Python 基礎教程 —— 網絡爬蟲入門篇
- 2021 年 4 月 29 日
- 筆記
- matplotlib, Python, Python基礎教程, urllib.request, 網絡爬蟲
前言
Python 是一種解釋型、面向對象、動態數據類型的高級程序設計語言,它由 Guido van Rossum 於 1989 年底發明,第一個公開發行版發行於 1991 年。
自面世以後,Python 深受廣大開發者的喜迎,在網站開發,網絡爬蟲,數據分析,機器學習,人工智能等領域都有其過人之處。
在「Python基礎教程「中,本人將會從各個不同領域介紹Python的用法,今天就先從最常用的網絡爬蟲開始說起。
網絡爬蟲主要目的是通過定期收集網絡的信息,把信息保存後進行分析歸類,最後通過報表顯示給相關的用戶作為業務參考。幾年我也曾經做過一個項目是對稅務局的政府網站進行信息收集,把收集到的稅務政策,各行業的稅率變動,國家頒佈的新行稅法進行分析,把分析結果綜合到財稅管理平台進行財務核算。
為了簡化流程,這次就以常用的天氣網為例子(//www.weather.com.cn/),定時收集地區的天氣情況,最後把數據作為圖表顯示。
目錄
這裡用到了 urllib 庫裏面的 request 類,它有兩個常用的方法:
1. urlretrieve 用於下載網頁
1 def urlretrieve(url: str, 2 filename: Optional[str] = ..., 3 reporthook: Optional[(int, int, int) -> None] = ..., 4 data: Optional[bytes] = ...)
參數說明
url:網頁地址 url
filename:指定了保存到本地的路徑(如果未指定該參數,urllib會生成一個臨時文件來保存數據);
reporthook:是一個回調函數,當連接上服務器、以及相應的數據塊傳輸完畢的時候會觸發該回調。我們可以利用這個回調函數來顯示當前的下載進度。
data:指post到服務器的數據。該方法返回一個包含兩個元素的元組(filename, headers),filename表示保存到本地的路徑,header表示服務器的響應頭。
2. urlopen 可以像打開文檔一樣直接打開遠程頁面,區別在於 urlopen是只讀模式
1 def urlopen(url: Union[str, Request], 2 data: Optional[bytes] = ..., 3 timeout: Optional[float] = ..., 4 *, 5 cafile: Optional[str] = ..., 6 capath: Optional[str] = ..., 7 cadefault: bool = ..., 8 context: Optional[SSLContext] = ...)
參數說明
url :目標資源在網路中的位置。可以是一個表示URL的字符串,也可以是一個urllib.request對象,詳細介紹請跳轉
data:data用來指明發往服務器請求中的額外的參數信息(如:在線翻譯,在線答題等提交的內容),data默認是None,此時以GET方式發送請求;當用戶給出data參數的時候,改為POST方式發送請求。
timeout:設置網站的訪問超時時間
cafile、capath、cadefault:用於實現可信任的CA證書的HTTP請求。(基本上很少用)
context參數:實現SSL加密傳輸。
1 class Weather(): 2 3 def __init__(self): 4 #確定下載路徑,以日期作為文件名 5 self.path='E:/Python_Projects/Test/weather/' 6 self.filename=str(datetime.date.today()).replace('-','') 7 8 def getPage(self,url): 9 #下載頁面並保存 10 file=self.path+self.filename+'.html' 11 urlretrieve(url,file,None,None)
運行方法後可以看到在文件夾里已經保存了整個靜態頁面
因為每個html頁面的數據均有不同,我們可以觀察html代碼的特徵,通過 re 的功能找到所需要的數據。
這裡介紹幾個 re 常用的方法
1、re.compile(pattern,flags = 0 )
將正則表達式模式編譯為正則表達式對象,可使用match(),search()以及下面所述的其他方法將其用於匹配
2、re.search(pattern,string,flags = 0 )
掃描字符串以查找正則表達式模式產生匹配項的第一個位置 ,然後返回相應的match對象。None如果字符串中沒有位置與模式匹配,則返回;否則返回false。請注意,這與在字符串中的某個點找到零長度匹配不同。
3、re.match(pattern,string,flags = 0 )
如果字符串開頭的零個或多個字符與正則表達式模式匹配,則返回相應的匹配對象。None如果字符串與模式不匹配,則返回;否則返回false。請注意,這與零長度匹配不同。
4、re.fullmatch(pattern,string,flags = 0 )
如果整個字符串與正則表達式模式匹配,則返回相應的match對象。None如果字符串與模式不匹配,則返回;否則返回false。請注意,這與零長度匹配不同。
5、re.split(pattern,string,maxsplit = 0,flags = 0 )
通過出現模式來拆分字符串。如果在pattern中使用了捕獲括號,那麼模式中所有組的文本也將作為結果列表的一部分返回。如果maxsplit不為零,則最多會發生maxsplit分割,並將字符串的其餘部分作為列表的最後一個元素返回。
6、re.findall(pattern,string,flags = 0 )
以string列表形式返回string中pattern的所有非重疊匹配項。從左到右掃描該字符串,並以找到的順序返回匹配項。如果該模式中存在一個或多個組,則返回一個組列表;否則,返回一個列表。如果模式包含多個組,則這將是一個元組列表。空匹配項包含在結果中。
7、re.finditer(pattern,string,flags = 0 )
返回一個迭代器,該迭代器在string類型的RE 模式的所有非重疊匹配中產生匹配對象。 從左到右掃描該字符串,並以找到的順序返回匹配項。空匹配項包含在結果中。
本例子比較簡單,可以看到在地區白天/夜晚的氣溫都包含在 <p class=”tem”><span>30</span><em>°C</em></p>,可以直接通過 re.compile() 找到數據。
然而在不同的頁面里,數據可能是通過後台綁定,或者在頁面渲染時綁定,這時候就需要細心地找尋數據來源,再通過鏈接獲取。
1 def readPage(self): 2 #讀取頁面 3 file=open(self.path+self.filename+'.html','r',1024,'utf8') 4 data=file.readlines() 5 #找出當天白天溫度與晚上溫度 6 pat=re.compile('<span>[0-9][0-9]</span>') 7 data=re.findall(pat,str(data)) 8 file.close() 9 #篩選溫度值,返回list 10 list1 = [] 11 for weather in data: 12 w1 = weather.replace('<span>', '') 13 w2 = w1.replace('</span>', '') 14 list1.append(w2) 15 return list1
最後返回 list 數組,其中包含當天的日間氣溫與夜間氣溫
把當天日期、日間氣溫、夜間氣溫保存到數據庫
1 def save(self,list1): 2 #保存到數據庫 3 db = MySQLdb.connect("localhost", "root", "********", "database", charset='utf8') 4 cursor = db.cursor() 5 sql = 'INSERT INTO weather(date,daytime,night) VALUES ('+self.filename+','+list1[0]+','+list1[1]+')' 6 try: 7 cursor.execute(sql) 8 db.commit() 9 except: 10 # 發生錯誤時回滾 11 db.rollback() 12 # 關閉數據庫連接 13 db.close()
在數據庫積累多天數據後,通過 matplotlib 庫顯示數據
1 def display(): 2 # X軸旋轉90度 3 plt.xticks(rotation=90) 4 # 從數據庫中獲取數據 5 db = MySQLdb.connect("localhost", "root", "********", "database", charset='utf8') 6 cursor = db.cursor() 7 sql = 'SELECT date,daytime,night FROM weather' 8 try: 9 cursor.execute(sql) 10 data=np.array(cursor.fetchall()) 11 db.commit() 12 except: 13 # 發生錯誤時回滾 14 db.rollback() 15 #數據轉換成日期數組,白天溫度數組,夜間溫度數組 16 if len(data)!=0: 17 date=data[:,0] 18 # y軸數據需要轉化為int形式,否則將按字符串形式排列 19 daytime=(np.int16(data[:,1])) 20 night=(np.int16(data[:,2])) 21 plt.xlabel('Date') 22 plt.ylabel('Temperature') 23 plt.title('Weather') 24 # 顯示數據 25 plt.plot(date,daytime,label='day') 26 plt.plot(date,night,label='night') 27 plt.legend() 28 plt.show()
顯示結果
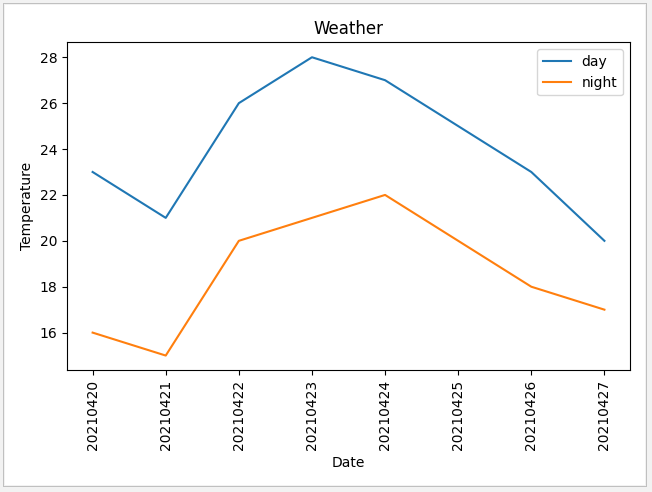
使用 Timer 定時器每天執行一次,下載數據,再刷新畫面
1 def start(): 2 weather=Weather() 3 weather.getPage(url) 4 data=weather.readPage() 5 weather.save(data) 6 display() 7 t = threading.Timer(86400, start) 8 t.start() 9 10 url='//www.weather.com.cn/weather1d/101280101.shtml' 11 if __name__ == '__main__': 12 start()
全部源代碼


1 from urllib.request import urlretrieve,urlopen 2 from matplotlib import pyplot as plt 3 4 import numpy as np,threading,re,datetime,MySQLdb 5 6 class Weather(): 7 8 def __init__(self): 9 #確定下載路徑,以日期作為文件名 10 self.path='E:/Python_Projects/Test/weather/' 11 self.filename=str(datetime.date.today()).replace('-','') 12 13 def getPage(self,url): 14 #下載頁面並保存 15 file=self.path+self.filename+'.html' 16 urlretrieve(url,file,None,None) 17 18 def readPage(self): 19 #讀取頁面 20 file=open(self.path+self.filename+'.html','r',1024,'utf8') 21 data=file.readlines() 22 #找出當天白天溫度與晚上溫度 23 pat=re.compile('<span>[0-9][0-9]</span>') 24 data=re.findall(pat,str(data)) 25 file.close() 26 #篩選溫度值,返回list 27 list1 = [] 28 for weather in data: 29 w1 = weather.replace('<span>', '') 30 w2 = w1.replace('</span>', '') 31 list1.append(w2) # 保存數據 32 return list1 33 34 def save(self,list1): 35 #保存到數據庫 36 db = MySQLdb.connect("localhost", "root", "********", "database", charset='utf8') 37 cursor = db.cursor() 38 sql = 'INSERT INTO weather(date,daytime,night) VALUES ('+self.filename+','+list1[0]+','+list1[1]+')' 39 try: 40 cursor.execute(sql) 41 db.commit() 42 except: 43 # 發生錯誤時回滾 44 db.rollback() 45 # 關閉數據庫連接 46 db.close() 47 48 def display(): 49 # X軸旋轉90度 50 plt.xticks(rotation=90) 51 # 從數據庫中獲取數據 52 db = MySQLdb.connect("localhost", "root", "********", "database", charset='utf8') 53 cursor = db.cursor() 54 sql = 'SELECT date,daytime,night FROM weather' 55 try: 56 cursor.execute(sql) 57 data=np.array(cursor.fetchall()) 58 db.commit() 59 except: 60 # 發生錯誤時回滾 61 db.rollback() 62 #數據轉換成日期數組,白天溫度數組,夜間溫度數組 63 if len(data)!=0: 64 date=data[:,0] 65 # y軸數據需要轉化為int形式,否則將按字符串形式排列 66 daytime=(np.int16(data[:,1])) 67 night=(np.int16(data[:,2])) 68 plt.xlabel('Date') 69 plt.ylabel('Temperature') 70 plt.title('Weather') 71 # 顯示數據 72 plt.plot(date,daytime,label='day') 73 plt.plot(date,night,label='night') 74 plt.legend() 75 plt.show() 76 77 def start(): 78 weather=Weather() 79 weather.getPage(url) 80 data=weather.readPage() 81 weather.save(data) 82 display() 83 t = threading.Timer(86400, start) 84 t.start() 85 86 url='//www.weather.com.cn/weather1d/101280101.shtml' 87 if __name__ == '__main__': 88 start()
View Code
總結
這個例子只是從最簡單的角度介紹爬蟲的使用方式,對應實際的應用場景只是冰山一角,在現實中經常還會遇到IP地址被封,數據綁定無法直接獲取,數據加密等諸多問題,在後面再作詳細介紹。
由於時間緊迫,文章中有所缺漏的地方敬請點評。
對 JAVA 開發有興趣的朋友歡迎加入QQ群:174850571 共同探討!
對 .NET 開發有興趣的朋友歡迎加入QQ群:230564952 共同探討 !
作者:風塵浪子
//www.cnblogs.com/leslies2/p/14719516.html
原創作品,轉載時請註明作者及出處


