『動善時』JMeter基礎 — 34、JMeter接口關聯【XPath提取器】
1、XPath提取器介紹
有些WEB項目是前後端不分離的,接口返回的內容不是Json格式的數據,而返回的是一個HTML頁面。並且有些參數是隱藏在HTML頁面裏面的,需要從HTML頁面中提取出這些隱藏參數,這個時候就會用到XPath提取器組件。
XPath提取器組件常用於接口返回值為HTML或XML格式數據的時候,進行數據的提取。
XPath提取器組件在後置處理器元件中,後置處理器主要的作用,在請求結束或者返迴響應結果時發揮作用。
2、XPath提取器界面詳解
添加XPath提取器組件操作:選中「取樣器」右鍵 —> 添加 —> 後置處理器 —> XPath提取器。
界面如下圖所示:
下面是XPath提取器組件的詳細說明:
- 名稱:XPath提取器組件的自定義名稱,見名知意最好。
- 注釋:即添加一些備註信息,對該XPath提取器組件的簡短說明,以便後期回顧時查看。
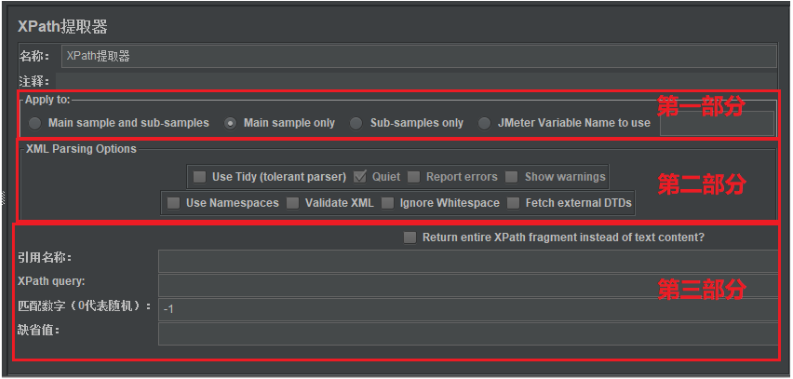
(1)Apply to:作用範圍(返回內容的取值範圍)
Main sample and sub-samples:作用於父節點的取樣器及對應子節點的取樣器。Main sample only:僅作用於父節點的取樣器。Sub-samples only:僅作用於子節點的取樣器。JMeter Variable Name to use:作用於JMeter變量(輸入框內可輸入JMeter的變量名稱),從指定變量中提取需要的值。
(2)XML Parsing Options:要解析的XML參數
Use Tidy (tolerant parser):當需要處理的頁面是HTML格式時,必須選中該選項;如果是XML或XHTML格式,則取消選中。Quiet:表示只顯示需要的HTML頁面。Report errors:表示顯示響應報錯。Show warnings:表示顯示警告。Use Namespaces:如果啟用該選項,後續的XML解析器將使用命名空間來分辨。Validate XML:根據頁面元素模式進行檢查解析。Ignore Whitespace:忽略空白內容。Fetch external DTDs:如果選中該項,外部將使用DTD規則來獲取頁面內容。
(3)第三部分內容
Return entire XPath fragment of text content:表示是否返迴文本內容的整個XPath片段。Reference Name:定義提取值的變量名稱。XPath Query:用於提取值的XPath表達式。- 匹配數字(0代表隨機):表示取值是第幾個匹配結果,因為有可能XPath表達式會匹配到多個值。0表示隨機,-1表示全部,1代表第一個,2代表第二個,以此類推。
Default Value:參數的默認值。也就是取不到值時的默認值。
總結XPath提取器組件:
對所有符合條件的取樣器按順序進行取樣。
例如,如果有一個主取樣器和三個子取樣器,每個取樣器都有一個符合條件的匹配結果(總共4個)。
當設置為
Sub-samples only時,匹配數字為3,則第三個子取樣器的匹配結果返回;當匹配數字為0或者負數,所有的合格的取樣器都將被處理,而當匹配數字>0,一旦找到足夠的匹配,比對就停止下來。
3、XPath提取器的使用
需求:
- 訪問網易官網,獲取title值。
- 將title值放入百度搜索框,進行搜索。
(1)測試計劃內包含的元件
添加元件操作步驟:
- 創建測試計劃。
- 創建線程組:
選中「測試計劃」右鍵 —> 添加 —> 線程(用戶) —> 線程組。 - 在線程組下,添加取樣器「HTTP請求」組件:
選中「線程組」右鍵 —> 添加 —> 取樣器 —> HTTP請求。 - 在取樣器下,添加後置處理器「XPath提取器」組件:
選中「取樣器」右鍵 —> 添加 —> 後置處理器 —> XPath提取器。 - 在線程組下,添加監聽器「察看結果樹」組件:
選中「線程組」右鍵 —> 添加 —> 監聽器 —> 察看結果樹。
提示:需要重複添加的組件這裡不重複描述。
最終測試計劃中的元件如下:
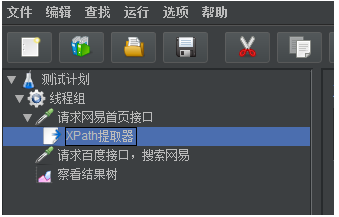
點擊運行按鈕,會提示你先保存該腳本,腳本保存完成後會直接自動運行該腳本。
提示:提取器一定要添加在你指定的某個請求下面,作為他的子請求,否則提取不到指定的數據!
