Go微服務全鏈路跟蹤詳解
- 2019 年 10 月 3 日
- 筆記
在微服務架構中,調用鏈是漫長而複雜的,要了解其中的每個環節及其性能,你需要全鏈路跟蹤。 它的原理很簡單,你可以在每個請求開始時生成一個唯一的ID,並將其傳遞到整個調用鏈。 該ID稱為CorrelationID¹,你可以用它來跟蹤整個請求並獲得各個調用環節的性能指標。簡單來說有兩個問題需要解決。第一,如何在應用程序內部傳遞ID; 第二,當你需要調用另一個微服務時,如何通過網絡傳遞ID。
什麼是OpenTracing?
現在有許多開源的分佈式跟蹤庫可供選擇,其中最受歡迎的庫可能是Zipkin²和Jaeger³。 選擇哪個是一個令人頭疼的問題,因為你現在可以選擇最受歡迎的一個,但是如果以後有一個更好的出現呢?OpenTracing⁴可以幫你解決這個問題。它建立了一套跟蹤庫的通用接口,這樣你的程序只需要調用這些接口而不被具體的跟蹤庫綁定,將來可以切換到不同的跟蹤庫而無需更改代碼。Zipkin和Jaeger都支持OpenTracing。
如何跟蹤服務器端點(server endpoints)?
在下面的程序中我使用「Zipkin」作為跟蹤庫,用「OpenTracing」作為通用跟蹤接口。 跟蹤系統中通常有四個組件,下面我用Zipkin作為示例:
-
recorder(記錄器):記錄跟蹤數據
-
Reporter (or collecting agent)(報告器或收集代理):從記錄器收集數據並將數據發送到UI程序
-
Tracer:生成跟蹤數據
-
UI:負責在圖形UI中顯示跟蹤數據

上面是Zipkin的組件圖,你可以在Zipkin Architecture中找到它。
有兩種不同類型的跟蹤,一種是進程內跟蹤(in-process),另一種是跨進程跟蹤(cross-process)。 我們將首先討論跨進程跟蹤。
客戶端程序:
我們將用一個簡單的gRPC程序作為示例,它分成客戶端和服務器端代碼。 我們想跟蹤一個完整的服務請求,它從客戶端到服務端並從服務端返回。 以下是在客戶端創建新跟蹤器的代碼。它首先創建「HTTP Collector」(the agent)用來收集跟蹤數據並將其發送到「Zipkin」 UI, 「endpointUrl」是「Zipkin」 UI的URL。 其次,它創建了一個記錄器(recorder)來記錄端點上的信息,「hostUrl」是gRPC(客戶端)呼叫的URL。第三,它用我們新建的記錄器創建了一個新的跟蹤器(tracer)。 最後,它為「OpenTracing」設置了「GlobalTracer」,這樣你可以在程序中的任何地方訪問它。
const ( endpoint_url = "http://localhost:9411/api/v1/spans" host_url = "localhost:5051" service_name_cache_client = "cache service client" service_name_call_get = "callGet" ) func newTracer () (opentracing.Tracer, zipkintracer.Collector, error) { collector, err := openzipkin.NewHTTPCollector(endpoint_url) if err != nil { return nil, nil, err } recorder :=openzipkin.NewRecorder(collector, true, host_url, service_name_cache_client) tracer, err := openzipkin.NewTracer( recorder, openzipkin.ClientServerSameSpan(true)) if err != nil { return nil,nil,err } opentracing.SetGlobalTracer(tracer) return tracer,collector, nil }以下是gRPC客戶端代碼。 它首先調用上面提到的函數「newTrace()」來創建跟蹤器,然後,它創建一個包含跟蹤器的gRPC調用連接。接下來,它使用新建的gRPC連接創建緩存服務(Cache service)的gRPC客戶端。 最後,它通過gRPC客戶端來調用緩存服務的「Get」函數。
