Python網絡爬蟲實戰(二)數據解析
- 2019 年 10 月 3 日
- 筆記
上一篇說完了如何爬取一個網頁,以及爬取中可能遇到的幾個問題。那麼接下來我們就需要對已經爬取下來的網頁進行解析,從中提取出我們想要的數據。
根據爬取下來的數據,我們需要寫不同的解析方式,最常見的一般都是HTML數據,也就是網頁的源碼,還有一些可能是Json數據,Json數據是一種輕量級的數據交換格式,相對來說容易解析,它的格式如下。
{ "name": "中國", "province": [{ "name": "黑龍江", "cities": { "city": ["哈爾濱", "大慶"] } }, { "name": "廣東", "cities": { "city": ["廣州", "深圳", "珠海"] } }, { "name": "台灣", "cities": { "city": ["台北", "高雄"] } }, { "name": "新疆", "cities": { "city": ["烏魯木齊"] } }] }上一篇說到的爬取攜程加載不出來的那部分數據就是異步請求Json返回給我們的,對於這類數據,Python有着十分便捷的解析庫,所以我們相對不用寫多少代碼。
但是對於爬取下來是一個HTML數據,其中標籤結構可能十分複雜,而且不同HTML的結構可能存在差異,所以解析方式也需要看情況而定。
相對方便的解析方式有正則表達式,xPath和BeautifulSoup4庫。
三者的運行速度相比當然是正則表達式最快,xPath其次,Bs4最慢了,因為Bs4是經過封裝的庫,相對於另外兩個,無疑是重裝坦克一般,但Bs4確實使用最簡單的一個,而正則表達式是最麻煩的一個。
正則表達式幾乎所有編程語言都支持,每一種語言的正則表達式都存在一點差異但大同小異。如果你是在設計一個複雜系統,就不要考慮正則表達式了,因為這種方法太過於不穩定,你永遠不敢保證你寫的正則規則是對應當前系統完全不會報錯的。
