全面講解線程池原理!
線程池(Executor)
什麼是線程池?
Java5引入了新的稱為Executor框架的並發API,以簡化程序員的工作。它簡化了多線程應用程序的設計和開發。它主要由Executor、ExecutorService接口和ThreadPoolExecutor類組成,ThreadPoolExecutor類同時實現Executor和ExecutorService接口。ThreadPoolExecutor類提供線程池的實現。我們將在教程的後面部分了解更多。
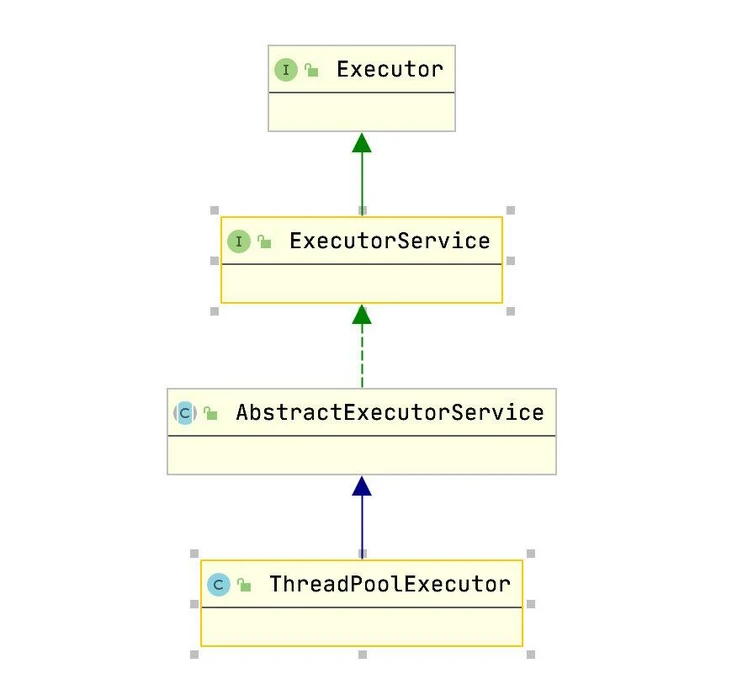 線程池繼承關係圖
線程池繼承關係圖
為什麼我們需要線程池?
當我們創建一個簡單的多線程應用程序時,我們創建Runnable對象,並使用Runnable構造線程對象,我們需要創建、執行和管理線程。我們可能很難做到這一點。Executor框架為您做這件事。它負責創建、執行和管理線程,不僅如此,它還提高了應用程序的性能。
當您為每個任務創建一個新線程,然後如果系統高度過載,您將出現內存不足錯誤,系統將失敗,甚至拋出oom異常。如果使用ThreadPoolExecutor,則不會為新任務創建線程。將任務分配給有限數量的線程只去執行Runnable,一旦線程完成一個任務,他將會去阻塞隊列中獲取Runnable去執行。
如何創建線程池?
public interface Executor {
void execute(Runnable command);
}
還有另一個名為ExecutorService的接口,它擴展了Executor接口。它可以被稱為Executor,它提供了可以控制終止的方法和可以生成未來跟蹤一個或多個異步任務進度的方法。它有提交、關機、立即關機等方法。
ThreadPoolExecutor是ThreadPool的實際實現。它擴展了實現ExecutorService接口的AbstractThreadPoolExecutor。可以從Executor類的工廠方法創建ThreadPoolExecutor。建議使用一種方法獲取ThreadPoolExecutor的實例。
-
使用
Executors工廠方法去創建線程池:
提供默認靜態方法
Executors類中有4個工廠方法可用於獲取ThreadPoolExecutor的實例。我們正在使用Executors的newFixedThreadPool獲取ThreadPoolExecutor的一個實例。
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) Executors.newFixedThreadPool(5);
| 方法 | 說明 |
|---|---|
| newFixedThreadPool(int nThreads) | 此方法返回線程池執行器,其最大大小(例如n個線程)是固定的 |
| newCachedThreadPool() | 此方法返回一個無限線程池。 |
| newSingleThreadedExecutor() | 此方法返回一個線程執行器,該執行器保證使用單個線程。 |
| newScheduledThreadPool(int corePoolSize) | 這個方法返回一個固定大小的線程池,可以安排命令在給定的延遲後運行,或者定期執行 |
-
自定義
ThreadPoolExecutor的創建線程池
提供默認構造函數
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,
TimeUnit unit,BlockingQueue workQueue ,ThreadFactory threadFactory,RejectedExecutionHandler handler) ;
| 參數 | 說明 |
|---|---|
| corePoolSize | 核心線程數 |
| maximumPoolSize | 最大線程數 |
| keepAliveTime | 線程保持存活的最大時間 |
| unit | 時間單位 |
| workQueue | 阻塞隊列 |
| threadFactory | 線程工廠 |
| handler | 拒絕策略 |
ThreadPoolExecutor源碼分析
-
線程池內部狀態
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// 獲取線程狀態
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 獲取work線程數
private static int workerCountOf(int c) { return c & CAPACITY; }
// 制定狀態&線程數 獲取ctl值
private static int ctlOf(int rs, int wc) { return rs | wc; }
