C語言代碼區錯誤以及編譯過程
C語言代碼區錯誤
欲想了解C語言代碼段會有如何錯誤,我們必須首先了解編譯器是如何把C語言文本信息編譯成為可以執行的機器碼的。🌞🌞🌞🌞
背景介紹
- 測試使用的C語言代碼
- 導入標準庫,定義宏變量,定義結構體,重命名結構體,
- 函數原型聲明,主函數入口,函數定義
#include <stdio.h>
#define PI 3.14159
typedef struct student {
char name[8];
int age;
} Student;
void sayHi(Student);
int main() {
// we define a Student structure here.
Student mushroom = {"mushroom", 19};
/*
Output some massage.
*/
sayHi(mushroom);
printf("I know PI equels to %lf", PI);
return 0;
}
void sayHi(Student stu) {
printf("Hi! I am %s.\n", stu.name);
}
- C語言編譯基本流程

- 一共劃分為了文件輸入,預處理,編譯,彙編,連接,最後輸出為可執行文件。GCC正好就為我們提供了所有的這些方法,下面來一一介紹下
GCC內置的處理C語言文件的指令。 GCC編譯器基本指令了解
| 指令名 | 解釋 |
|---|---|
gcc -c |
編譯或彙編源文件,但是不作連接.編譯器輸出對應於源文件的目標文件. |
gcc -S |
編譯後即停止,不進行彙編.對於每個輸入的非彙編語言文件,輸出文件是彙編語言文件. |
gcc -E |
預處理後即停止,不進行編譯.預處理後的代碼送往標準輸出. |
gcc -o filename |
指定輸出文件為file.該選項不在乎GCC產生什麼輸出,無論是可執行文件,目標文件,彙編文件還是 預處理後的C代碼. |
這裡只是給出了gcc最常見的指令,如果還想了解更多的細節可以查看下官方文檔.這裡給出國內維護的GCC中文手冊
如上的GCC相關指令給出了一整套處理C語言文件的完整方法,下面使用來完整的按流程編譯下C語言文件。
預處理階段(preprocessing)
再看一眼
test.c文件

使用gcc -E filename > outputFilename預處理文件
gcc -E test.c
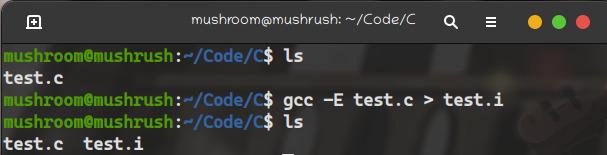
將信息輸出到test.i文件之中
原本只有二十五行的代碼,一下子被擴張到了751行
基本數據類型的重新定義

標準輸入輸出函數

外部函數
test.c代碼段
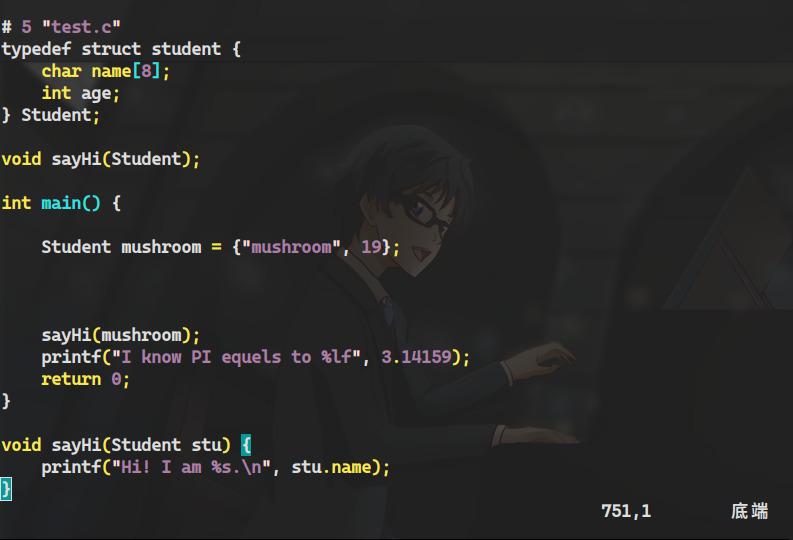
這裡說的代碼段不準確,代碼段是整個代碼,這裡是特指
test.c中手動寫入的代碼區
預處理後效果分析
- 插入了頭文件信息
- 宏消失,發生了宏替換
- 注釋刪除

編譯階段(compilation)
使用gcc -S filename
gcc -S test.i
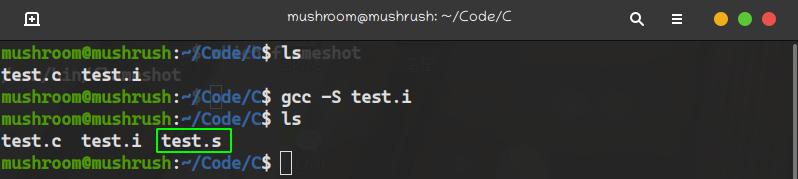
編譯生成了
test.s文件,只是一個彙編代碼文件藉助彙編代碼翻譯為機器碼
彙編代碼