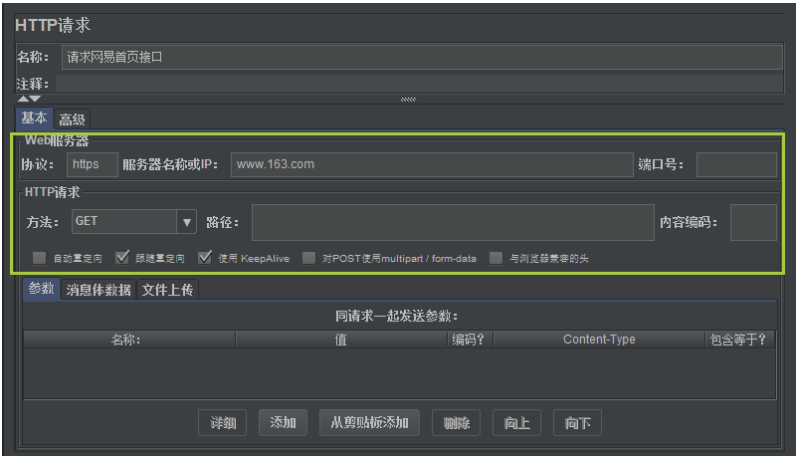
(2)網易首頁請求界面內容
非常簡單的Get請求,之前說了很多次了,這裡就不做解釋了。
界面內容如下圖所示:
(3)XPath提取器界面內容
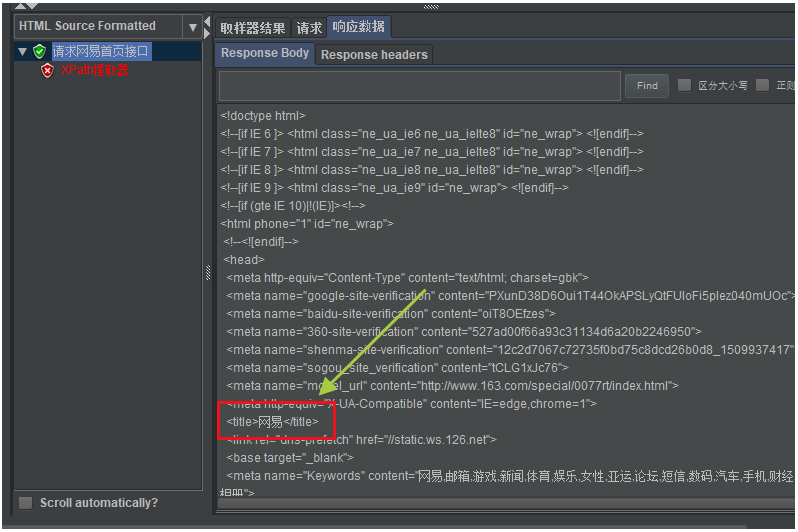
我們在編輯XPath提取器組件之前,一般先請求一下需要提取返回數據的接口。
因為我們需要先查看一下需要提取的數據在什麼位置,如下圖所示:
然後選擇XPath Tester視圖模式,先手動編寫XPath表達式,看看是否能夠取到需要的數據。
如下圖所示:
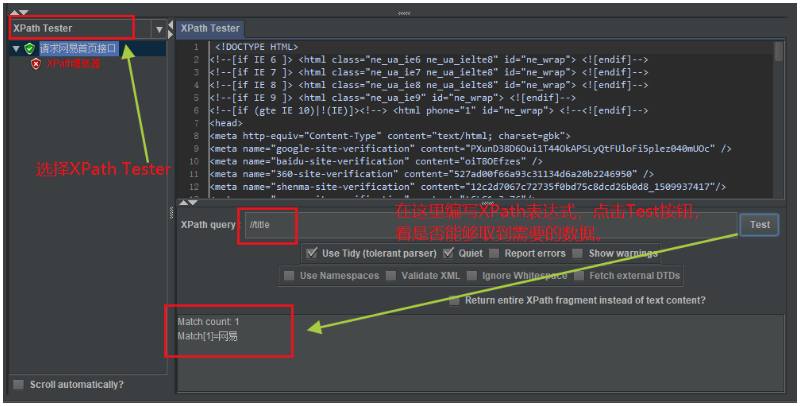
注意兩點:
- 選擇
XPath Tester模式進行XPath表達式的編寫驗證。 - 如果是在HTML頁面源碼中提取數據,
Use Tidy (tolerant parser)選擇一定要勾選,否則會報錯。
之後我們就可以編寫XPath提取器組件界面了,如下:
編寫引用名稱、XPath表達式、匹配數據選擇,還有Use Tidy選項一定要勾選,否則不能取到數據。
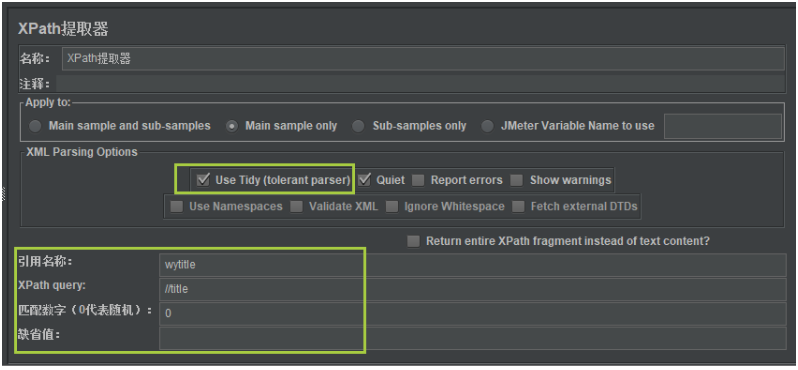
XPath提取器組件提取出來的數據,會存儲在線程變量中,供其他後續接口使用。
關於XPath表示的寫法,可以看Selenium相關的文章,裏面有詳細的寫法。
(4)百度首頁請求界面內容