key:="123" tracer, collector, err :=newTracer() if err != nil { panic(err) } defer collector.Close() connection, err := grpc.Dial(host_url, grpc.WithInsecure(), grpc.WithUnaryInterceptor(otgrpc.OpenTracingClientInterceptor(tracer, otgrpc.LogPayloads())), ) if err != nil { panic(err) } defer connection.Close() client := pb.NewCacheServiceClient(connection) value, err := callGet(key, client)Trace 和 Span:
在OpenTracing中,一個重要的概念是「trace」,它表示從頭到尾的一個請求的調用鏈,它的標識符是「traceID」。 一個「trace」包含有許多跨度(span),每個跨度捕獲調用鏈內的一個工作單元,並由「spanId」標識。 每個跨度具有一個父跨度,並且一個「trace」的所有跨度形成有向無環圖(DAG)。 以下是跨度之間的關係圖。 你可以從The OpenTracing Semantic Specification中找到它。

以下是函數「callGet」的代碼,它調用了gRPC服務端的「Get"函數。 在函數的開頭,OpenTracing為這個函數調用開啟了一個新的span,整個函數結束後,它也結束了這個span。
const service_name_call_get = "callGet" func callGet(key string, c pb.CacheServiceClient) ( []byte, error) { span := opentracing.StartSpan(service_name_call_get) defer span.Finish() time.Sleep(5*time.Millisecond) // Put root span in context so it will be used in our calls to the client. ctx := opentracing.ContextWithSpan(context.Background(), span) //ctx := context.Background() getReq:=&pb.GetReq{Key:key} getResp, err :=c.Get(ctx, getReq ) value := getResp.Value return value, err }服務端代碼:
下面是服務端代碼,它與客戶端代碼類似,它調用了「newTracer()」(與客戶端「newTracer()」函數幾乎相同)來創建跟蹤器。然後,它創建了一個「OpenTracingServerInterceptor」,其中包含跟蹤器。 最後,它使用我們剛創建的攔截器(Interceptor)創建了gRPC服務器。
connection, err := net.Listen(network, host_url) if err != nil { panic(err) } tracer,err := newTracer() if err != nil { panic(err) } opts := []grpc.ServerOption{ grpc.UnaryInterceptor( otgrpc.OpenTracingServerInterceptor(tracer,otgrpc.LogPayloads()), ), } srv := grpc.NewServer(opts...) cs := initCache() pb.RegisterCacheServiceServer(srv, cs) err = srv.Serve(connection) if err != nil { panic(err) } else { fmt.Println("server listening on port 5051") }以下是運行上述代碼後在Zipkin中看到的跟蹤和跨度的圖片。 在服務器端,我們不需要在函數內部編寫任何代碼來生成span,我們需要做的就是創建跟蹤器(tracer),服務器攔截器自動為我們生成span。
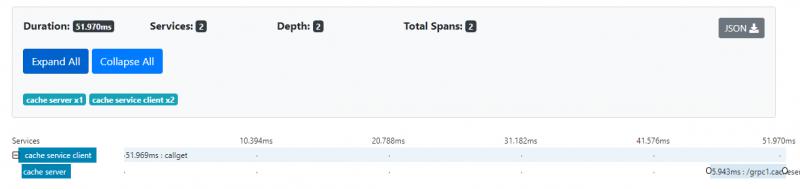
怎樣跟蹤函數內部?
