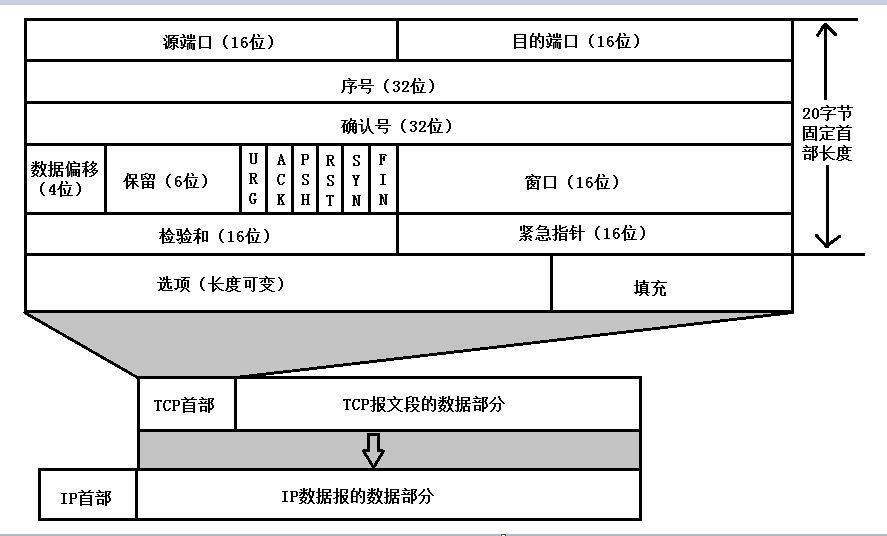
17.3 TCP的首部
視圖:
-
-
端口:每個TCP段都包含源端和目的端的端口號,用於尋找發端和收端應用進程。這兩個值加上IP首部中的源端IP地址和目的端IP地址唯一確定一個TCP連接。
- socket:包含客戶 IP 地址、客戶端口號、服務器 IP 地址和服務器端口號的四元組。
-
序號:用於對位元組流進行編號。
- 例如序號為 301,表示第一個位元組的編號為 301,如果攜帶的數據長度為 100 位元組,那麼下一個報文段的序號應為 401。
-
確認號:期望收到的下一個報文段的序號。
- 例如 B 正確收到 A 發送來的一個報文段,序號為 501,攜帶的數據長度為 200 位元組,因此 B 期望下一個報文段的序號為 701,B 發送給 A的確認報文段中確認號就為 701。
-
數據偏移:指的是數據部分距離報文段起始處的偏移量,實際上指的是首部的長度。
-
URG:緊急(The urgent pointer) 標誌置位。只有當 URG 標誌置1時緊急指針才有效。
-
ACK:確認標誌。當 ACK=1 時確認號字段有效,否則無效。
- TCP 規定,在連接建立後所有傳送的報文段都必須把 ACK 置 1。
-
PSH:推標誌。該標誌置位時,接收端不將該數據進行隊列處理,而是儘可能快將數據轉由應用處理。
- 在處理 telnet 或 rlogin 等交互模式的連接時,該標誌總是置位的。
-
RST:複位標誌。複位標誌有效,重建連接。
-
SYN:同步標誌。同步序列編號(Synchronize Sequence Numbers)欄有效。
- 在連接建立時用來同步序號。當 SYN=1,ACK=0 時表示這是一個連接請求報文段。若對方同意建立連接,則響應報文中 SYN=1,ACK=1。
-
FIN:結束標誌。用來釋放一個連接,當 FIN=1 時,表示此報文段的發送方的數據已發送完畢,並要求釋放運輸連接。
-
窗口:窗口值作為接收方讓發送方設置其發送窗口的依據。流量控制。
-
校驗和:檢驗和覆蓋了整個的TCP報文段:TCP首部和TCP數據。這是一個強制性的字段,一定是由發端計算和存儲,並由收端進行驗證。
-
緊急指針:緊急指針是一個正的偏移量,和序號字段中的值相加表示緊急數據最後一個位元組的序號。
- TCP的緊急方式是發送端向另一端發送緊急數據的一種方式。
- 只有當 URG 標誌置1時緊急指針才有效。
-
選項:長度可變,最長可達40位元組。當沒有使用「選項」時,TCP的首部長度是20位元組。最後的填充字段僅僅是為了使整個TCP首部長度是4位元組的整數倍。

18. TCP連接的建立與終止
18.1 引言
18.2 連接的建立與終止
18.2.1 建立連接
三次握手建立連接
-
參考圖:
-
建立連接的過程是由客戶端發起,服務端等待客戶請求
-
第一步:客戶端向服務器端發送一個SYN報文段(只有首部,且SYN被置 1),初始序號(ISN)隨機選擇,假設為num_a,ACK 置 0。(客戶端進入SYN_SEND狀態)
-
