用C/C++手撕CPlus語言的集成開發環境(1)—— 語言規範 + 詞法分析器
序言
之所以叫做CPlus語言,是因為原本是想起名為CMinus的,結果發現GitHub和Gitee上一堆的CMinus的編譯器(想必都是開過編譯原理課程並且寫了個玩具級的語言編譯器的大佬們吧)。但是CPlus相較於C多了一些東西,而相較於C++又少了一些東西,又有點C#的影子,而且並不嚴格遵守編譯原理課本上的CMinus標準,所以暫且取個中間值,就叫C+(CPlus,反正目前還沒人用,那我就抱走了)。
在開始之前,老規矩:
-
如果覺得這篇文章可以幫到你,歡迎一鍵三連(點贊,收藏,打賞(這一項只適用於在CSDN上))或者star和watch我的GitHub博客。
-
如果想要幫忙宣傳一下,當然歡迎,不過還請轉載標明出處。
-
我使用的C/C++ IDE是Microsoft Visual Studio 2017 Community(以下簡稱VS2017),WinSDK是10.0.17763.0。不過由於WinSDK造成的Bug在這種軟件上並不致命。所以暫時忽略。
那麼,好戲開場!(打響指)
1. 理論
在直接開始手撕CPlus的IDE之前,我們需要預先定義好CPlus的一些基礎規則,當然,不是全部,因為在後面的話可能還是會像C++標準一樣每隔一段時間就添加上那麼億點點細節。首先,說明一下CPlus和普通的C/C++有什麼區別,這樣或許更直觀些:
-
CPlus支持面向對象編程,但不會像C++那樣支持多繼承,在這點上和目前主流的Java以及C#保持一致。當然,類與結構體中的成員有兩種展現方式:public以及private。
-
關於比較惱人的指針問題,CPlus並不允許在基礎數據類型(整型,浮點,布爾值等)上使用指針。但是,為了使CPlus更好的契合設計模式,允許在自定義結構體以及類類型里使用指針。而且在對象的生命周期結束後會自動回收(這一點有點兒難,不過這只是目前設想)。
-
稍微有點C/C++基礎的各位都知道,在C++ 20標準之前,頭文件一直是一個比較頭疼的存在,尤其在VS上,加載速度慢以及 「LNK2019」 是常客,雖說前向聲明可以解決不少問題,但還是有些力不從心(尤其是前向聲明標準庫的那些『大爺們』)。CPlus吸取了C++ 20以及C#的包導入優點,使用import關鍵字作為外部導入關鍵字。
-
採用了多種長度的int類型:int8、int16、int32、int64以及相應的uint(無符號整型)。
接下來,就是定義CPlus里的關鍵字、運算符、界符、標識符相關的定義了,以便在編寫詞法分析器中起作用。
- 關鍵字:
"int8", "int16", "int32", "int64",
"uint8", "uint16", "uint32", "uint64",
"float", "double", "bool", "char",
"void", "if", "else", "switch",
"case", "break", "continue", "while",
"for", "return", "struct", "class",