上面的圖片沒有告訴我們函數內部的跟蹤細節, 我們需要編寫一些代碼來獲得它。
以下是服務器端「get」函數,我們在其中添加了跟蹤代碼。 它首先從上下文獲取跨度(span),然後創建一個新的子跨度並使用我們剛剛獲得的跨度作為父跨度。 接下來,它執行一些操作(例如數據庫查詢),然後結束(mysqlSpan.Finish())子跨度。
const service_name_db_query_user = "db query user" func (c *CacheService) Get(ctx context.Context, req *pb.GetReq) (*pb.GetResp, error) { time.Sleep(5*time.Millisecond) if parent := opentracing.SpanFromContext(ctx); parent != nil { pctx := parent.Context() if tracer := opentracing.GlobalTracer(); tracer != nil { mysqlSpan := tracer.StartSpan(service_name_db_query_user, opentracing.ChildOf(pctx)) defer mysqlSpan.Finish() //do some operations time.Sleep(time.Millisecond * 10) } } key := req.GetKey() value := c.storage[key] fmt.Println("get called with return of value: ", value) resp := &pb.GetResp{Value: value} return resp, nil }以下是它運行後的圖片。 現在它在服務器端有一個新的跨度「db query user」。
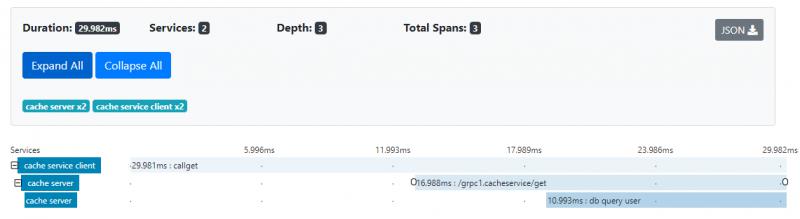
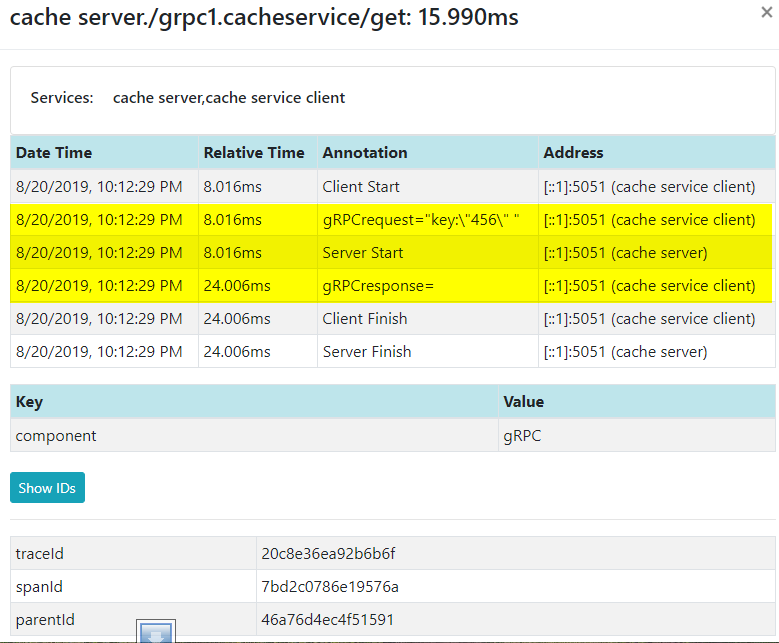
以下是zipkin中的跟蹤數據。 你可以看到客戶端從8.016ms開始,服務端也在同一時間啟動。 服務器端完成需要大約16ms。
怎樣跟蹤數據庫?