第二步:服務器端收到 SYN報文段,便知道客戶端需要請求握手,從 SYN報文段 中提取對應的信息,為該 TCP 連接分配 TCP 緩存和變量,並向該客戶 TCP 發送允許連接的報文段(握手應答報文)。這個報文段只有首部,包含3個重要的信息:(建立客戶端–>服務端的連接)(服務器進入SYN_RECV狀態)
- SYN與ACK標誌位1
- 將TCP報文段首部的確認序號字段設置為 num_a+1(這個num_a(ISN)是從握手請求報文中得到)。
- 服務器隨機選擇自己的初始序號(ISN,注意此ISN是服務器端的ISN,假設為num_b),並將其放置到TCP報文段首部的序號字段中。
-
第三步:客戶端接收到服務器端的握手應答後,會將 SYN 置 0,ACK 置 1,確認序號置為 num_b+1, 設置窗口值,可以添加數據域的報文段發給服務器端。同時給該TCP連接分配緩存和變量。(建立服務端–>客戶端的連接)(客戶端和服務器端都進入ESTABLISHED狀態)

18.2.2 終止連接
四次揮手終止連接
-
參考圖
-
第一步:主機A發出 FIN報文段(首部FIN被置 1),序號假設為 num_c,ACK 被置 1,但是確認序號是無效的。(主機A進入FIN_WAIT_1狀態)(主機B進入CLOSE_WAIT狀態)
-
第二步:當主機B收到 FIN報文段,它返回一個 ACK報文段(終止連接應答),確認序號為 num_c+1。此時斷開客戶端–>服務器端的方向。(主機A進入FIN_WAIT_2狀態)
-
第三步:主機B發出 FIN報文段 向主機A請求終止連接,此時序號為 num_d,ACK 被置 1,但是確認序號是無效的。(主機B進入LAST_ACK狀態)
-
第四步:當主機A收到FIN報文段,它返回一個ACK報文段(終止連接應答),確認序號為 num_d+1。此時斷開服務器端–>客戶端的連接。(主機A進入TIME_WAIT狀態)(主機B進入CLOSE狀態)

18.2.3 TCP 連接狀態變遷圖
視圖:

18.3 連接建立超時
18.4 最大報文段長度
最大報文段長度(MSS)表示TCP傳往另一端的最大塊數據的長度。當一個連接建立時,連接的雙方都要通告各自的 MSS。
我們已經見過MSS都是1024。這導致 IP 數據報通常是4 0位元組長:2 0位元組的TCP首部和2 0位元組的 IP 首部。
使用IEEE 802.3的封裝,它的MSS可達 1452 位元組。
18.5 TCP 半關閉
TCP 是全雙工的。主要斷開一線的連接,剩下一線還可以正常工作。如A只能發,B只能收。
為了使用這個特性,編程接口必須為應用程序提供一種方式來說明:
- 我已經完成了數據傳送,因此發送一個文件結束(FIN)給另一端,但我還想接收另一端發來的數據,直到它給我發來文件結束(FIN)。
18.6 TCP 狀態變遷圖
視圖:

18.6.1 2MSL 等待狀態
MSL:報文段最大生存時間,它是任何報文段被丟棄前在網絡內的最長時間。
等待 2MSL 原因:
- 保證 TCP 協議的全雙工連接能夠可靠關閉。
- 如果 B 端沒有收到 ACK ,觸發超時重發 FIN報文段,A 端依然能處理重發 ACK。如果 A 端直接 CLOSE 狀態,就不能保證 B 端收到 ACK。
- 保證這次連接的重複數據段從網絡中消失。
- 保證下次連接收到的數據報文段都是來自新連接的目標端。
18.6.2 平靜時間的概念