"public", "private", "import", "true",
"false", "default"
和C/C++沒多大區別,少了#include以及#define等預處理器指令關鍵字,增加了import關鍵字。
- 運算符:
"+", "-", "*", "/", ">",
"<", "=", ">=", "<=", "==",
"!", "!=", "&&", "||", "&",
"|", ":", "::", "+=", ".", ","
這沒什麼可說的
-
界符:” ” “, “{“, “}”, “(“, “)”, “[“, “]”, “;”
-
數字:阿拉伯數字0 ~ 9,支持浮點數以及帶正負號的數。
-
標識符:同C/C++一致,支持下劃線作為標識符,同時支持字母與數字的組合作為標識符,但不允許以數字為開始字符。
-
注釋:支持多行注釋,但目前只支持” /**/ “注釋符。
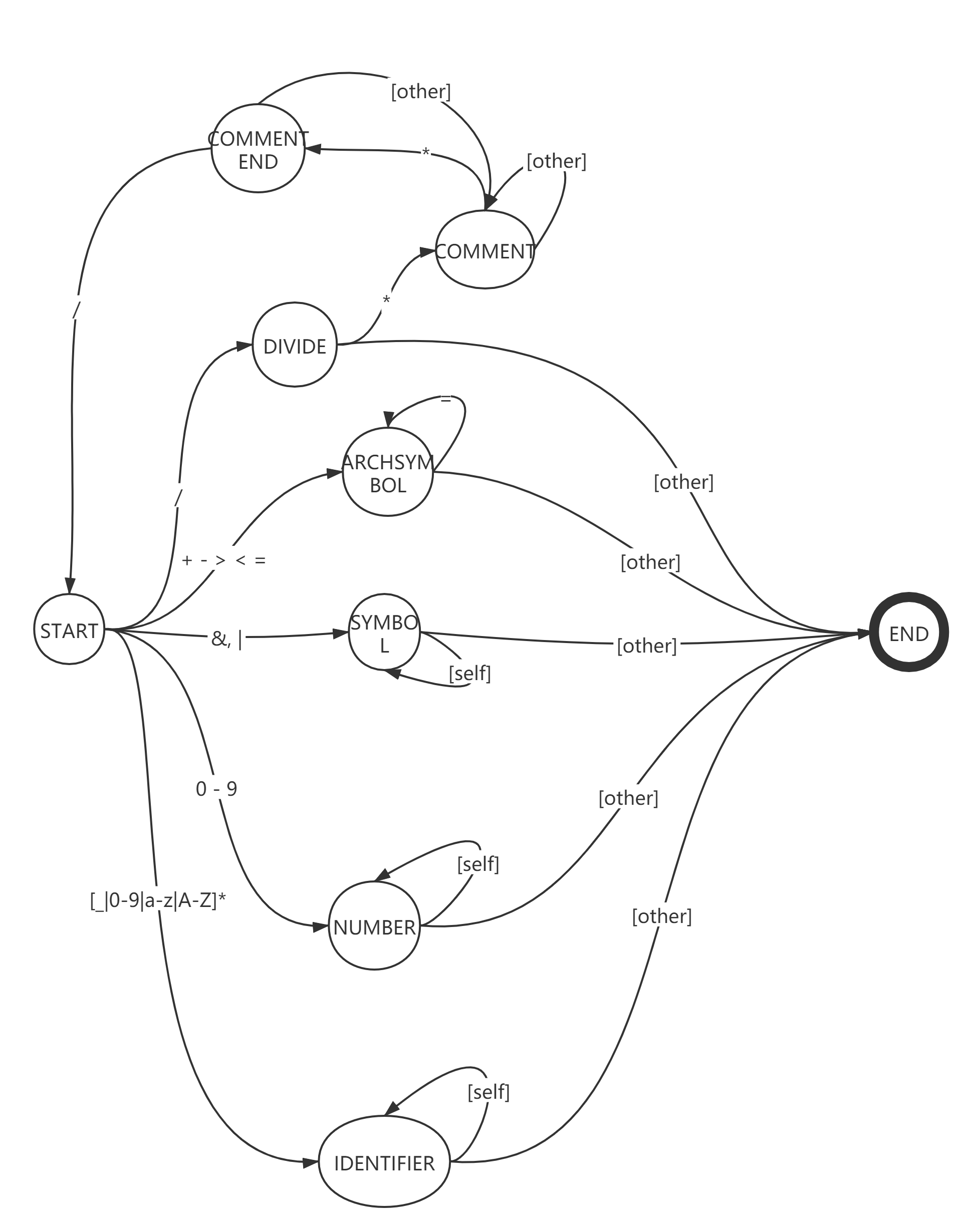
在上述這些基礎定義完後,我們便可以開始定義詞法分析器了,對於詞法分析器的構建,我們可以用多種方法:使用現成輔助工具生成相關代碼(著名的有JavaCC)、採用一大堆的if-else語句對讀入的每個字符做一次判斷、或者親手構建一個符合CPlus詞法的DFA。從方便性上來說,第一種方法是最不錯的選擇,但咱們是手撕,所以不做考慮。而且由於一大堆的if-else語句邏輯結構實在太過複雜,想用if-else實現樹狀結構實屬愚蠢,所以,也就剩下最後一條路——構建符合CPlus詞法的DFA。話不多說,先上圖:
接下來開始解釋:
所有的狀態機都是一致的,均具備開始以及結束節點,還記得我在講虛幻引擎AI系統的時候說過的行為樹么?那也是一種狀態機,同樣具備開始和結束節點,只不過被隱藏掉了而已。雖說叫做狀態機,但DFA全名為deterministic finite automata(確定狀態的有窮自動機),實際上應該算是狀態機的一個子集,虛幻引擎AI行為樹也屬於DFA,因為每種狀態的觸發都是有不同條件的,遵循着一對一原則。當DFA讀入一個字符時,如果處於開始狀態,那麼會根據給出字符在ASCII對應的位置來鎖定下一個應該到達的狀態,以符號「斜線」為例,當DFA遇到讀入字符為「斜線」時,會徑直進入DIVIDE狀態,在這時若狀態機接受的下一個字符為星號時,那麼便會進入COMMENT狀態,若接收的是除星號以外的任意字符,那麼便會將此「斜線」符號作為一個token保存起來,並以DIVIDE標記這個token,在以後的語法解析過程中當語法解析器遇到它後會說「啊,原來這是一個除號(DIVIDE)」。
當然,上圖只是我為了解釋DFA在真實計算機編程語言編譯過程中詞法解析的原理而畫的一個簡易的DFA,與真實的CPlus語言的DFA有一部分不一致的地方,有了基礎的DFA思想以後,接下來就要開始手撕詞法分析器部分了。當然,如何通過字符串流操作將文本代碼存入內存的方法我就不再贅述,直接開始詞法分析器部分。Talk is cheap and show me the code.