討論彙編代碼已經超過了本次討論的內容,這裡附上一篇講解彙編的文章彙編代碼,裏面正對於計算機內存,與CPU的關係闡釋的相當清楚,各位有時間可以看看。
可以從彙編代碼的一些細節處看出來,這彙編代碼實際上是原
test.c向彙編語言的翻譯,像C語言這樣計算機編程語言實際上是高級語言,簡單來說是給人看的,語法等等各個方面的都適用於人類去閱讀,但是計算機是無法理解的。計算機只能理解0和1,二進制, (最開始電子計算機剛剛被發明出來的時候,程序員們編程就是使用的手動輸入01二進制指令的方法編程的),帶有特定功能的二進制碼被稱為指令,指令的集合被稱為指令集,(這也正是當前中國被卡脖子的地方)彙編語言是機器碼的封裝,每一個彙編指令都對應與一個機器碼,這也是為什麼彙編語言被成為低級語言。
梳理下編譯階段
我們不去考察
GCC是如何巴拉巴拉變出這一堆看不懂的彙編代碼,但我們應當明白,C語言是想把自己轉化成為彙編碼然後直接交給CPU,我們可以這麼理解C語言是彙編語言的重構封裝,使得,而編譯器就好像是翻譯器。大致理解為如下流程。

彙編階段(assembly)
gcc -c filename
gcc -c test.s
彙編階段是彙編語言向機器碼轉化的過程,可以理解為彙編語言的編譯過程。

強行讀取一下

雖然基本上是亂碼,但是其中還是有不少的部分如
I know PI equels to %lf等等字符串類型的數據可以被顯示出來。但是此程序還無法交給CPU計算,還缺少最後一步連接(link)

連接階段(link)
gcc filename -o targetname
-o選項實際上可以處理很多種類的中間文件,如果沒有使用`-o'選項,默認的輸出結果是:可執行文件為`a.out', `source.suffix '的目標文件是`source.o',彙編文件是 `source.s',而預處理後的C源代碼送往標準輸出.
gcc test.o -o test
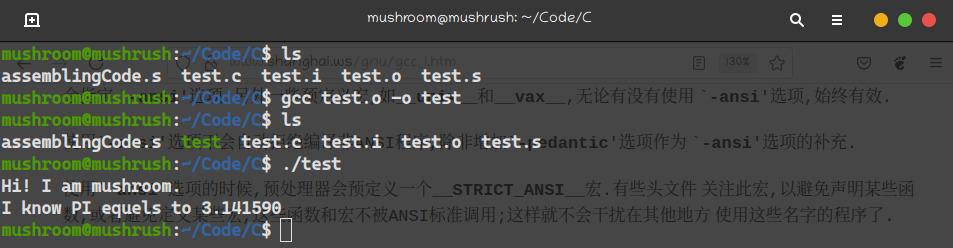
最終的階段終於得到了真正的目標文件,完成了一次人機的簡單交互。
但是這個
gcc -o實際上給出的很曖昧,這個過程中實際上是把我們自己寫好的程序與存儲在硬盤的庫文件連接,比如說printf()函數,並沒有定義它,但是卻可以使用,這是由於上述操作與標準庫建立了連接.
!!!注意!!!,所有的可執行程序必須放在CPU中才可以運行!!****
舉個例子也許會好理解一些:
你們全家人要出去郊遊,你跟媽媽說我要吃大雪糕,媽媽答應給你準備。
你把你的想法傳達給了媽媽,你們一起建立起了一個約定,可以理解為上述彙編階段產生的未連接的可執行文件
媽媽答應了你的約定,可是,如何去履現和你的承諾呢?
在郊遊地點周圍現買.(假設郊遊地點周圍一定有)
在家裡就準備好,打包一起帶走到郊遊地點.
這導出了兩種不同的連接方式:
- 靜態連接:一起打包好,我要的我都準備好。(對應於上述的在家裡準備雪糕)
- 動態鏈接: 我暫時不準備,但是我知道,它雪糕就在那兒,所以等到了之後在動態的把它拿過來執行。
很容易想到動態鏈接的文件體積會相對來說少很多,但是可移植性差點。
反思
真正的可執行的程序在經過預處理,編譯,彙編,連接相關庫文件。最終形成了程序的最終形態,當次文件執行的時候,立馬從硬盤讀取到了內存中,然後立馬放置到CPU進行計算。
如何避免代碼段出現內存錯誤呢?
代碼段,是存放指令集的,所以我列舉出了以下幾個方面可能造成的錯誤.
1. 阻止C文件翻譯為彙編代碼 2. 阻止庫連接,或者庫連接失敗
阻止C文件翻譯為彙編代碼:
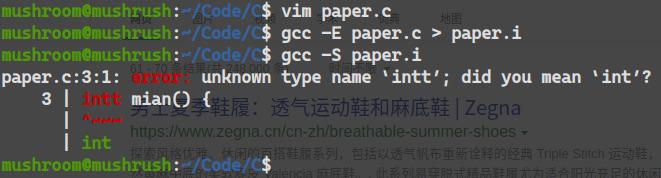
#include <stdio.h>
int mian() {
printf("Mushroon!!!!\n");
return 0;
}
如上代碼,故意將函數入口main寫成mian``int寫成intt
雖然我們已經儘力的想去迫害C語言的編譯器,可是它還是認真的指出了我們的惡劣行經。
預處理完全沒問題,編譯階段出現了問題,失敗了,超出了C語言編譯器可以理解的符號系統
阻止庫連接
回到上面給出的一家人郊遊你卻想吃雪糕的例子,當你提出吃雪糕的時候,你媽媽給你一大耳巴子,說”吃什麼吃!不給吃!!”,這就是阻止了庫的連接。自然無法完成你想要吃雪糕這件事了。
總結
實際上本文沒有得到什麼比較深刻的結論。
目前隨着編譯器越來越完善,各大IDE(集成式編程環境)越來越強大,語義分析,自動查詢語法錯誤,還能在不編譯的時候察覺出想C語言編譯器無法查出的問題:如數組訪問越界。
這些工具的出現使得編程時代碼準確無誤的被翻譯成為機器碼,確保可以執行,讓程序員更注重於程序的功能上,是否準確?是否有效?這也是時代的一大進步吧!