平靜時間(quiet time):TCP在重啟動後的 MSL 秒內不能建立任何連接。
- 防止重啟前的報文段被認為新的報文。所以要保證重啟前的報文在網絡中消失才能重啟。
18.6.3 FIN_WAIT_2 狀態
在揮手斷開連接過程中,如果 B端(第三次揮手)不發出 FIN報文段 將會導致 A端 一直處於 FIN_WAIT_2 狀態。而 B端 一直處於 CLOSE_WAIT 狀態。
直至應用層決定關閉進行關閉才能跳出該狀態。
可以設立定時器維護這個狀態,但是必須在代碼中註明此做法是違背協議的規範。
18.7 複位報文段
TCP首部中的 RST比特 是用於「複位」的。
18.7.1 到不存在的端口的連接請求
產生複位的一種常見情況是當連接請求到達時,目的端口沒有進程正在聽。
- 對於 UDP,當一個數據報到達目的端口時,該端口沒在使用,它將產生一個ICMP端口不可達的信息。
- 而TCP則使用複位。
18.7.2 異常終止一個連接
正常的終止連接請求是發送 FIN報文段。
但是直接發送 RST複位報文段 也可以終止連接。稱為 異常終止。
異常終止一個連接對應用程序來說有兩個優點:
- 丟棄任何待發數據並立即發送複位報文段;
- RST的接收方會區分另一端執行的是異常關閉還是正常關閉。
18.7.3 檢測半邊打開連接
半打開(Half-Open):一方已經關閉或異常終止連接而另一方卻還不知道的TCP連接。
當異常的一方回復正常且繼續收到來自另一方的數據(另一方並不知道這邊的情況),這時接收方無法辨認接受的數據是什麼,於是發送 RST複位報文段 作為應答。
tip:另一種檢測方法:
- 可以採用 keepalive 功能。(在23章-TCP的保活定時器 中說明)
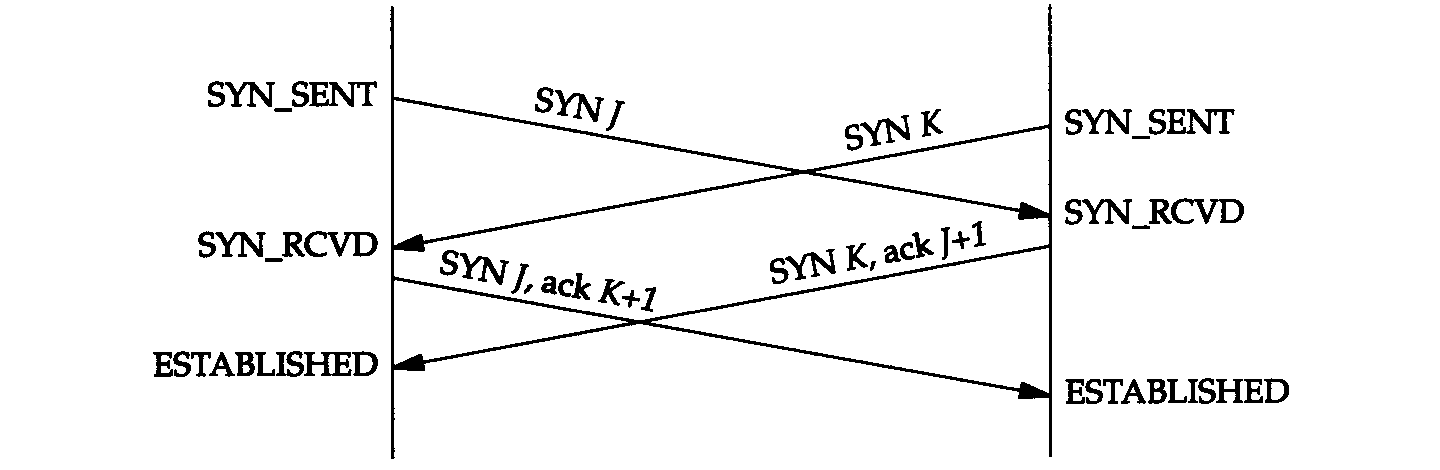
18.8 同時打開
同時打開(simultaneous open):每一方必須發送一個SYN,且這些SYN必須傳遞給對方。
TCP是特意設計為了可以處理同時打開,對於同時打開它僅建立一條連接而不是兩條連接。
(其他的協議族,最突出的是OSI運輸層,在這種情況下將建立兩條連接而不是一條連接)
- 兩端幾乎在同時發送 SYN,並進入SYN_SENT狀態。當每一端收到SYN時,狀態變為SYN_RCVD,同時它們都再發SYN並對收到的SYN進行確認。當雙方都收到SYN及相應的ACK時,狀態都變遷為ESTABLISHED。

18.9 同時關閉

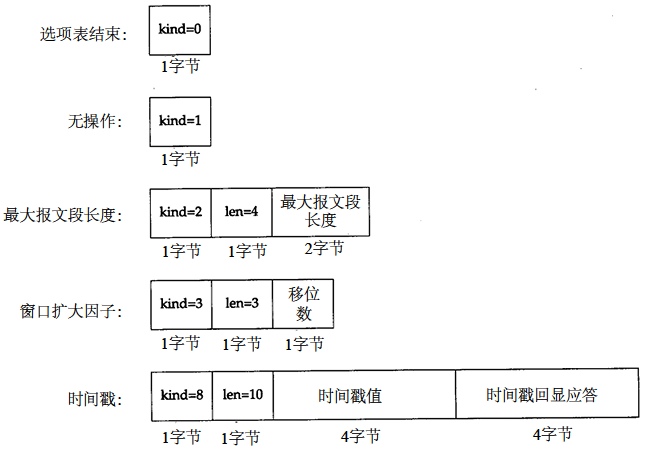
18.10 TCP 選項
當前 TCP 選項格式:
-
-
每個選項的開始是1位元組k i n d字段,說明選項的類型。

18.11 TCP 服務器的設計
大多數的TCP服務器進程是並發的。當一個新的連接請求到達服務器時,一般會用一個新的進程或線程處理新客戶請求。(不同的操作系統有不同的處理方案)
TCP服務器忙時處理連接請求規則:
- 服務端維護一個固定長度的連接隊列。該隊列維護着已經三次握手完成,但是還沒有被應用層接受的連接。
- 注意: 區分TCP接受一個連接是將其放入這個隊列,而應用層接受連接是將其從該隊列中移出。
- 應用層將指明該隊列的最大長度,這個值通常稱為積壓值 ( backlog)。