怎樣才能跟蹤數據庫內部的操作?首先,數據庫驅動程序需要支持跟蹤,另外你需要將跟蹤器(tracer)傳遞到數據庫函數中。如果數據庫驅動程序不支持跟蹤怎麼辦?現在已經有幾個開源驅動程序封裝器(Wrapper),它們可以封裝任何數據庫驅動程序並使其支持跟蹤。其中一個是instrumentedsql⁷(另外兩個是luna-duclos/instrumentedsql⁸和ocsql/driver.go⁹)。我簡要地看了一下他們的代碼,他們的原理基本相同。它們都為底層數據庫的每個函數創建了一個封裝(Wrapper),並在每個數據庫操作之前啟動一個新的跨度,並在操作完成後結束跨度。但是所有這些都只封裝了「database/sql」接口,這就意味着NoSQL數據庫沒有辦法使用他們。如果你找不到支持你需要的NoSQL數據庫(例如MongoDB)的OpenTracing的驅動程序,你可能需要自己編寫一個封裝(Wrapper),它並不困難。
一個問題是「如果我使用OpenTracing和Zipkin而數據庫驅動程序使用Openeracing和Jaeger,那會有問題嗎?"這其實不會發生。我上面提到的大部分封裝都支持OpenTracing。在使用封裝時,你需要註冊封裝了的SQL驅動程序,其中包含跟蹤器。在SQL驅動程序內部,所有跟蹤函數都只調用了OpenTracing的接口,因此它們甚至不知道底層實現是Zipkin還是Jaeger。現在使用OpenTarcing的好處終於體現出來了。在應用程序中創建全局跟蹤器時(Global tracer),你需要決定是使用Zipkin還是Jaeger,但這之後,應用程序或第三方庫中的每個函數都只調用OpenTracing接口,已經與具體的跟蹤庫(Zipkin或Jaeger)沒關係了。
怎樣跟蹤服務調用?
假設我們需要在gRPC服務中調用另外一個微服務(例如RESTFul服務),該如何跟蹤?
簡單來說就是使用HTTP頭作為媒介(Carrier)來傳遞跟蹤信息(traceID)。無論微服務是gRPC還是RESTFul,它們都使用HTTP協議。如果是消息隊列(Message Queue),則將跟蹤信息(traceID)放入消息報頭中。(Zipkin B3-propogation有「single header」和「multiple header」有兩種不同類型的跟蹤信息,但JMS僅支持「single header」)
一個重要的概念是「跟蹤上下文(trace context)」,它定義了傳播跟蹤所需的所有信息,例如traceID,parentId(父spanId)等。有關詳細信息,請閱讀跟蹤上下文(trace context)¹⁰。
OpenTracing提供了兩個處理「跟蹤上下文(trace context)」的函數:「extract(format,carrier)」和「inject(SpanContext,format,carrier)」。 「extarct()」從媒介(通常是HTTP頭)獲取跟蹤上下文。 「inject」將跟蹤上下文放入媒介,來保證跟蹤鏈的連續性。以下是我從Zipkin獲取的b3-propagation圖。
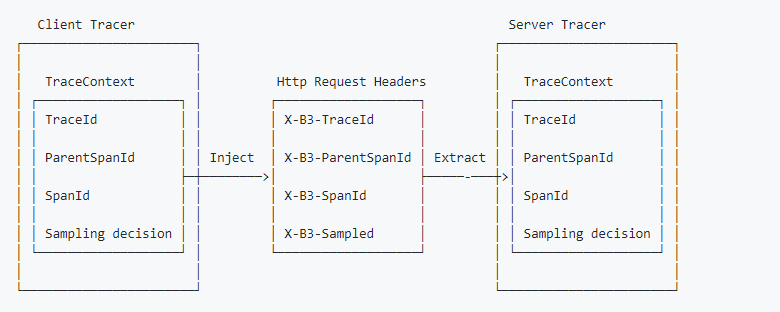
但是為什麼我們沒有在上面的例子中調用這些函數呢?讓我們再來回顧一下代碼。在客戶端,在創建gRPC客戶端連接時,我們調用了一個為「OpenTracingClientInterceptor」的函數。 以下是「OpenTracingClientInterceptor」的部分代碼,我從otgrpc¹¹包中的「client.go」中得到了它。它已經從Go context¹²獲取了跟蹤上下文並將其注入HTTP頭,因此我們不再需要再次調用「inject」函數。
func OpenTracingClientInterceptor(tracer opentracing.Tracer, optFuncs ...Option) grpc.UnaryClientInterceptor { ... ctx = injectSpanContext(ctx, tracer, clientSpan) ... } func injectSpanContext(ctx context.Context, tracer opentracing.Tracer, clientSpan opentracing.Span) context.Context { md, ok := metadata.FromOutgoingContext(ctx) if !ok { md = metadata.New(nil) } else { md = md.Copy() } mdWriter := metadataReaderWriter{md} err := tracer.Inject(clientSpan.Context(), opentracing.HTTPHeaders, mdWriter) // We have no better place to record an error than the Span itself :-/ if err != nil { clientSpan.LogFields(log.String("event", "Tracer.Inject() failed"), log.Error(err)) } return metadata.NewOutgoingContext(ctx, md) }在服務器端,我們還調用了一個函數「otgrpc.OpenTracingServerInterceptor」,其代碼類似於客戶端的「OpenTracingClientInterceptor」。它不是調用「inject」寫入跟蹤上下文,而是從HTTP頭中提取(extract)跟蹤上下文並將其放入Go上下文(Go context)中。 這就是我們不需要再次手動調用「extract()」的原因。 我們可以直接從Go上下文中提取跟蹤上下文(opentracing.SpanFromContext(ctx))。 但對於其他基於HTTP的服務(如RESTFul服務), 情況就並非如此,因此我們需要寫代碼從服務器端的HTTP頭中提取跟蹤上下文。 當然,您也可以使用攔截器或過濾器。
跟蹤庫之間的互兼容性
你也許會問「如果我的程序使用Zipkin和OpenTracing而需要調用的第三方微服務使用OpenTracing與Jaeger,它們會兼容嗎?"它看起來於我們之前詢問的數據庫問題類似,但實際上很不相同。對於數據庫,因為應用程序和數據庫在同一個進程中,它們可以共享相同的全局跟蹤器,因此更容易解決。對於微服務,這種方式將不兼容。因為OpenTracing只標準化了跟蹤接口,它沒有標準化跟蹤上下文。萬維網聯盟(W3C)正在制定跟蹤上下文(trace context)¹⁰的標準,並於2019-08-09年發佈了候選推薦標準。OpenTracing沒有規定跟蹤上下文的格式,而是把決定權留給了實現它的跟蹤庫。結果每個庫都選擇了自己獨有的的格式。例如,Zipkin使用「X-B3-TraceId」作為跟蹤ID,Jaeger使用「uber-trace-id」,因此使用OpenTracing並不意味着不同的跟蹤庫可以進行跨網互操作。 對於「Jaeger」來說有一個好處是你可以選擇使用「Zipkin兼容性功能"¹³來生成Zipkin跟蹤上下文, 這樣就可以與Zipkin相互兼容了。對於其他情況,你需要自己進行手動格式轉換(在「inject」和「extract」之間)。
全鏈路跟蹤設計
盡量少寫代碼
一個好的全鏈路跟蹤系統不需要用戶編寫很多跟蹤代碼。最理想的情況是你不需要任何代碼,讓框架或庫負責處理它,當然這比較困難。 全鏈路跟蹤分成三個跟蹤級別:
-
跨進程跟蹤 (cross-process)(調用另一個微服務)
-
數據庫跟蹤
-
進程內部的跟蹤 (in-process)(在一個函數內部的跟蹤)
跨進程跟蹤是最簡單的。你可以編寫攔截器或過濾器來跟蹤每個請求,它只需要編寫極少的編碼。數據庫跟蹤也比較簡單。如果使用我們上面討論過的封裝器(Wrapper),你只需要註冊SQL驅動程序封裝器(Wrapper)並將go-context(裏面有跟蹤上下文) 傳入數據庫函數。你可以使用依賴注入(Dependency Injection)這樣就可以用比較少的代碼來完成此操作。
進程內跟蹤是最困難的,因為你必須為每個單獨的函數編寫跟蹤代碼。現在還沒有一個很好的方法,可以編寫一個通用的函數來跟蹤應用程序中的每個函數(攔截器不是一個好選擇,因為它需要每個函數的參數和返回都必須是一個泛型類型(interface {}))。幸運的是,對於大多數人來說,前兩個級別的跟蹤應該已經足夠了。
有些人可能會使用服務網格(service mesh)來實現分佈式跟蹤,例如Istio或Linkerd。它確實是一個好主意,跟蹤最好由基礎架構實現,而不是將業務邏輯代碼與跟蹤代碼混在一起,不過你將遇到我們剛才談到的同樣問題。服務網格只負責跨進程跟蹤,函數內部或數據庫跟蹤任然需要你來編寫代碼。不過一些服務網格可以通過提供與流行跟蹤庫的集成,來簡化不同跟蹤庫跨網跟蹤時的的上下文格式轉換。
跟蹤設計:
精心設計的跨度(span),服務名稱(service name),標籤(tag)能充分發揮全鏈路跟蹤的作用,並使之簡單易用。有關信息請閱讀語義約定(Semantic Conventions)¹⁴。
將Trace ID記錄到日誌
將跟蹤與日誌記錄集成是一個常見的需求,最重要的是將跟蹤ID記錄到整個調用鏈的日誌消息中。 目前OpenTracing不提供訪問traceID的方法。 你可以將「OpenTracing.SpanContext」轉換為特定跟蹤庫的「SpanContext」(Zipkin和Jaeger都可以通過「SpanContext」訪問traceID)或將「OpenTracing.SpanContext」轉換為字符串並解析它以獲取traceID。轉換為字符串更好,因為它不會破壞程序的依賴關係。 幸運的是不久的將來你就不需要它了,因為OpenTracing將提供訪問traceID的方法,請閱讀這裡。
OpenTracing 和 OpenCensus
OpenCensus¹⁵不是另一個通用跟蹤接口,它是一組庫,可以用來與其他跟蹤庫集成以完成跟蹤功能,因此它經常與OpenTracing進行比較。 那麼它與OpenTracing兼容嗎?答案是否定的。 因此,在選擇跟蹤接口時(不論是OpenTracing還是OpenCensus)需要小心,以確保你需要調用的其他庫支持它。 一個好消息是,你不需要在將來做出選擇,因為它們會將項目合併為一個¹⁶。
結論:
全鏈路跟蹤包括不同的場景,例如在函數內部跟蹤,數據庫跟蹤和跨進程跟蹤。 每個場景都有不同的問題和解決方案。如果你想設計更好的跟蹤解決方案或為你的應用選擇最適合的跟蹤工具或庫,那你需要對每種情況都有清晰的了解。
源碼:
索引:
[1]Correlation IDs for microservices architectures
https://hilton.org.uk/blog/microservices-correlation-id
[2]Zipkin
https://zipkin.io
[3]Jaeger: open source, end-to-end distributed tracing
https://www.jaegertracing.io
[4]OpenTracing
https://opentracing.io/docs/getting-started
[5]Zipkin Architecture
https://zipkin.io/pages/architecture.html
[6]The OpenTracing Semantic Specification
https://opentracing.io/specification/
[7]instrumentedsql
https://github.com/ExpansiveWorlds/instrumentedsql
[8]luna-duclos/instrumentedsql
https://github.com/luna-duclos/instrumentedsql
[9]ocsql/driver.go
https://github.com/opencensus-integrations/ocsql/blob/master/driver.go
[10]Trace Context
https://www.w3.org/TR/trace-context/
[11]otgrpc
http://github.com/grpc-ecosystem/grpc-opentracing/go/otgrpc
[12]Go Concurrency Patterns: Context
https://blog.golang.org/context
[13]Zipkin compatibility features
https://github.com/jaegertracing/jaeger-client-go/tree/master/zipkin
[14]Semantic Conventions
https://github.com/opentracing/specification/blob/master/semantic_conventions.md
[15]OpenCensus
https://opencensus.io/
[16]merge the project into one
https://medium.com/opentracing/merging-opentracing-and-opencensus-f0fe9c7ca6f0