xPath 是一門在XML文檔中查找信息的語言。xPath可用來在XML文檔中對元素和屬性進行遍歷。
關於正則表達式和xPath在之後的實戰中再做詳解,現在主要是掌握Bs4的使用。
我們首先需要下載Bs4的庫。
pip install lxml pip install beautifulsoup4當我們爬取下來一整個網頁的HTML之後,Bs4就可以根據標籤的相對定位來找准你要爬取的數據了。
這個相對定位類似於如下:
body > div.banner > div > div.celeInfo-right.clearfix > div.movie-stats-container > div > div > span > span可以理解把HTML頁面當做洋蔥一層一層剝開。
這種定位叫做selector,我們可以不用自己編寫它,比較HTML結構可能比較複雜,很容易寫錯。
我們可以打開瀏覽器的控制台(F12),然後Elements裏面找到我們想要爬取之後解析的內容,這時候你鼠標放上去的位置對應頁面內容會變成藍色讓你來對比,如下圖。
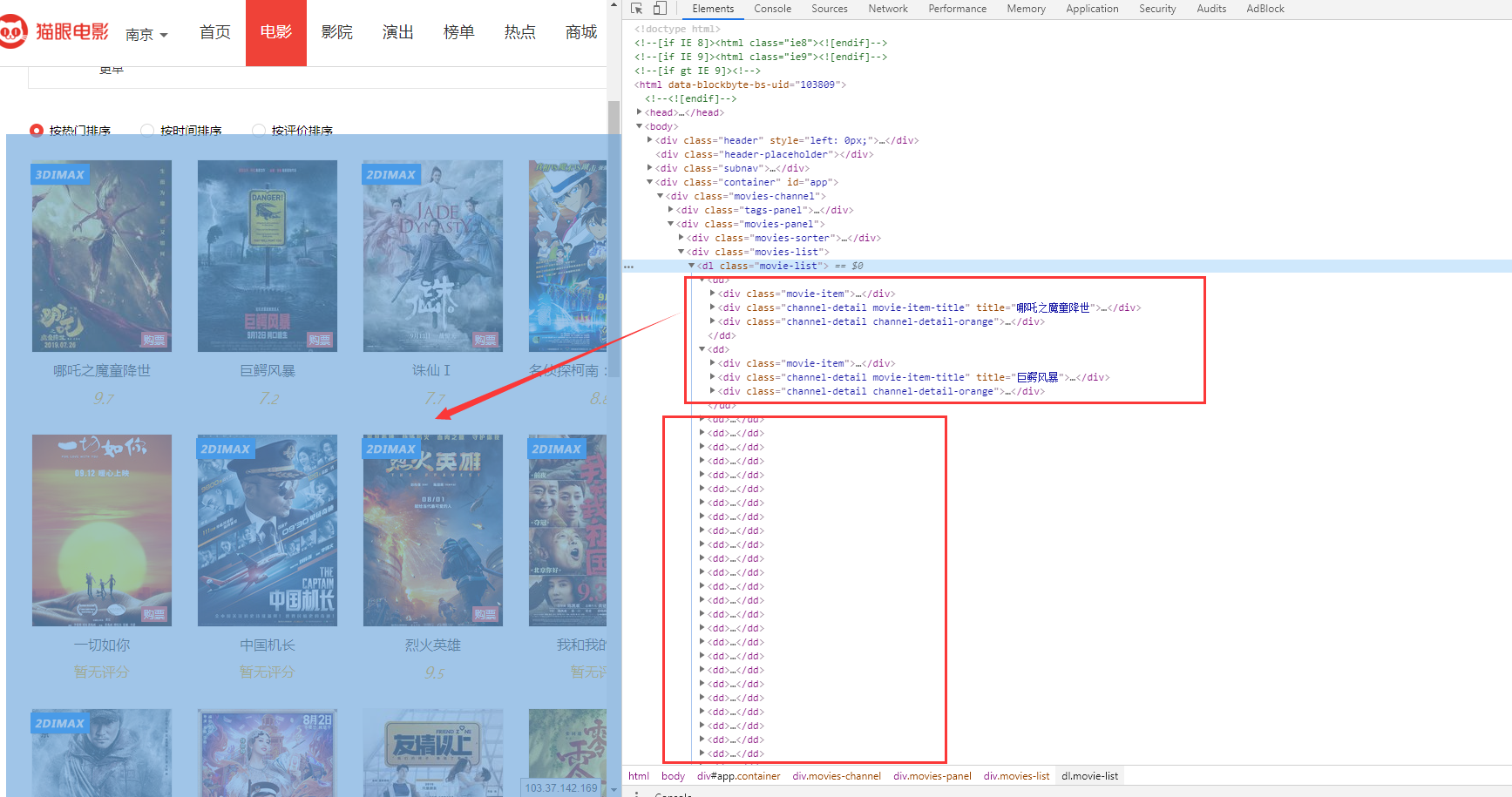
可以發現,這些dd標籤裏面就是當前頁面所有的電影信息了。哪吒之魔童降世你可以理解為dd-1,巨鱷風暴可以當做dd-2,以此類推。
然後你把鼠標放在dd標籤上右鍵,會有一個copy選項,裏面有一個selector,就是將它的selector複製下來。
下面分別是哪吒之魔童降世和巨鱷風暴的selector,可以發現,只有最後的dd:nth-child不同。
#app > div > div.movies-panel > div.movies-list > dl > dd:nth-child(1) #app > div > div.movies-panel > div.movies-list > dl > dd:nth-child(2)有了這個規律,我們就可以很容易的一次性解析那種列表型網頁了。
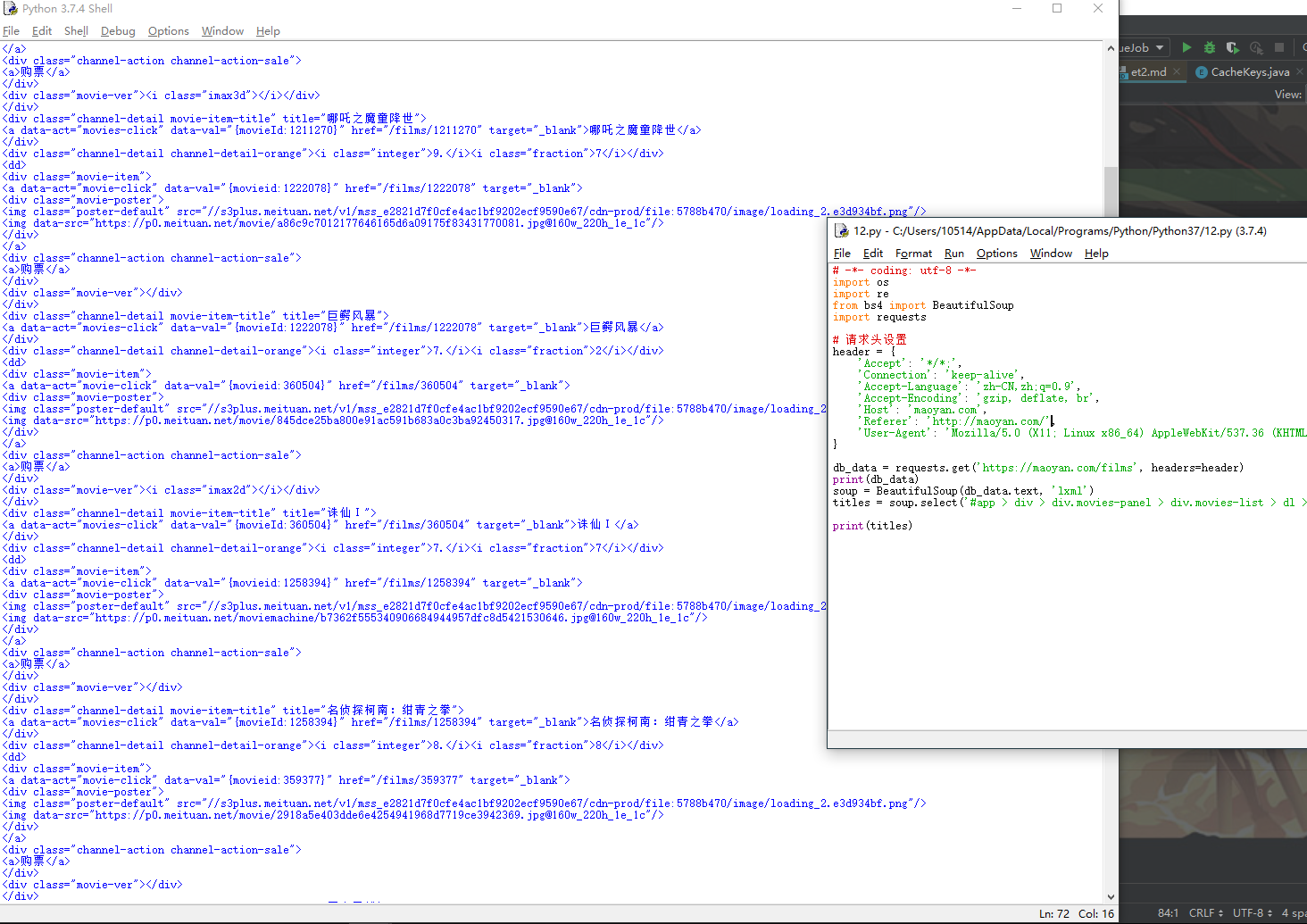
# -*- coding: utf-8 -*- import os import re from bs4 import BeautifulSoup import requests # 請求頭設置 header = { 'Accept': '*/*;', 'Connection': 'keep-alive', 'Accept-Language': 'zh-CN,zh;q=0.9', 'Accept-Encoding': 'gzip, deflate, br', 'Host': 'maoyan.com', 'Referer': 'http://maoyan.com/', 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36' } data = requests.get('https://maoyan.com/films', headers=header) soup = BeautifulSoup(data.text, 'lxml') titles = soup.select('#app > div > div.movies-panel > div.movies-list > dl > dd ') print(titles)來仔細講解一下上面這些代碼。
request.get(url,headers)是昨天說過的了,headers就是請求頭信息,裏面包含了我們客戶端的信息以及請求方式是Get還是Post等。
返回的data就是響應了,你可以直接print這個數據,但是這個響應體裏面不止包含網頁的HTML,還有這次請求的相關數據,比如響應碼,200說明成功,404說明沒有找到資源等。
data.text就是從響應體中拿到網頁HTML代碼了。
BeautifulSoup就是我們的主要解析對象,lxml是相應的解析方式。
通過調用BeautifulSoup的select選擇器方法,來從之前傳入的HTML中獲取相應的標籤。
這麼一看其實Bs4還是很簡單的,但這只是Bs4的基礎應用了,對於我們普通解析一個網頁已經足夠用了,如果感興趣可以去深入去了解一下,不過這個這麼說也只是工具庫,如果你不嫌麻煩可以自己解析。
看完代碼,如果現在我要拿到這個頁面的電影名稱,這時候上面這個selector就不能用了,因為它不夠精確,它只到了’
用這個selector。

#app > div > div.movies-panel > div.movies-list > dl > dd:nth-child(1) > div.channel-detail.movie-item-title > a其它方式幾乎都大同小異了。
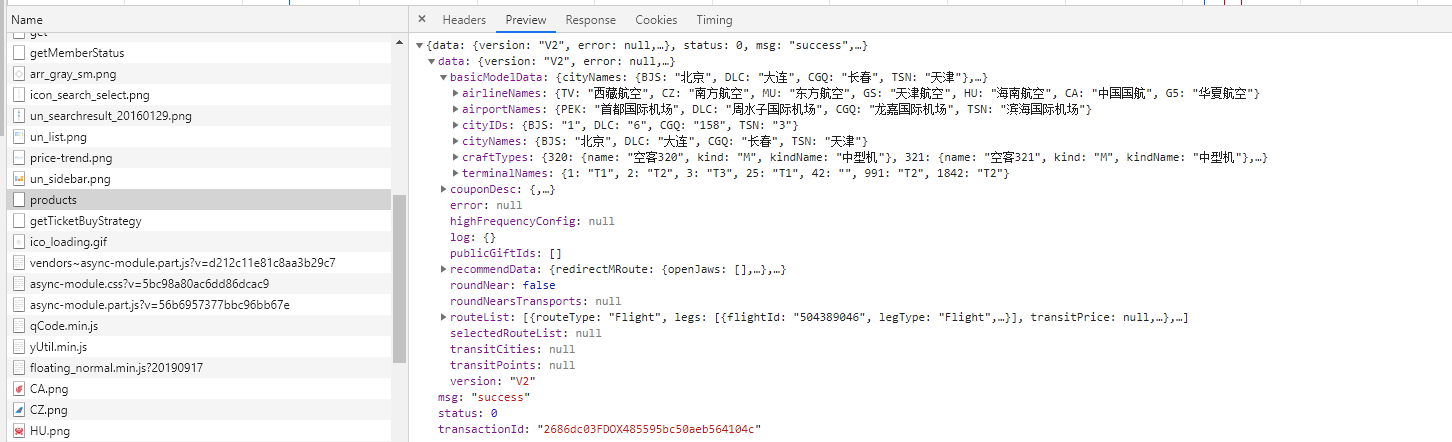
以上是HTML的解析,我們爬取的數據有時還會是Json數據,這類數據相對來說十分規則,我倒是很希望目標數據會是Json格式。
比如上篇中的攜程。
它的航班信息就是請求Json返回的。
Python中正則表達式的解析十分簡單,你把它當做字典數據類型就可以了。
最開始你獲得的Json是一串字符串,通過Python的Json.loads(jsonData)之後,返回的其實就是字典數據類型,直接操作就可以了。

import json jsonData = '{ "name":"gzj", "age":"23", "sex":"man", "mail":{ "gmail":"[email protected]", "qmail":"[email protected]" } }' res = json.loads(jsonData) print(res['mail']['qmail'])(最近在想實戰部分要不要錄視頻和文章兩部分,歡迎關注公眾號來康康!)