- 當一個連接請求(即SYN)到達時,TCP使用一個算法,根據當前連接隊列中的連接數來確定是否接收這個連接。
- 如果對於新的連接請求,該 TCP 監聽的端點的連接隊列中還有空間,TCP 模塊將對SYN進行確認並完成連接的建立。但應用層只有在三次握手中的第三個報文段收到後才會知道這個新連接時。另外,當客戶進程的主動打開成功但服務器的應用層還不知道這個新的連接時,它可能會認為服務器進程已經準備好接收數據了(如果發生這種情況,服務器的TCP僅將接收的數據放入緩衝隊列)。
- 如果對於新的連接請求,連接隊列中已沒有空間,TCP將不理會收到的SYN。也不發回任何報文段(即不發回RST)。如果應用層不能及時接受已被 TCP 接受的連接,這些連接可能佔滿整個連接隊列,客戶的主動打開最終將超時。
19. TCP 的交互數據流
19.1 引言
建立在TCP協議上的應用層協議有非常多,如FTP、HTTP、Telnet、Rlogin等。這些協議依據數據傳輸的多少能夠分為兩類:
- 交互數據類型:如 Telnet,這類協議一般僅僅做小流量的數據交換,比方每按下一個鍵,要回顯一些字符。
- 成塊數據類型:如 FTP,這類協議須要傳輸的數據比較多,一般傳輸的數據量比較大。
19.2 交互式輸入
視圖:

一個回顯鍵入會產生4個報文段:(也可以把②和③合併)
- 客戶發出的按鍵數據報文段。
- 服務器發出的按鍵確認報文段。
- 服務器發出的回顯數據報文段。
- 客戶發出的回顯確認報文段。
19.3 經受時延的確認
通常 TCP 在接收到數據時並不立即發送 ACK;它推遲發送,以便將 ACK 與需要沿該方向發送的數據一起發送(有時稱這種現象為數據捎帶 ACK)。
絕大多數實現採用的時延為200 ms,也就是說,TCP 將以最大 200 ms的時延等待是否有數據一起發送。
19.4Nagle 算法
在上面描述的 Rlogin 回顯中,一個字符就回顯一次,其中產生的分組為 41位元組的分組:20位元組IP首部 + 20位元組TCP首部 + 1位元組的數據。
若把這些小分組放到廣域網上,會增加擁塞。
Nagle 算法就是解決上面的情況。
Nagle:
- 該算法要求一個 TCP 連接上最多只能有一個未被確認的未完成的小分組。在該分組的確認到達之前不能發送其他的小分組。
- TCP 收集這些少量的分組,並在確認到來時以一個分組的方式發出去。
- Nagle 優點是自適應:確認到達得越快,數據也就發送得越快。
19.4.1 關閉 Nagle 算法
插口API用戶可以使用 TCP_NODELAY 選項來關閉Nagle算法。
19.5 窗口大小通告
20. TCP的成塊數據流
20.1 引言
主要涉及:
- 滑動窗口-流量控制
- 慢啟動
20.2 正常數據流
20.3 滑動窗口
利用滑動窗口實現流量控制。
視圖:
-
-
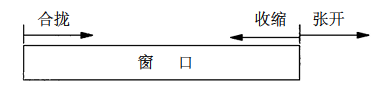
窗口兩個邊沿的相對運動增加或減少了窗口的大小。
- 稱窗口左邊沿向右邊沿靠近為窗口合攏。這種現象發生在數據被發送和確認時。
- 當窗口右邊沿向右移動時將允許發送更多的數據,我們稱之為窗口張開。這種現象發生在另一端的接收進程讀取已經確認的數據並釋放了 TCP 的接收緩存時。
- 當右邊沿向左移動時,我們稱之為窗口收縮。
