JUC包的線程池詳解
為什麼要使用線程池
-
創建/銷毀線程需要消耗系統資源,線程池可以復用已創建的線程。
-
控制並發的數量。並發數量過多,可能會導致資源消耗過多,從而造成服務器崩潰。(主要原因)
-
可以對線程做統一管理。
JUC下線程池的體系結構
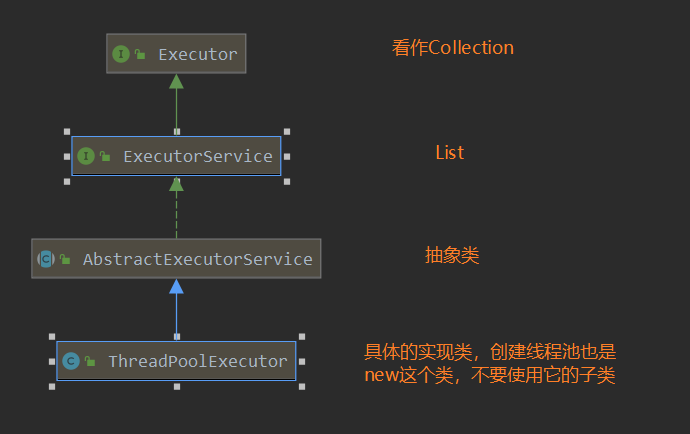
創建線程池的兩種方法
-
使用ThreadPoolExecutor的構造方法創建
public class ThreadPoolTest1 { public static void main(String[] args) { ThreadPoolExecutor pool = new ThreadPoolExecutor(5, 8, 1, TimeUnit.SECONDS , new ArrayBlockingQueue<>(5) , Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); for (int i = 0; i < 11; i++) { pool.execute( () -> { System.out.println(Thread.currentThread().getName()); } ); } }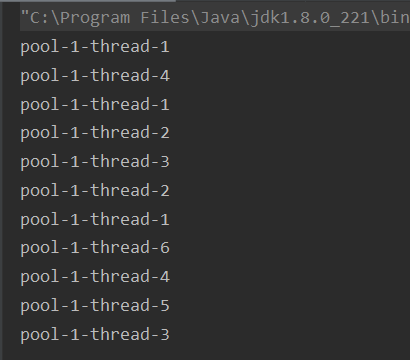
-
使用Executors這個工具類來實現
JDK工具類為我們提供了四種常用的線程池,其實它們的底層源碼都是調用ThreadPoolExecutor來實現的,傳遞的線程池參數不同罷了。
工程中我們都是使用第一種方法來創建線程池,這樣的處理方式讓寫的同學更加明確線程池的運行規則,規避資源耗盡的⻛險(OOM)

線程池ThreadPoolExecutor的七大參數
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
- corePoolSize:核心線程的最大值,相當於正式員工,到點才下班
- maximumPoolSize:核心線程+非核心線程的最大值,非核心線程相當於臨時工,核心線程處理不過來才會激活非核心線程,業務量低時先下班
- keepAliveTime:非核心線程閑置超時時長,超時了非核心線程被銷毀
- TimeUnit unit:keepAliveTime的時間單位
- workQueue:阻塞隊列,線程池的底層也用了阻塞隊列,維護等待執行的線程對象
- ThreadFactory threadFactory:創建線程的工程,一般使用Excetory的默認實現默認實現
- RejectedExecutionHandler handler:阻塞隊列滿了之後對新來線程的拒絕策略,默認有四種
- ThreadPoolExecutor.AbortPolicy:默認拒絕處理策略,丟棄任務並拋出RejectedExecutionException異常。
- ThreadPoolExecutor.DiscardPolicy:丟棄新來的任務,但是不拋出異常。
- ThreadPoolExecutor.DiscardOldestPolicy:丟棄隊列頭部(最舊的)的任務,然後重新嘗試執行程序(如果再次失敗,重複此過程)。
- ThreadPoolExecutor.CallerRunsPolicy:返回給上一步,由調用線程處理該任務。
線程池調度的策略
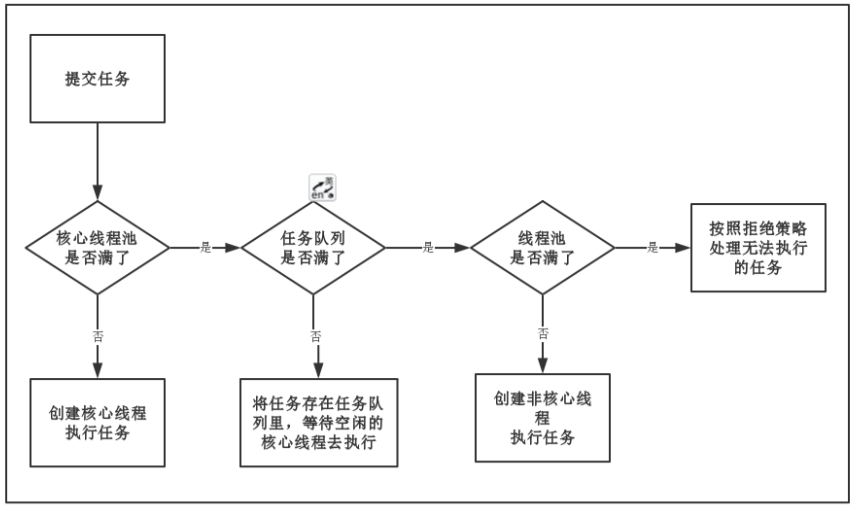
線程池調度的核心是execute方法,總結完就是上圖
// JDK 1.8
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 1.當前線程數小於corePoolSize,則調用addWorker創建核心線程執行任務
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2.如果不小於corePoolSize,則將任務添加到workQueue隊列。
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 2.1 如果isRunning返回false(狀態檢查),則remove這個任務,然後執行拒絕策略。
if (! isRunning(recheck) && remove(command))
reject(command);
// 2.2 線程池處於running狀態,但是沒有線程,則創建線程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3.如果放入workQueue失敗,則創建非核心線程執行任務,
// 如果這時創建非核心線程失敗(當前線程總數不小於maximumPoolSize時),就會執行拒絕策略。
else if (!addWorker(command, false))
reject(command);
}
這個對線程調度的源碼沒有深入分析,如addWord函數,拒絕策略是怎麼實現的等。以後會再專門寫一篇文章,可以參考《並發編程之美》的源碼分析。
執行execute方法和submit方法有何區別?
- execute()方法用於提交不需要返回值的任務,所以無法判斷任務是否被線程池執行成功與否;
- submit()方法用於提交需要返回值的任務。線程池會返回一個Future類型的對象,通過這個Future對象可以判斷任務是否執行成功,並且可以通過Future的get()方法來獲取返回值。
這也可以看到線程池的又一優點:靈活。
參考
-
JavaGuide
-
還沒仔細研究,粗略看了下,怎麼很不錯,值得參考
