內存回收導致關鍵業務抖動案例分析-論雲原生OS內存QoS保障
蔣彪,騰訊雲高級工程師,10+年專註於操作系統相關技術,Linux內核資深發燒友。目前負責騰訊雲原生OS的研發,以及OS/虛擬化的性能優化工作。
導語
雲原生場景,相比於傳統的IDC場景,業務更加複雜多樣,而原生 Linux kernel 在面對雲原生的各種複雜場景時,時常顯得有些力不從心。本文基於一個騰訊雲原生場景中的一個實際案例,展現針對類似問題的一些排查思路,並希望藉此透視Linux kernel的相關底層邏輯以及可能的優化方向。
背景
騰訊雲客戶某關鍵業務容器所在節點,偶發CPU sys(內核態CPU佔用)沖高的問題,導致業務抖動,復現無規律。節點使用內核為upstream 3.x版本。
現象
在業務負載正常的情況下,監控可見明顯的CPU佔用率毛刺,最高可達100%,同時節點load飆升,此時業務會隨之出現抖動。
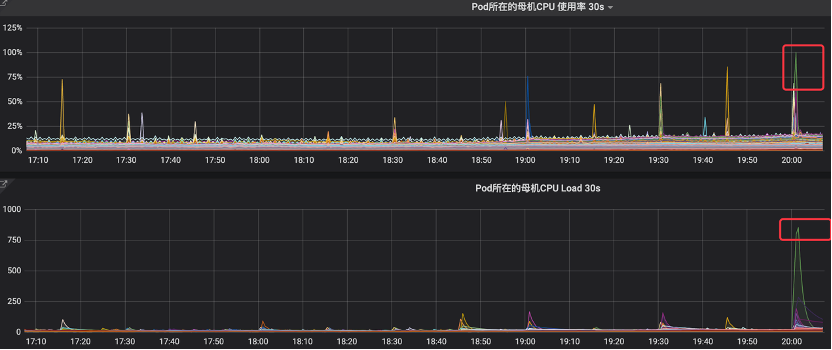
捕獲數據
思路
故障現象為CPU sys沖高,即CPU在內核態持續運行導致,分析思路很簡單,需要確認sys沖高時,具體的執行上下文信息,可以是堆棧,也可以是熱點。
難點:
由於故障出現隨機,持續時間比較短(秒級),而且由於是內核態CPU沖高,當故障復現時,常規排查工具無法得到調度運行,登錄終端也會hung住(由於無法正常調度),所以常規監控(通常粒度為分鐘級)和排查工具均無法及時抓到現場數據。
具體操作
秒級監控
通過部署秒級監控(基於atop),在故障復現時能抓到故障發生時的系統級別的上下文信息,示例如下:
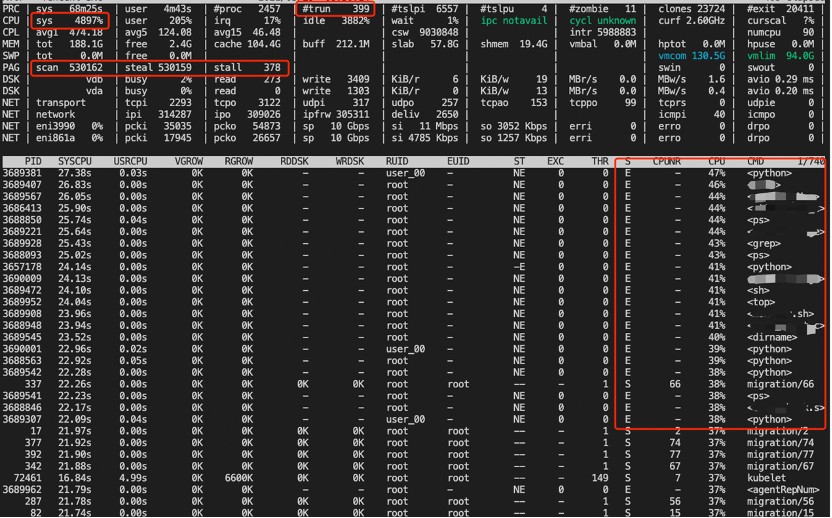
從圖中我們可以看到如下現象:
- sys很高,usr比較低
- 觸發了頁面回收(PAG行),且非常頻繁
- 比如ps之類的進程普遍內核態CPU使用率較高,而用戶態CPU使用率較低,且處於退出狀態
至此,抓到了系統級別的上下文信息,可以看到故障當時,系統中正在運行的、CPU佔用較高的進程和狀態,也有一些系統級別的統計信息,但仍無從知曉故障當時,sys具體消耗在了什麼地方,需要通過其他方法/工具繼續抓現場。
故障現場
如前面所說,這裡說的現場,可以是故障當時的瞬時堆棧信息,也可以是熱點信息。
對於堆棧的採集,直接能想到的簡單方式:
- pstack
- cat /proc/
/stack
當然這兩種方式都依賴:
- 故障當時CPU佔用高的進程的pid
- 故障時採集進程能及時執行,並得到及時調度、處理
顯然這些對於當前的問題來說,都是難以操作的。
對於熱點的採集,最直接的方式就是perf工具,簡單、直接、易用。但也存在問題:
- 開銷較大,難以常態化部署;如果常態化部署,採集數據量巨大,解析困難
- 故障時不能保證能及時觸發執行
perf本質上是通過pmu硬件進行周期性採樣,實現時採用NMI(x86)進行採樣,所以,一旦觸發採集,就不會受到調度、中斷、軟中斷等因素的干擾。但由於執行perf命令的動作本身必須是在進程上下文中觸發(通過命令行、程序等),所以在故障發生時,由於內核態CPU使用率較高,並不能保證perf命令執行的進程能得到正常調度,從而及時採樣。
因此針對此問題的熱點採集,必須提前部署(常態化部署)。通過兩種方式可解決(緩解)前面提到的開銷大和數據解析困難的問題:
- 降低perf採樣頻率,通常降低到99次/s,實測對真實業務影響可控
- Perf數據切片。通過對perf採集的數據按時間段進行切片,結合雲監控中的故障時間點(段),可以準確定位到相應的數據片,然後做針對性的統計分析。
具體方法:
採集:
`.``/perf` `record -F99 -g -a`
分析:
#查看header裏面的captured on時間,應該表示結束時間,time of last sample最後採集時間戳,單位是秒,可往前追溯現場時間
./perf report --header-only
#根據時間戳索引
./perf report --time start_tsc,end_tsc
按此思路,通過提前部署perf工具採集到了一個現場,熱點分析如下:
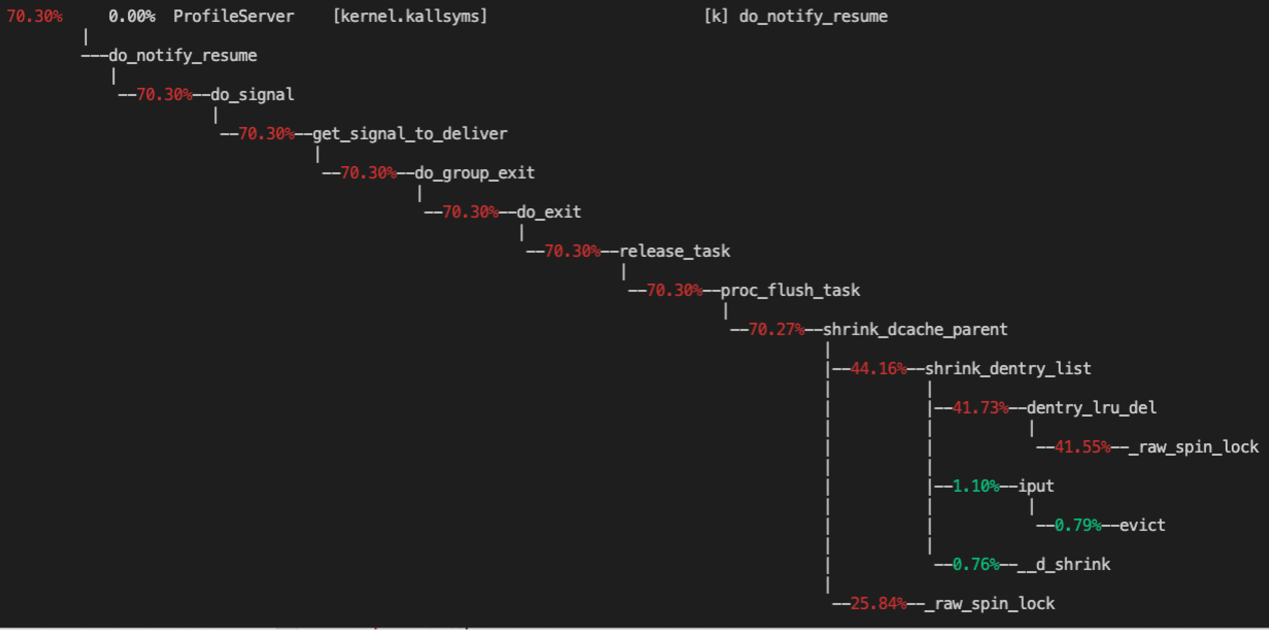
可以看到,主要的熱點在於 shrink_dentry_list 中的一把 spinlock。
分析
現場分析
根據 perf 的結果,我們找到內核中的熱點函數 dentry_lru_del,簡單看下代碼:
// dentry_lru_del()函數:
static void dentry_lru_del(struct dentry *dentry) {
if (!list_empty(&dentry->d_lru)) {
spin_lock(&dcache_lru_lock);
__dentry_lru_del(dentry);
spin_unlock(&dcache_lru_lock);
}
}
函數中使用到的 spinlock 為 dentry_lru_lock,在3.x內核代碼中,這是一把超大鎖(全局鎖)。單個文件系統的所有的 dentry 都放入同一個lru鏈表(位於superblock)中,對該鏈表的幾乎所有操作(dentry_lru_(add|del|prune|move_tail))都需要拿這把鎖,而且所有的文件系統共用了同一把全局鎖(3.x內核代碼),參考 add 流程:
static void dentry_lru_add(struct dentry *dentry) {
if (list_empty(&dentry->d_lru)) {
// 拿全局鎖
spin_lock(&dcache_lru_lock);
// 把dentry放入sb的lru鏈表中
list_add(&dentry->d_lru, &dentry->d_sb->s_dentry_lru);
dentry->d_sb->s_nr_dentry_unused++;
dentry_stat.nr_unused++;
spin_unlock(&dcache_lru_lock);
}
}
由於 dentry_lru_lock 是全局大鎖,可以想到的一些典型場景中都會持這把鎖:
- 文件系統 umount 流程
- rmdir 流程
- 內存回收 shrink_slab 流程
- 進程退出清理/proc目錄流程(proc_flush_task)-前面抓到的現場
其中,文件系統 umount 時,會清理掉對應 superblock 中的所有 dentry,則會遍歷整個 dentry 的lru鏈表,如果 dentry 數量過多,將直接導致 sys 沖高,而且其他依賴於 dentry_lru_lock 的流程也會產生嚴重的鎖競爭,由於是 spinlock,也會導致其他上下文 sys 沖高。
接下來,再回過頭看之前的秒級監控日誌,就會發現故障是系統的 slab 佔用近60G,非常大:

而dentry cache(位於slab中)很可能是罪魁禍首,確認slab中的對象的具體分佈的最簡便的方法:Slabtop,在相同業務集群其他節點找到類似環境,可見確實dentry佔用率絕大部分:
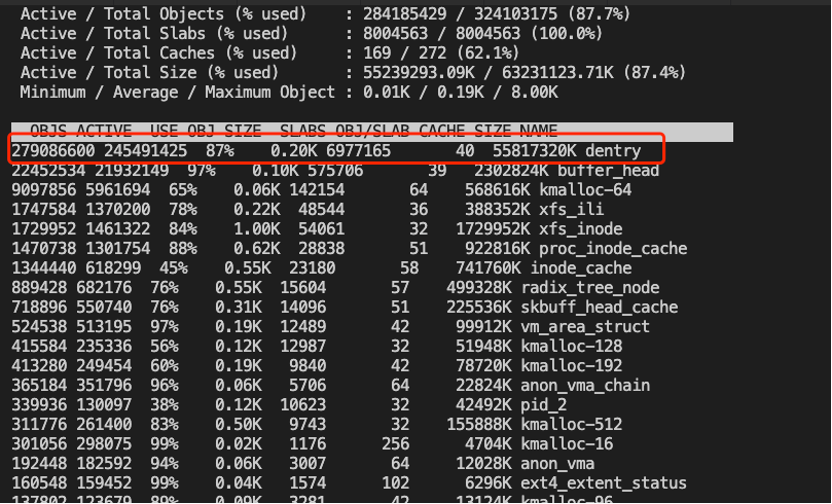
我們接下來可以使用 crash 工具在線解析對應文件系統的 superblock 的 dentry lru 鏈表,可見 unused entry 數量高達2億+
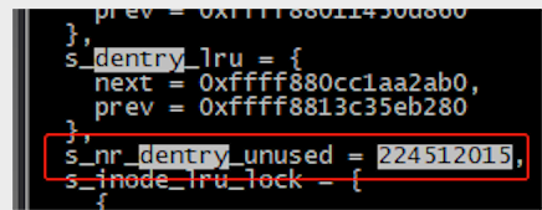
另一方面,根據業務的上下文日誌,可以確認其中一類故障時,業務有刪除 pod 的操作,而刪除pod過程中,會 umount overlayfs,然後會觸發文件系統 umount 操作,然後就出現這樣的現象,場景完全吻合!
進一步,在有 2億+dentry 環境中,手工drop slab並通過time計時,接近40s,阻塞時間也能吻合。
`time` `echo` `2 > ``/proc/sys/vm/drop_caches`
至此,基本能解釋:sys 沖高的直接原因為dentry數量太多。
億級 Dentry 從何而來
接下來的疑問:為何會有這麼多dentry?