-
注意,窗口只是說明接收方當前能接收的最大容量而已,發送方不必一次性發滿整個窗口大小。

20.4 窗口大小
由接收方提供的窗口的大小通常可以由接收進程控制,這將影響 TCP 的性能。
插口API允許進程設置發送和接收緩存的大小。
接收緩存的大小是該連接上所能夠通告的最大窗口大小。
應用程序可以通過修改插口緩存大小來增加性能。
20.5 PUSH 標誌
發送方使用 PUSH標誌 通知接收方將所收到的數據全部提交給接收進程。
這裡的數據包括與 PUSH 一起傳送的數據以及接收方 TCP 已經為接收進程收到的其他數據。
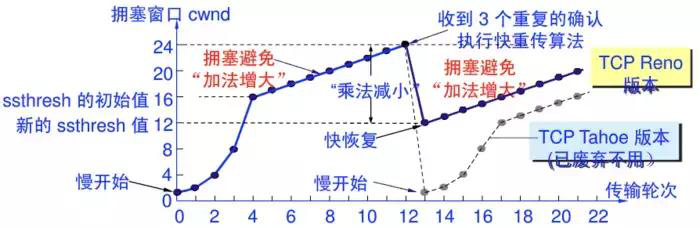
20.6 慢啟動
慢開始算法處理屬於 TCP擁塞控制。
當主機開始發送數據時,如果立即所大量數據位元組注入到網絡,那麼就有可能引起網絡擁塞,因為現在並不清楚網絡的負荷情況。所以,較好的方法是 先探測一下,即由小到大逐漸增大發送窗口。
慢開始和擁塞避免:
- 發送方維持一個擁塞窗口 cwnd ( congestion window )的狀態變量。
- 擁塞窗口的大小取決於網絡的擁塞程度,並且動態地在變化。
- 發送方讓自己的發送窗口等於擁塞窗口。
- 發送方控制擁塞窗口的原則是:
- 只要網絡沒有出現擁塞,擁塞窗口就再增大一些,以便把更多的分組發送出去。
- 但只要網絡出現擁塞,擁塞窗口就減小一些,以減少注入到網絡中的分組數。
慢開始算法:
- 通常在剛剛開始發送報文段時,先把擁塞窗口 cwnd 設置為一個最大報文段MSS的數值。
- 在每收到一個對新的報文段的確認後,把擁塞窗口增加至多一個MSS的數值。
- 用這樣的方法逐步增大發送方的擁塞窗口 cwnd ,可以使分組注入到網絡的速率更加合理。
- 為了防止擁塞窗口cwnd增長過大引起網絡擁塞,還需要設置一個慢開始門限 ssthresh 狀態變量。
- 當 cwnd < ssthresh 時,使用上述的慢開始算法。
- 當 cwnd = ssthresh 時,既可使用慢開始算法,也可使用擁塞控制避免算法。
- 當 cwnd > ssthresh 時,停止使用慢開始算法而改用擁塞避免算法。
擁塞避免:
- 讓擁塞窗口cwnd緩慢地增大,即每經過一個往返時間RTT就把發送方的擁塞窗口cwnd加1,而不是加倍。
注意:
- 符合以下條件之一即可使用 擁塞避免 ,不一定要達到 ssthresh 值。
- 當 cwnd > ssthresh 時。
- 發送方判斷網絡出現擁塞(其根據就是沒有收到確認)。

20.7 成塊數據的吞吐量
20.7.1 帶寬時延乘積
帶寬時延乘積:capacity(bit) = bandwidth (b/s) × round-trip time ( s )。
- 這個值依賴於 網絡速度 和 兩端的 RTT。
20.7.2 擁塞
部分擁塞情景:
- 當數據到達一個大的管道(如一個快速局域網)並向一個較小的管道(如一個較慢的廣域網)發送時便會發生擁塞。
- 當多個輸入流到達一個路由器,而路由器的輸出流小於這些輸入流的總和時也會發生擁塞。
20.8 緊急方式
TCP提供了 緊急方式 ( u rgent mode),它使一端可以告訴另一端有些具有某種方式的 緊急數據 已經放置在普通的數據流中。