填寫接口的基本請求信息,然後把XPath提取器提取出來的數據,作為參數化變量應用到請求中。
如下圖所示:
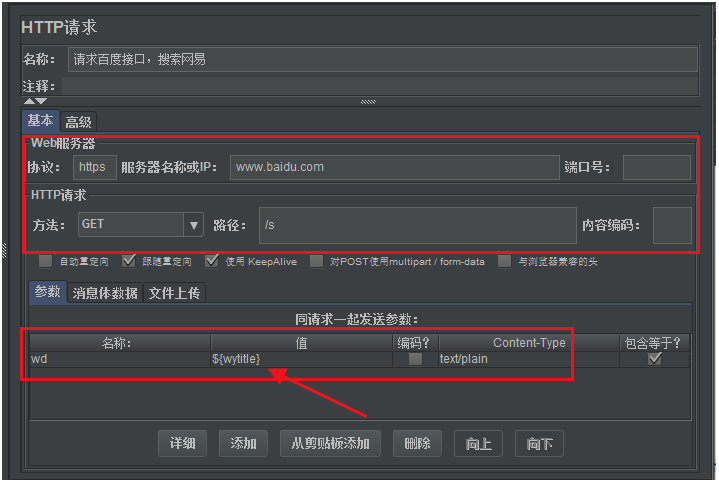
提示:如果此時直接執行該腳本,請求百度搜索網易的接口會執行,但是沒有返回數據的,因為百度拒絕你的訪問,我們需要設置請求頭
User-Agent屬性,來模擬是一個瀏覽器訪問,如User-Agent=Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400,這樣百度就不會拒絕訪問了。
(5)查看結果
我們可以看到再第二個請求中,拿到了第一個請求提取出來的數據「網易」。
如下圖所示:
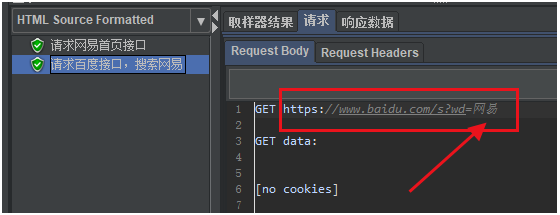
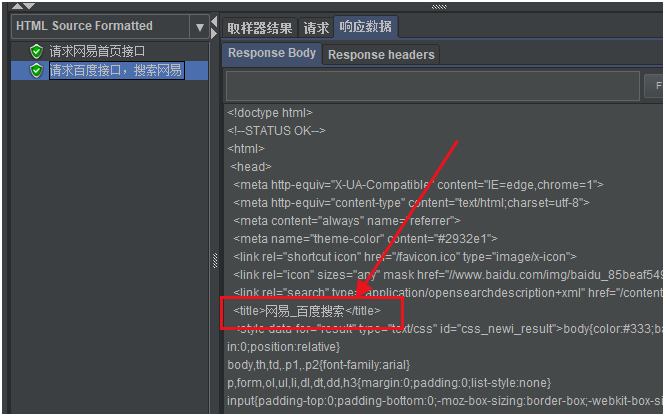
再來看看第二個請求響應的結果,可以看到有網易_百度搜索的title屬性,說明在百度已經進行了網易搜索。
如下圖所示:
提示:可以添加
Debug PostProcessor(調試後置處理器),或者Debug Sampler(調試取樣器),來查看Xpath提取器中,提取出的內容是否正確。注意:正常跑用例時刪除或禁用它們。
4、總結
XPath提取器通常是從網頁源文件中,提取數據時用的比較多。提取完參數後,相當於把參數以 key-value 的形式,存放到參數池中,以便後面的請求使用。
注意:不能超前引用。