直接的解答方法,找到這些dentry的絕對路徑,然後根據路徑反推業務即可。那麼2億+dentry如何解析?
兩種辦法:
方法1:在線解析
通過crash工具在線解析(手工操練),
基本思路:
- 找到sb中的dentry lru list位置
- List所有的node地址,結果存檔
- 由於entry數量過多,可以進行切片,分批保存至單獨文檔,後續可以批量解析。
- Vim列編輯存檔文件,批量插入命令(file),保存為批量執行命令的文件
- crash -i批量執行命令文件,結果存檔
- 對批量執行結果進行文本處理,統計文件路徑和數量
結果示例:

其中:
- db為後面提及的類似xxxxx_dOeSnotExist_.db文件,佔大部分。
- session為systemd為每個session創建的臨時文件
db文件分析如下:
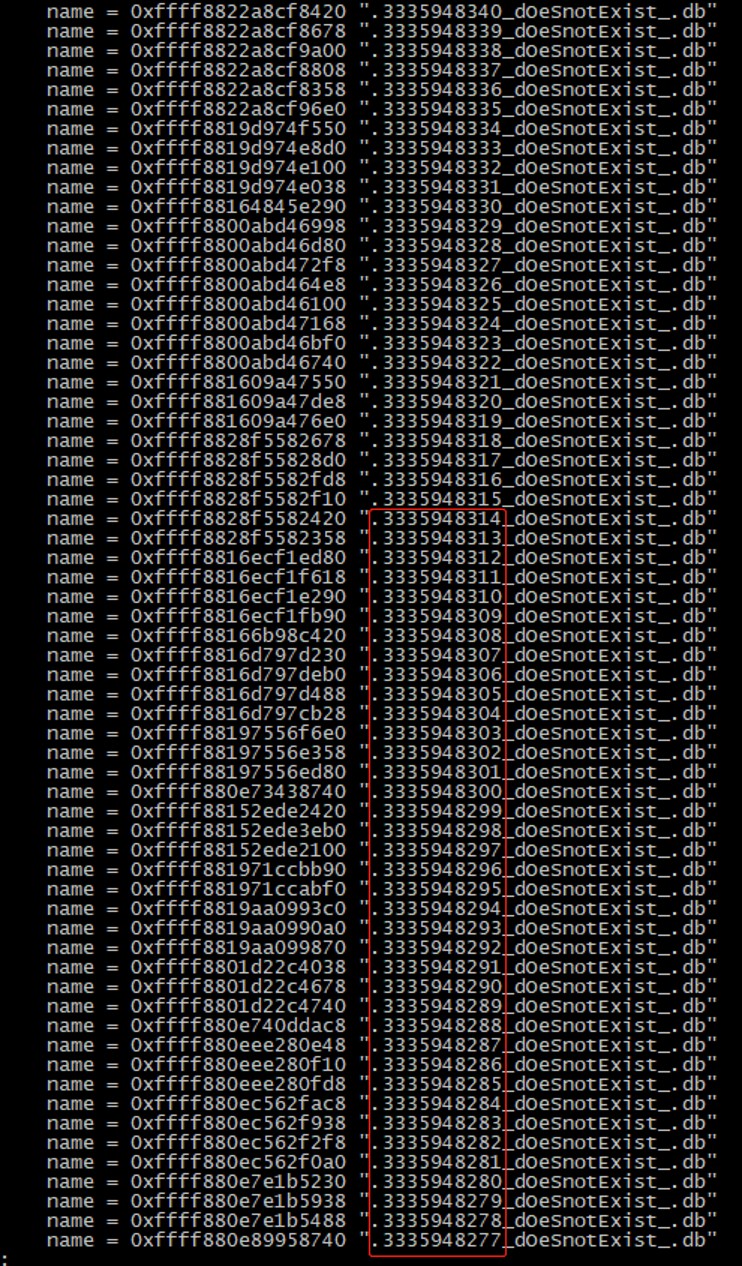
文件名稱有幾個明顯特徵:
- 有統一的計數,可能是某一個容器產生
- 名稱中包含字符串「dOeSnotExist「
- 都擁有.db的後綴
對應的絕對路徑示例如下(用於確認所在容器)


如此可以通過繼續通過 overlayfs id 繼續查找對應的容器(docker inspect),確認業務。
方法2:動態跟蹤
通過編寫 systemtap 腳本,追蹤 dentry 分配請求,可抓到對應進程(在可復現的前提下),腳本示例如下:
probe kernel.function("d_alloc") {
printf("[%d] %s(pid:%d ppid:%d) %s %s\n", gettimeofday_ms(), execname(), pid(), ppid(), ppfunc(), kernel_string_n($name->name, $name->len));
}
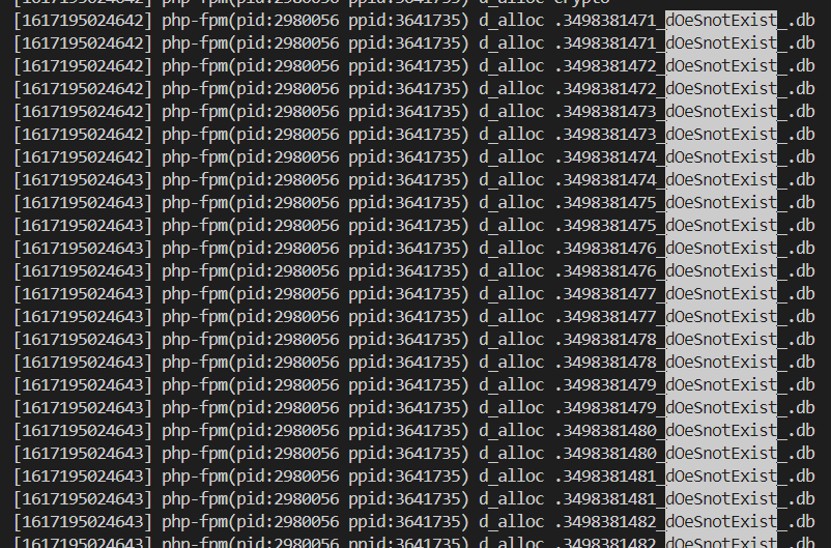
按進程維度統計:
Xxx_dOeSnotExist_.db文件分析
通過前面抓取到的路徑可以判斷該文件與nss庫(證書/密鑰相關)相關,https 服務時,需要使用到底層nss密碼庫,訪問web服務的工具如 curl 都使用到了這個庫,而nss庫存在bug:
//bugzilla.mozilla.org/show_bug.cgi?id=956082
//bugzilla.redhat.com/show_bug.cgi?id=1779325
大量訪問不存在的路徑這個行為,是為了檢測是否在網絡文件系統上訪問 nss db, 如果訪問臨時目錄比訪問數據庫目錄快很多,會開啟cache。這個探測過程會嘗試 33ms 內循環 stat 不存在的文件(最大1萬次), 這個行為導致了大量的 negative dentry。
使用curl工具可模擬這個bug,在測試機中執行如下命令:
`strace` `-f -e trace=access curl ``'//baidu.com'`
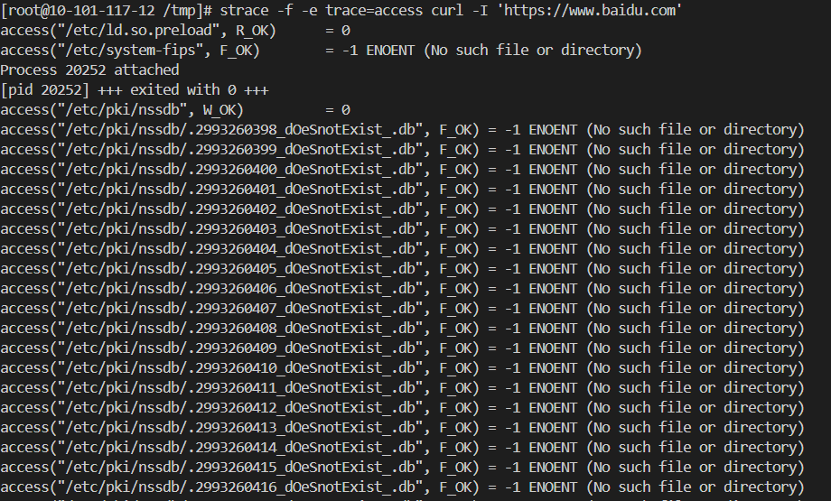
規避方法:設置環境變量 NSS_SDB_USE_CACHE=yes
解決方法:升級 pod 內的 nss 服務