ctl變量利用低29位表示線程池中線程數,通過高3位表示線程池的運行狀態:
RUNNING:-1 << COUNT_BITS,即高3位為111,該狀態的線程池會接收新任務,並處理阻塞隊列中的任務;SHUTDOWN: 0 << COUNT_BITS,即高3位為000,該狀態的線程池不會接收新任務,但會處理阻塞隊列中的任務;STOP: 1 << COUNT_BITS,即高3位為001,該狀態的線程不會接收新任務,也不會處理阻塞隊列中的任務,而且會中斷正在運行的任務;TIDYING: 2 << COUNT_BITS,即高3位為010, 所有的任務都已經終止;TERMINATED: 3 << COUNT_BITS,即高3位為011, terminated
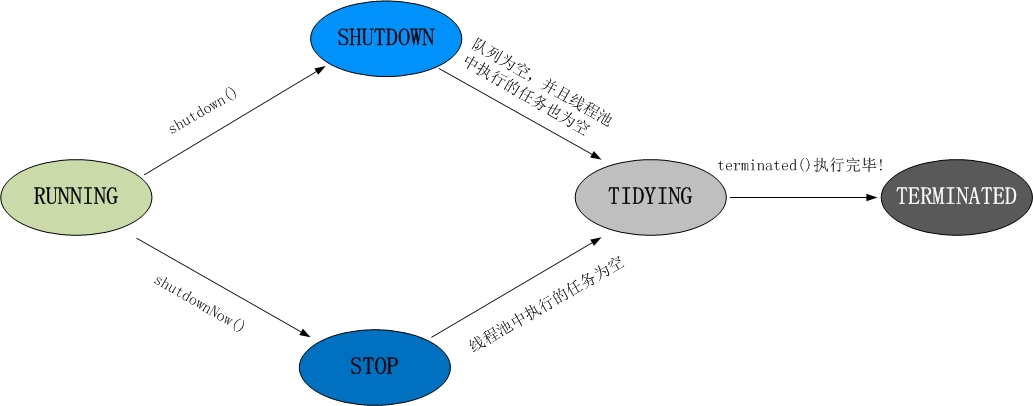 狀態轉換圖
狀態轉換圖
下面帶大家分析下ThreadPoolExecutor內部幾個核心方法:
-
添加任務:execute(Runnable command)
執行Runnable入口方法
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//workerCountOf獲取線程池的當前線程數;小於corePoolSize,執行addWorker創建新線程執行command任務
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// double check: c, recheck
// 線程池處於RUNNING狀態,把提交的任務成功放入阻塞隊列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//回滾到入隊操作前,即倘若線程池shutdown狀態,就remove(command)
//如果線程池沒有RUNNING,成功從阻塞隊列中刪除任務,執行reject方法處理任務
if (! isRunning(recheck) && remove(command))
reject(command);
//線程池處於running狀態,但是沒有線程,則創建線程去執行隊列的任務。
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 往線程池中創建新的線程失敗,則reject任務
else if (!addWorker(command, false))
reject(command);
}
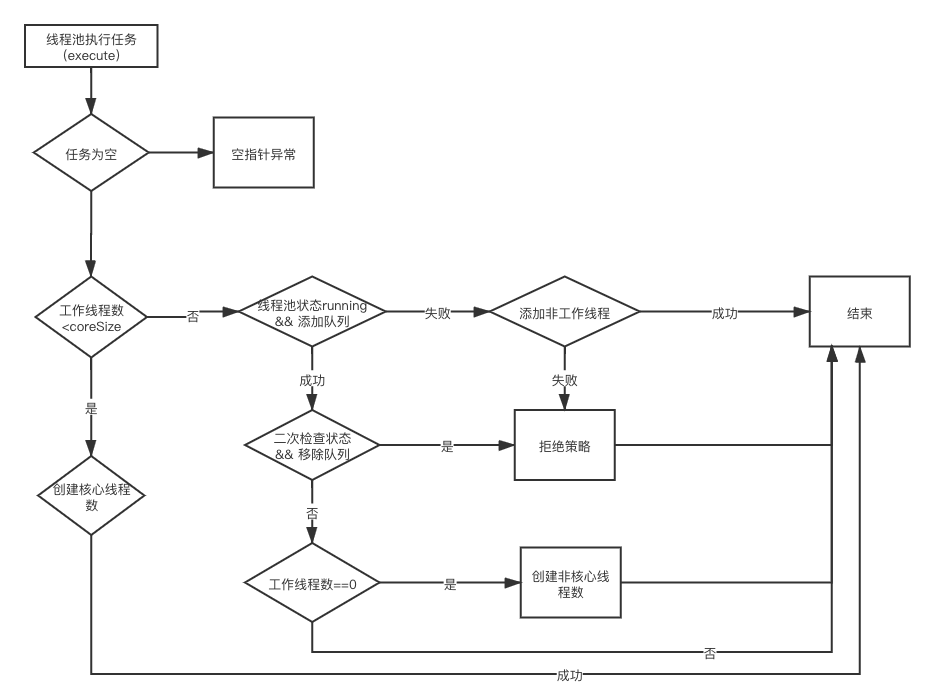 添加任務流程圖
添加任務流程圖
-
添加工作隊列 addWorker(Runnable firstTask, boolean core)
我們接下來看看如何添加worker線程的
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
for (;;) {
int c = ctl.get(); //讀取ctl的值
int rs = runStateOf(c); //獲取線程池的運行狀態
/*判斷當前線程池還是否需要執行任務
*如果當前線程池的狀態為RUNNING態則不會返回false
*返回false的條件(大前提:當前線程池狀態不是RUNNING態),在此基礎下下面三個條件有任何一個不成立都會直接返回,而不新建工作線程:
* 1.當前線程池的狀態為SHUTDOWN態
* 2.所提交任務為null
* 3.阻塞隊列非空
*/
if (rs >= SHUTDOWN &&
!(rs == SHUTDOWN && firstTask == null && !workQueue.isEmpty()))
return false;
for (;;) {
//獲取當前池中線程個數
int wc = workerCountOf(c);
/*
*若當前池中線程個數 >= 2的29次方減1,則無法創建新線程。池中最大線程數量為2的29次方減1個
*如果core為true則於核心先稱數量進行比較,否則與最大線程數量進行比較
*/
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//將workerCount的值加1,並跳出外層循環
if (compareAndIncrementWorkerCount(c))
break retry;
//如果線程狀態被修改,則再次執行外層循環
c = ctl.get();
if (runStateOf(c) != rs)
continue retry;
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
/*
*此處創建Worker實例,並將任務firstTask設置進去