2. 詞法分析器
2.1 DFA定義
在講解虛幻引擎AI行為樹時,我們用到了枚舉類型來實現Agent的狀態切換,枚舉是個好東西,在代碼層級上實現這一類的自動機也的確是要用到「enum + switch」來進行實現。(什麼?構建網狀數據結構來表示DFA?在C/C++里太麻煩了吧。你用的是JavaScript?哦那沒事了。)
接下來展示一下DFA狀態:
enum lexerDFAStatus
{
DFA_SLEEP,
DFA_START,
DFA_SYMBOL,
DFA_COMMENT,
DFA_NUM,
DFA_IDENTIFIER,
DFA_END
};
一共有七種:睡眠(DFA_SLEEP),開始(DFA_START),符號(DFA_SYMBOL),注釋(DFA_COMMENT),數字(DFA_NUM),標識符(DFA_IDENTIFIER),結束(DFA_END)。
其中,睡眠指的是在詞法分析器對象在構造函數里初始化狀態機的時候用的,沒什麼特別的意義。開始和結束我不再過多說明,上面有提到。符號的話,就是在DFA遇到除52個大小寫字母,0-9以及非法符號外的所有符號後跳躍到的狀態。注釋是指在DFA遇到了形如「/**/」的符號後進入的狀態,此時在注釋範圍內的所有符號,DFA一概不讀取。數字指在DFA遇到了0-9的數後進入的狀態,當然在數字中間遇到了「.」也會將其歸為數字範疇,畢竟是小數啊。標識符就是標識符,不解釋。當然,在注釋之外遇到了非法符號(比如『……,¥,%,@,#』)會自動拋出異常並停止接下來的編譯流程。
然後聰明又可愛的觀眾們就會問了,說:永樂,你為什麼沒有給關鍵字和標識符做區分呢?這其實不是什麼問題,還請往後看。
2.2 token定義
本人計劃使用單向鏈表來實現token對象的存儲,相關定義如下:
/*
CPlus_CORE_API 可以無視掉,這是為了將tokenType開放出去,由於本編譯器是以
dll動態鏈接庫表現的,在使用時直接掛載即可,這也是為了考慮到IDE開發中
需要重複調用編譯器的某項功能的情況(我總不可能把編譯器和IDE寫進一個項目里吧,耦合度可是很高的),
而封裝成可運行二進制.exe文件時就沒有這麼自由了。關於dll的生成與調用,
敬請參閱我的《從新建文件夾開始構建UtopiaEngine(1)》文章,裏面有詳細介紹。
*/
enum CPlus_CORE_API tokenType
{
NOTHING,
KEYWORD,
SYMBOL,
DELIMITER,
NUMBER,
IDENTIFIER
};
struct lexerTokenData
{
tokenType tkt;
std::string value;
int rowLoc;
lexerTokenData() : tkt(NOTHING), value("Start node"), rowLoc(-1)
{
// Nothing.
}
void setToken(tokenType _tkt, std::string _value, int _rowLoc)
{
this->tkt = _tkt;
this->value = _value;
this->rowLoc = _rowLoc;
}
};
// This is struct for token Node.