至此,問題分析近乎完成。看起來就是一個由平平無奇的用戶態組件的bug引發的血案,分析方法和手段也平平無奇,但後面的分析才是我們關注的重點。
另一種現象
回想前面講到的 dentry_lru_lock 大鎖競爭的場景,仔細分析其他幾例出現 sys 沖高的秒級監控現場,發現這種場景中並無刪除pod動作(也就是沒有 umount 動作),也就意味着沒有遍歷 dentry lru 的動作,按理不應該有反覆持有 dentry_lru_lock 的情況,而且同時會出現sys沖高的現象。
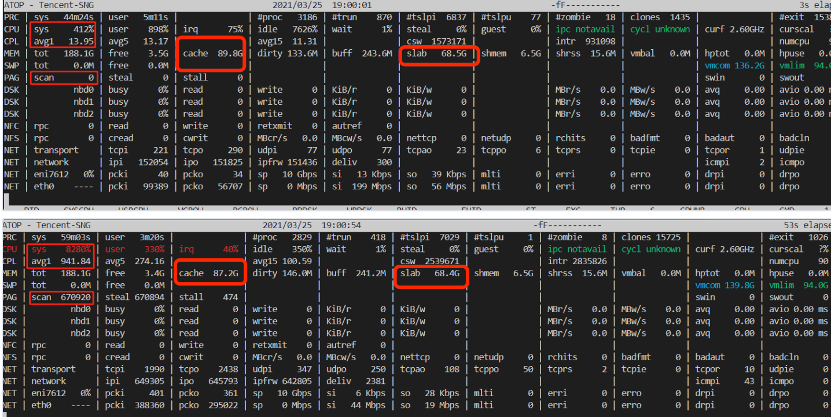
可以看到,故障前後的 cache 回收了2G+,但實際的 free 內存並沒有增加,反而減少了,說明此時,業務應該正在大量分配新內存,導致內存不足,從而導致內存一直處於回收狀態(scan 數量增加很多)。
而在內存緊張進入直接回收後時,會(可能)shrink_slab,以至於需要持 dentry_lru_lock,這裡的具體邏輯和算法不分析了:)。當回收內存壓力持續時,可能會反覆/並發進入直接回收流程,導致 dentry_lru_lock 鎖競爭,同時,在出現問題的業務場景中,單pod進程擁有2400+線程,批量退出時調用 proc_flush_task 釋放/proc目錄下的進程目錄項,從而也會批量/並發獲取 dcache_lru_lock 鎖,加劇鎖競爭,從而導致sys沖高。
兩種現象都能基本解釋了。其中,第二種現象相比於第一種,更複雜,原因在於其中涉及到了內存緊張時的並發處理邏輯。
解決 & 思考
直接解決/規避
基於前面的分析,可以看出,最直接的解決方式為:
升級 pod nss 服務,或者設置設置環境變量規避
但如果再思考下:如果nss沒有 bug,但其他組件也做了類似可能產生大量 dentry 的動作,比如執行類似這樣的腳本:
#!/bin/bash
i=0
while (( i < 1000000 )) ; do
if test -e ./$i; then
echo $i > ./$i
fi
((i++))
done
本質上也會不停的產生 dentry(slab),面對這種場景該怎麼辦?可能的簡便的解決/規避方法是:周期性 drop cache/slab,雖然可能引發偶爾的性能小波動,但基本能解決問題。
鎖優化
前面分析指出,導致 sys 沖高的直接原因是 dcache_lru_lock 鎖的競爭,那這把鎖是否有優化空間呢?
答案是:有
看看3.x內核代碼中的鎖使用:
static void dentry_lru_add(struct dentry *dentry) {
if (list_empty(&dentry->d_lru)) {
//全局鎖
spin_lock(&dcache_lru_lock);
list_add(&dentry->d_lru, &dentry->d_sb->s_dentry_lru);
dentry->d_sb->s_nr_dentry_unused++;
dentry_stat.nr_unused++;
spin_unlock(&dcache_lru_lock);
}
}
可以明顯看出這是個全局變量,即所有文件系統公用的全局鎖。而實際的 dentry_lru 是放在 superblock 中的,顯然這把鎖的範圍跟lru是不一致的。