*注意Worker類中有兩個特殊的字段:1. Runnable firstTask 2. final Thread thread
*Worker類本身也繼承了Runnable接口,實現了其run()方法
*/
w = new Worker(firstTask);
//這裡的t是w本身表示的線程對象,而非firstTask。
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//獲取當前線程池的運行狀態rs
int rs = runStateOf(ctl.get());
/*
*rs < SHUTDOWN的狀態只有RUNNING態
*能進去下面if的條件:
* 1. 當前線程池運行狀態為RUNNING
* 2.當前線程池狀態為SHUTDOWN而且firstTask為null
*/
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive())
throw new IllegalThreadStateException();
//HashSet<Worker> workers線程池中利用HashSet保存的worker對象
workers.add(w);
int s = workers.size();
//largestPoolSize用來記錄線程池中最大的線程數量
if (s > largestPoolSize)
largestPoolSize = s;
//任務添加成功(線程創建成功)
workerAdded = true;
}
}finally {
mainLock.unlock();
}
if (workerAdded) {
//啟動工作線程,這裡調用的是Worker類中的run()方法
t.start();
workerStarted = true;
}
}
} finally {
if (!workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
-
執行任務: runWorker(Worker w)
在addWorker成功後會調用Worker的start()方法,接下來來分析下如何執行任務的。
final void runWorker(Worker w) {
//獲取當前執行的線程對象
Thread wt = Thread.currentThread();
//獲取第一個任務
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // 允許中斷
boolean completedAbruptly = true;
try {
// task任務不為空 或者 getTask()獲取任務不為空時候進入循環
while (task != null || (task = getTask()) != null) {
w.lock();
// 如果線程狀態>STOP 或者當前線程被中斷時候 這時候調用wt.interrupt()去中斷worker線程
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() && runStateAtLeast(ctl.get(), STOP))) && !wt.isInterrupted())
wt.interrupt();
try {
//在ThreadPoolExecutor中該方法是一個空方法
beforeExecute(wt, task);
Throwable thrown = null;
try {
//執行任務。
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
//任務計數器加1
w.completedTasks++;
//釋放鎖
w.unlock();
}
}
//如果執行任務的過程中沒有發生異常,則completedAbruptly會被賦值為false
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
看到這裡我們還沒看到當worker線程數>coreSize時候是如何去回收線程的,不用着急,接下來我們去看下getTask()方法。
-
獲取task任務: getTask()
private Runnable getTask() {
boolean timedOut = false;
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
/*
*若當前線程池的工作狀態為RUNNING則不會進入下面if。
*1.若狀態為STOP、TIDYING、TERMINATED則當前工作線程不能執行任務。
*2.若狀態為SHUTDOWN,且阻塞隊列為空,則獲取任務為null
*/
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
//workerCount的值減1
