構建企業級數據湖?Azure Data Lake Storage Gen2實戰體驗(中)
- 2019 年 10 月 3 日
- 筆記
引言
相較傳統的重量級OLAP數據倉庫,“數據湖”以其數據體量大、綜合成本低、支持非結構化數據、查詢靈活多變等特點,受到越來越多企業的青睞,逐漸成為了現代數據平台的核心和架構範式。
因此數據湖相關服務成為了雲計算的發展重點之一。Azure平台早年就曾發佈第一代Data Lake Storage,隨後微軟將它與Azure Storage進行了大力整合,於今年初正式對外發佈了其第二代產品:Azure Data Lake Storage Gen2 (下稱ADLS Gen2)。ADLS Gen2的口號是“不妥協的數據湖平台,它結合了豐富的高級數據湖解決方案功能集以及 Azure Blob 存儲的經濟性、全球規模和企業級安全性”。
全新一代的ADLS Gen2實際體驗如何?在架構及特性上是否堪任大型數據湖應用的主存儲呢?在上篇文章中,我們已對ADLS Gen2的基本操作和權限體系有了初步的了解。接下來讓我們繼續深入探究,尤其是關注ADLS Gen2作為存儲層掛載到大數據集群後的表現。
ADLS Gen2體驗:集群掛載
數據湖存儲主要適用於大數據處理的場景,所以我們選擇建立一個HDInsight大數據集群來進行實驗,使用Spark來訪問和操作數據湖中的數據。可以看到HDInsight已經支持ADLS Gen2了:
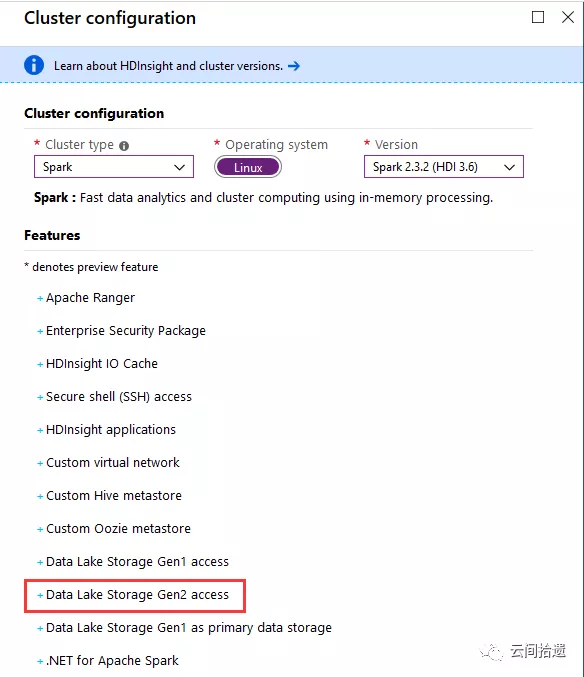

接下來是比較關鍵的存儲配置環節,我們指定使用一個新建的ADLS Gen2實例hdiclusterroot來作為整個集群的存儲,文件系統名為hdfs-root,如圖所示:
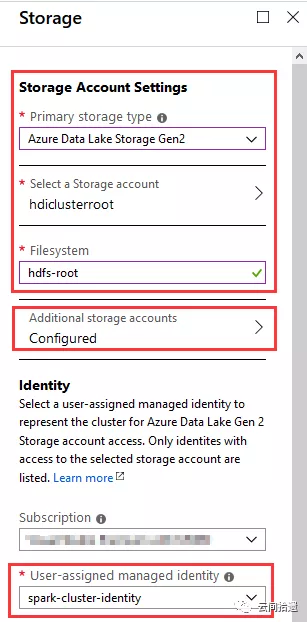

(圖中我們還配置了Additional storage accounts,用於掛載傳統Blob,之後作性能對比時會用到。此處暫不展開。)
很有意思的是上圖的下半部分,它允許我們指定一個Identity,這個Identity可以代表Spark集群的身份和訪問權限。這非常關鍵,意味着集群的身份能夠完美地與ADLS Gen2的權限體系對應起來,在企業級的場景中能夠很好地落地對於大數據資源訪問的管控。
這裡選擇了專門建立的一個spark-cluster-identity作為集群的身份。我們事先為它賦予了hdiclusterroot這個存儲賬號的storage blob data owner權限,以便該identity能夠對數據湖中的數據進行任意操作:
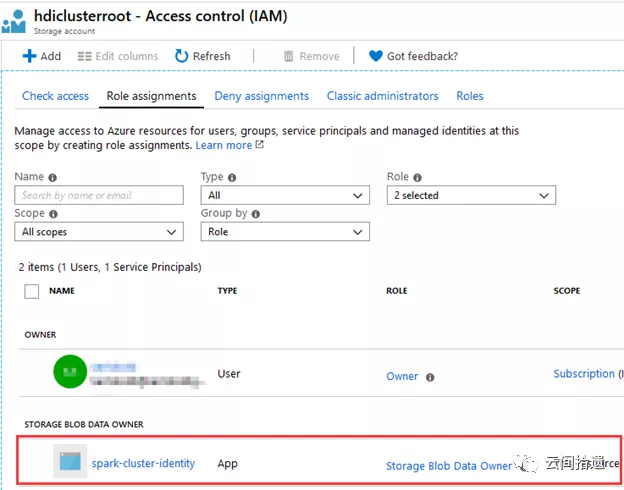