struct lexerToken
{
lexerTokenData tokenSave;
lexerToken* nextNode;
lexerToken()
{
this->nextNode = nullptr;
}
};
tokenType指的是這則token所用的類型,有這麼幾種:NOTHING(啥也不是),KEYWORD(關鍵字),SYMBOL(合法符號),DELIMITER(界符),NUMBER(數字),IDENTIFIER(標識符)。和DFA狀態定義一樣,NOTHING只是為了方便構造函數初始化用的。
lexerTokenData是對要存儲進token的數據做一個整合,其中存儲了token的類型,token的值以及token所在的行數(話說行數這個東西在現在看來貌似沒什麼用,在以後的語法分析器中我會提及),lexerToken也就是存儲token所用的鏈表結點的結構定義了。(什麼?你還不知道結構體里可以寫成員函數?敬請參閱C++ 11標準哦親)
2.3 開始構建
必要的前置說明已經在上文中提過,直接上代碼吧:
for (int i = 0; i < this->codeStr.size(); i++)
{
codeChar = this->codeStr[i];
if (this->DFA != DFA_COMMENT)
{
if ((codeChar >= '0') && (codeChar <= '9') && (this->DFA != DFA_NUM) && (this->DFA != DFA_IDENTIFIER)) { this->DFA = DFA_NUM; }
else if ((codeChar >= '0') && (codeChar <= '9') && (this->DFA == DFA_NUM));
else if ((codeChar >= '0') && (codeChar <= '9') && (this->DFA == DFA_IDENTIFIER));
else if ((codeChar >= 'a') && (codeChar <= 'z') && (this->DFA != DFA_IDENTIFIER) && (this->DFA == DFA_NUM))
{
ConsoleLog::PrintLog(COMPILER_LOG, CPCE_0003, CPCW_0000, "The identifier cannot start by number");
throw std::exception();
}
else if ((codeChar >= 'a') && (codeChar <= 'z') && ((this->DFA != DFA_IDENTIFIER))) { this->DFA = DFA_IDENTIFIER; }
else if ((codeChar >= 'A') && (codeChar <= 'Z') && (this->DFA != DFA_IDENTIFIER) && (this->DFA == DFA_NUM))
{
ConsoleLog::PrintLog(COMPILER_LOG, CPCE_0003, CPCW_0000, "The identifier cannot start by number");
throw std::exception();
}
else if ((codeChar >= 'A') && (codeChar <= 'Z') && ((this->DFA != DFA_IDENTIFIER))) { this->DFA = DFA_IDENTIFIER; }
else if ((codeChar >= 'a') && (codeChar <= 'z') && ((this->DFA == DFA_IDENTIFIER)));
else if ((codeChar >= 'A') && (codeChar <= 'Z') && ((this->DFA == DFA_IDENTIFIER)));
else if (codeChar == '_') { this->DFA = DFA_IDENTIFIER; }
else if ((codeChar == '/') && (this->codeStr[i + 1] == '*')) { this->DFA = DFA_COMMENT; }
else if ((codeChar == ' ') || (codeChar == '\n'))
{
switch (this->DFA)
{
case DFA_NUM:
this->tokenLLNodeAdd(NUMBER, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_END;
break;
case DFA_IDENTIFIER:
{
if (this->isKeyword(subCodeStr))
{
this->tokenLLNodeAdd(KEYWORD, subCodeStr, rowNum);
subCodeStr.clear();
}
else
{
this->tokenLLNodeAdd(IDENTIFIER, subCodeStr, rowNum);
subCodeStr.clear();
}
}
this->DFA = DFA_END;
break;
case DFA_COMMENT:
this->DFA = DFA_COMMENT;
break;
default:
break;
}
if (codeChar == '\n') { rowNum += 1; }
}
else if ((codeChar == '.') && (this->DFA == DFA_NUM));
else if (codeChar == '\t');
else
{
if (this->DFA == DFA_IDENTIFIER)
{
if (this->isKeyword(subCodeStr))
{
this->tokenLLNodeAdd(KEYWORD, subCodeStr, rowNum);
subCodeStr.clear();
}
else
{
this->tokenLLNodeAdd(IDENTIFIER, subCodeStr, rowNum);
subCodeStr.clear();
}
this->DFA = DFA_SYMBOL;
}
else if(this->DFA == DFA_NUM)
{
this->tokenLLNodeAdd(NUMBER, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_SYMBOL;
}
else if (this->DFA == DFA_COMMENT)
{
// Nothing.
}
else
{
this->DFA = DFA_SYMBOL;
}
}
}
else if (codeChar == '\n')
{
rowNum += 1;
}
switch (this->DFA)
{
case DFA_SYMBOL:
{
subCodeStr += codeChar;
if (this->isSymbol(subCodeStr))
{
subCodeStr += codeStr[i + 1];
if (this->isSymbol(subCodeStr))
{
i += 1;
this->tokenLLNodeAdd(SYMBOL, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_START;
}
else
{
subCodeStr.clear();
subCodeStr += codeChar;
this->tokenLLNodeAdd(SYMBOL, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_START;
}
}
else if (this->isDelimiter(subCodeStr))
{
this->tokenLLNodeAdd(DELIMITER, subCodeStr, rowNum);
subCodeStr.clear();
this->DFA = DFA_START;
}
else if (this->DFA != DFA_IDENTIFIER)
{
ConsoleLog::PrintLog(COMPILER_LOG, CPCE_0003, CPCW_0000, "You are use the unknown invalid symbol. This symbol is not supported at present.");
this->tokenLLDelete();
throw std::exception();
}
}
break;
case DFA_NUM:
subCodeStr += codeChar;
break;
case DFA_IDENTIFIER:
subCodeStr += codeChar;
break;
case DFA_COMMENT:
{
if ((codeChar == '*') && (this->codeStr[i + 1] == '/')) {
i += 1;
this->DFA = DFA_START;
}
}
break;
case DFA_END:
this->DFA = DFA_START;
break;
default:
break;
}
}
額,這的確有點多,一行行解釋怕是各位也是聽到了後面就忘了前面的,這樣吧,我用幾個實例帶入進行說明,希望可以讓各位理解。接下來會用到行號,還煩請各位將這段代碼粘貼到NotePad++或者VSCode上方便閱讀,在開始舉例前,先對代碼結構進行說明:
整個代碼有一個外圍大循環,主要是對每個讀入的字符對號入座進行處理的。大循環里的步驟大致分為:分配狀態(第4行至第24行) -> 保持狀態加入子串(第98行至第155行) -> 打包token並分配token類型(凡是你能看到的this->tokenLLNodeAdd() 都是)。
好的,上實例:
-
我們先以關鍵字 「int8」 為例,此時DFA狀態為DFA_START,當我們的讀入指針codeChar到達了字符 「i」 時,DFA會先進入一個if判斷,即判斷當前DFA是否處在DFA_COMMENT狀態,若是,那麼跳至第93行進行接下來的處理,關於注釋的處理我們稍後在講。但此時狀態並不是DFA_COMMENT,所以進行接下來的處理。根據要求會執行第14行的條件判斷內的處理語句,將DFA狀態設置為DFA_IDENTIFIER。完成後會跳至第98行進行狀態判斷,由於此時狀態為DFA_IDENTIFIER,所以執行第140行語句,即向子串加入字符 「i」 。此時DFA會將DFA_IDENTIFIER狀態保留並再次跳至大循環即從第3行再次讀入下一個字符 「n」 。按照上面的邏輯循環若干次後來到了 「8」 ,此時DFA的狀態是DFA_IDENTIFIER,這時滿足第8行要求,無狀態轉換語句,即保持原有狀態。接下來進入第139行將「8」錄入子串中,按照普通編程習慣以及語法規定,此時若要結束,必須要有一個空格或者換行符來隔開本標識符和下一個符號。假設是空格,此時DFA會轉至第25行進行token錄入操作。由於此時狀態在DFA_IDENTIFIER中,則跳至第35行開始錄入。在本文剛開始有一個問題即關於標識符和關鍵字的問題,這裡便給出解決方法:由於子串中的 「int8」 屬於關鍵字,則第37行判斷返回結果為真,那麼這個token便會被創建並被標識為 「KEYWORD(關鍵字)」 ,DFA的狀態也轉換為DFA_END,在循環結束後回到DFA_START狀態以便讀取別的標識符以及別的文件內容。
-
接下來舉一個關於注釋的例子:「/* abcdefgh(這裡有個換行符)+=*@#$%^ */」,在開始時,DFA狀態為DFA_START,這時會進入第四行所在的條件判斷內,接下來跳至第24行並將狀態轉換為DFA_COMMENT。此時會再次跳回循環開始處。若讀取到換行符則會跳至第93行為行數加一,所以至少在CPlus語言中,向注釋中加入 「\n」 形式的換行符且真實語義上並未換行的做法是非法的,只支持回車的隱式換行符。接下來若遇到了 「*」 以及 「/」 符號,則跳至第142行為序號i加1以跳過「/」符號。並將DFA狀態切換為DFA_START,以準備下一階段的讀取。
3. 運行
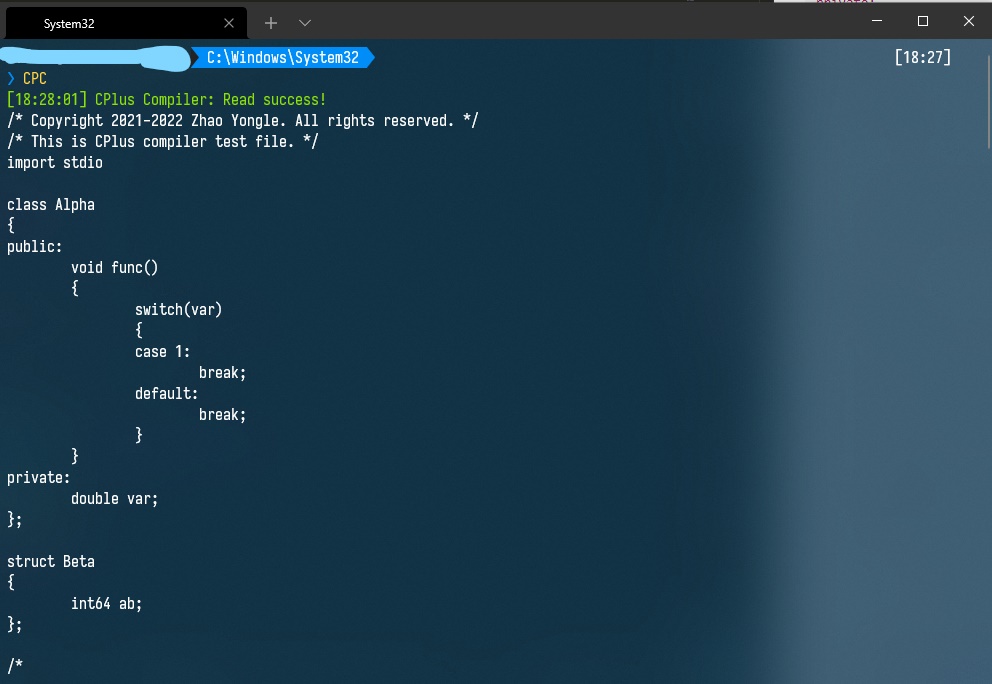
將項目生成的詞法分析器用於解析下面的 .cpc(CPlus Code) 文件:
/* Copyright 2021-2022 Zhao Yongle. All rights reserved. */
/* This is CPlus compiler test file. */
import stdio
class Alpha
{
public:
void func()
{
switch(var)
{
case 1:
break;
default:
break;
}
}
private:
double var;
};
struct Beta
{
int64 ab;
};
/*
Multiline comment 1,
Multiline comment 2,
Multiline comment 3.
*/
int8 main()
{
if(true)
{
print("Hello, world!");
}
else if(false)
{
/* Nothing */
}
else {}
while(true)
{
/* Code+-*= */
}
for(int8 i = 0; i < 8; i++)
{
/* Loop body */
}
int32 _a = 32;
float b = -1.0+1.23456789;
bool c0 = false;
Alpha d;
d.func();
d.var;
return 0;
}
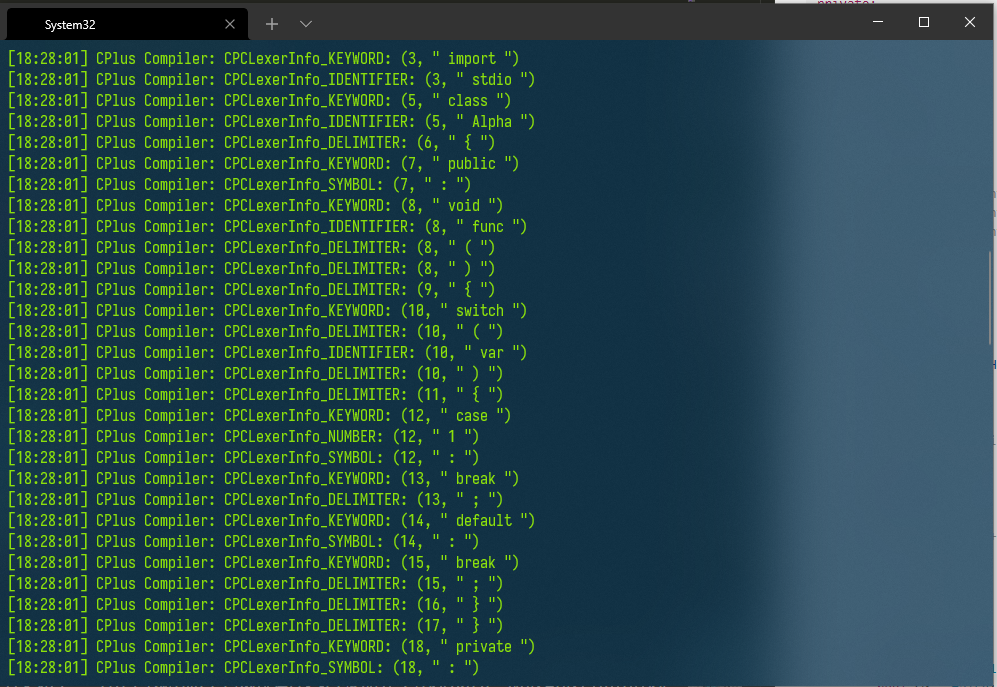
運行結果如下:(由於我將項目生成的編譯器目錄加入了系統path,所以可以直接由命令CPC啟動)
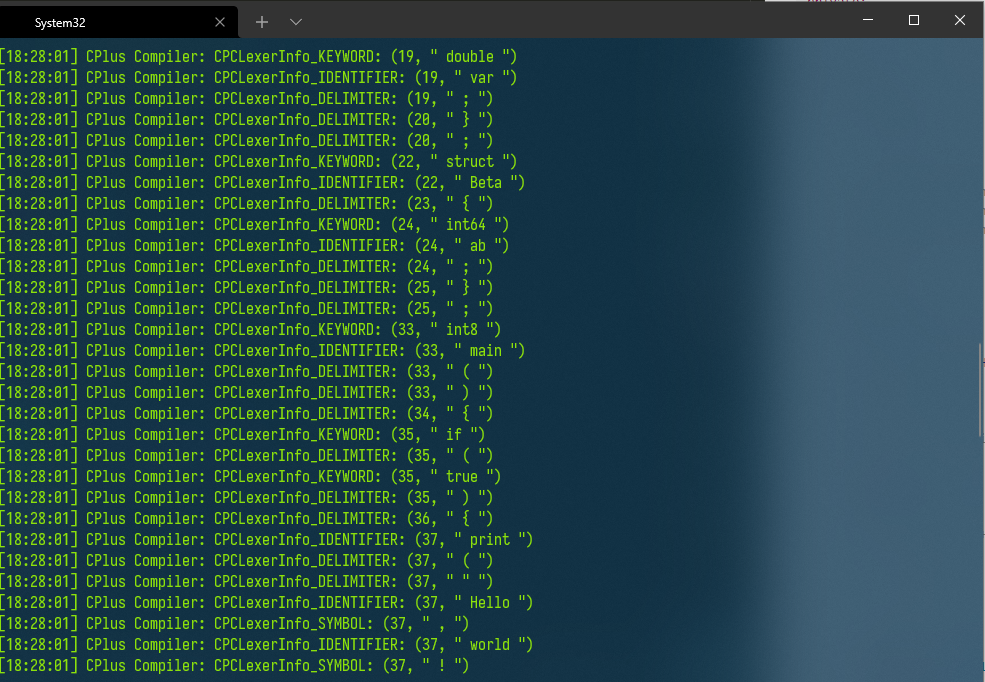
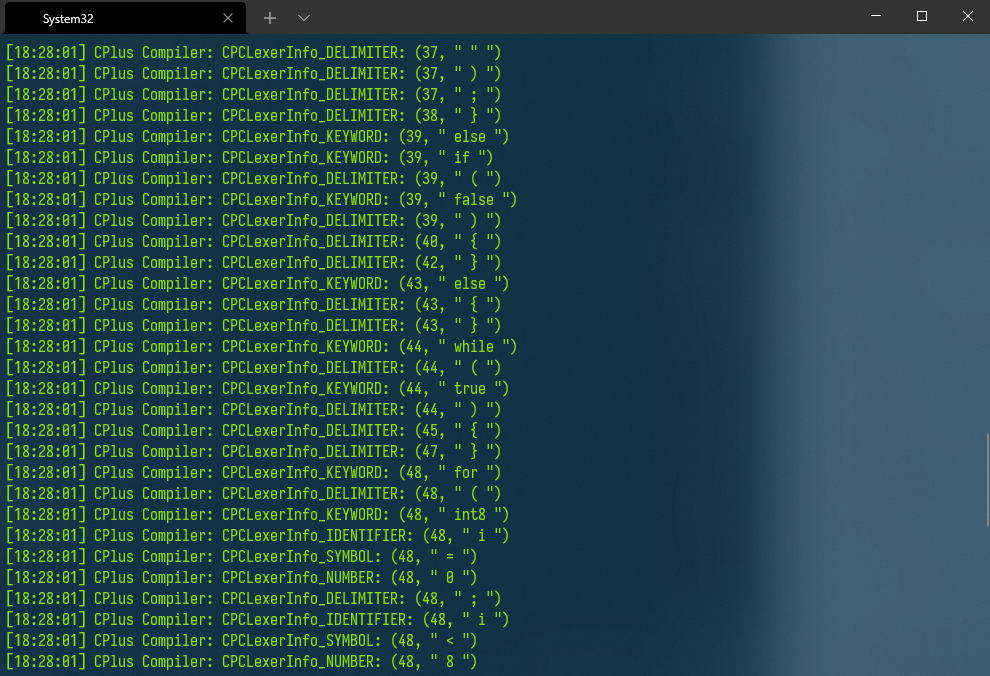
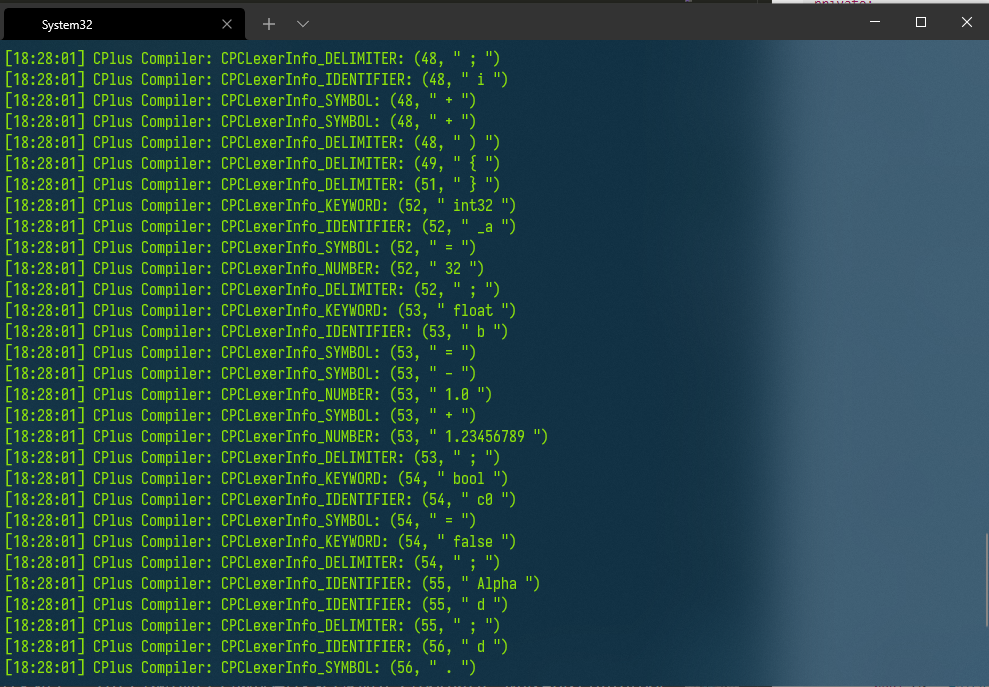
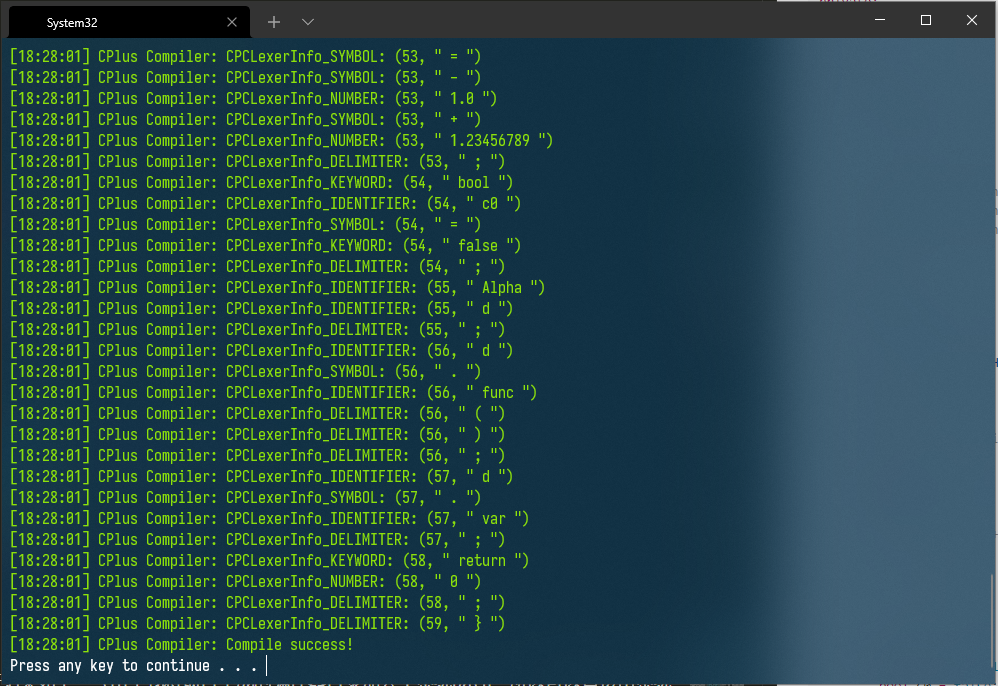
4. 結語
又是個天坑(笑),當然,我並沒有忘和大家許諾的虛幻引擎系列、圖形學系列以及遊戲引擎系列,只是咕一會而已,並無大礙,至少不會是麻蛇和富堅老賊那樣無限期拖更。額,也沒什麼要說的,如果有什麼好的建議或者意見歡迎提出,就這樣,期待下次再會!誒嘿,饢打油!