另一端被通知這個緊急數據已被放置在普通數據流中,由接收方決定如何處理。
URG比特 被置 1,並且一個 16bit 的緊急指針 被置為一個正的偏移量,該偏移量必須與 TCP 首部中的序號字段相加,以便得出緊急數據的最後一個位元組的序號。
緊急方式的作用:
- 兩個最常見的例子是 Telnet 和 Rlogin。當交互用戶鍵入中斷鍵時。(參考 卷一26 章)
- 另一個例子是 FTP,當交互用戶放棄一個文件的傳輸時。(參考 卷一27 章)
21. TCP的超時與重傳
21.1 引言
對每個連接,TCP管理4個不同的定時器:
- 重傳定時器使用於當希望收到另一端的確認。功能如擁塞避免。
- 堅持( persist )定時器使窗口大小信息保持不斷流動,即使另一端關閉了其接收窗口。
- 保活( keepalive )定時器可檢測到一個空閑連接的另一端何時崩潰或重啟。
- 2MSL定時器測量一個連接處於TIME_WAIT狀態的時間。
21.2 超時與重傳的簡單例子
21.3 往返時間測量
TCP 超時與重傳中最重要的部分就是對一個給定連接的往返時間(RTT)的測量。
由於路由器和網絡流量均會變化,因此我們認為這個時間可能經常會發生變化,TCP 應該跟蹤這些變化並相應地改變其超時時間。
首先 TCP 必須測量在發送一個帶有特別序號的位元組和接收到包含該位元組的確認之間的 RTT。
用 M 表示所測量到的 RTT。
計算:new_RTTS = (1-α)x(old_RTTS) + αx(new_RTT)
- α:值推薦為 1/8 的平滑因子。
- new_RTTS:新的平滑往返時間。
- old_RTTS:舊的平滑往返時間。
- new_RTT:測量到的 RTT。
- 每個新估計的90%來自前一個估計,而10%則取自新的測量。
計算:RTO = RTTS+4x(RTTD)
- RTO:重傳超時時間。
- RTTD:是RTT的偏差加權的平均值,與 RTTS 和新得到的 RTT 樣本之差有關。
- 第一次測量到 RTT 樣本時,RTTS 的取值就為測量的 RTT 樣本值。
計算:new_RTTD = (1-β)x(lod_RTTD) + βx(new_RTT)
- β:推薦值為 1/4。
- 第一次測量 RTTD 時,RTTD 的取值為 RTT 樣本值的一半。
如上所述就是測量 RTO 公式和參數。
但是仍然有一個問題需要確定,在計算加權平均 RTTS 時,只要數據包重傳沒有使用往返時間,就可以得出 RTTS 和 RTO 是準確的。
當之後出現超重時,新 RTO 是 old_RTO 的2倍。
21.4 往返時間RTT的例子
21.5 擁塞舉例
21.6 擁塞避免算法
擁塞避免算法是一種處理丟失分組的方法。
擁塞避免算法和慢啟動算法需要對每個連接維持兩個變量:一個擁塞窗口 cwnd 和一個慢 啟動門限 ssthresh。
符合以下條件之一即可使用 擁塞避免 ,不一定要達到 ssthresh 值。
- 當 cwnd > ssthresh 時。
- 發送方判斷網絡出現擁塞(其根據就是沒有收到確認)。
21.7 快速重傳與快速恢復算法
快重傳:
快重傳算法:
- 首先要求接收方每收到一個失序的報文段後就立即發出重複確認(為的是使發送方及早知道有報文段沒有到達對方)而不要等到自己發送數據時才進行捎帶確認。