完成其他配置後按下創建按鈕,Azure會一鍵生成Spark集群,大約十來分鐘後整個集群就進入可用狀態了:


我們迫不及待地SSH登錄進集群,查看其默認掛載的文件系統。嘗試使用hadoop fs -ls列出根目錄下的文件信息:
sshuser@hn0-cloudp:~$ hadoop fs -ls / Found 18 items drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:10 /HdiNotebooks drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:29 /HdiSamples drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /ams drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /amshbase drwxrwx-wt - sshuser sshuser 0 2019-08-26 02:54 /app-logs drwxr-x--- - sshuser sshuser 0 2019-09-06 07:41 /apps drwxr-x--x - sshuser sshuser 0 2019-08-26 02:54 /atshistory drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:25 /custom-scriptaction-logs drwxr-xr-x - sshuser sshuser 0 2019-08-26 03:19 /example drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /hbase drwxr-x--x - sshuser sshuser 0 2019-09-06 07:41 /hdp drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /hive drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /mapred drwxrwx-wt - sshuser sshuser 0 2019-08-26 03:19 /mapreducestaging drwxrwx-wt - sshuser sshuser 0 2019-08-26 02:54 /mr-history drwxrwx-wt - sshuser sshuser 0 2019-08-26 03:19 /tezstaging drwxr-x--- - sshuser sshuser 0 2019-08-26 02:54 /tmp drwxrwx-wt - sshuser sshuser 0 2019-09-09 02:31 /user
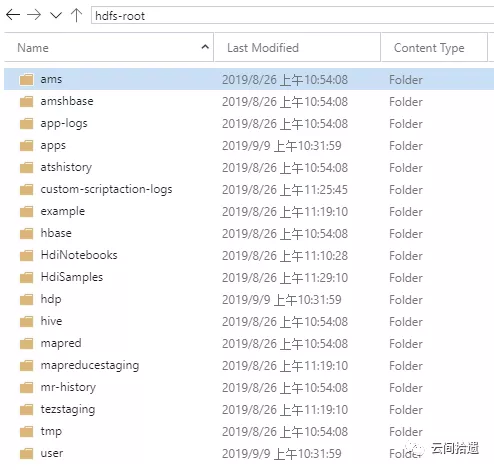
將文件列表和ADLS Gen2比對,可以看到這裡的“根目錄”事實上就完全對應着hdiclusterroot這個數據湖實例下hdfs-root文件系統中的數據,這說明集群實現了該數據湖文件系統的掛載:

那麼,這樣的遠程掛載是如何實現的呢?打開集群的core-site.xml 配置文件,答案在fs.defaultFS配置節中:
<property> <name>fs.defaultFS</name> <value>abfs://hdfs-root@hdiclusterroot.dfs.core.windows.net</value> <final>true</final> </property>
原來,與通常使用hdfs不同,集群的fs.defaultFS在創建時就被設置為了以abfs為開頭的特定url,該url正是指向我們的數據湖存儲。這個ABFS驅動(Azure Blob File System)是微軟專門為Data Lake Storage Gen2開發,全面實現了Hadoop的FileSystem接口,為Hadoop體系和ADLS Gen2架起了溝通橋樑。
為證明數據湖文件系統能夠正常工作,我們來運行一個經典的WordCount程序。筆者使用AzCopy往數據湖中上傳了一本小說《雙城記》 (ATaleOfTwoCities.txt),然後到HDInsight集群自帶的Jupyter Notebook里通過Scala腳本運用Spark來進行詞頻統計:


Great! 我們的Spark on ADLS Gen2實驗完美運行,過程如絲般順滑。
小結
Azure Data Lake Storage Gen2是微軟Azure全新一代的大數據存儲產品,專為企業級數據湖類應用所構建。它繼承了Azure Blob Storage易於使用、成本低廉的特點,同時又加入了目錄層次結構、細粒度權限控制等企業級特性。
作為ADLS Gen2系列的第二篇,本文主要實踐了大數據集群掛載ADLS Gen2作為主存儲的場景,在證明ADLS Gen2具備良好Hadoop生態兼容性的同時,也體驗了與傳統HDFS不同的存儲計算分離架構。該種架構由於可獨立擴展計算和存儲部分,非常適合雲端特點,正受到越來越多的歡迎。後續我們還將探索ADLS Gen2的更多特性,敬請關注。
關聯閱讀:
構建企業級數據湖?Azure Data Lake Storage Gen2實戰體驗(上)
“雲間拾遺”專註於從用戶視角介紹雲計算產品與技術,堅持以實操體驗為核心輸出內容,同時結合產品邏輯對應用場景進行深度解讀。歡迎掃描下方二維碼關注“雲間拾遺”微信公眾號,或訂閱本博客。