於是,新內核版本中,果真把這把鎖放入了 superblock 中:
static void d_lru_del(struct dentry *dentry) {
D_FLAG_VERIFY(dentry, DCACHE_LRU_LIST);
dentry->d_flags &= ~DCACHE_LRU_LIST;
this_cpu_dec(nr_dentry_unused);
if (d_is_negative(dentry)) this_cpu_dec(nr_dentry_negative);
//不再加單獨的鎖,使用list_lru_del原語中自帶的per list的lock
WARN_ON_ONCE(!list_lru_del(&dentry->d_sb->s_dentry_lru, &dentry->d_lru));
}
bool list_lru_add(struct list_lru *lru, struct list_head *item) {
int nid = page_to_nid(virt_to_page(item));
struct list_lru_node *nlru = &lru->node[nid];
struct mem_cgroup *memcg;
struct list_lru_one *l;
//使用per lru list的lock
spin_lock(&nlru->lock);
if (list_empty(item)) {
// …
}
spin_unlock(&nlru->lock);
return false;
}
`
新內核中,棄用了全局鎖,而改用了 list_lru 原語中自帶的 lock,而由於 list_lru 自身位於 superblock 中,所以,鎖變成了per list(superblock)的鎖,雖然還是有點大,但相比之前減小了許多。
所以,新內核中,對鎖做了優化,但未必能完全解決問題。
繼續思考1
為什麼訪問不存在的文件/目錄(nss cache和上述腳本)也會產生 dentry cache 呢?一個不存在的文件/目錄的 dentry cache 有何用處呢?為何需要保留?表面看,看似沒有必要為一個不存在的文件/目錄保留 dentry cache。其實,這樣的 dentry cache(後文簡稱dcache)在內核中有標準的定義:Negative dentry
`A special form of dcache entry gets created ``if` `a process attempts to access a non-existent ``file``. Such an entry is known as a negative dentry.`
Negative dentry 具體有何用途?由於 dcache 的主要作用是:用於加快文件系統中的文件查找速度,設想如下場景:如果一個應用總是從一些預先配置好的路徑列表中去查找指定文件(類似於 PATH 環境變量),而且該文件僅存在與這些路徑中的一個,這種情況下,如果存在 negative dcache,則能加速失敗路徑的查找,整體提升文件查找的性能。
繼續思考2
是否能單獨限制 negative dcache 的數量呢?