- 快重傳算法還規定,發送方只要一連收到三個重複確認就應當立即重傳對方尚未收到的報文段,而不必繼續等待M3設置的重傳計時器到期。
快恢復:
快恢復有兩個要點:
-
當發送方連續收到三個重複確認,就執行乘法減小算法,把慢開始門限 ssthresh 減半。
-
把 cwnd 值設置為 慢開始門限 ssthresh 減半後的數值,然後開始執行擁塞避免算法(加法增大),使擁塞窗口緩慢地線性增大。(而不是重新執行慢開始算法)
-

21.8 擁塞舉例(續)
21.9 按每條路由進行度量
如今較新的TCP實現的路由表項中維持了很多指標,當一個TCP連接關閉時,假設已經發出了足夠多的數據來獲得有意義的統計資料。
且目的節點的路由表項不是一個默認表項。
那麼下列信息就保存在在路由表項中以備下次使用:
- 被平滑的RTT
- 被平滑的均值偏差
- 慢啟動門限
足夠多的數據:是指 16 個窗口的數據。
21.10 ICMP的差錯
TCP 能夠遇到的最常見的 ICMP 差錯就是:
- 源站抑制
- 主機不可達
- 網絡不可達
處理:
- 一個接收到的源站抑制引起擁塞窗口 cwnd 被置為1個報文段大小來發起慢啟動,但是慢 啟動門限 ssthresh 沒有變化,所以窗口將打開直至它或者開放了所有的通路(受窗口大小和往返時間的限制)或者發生了擁塞。
- 一個接收到的主機不可達或網絡不可達實際上都被忽略,因為這兩個差錯都被認為是短暫現象。這有可能是由於中間路由器被關閉而導致選路協議要花數分鐘才能穩定到另一個替換路由。
- 在這個過程中就可能發生這兩個ICMP差錯中的一個,但是連接並不必被關閉。相反,TCP試圖發送引起該差錯的數據,儘管最終有可能會超時。
21.11 重新分組
當TCP超時並重傳時,它不一定要重傳同樣的報文段。
相反,TCP允許進行重新分組而發送一個較大的報文段,這將有助於提高性能( 接收方聲明的MSS)。
在協議中這是允許的,因為TCP是使用位元組序號而不是報文段序號來進行識別它所要發送的數據和確認。
TCP數據長度:
**TCP數據長度 = IP包總長度(IP首部里)- IP首部長度(IP首部里)- TCP首部長度 **
22. TCP 的堅持定時器
22.1 引言
如果接收方發送一個大小為 0 的窗口到發送方,那發送方就停止發送數據,直至窗口為非 0。
TCP 不對 ACK 報文段進行確認,只確認那些包含有數據的 ACK 報文段。
22.2 例子&解決
bug情景:如果一個確認丟失了,則雙方就有可能因為等待對方而使連接終止:
- 接受方等待接收數據
- (因為它已經向發送方通告了一個非0的窗口,但是丟失了,且接收方是不對這個報文段進行確認的)
- 而發送方在等待允許它繼續發送數據的窗口更新。
解決:為防止這種死鎖情況發生,發送方使用了一個堅持定時器(persist timer)來周期性地向接收方查詢,以便發現窗口是否已增大,範圍在5~60 s之間。這些從發送方發出的報文段稱為窗口探查(window probe)。
22.3 糊塗窗口綜合症
糊塗窗口綜合症SWS(Silly Window Syndrome):
- 發生在兩端中的任何一端。
- 接收方可以通告一個小的窗口(而不是一直等到有大的窗口時才通告)。