decrementWorkerCount();
return null;
}
//獲取工作線程數量
int wc = workerCountOf(c);
//若allowCoreThreadTimeOut設置為true 或者 當前池中工作線程數量大於核心線程數量 則timed為true
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//若當前工作線程數量已經超過最大線程數量,則也獲取不到任務,會從該方法中返回null,進而結束該工作線程
if ((wc > maximumPoolSize || (timed && timedOut)) && (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
/*
*若allowCoreThreadTimeOut設置為true 或者 當前池中工作線程數量大於核心線程數量
* 則:在指定的時間內從阻塞隊列中獲取任務,若取不到則返回null
*若allowCoreThreadTimeOut設置為false 而且 當前池中工作線程數量小於核心線程數量
* 則:在指定的時間內從阻塞隊列中獲取任務,若取不到則一直阻塞
*/
Runnable r = timed ? workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) : workQueue.take();
if (r != null)
return r;
//若r == null,則此處timedOut的值被設置為true
timedOut = true;
} catch (InterruptedException retry) {
//如果阻塞等待過程中線程發生中斷,則將timeOut設置為false,進入下一次循環
timedOut = false;
}
}
-
關閉線程: shutdown()
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//檢測是否有關閉線程池的權限
checkShutdownAccess();
//將線程池狀態設置為SHUTDOWN態
advanceRunState(SHUTDOWN);
//中斷空閑線程(沒有執行任務的線程)
interruptIdleWorkers();
//該方法在ThreadPoolExecutor中是一個空方法
onShutdown();
} finally {
mainLock.unlock();
}
//嘗試將線程池狀態設置為TERMINATED狀態。
tryTerminate();
-
立即關閉線程: shutdownNow()
此方法會中斷任務執行,返回未執行的task
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
// 加鎖
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 直接設置STOP狀態
advanceRunState(STOP);
interruptWorkers();
// 丟棄未執行的task,返回
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
線程池使用注意事項
-
使用ThreadLocal
ThreadLocal 稱為線程本地存儲,一般作為靜態域使用,它為每一個使用它的線程提供一個其值(value)的副本。通常對數據庫連接(Connection)和事務(Transaction)使用線程本地存儲。 可以簡單地將 ThreadLocal 理解成一個容器,它將 value 對象存儲在 Map<Thread, T> 域中,即使用當前線程為 key 的一個 Map,ThreadLocal 的 get() 方法從 Map 里取與當前線程相關聯的 value 對象。ThreadLocal 的真正實現並不是這樣的,但是可以簡單地這樣理解。線程池中的線程在任務執行完成後會被複用,所以在線程執行完成時,要對 ThreadLocal 進行清理(清除掉與本線程相關聯的 value 對象)。不然,被複用的線程去執行新的任務時會使用被上一個線程操作過的 value 對象,從而產生不符合預期的結果。
-
設置合理的線程數
新手可能對使用線程池有一個誤區,並發越高使用更多線程數,然而實際的情況就是過多的線程會造成系統大量的Context-Switch從而影響系統的吞吐量,所以合理的線程數需要結合項目進行壓測,一般我們主要針對2種類型的任務設置線程數規則為:
-
cpu密集型
coreSize == cpu核心數+1
-
Io密集型
coreSize == 2*cpu核心數
結束
識別下方二維碼!回復:
入群,掃碼加入我們交流群!

 點贊是認可,在看是支持
點贊是認可,在看是支持