答案是:可以。
Rhel7.8版本內核中(3.10.0-1127.el7),合入了一個 feature:negative-dentry-limit,專門用來限制 negative dcache 的數量,關於這個 feature 的說明請參考:
//access.redhat.com/solutions/4982351
關於 feature 的具體實現,請參考:
//lwn.net/Articles/813353/
具體原理就不解釋了:)
殘酷的現實是:rhel8和upstream kernel都沒有合入這個feature,為啥呢?
請參考:
Redhat 的官方解釋(其實並沒有解釋清楚)
//access.redhat.com/solutions/5777081
再看看社區的激烈討論:
//lore.kernel.org/patchwork/cover/960253/
Linus 也親自站出來反對。整體基調是:現有的 cache reclaim 機制已經夠用(夠複雜了),再結合 memcg 的 low 水線等保護措施(cgroup v2才有哦),能處理好 cache reclaim 的活,如果限制的話,可能會涉及到同步回收等,引入新阻塞、問題和不必要的複雜,negative dache 相比於普通的 pagecache 沒有特別之處,不應該被區別對待(被優待),而且 negative dcache 本身回收很快,balabala。
結果是,還是不能進社區,儘管這個功能看起來是如此「實用」。
繼續思考3
還有其他方式能限制 dcache 嗎?
答案是:還有
文件系統層,提供了 unused_dentry_hard_limit 參數,可以控制 dcache 的整體數量,整體控制邏輯類似。具體代碼原理也不贅述了,歡迎大家查閱代碼。
遺憾的是,該參數依賴於各文件系統自身實現,3.x內核中只看到 overlayfs 有實現,其他文件系統沒有。所以,通用性有所限制,具體效果未知(未實際驗證)。
至此,看似真的已經分析清楚了?
Think More
能否再思考一下:為什麼 dentry 數量這麼多,而沒有被及時回收呢?
當前案例表面上看似一個有應用(nss)bug引發的內核抖動問題,但如果仔細思考,你會發現這其實還是內核自身面對類似場景的能力不足,其本質問題還在於:
- 回收不及時
- cache 無限制
回收不及時
由於內核中會將訪問過的所有文件(目錄)對應的 dentry 都緩存起來存於slab中(除非有特性標記),用於下次訪問時提示效率,可以看到出問題的環境中,slab佔用都高達60G,其中絕大部分都是 dentry 佔用。
而內核中,僅(絕大部分場景)當內存緊張時(到達內存水線)才會觸發主動回收cache(主要包括slab和pagecache),而問題環境中,內存通常很充足,實際使用較少,絕大部分為緩存(slab和pagecache)。
當系統free內存低於low水線時,觸發異步回收(kswapd);當 free 內存低於 min 水線是觸發同步回收。也就是說僅當free內存低到一定程度(水線)時才能開始回收 dentry,而由於水線通常較低,導致回收時機較晚,而當業務有突發內存申請時,可能導致短期內處於內存反覆回收狀態。
註:水線(全局)由內核默認根據內存大小計算的,upstream內核中默認的水線比較低。在部分容器場景確實不太合理,新版本內核中有部分優化(可以設置min和low之間的距離),但也不完美。
Memcg async reclaim
在雲原生(容器)場景中,針對cache的有效、及時回收,內核提供了標準異步回收方式:到達low水線後的 kswapd 回收,但 kswapd 是per-node粒度(全局),即使在調大 min 和 low 水線之間的 distance 之後(高版本內核支持),仍存在如下不足:
- distance 參數難以通用,難以控制
- 全局掃描開銷較大,比較笨重
- 單線程(per-node)回收,仍可能較慢,不及時
在實際應用中,也常見因為內存回收不及時導致水線被擊穿,從而出現業務抖動的問題。針對類似場景的問題,社區在多年前有人提交了 memcg async relaim 的想法和補丁(相對原始),基本原理為:為每個 pod (memcg)創建一個類似 kswapd 這樣的內存異步回收線程,當pod級別的 async low 水線達到後,觸發 per-cgroup 基本的異步內存回收。理論上也能比較好的解決/優化類似場景的問題。但最終經過長時間討論後,社區最終沒有接受,主要原因還是出於容器資源開銷和 Isolation 的考慮:
- 如果為每個 cgroup 創建一個內核線程,當容器數量較多時,內存線程數量增多,開銷難以控制。
- 後續優化版本去除了 per-cgroup 的內核回收線程,而借用於內核自帶的 workqueue 來做,由於 workqueue 的池化能力,可以合併請求,減少線程線程創建數量,控制開銷。但隨之而來的是隔離性(Isolation)的問題,問題在於新提交的 workqueue 請求無法 account 到具體的 pod(cgroup),破壞了容器的隔離性。
從Maintainer的角度看,拒絕的理由很充分。但從(雲原生)用戶的角度看,只能是再次的失落,畢竟實際的問題並未得到真正充分解決。
雖然 memcg async reclaim 功能最終未能被社區接受,但仍有少數廠商堅持在自己的版本分支中合入了相應功能,其中的典型代表如 Google,另外還包括我們的 TencentOS Server (原TLinux),我們不僅合入/增強了原有的 memcg async reclaim 功能,還將其整體融入了我們的雲原生資源 QoS 框架,整體為保證業務的內存服務質量提供底層支撐。
cache 無限制
Linux 傾向於盡可能將空閑內存利用起來,用做cache(主要是page cache和slab),用於提升性能(主要是文件訪問)。意味着系統中 cache 可以幾乎不限制(只要有free內存)的增長。在現實場景中帶來不少的問題,本案例中的問題就是其中一種典型。如果有 cache limit 能力,理論上能很大程度解決類似問題。
Cache limit
而關於page cache limit話題,多年前曾在 Kernel upstream 社區中持續爭論了很長一段時間,但最終還是未能進入upstream,主要原因還在於違背了盡量利用內存的初衷。儘管在一些場景中確實存在一些問題,社區仍建議通過其他方式解決(業務或者其他內核手段)。
雖然社區未接受,但少部分廠商還是堅持在自己的版本分支中合入了 page cache limit 功能,其中典型代表如SUSE,另外還包括我們的 TencentOS Server(原TLinux),我們不僅合入/增強了 page cache limit 功能,支持同步/異步回收,同時還增強了 slab limit 的限制,可以同時限制 page cache 和 slab 的用量。該功能在很多場景中起到了關鍵作用。
結論
- 在如下多個條件同時發生時,可能出現 dentry list 相關的鎖競爭,導致sys高:
- 系統中存在大量dentry緩存(容器訪問過的大量文件/目錄,不停累積)
- 業務突發內存申請,導致free內存突破水線,觸發內存回收(反覆)
- 業務進程退出,退出時需要清理/proc 文件,期間依賴於 dentry list 的大鎖,出現 spinlock race。
- 用戶態應用 nss bug 導致 dcache 過多,是事故的直接原因。
- 深層次思考,可以發現,upstream kernel 為考慮通用性、架構優雅等因素,放棄了很多實用功能和設計,在雲原生場景中,難以滿足極致需求,要成為雲原生OS的核心底座,還需要深度hack。
- TencentOS Server 為雲原生海量場景做了大量深度定製和優化,能自如應對複雜、極端雲原生業務帶來各種挑戰(包括本案例中涉及的問題)。此外,TencentOS Server 還設計實現了雲原生資源 QoS 保障特性(RUE),為不同優先級的容器提供了各種關鍵資源的 QoS 保障能力。敬請期待相關分享。
結語
在雲原生場景中,upstream kerne l難以滿足極端場景的極致需求,要成為雲原生OS的底座,還需要深度hack。而 TencentOS Server 正為之不懈努力!
【註:案例素材取自騰訊雲虛擬化團隊和雲技術運營團隊】
容器服務(Tencent Kubernetes Engine,TKE)是騰訊雲提供的基於 Kubernetes,一站式雲原生 PaaS 服務平台。為用戶提供集成了容器集群調度、Helm 應用編排、Docker 鏡像管理、Istio服務治理、自動化DevOps以及全套監控運維體系的企業級服務。