- 而發送方也可以發送少量的數據(而不是等待其他的數據以便發送一個大的報文段)。
可以在任何一端採取措施避免出現糊塗窗口綜合症的現象:
- 接收方不通告小窗口。通常的算法是接收方不通告一個比當前窗口大的窗口(可以為0),除非窗口可以增加一個報文段大小(也就是將要接收的MSS)或可以增加接收方緩存空間的一半,不論實際有多少。
- 發送方避免出現糊塗窗口綜合症的措施是只有以下條件之一滿足時才發送數據:
- 可以發送一個滿長度的報文段。
- 可以發送至少是接收方通告窗口大小一半的報文段。
- 可以發送任何數據並且不希望接收ACK(也就是沒有還未被確認的數據)或該連接上不能使用 Nagle 算法。
- 該條件使在有尚未被確認的數據(正在等待被確認)以及在不能使用Nagle算法的情況下,避免發送小的報文段。
- 例如如果應用程序在進程小數據的寫操作(例如比該報文段還小),該條件就可以避免出現糊塗窗口綜合症。
23. TCP 的保活定時器
情景:啟動一個客戶與服務器建立一個連接,然後離去數小時、數天、數個星期或數月,而連接依然保持。中間路由器可以崩潰和重啟,電話線可以被掛斷再連通,但是只有兩端的主機沒有被重啟,則連接依然保持建立。這種非活動狀態可以導致應用進程中的任何一個終止其活動。
許多時候一個服務器希望知道客戶主機是否崩潰並關機或者崩潰又重新啟動。許多實現提供的保活定時器可以提供這種能力。
保活並不是 TCP 規範中的一部分。Host Requirements RFC提供了3個不使用保活定時器的理由:
- 在出現短暫差錯的情況下,這可能會使一個非常好的連接釋放掉;
- 它們耗費不必要的帶寬;
- 在按分組計費的情況下會在互聯網上花掉更多的錢。
如果一個給定的連接在2個小時之內沒有任何動作,則服務器向客戶發送一個探查報文段。客戶主機必須處於以下4個狀態之一:
- 客戶主機仍然正常運行,並從服務器可達。客戶的TCP響應正常,而服務器也知道對方是正常工作的。服務器在2個小時以後將保活定時器複位。如果在2個小時定時器到時間之前應用程序的通信量通過此連接,則定時器在交換數據後的未來2個小時再複位。
- 客戶主機已經崩潰,並且關閉或者正在重新啟動。在任何一種情況下,客戶的TCP都沒有響應。服務器將不能夠收到探查的響應,並在75s後超時。服務器總共發送10個這樣的探查,每個間隔75秒。如果服務器沒有收到一個響應,它就認為客戶主機已經關閉並終止連接。
- 客戶主機崩潰並已經重新啟動。這時服務器將收到一個對其保活探查的響應,但是這個響應是一個複位,使得服務器終止這個連接。
- 客戶主機正常運行,但是從服務器不可達。這與狀態2相同,因為TCP不能夠區分狀態4與狀態2之間的區別,它所能發現的就是沒有接收到探查的響應。
在這2、3、4情況下,服務器application將收到來自它的TCP的差錯報告(通常服務器已經向網絡發出了讀操作請求,然後等待來自客戶的數據。如果保活功能返回一個差錯,則該差錯將作為讀操作的返回值給服務器)。其差錯對應如下:
| 客戶主機已經崩潰,並且關閉或者正在重新啟動 | 類似 連接超時 |
| 客戶主機崩潰並已經重新啟動 | 類似 連接被對方複位 |
| 客戶主機正常運行,但是從服務器不可達 | 類似 連接超時 |
24. TCP 的未來和性能
有興趣可看原文
參考
鏈接: