CVPR2021 | 華為諾亞實驗室提出Transformer in Transformer
- 2021 年 5 月 4 日
- 筆記
前言:
transformer用於圖像方面的應用逐漸多了起來,其主要做法是將圖像進行分塊,形成塊序列,簡單地將塊直接丟進transformer中。然而這樣的做法忽略了塊之間的內在結構信息,為此,這篇論文提出了一種同時利用了塊內部序列和塊之間序列信息的transformer模型,稱之為Transformer-iN-Transformer,簡稱TNT。
主要思想
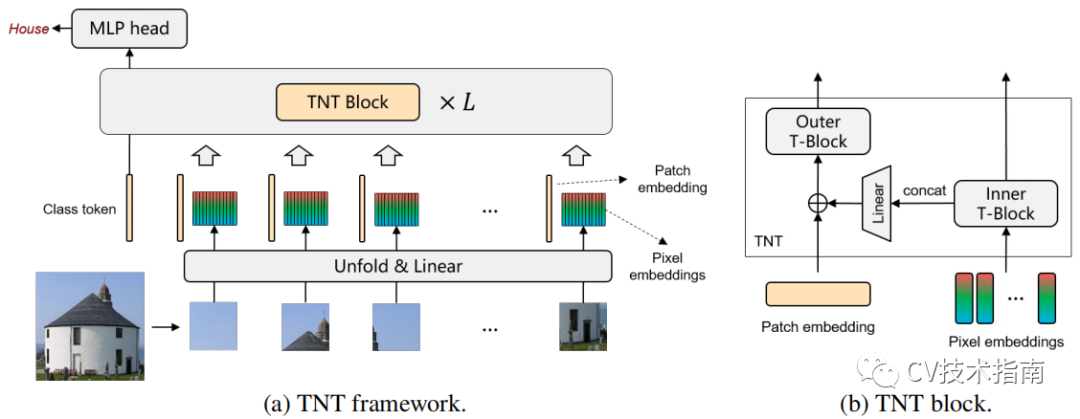
TNT模型把一張圖像分為塊序列,每個塊reshape為像素序列。經過線性變換可從塊和像素中獲得patch embedding和pixel embedding。將這兩者放進堆疊的TNT block中學習。
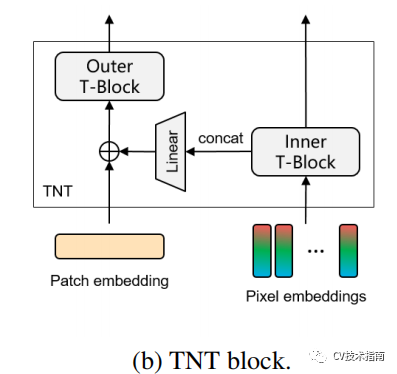
在TNT block中由outer transformer block和inner transformer block組成。
outer transformer block負責建模patch embedding上的全局相關性,inner block負責建模pixel embedding之間的局部結構信息。通過把pixel embedding線性映射到patch embedding空間的方式來使patch embedding融合局部信息。為了保持空間信息,引入了位置編碼。最後class token通過一個MLP用於分類。
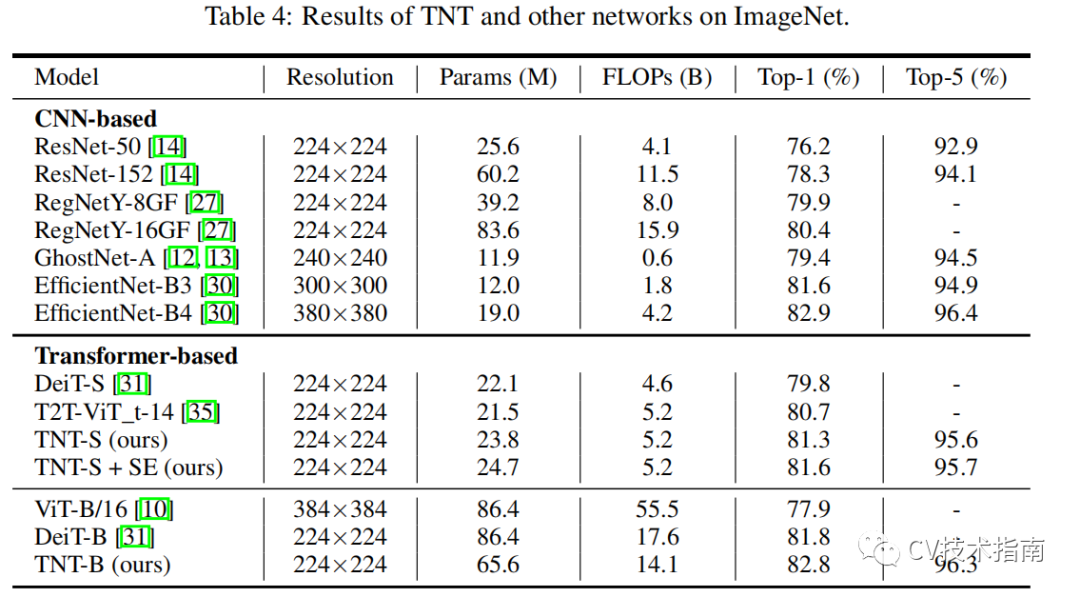
通過提出的TNT模型,可以把全局和局部的結構信息建模,並提高特徵表示能力。在精度和計算量方面,TNT在ImageNet和downstream 任務上有非常優異的表現。例如,TNT-S所在ImageNet top-1上在只有5.2B FLOPs的前提下實現了81.3%,比DeiT高了 1.5%。
一些細節
對照這個圖,用幾個公式來介紹。
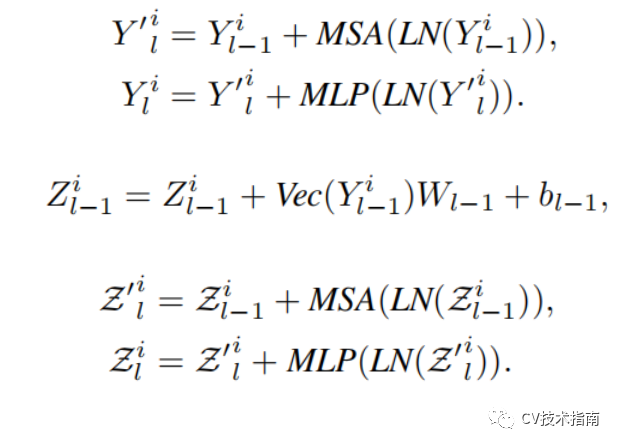
MSA為Multi-head Self-Attention。
MLP為Multi Layer Perceptron。
LN為Layer Normalization。
Vec為flatten。
加號表示殘差連接。
前兩個公式是inner transformer block,處理塊內部的信息,第三個公式是將塊內部的信息通過線性映射到patch embedding空間,最後兩個公式是outer transformer block,處理塊之間的信息。
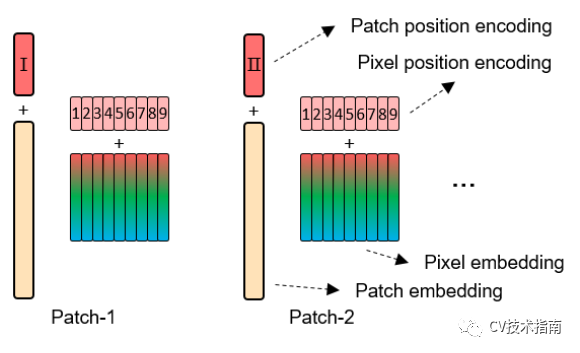
位置編碼的方式看下面的圖就足了。
模型參數量和計算量如下表所示:

Conclusion
最近把公眾號(CV技術指南)所有的技術總結打包成了一個pdf,在公眾號中回復關鍵字「技術總結」可獲取。

本文來源於公眾號CV技術指南的技術總結系列,更多內容請掃描文末二維碼關注公眾號。



