Erda MSP 系列 – 以服務觀測為中心的 APM 系統設計:開篇詞
- 2021 年 4 月 26 日
- 筆記
本文首發於 Erda 技術團隊知乎技術號,更多技術文章可點擊 Erda 技術團隊
作者:劉浩楊,端點科技 PaaS 技術專家,微服務治理和監控平台負責人,Apache SkyWalking PMC成員
原文鏈接://zhuanlan.zhihu.com/p/367779900
前言
Erda Cloud 是我們即將發佈的一站式開發者雲平台,為企業開發團隊提供 DevOps (DevOps Platform, DOP )、微服務治理 (MicroService Platform,MSP )、多雲管理 (Cloud Management Platform,CMP ) 以及快數據管理 (FastData Platform,FDP ) 等雲原生服務。
作為 Erda Cloud 中的核心平台,MSP 提供了託管的微服務解決方案,包括 API 網關、註冊中心、配置中心、應用監控和日誌服務等,來幫助用戶解決業務系統進行微服務化而帶來技術複雜度難題。伴隨着產品的升級,我們也全新設計了以服務觀測為中心的 APM (應用性能監控) 產品,探索可觀測性在應用監控領域中落地的最佳實踐。
為了讓大家更好的了解 MSP 中 APM 系統的設計實現,我們將編寫一個系列專題,深入 APM 系統的產品、架構設計和基礎技術。這是該專題的第一篇,將通過分享我們在可觀測性上的一些思考來開啟這個專題的序章。
從監控到可觀測性
隨着近年來雲原生概念和雲原生架構設計的流行,越來越多的開發團隊開始使用 DevOps 模式進行系統開發,並把大型系統拆解成一個個微小的服務模塊,以便系統能更好的進行容器化部署。基於 DevOps、微服務、容器化等雲原生的能力,可以幫助業務團隊快速、持續、可靠和規模化地交付系統,同時也使得系統的複雜度成倍提升,由此帶來前所未有的運維挑戰,比如:
• 模塊之間的調用從進程內的函數調用變為進程間的調用,而網絡總是不可靠的
• 服務的調用路徑變長,使得流量的走向變得不可控,故障排查的難度增大
• 引入 Kubernetes、Docker、Service Mesh 等雲原生系統,基礎設施層對業務開發團隊來說變得更加黑盒
在傳統的監控系統中,我們往往會關注虛擬機的 CPU、內存、網絡、應用服務的接口請求量、資源使用率等指標,但在複雜的雲原生系統中,僅僅關注單點或者單個維度的指標,並不足以幫助我們掌握系統的整體運行狀況。在此背景下,對分佈式系統的「可觀測性」應運而生。通常,我們認為可觀測性相對於過去監控,最大的變化就是系統需要處理的數據,從指標為主,擴展到了更廣的領域。綜合起來,大約有幾類數據被看作是可觀測性的支柱:
• Metrics
• Tracing
• Logging
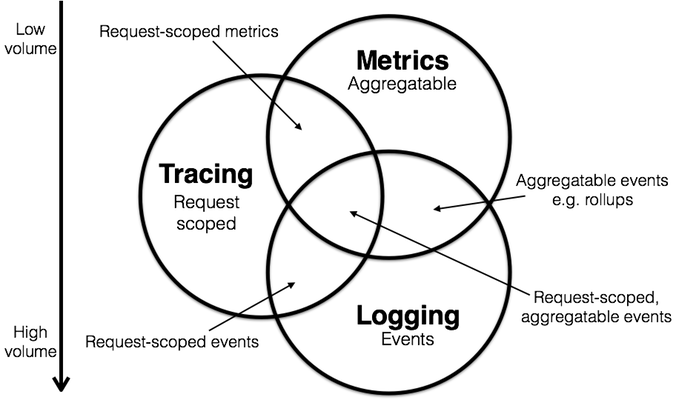
為了統一可觀測性系統中的數據採集和標準規範,同時提供與供應商無關的接口,CNCF 把 OpenTracing 和 OpenCensus 合併成 OpenTelemetry 項目。OpenTelemetry 通過 Spec 規範了觀測數據的數據模型以及採集、處理、導出方法,但對於數據如何去使用、存儲、展示和告警是不涉及的,官方目前的推薦方案是:
• 使用 Prometheus 和 Grafana 做 Metrics 的存儲和展示
• 使用 Jaeger 做分佈式追蹤的存儲和展示
得益於雲原生開源生態的蓬勃發展,技術團隊可以輕而易舉建設一套監控體系,比如使用 Prometheus + Grafana 搭建基礎監控,使用 SkyWalking 或 Jaeger 搭建追蹤系統,使用 ELK 或 Loki 搭建日誌系統。但對於可觀測性系統的用戶來說,不同類型的觀測數據分散存儲在不同的後端,排查問題仍需要在多個系統之間跳轉,效率和用戶體驗都得不到保證。為解決可觀測性數據的融合存儲和分析,我們自研的統一存儲和查詢引擎,提供了指標、追蹤和日誌數據的無縫關聯分析。在本文的其他部分,將詳細介紹我們是如何提供針對服務的可觀測性分析能力。
觀測的入口:可觀測性拓撲
可觀測性提出了三種數據之間的關係,讓我們可以使用標籤關聯 Metrics 和 Tracing,使用請求上下文去打通 Tracing 和 Log。因此,通常可以使用下面的方法去定位線上應用系統的接口異常:使用 Metrics 和 告警發現問題,然後使用 Tracing 定位到可能發生異常的模塊,最後使用 Logging 定位到錯誤根源。
雖然在大多數時間裏這個方法是行之有效的,但我們並不認為這是一個對系統進行觀測的最佳實踐:
• 雖然基於 Metrics 可以幫助我們及時發現問題,但往往我們發現的是大量單點問題,沒有一個全局的視角來觀測整個系統的狀態
• 業務開發團隊需要去熟悉 Metrics、Tracing 和 Logging 系統的各種概念和使用。如果基於開源組件搭配的監控系統,還需要在各個系統之間不斷跳轉才能完成一次問題的排查,這在今天很多公司里是經常見的
我們在不同領域用戶的監控需求的實踐中,發現拓撲可以天然的作為觀測系統的入口。不同於常見的分佈式追蹤平台,我們不僅僅把拓撲作為應用系統的運行時架構展示,在基於 100% 採樣的真實請求關係繪製出拓撲後,更進一步在拓撲節點上透出服務的請求和服務實例狀態(未來還會透出更多的觀測數據,比如流量比例、物理節點的狀態等)。
在拓撲頁面的布局上,我們把頁面切分為左右兩欄,右邊的狀態欄會顯示我們需要觀測的系統關鍵指標,如服務實例數、服務的錯誤請求、代碼異常和告警次數等。當我們點擊拓撲節點時,狀態欄會檢測節點類型的不同而顯示不同的狀態數據。當前我們支持展示狀態的節點類型有 API Gateway、服務、外部服務和中間件。
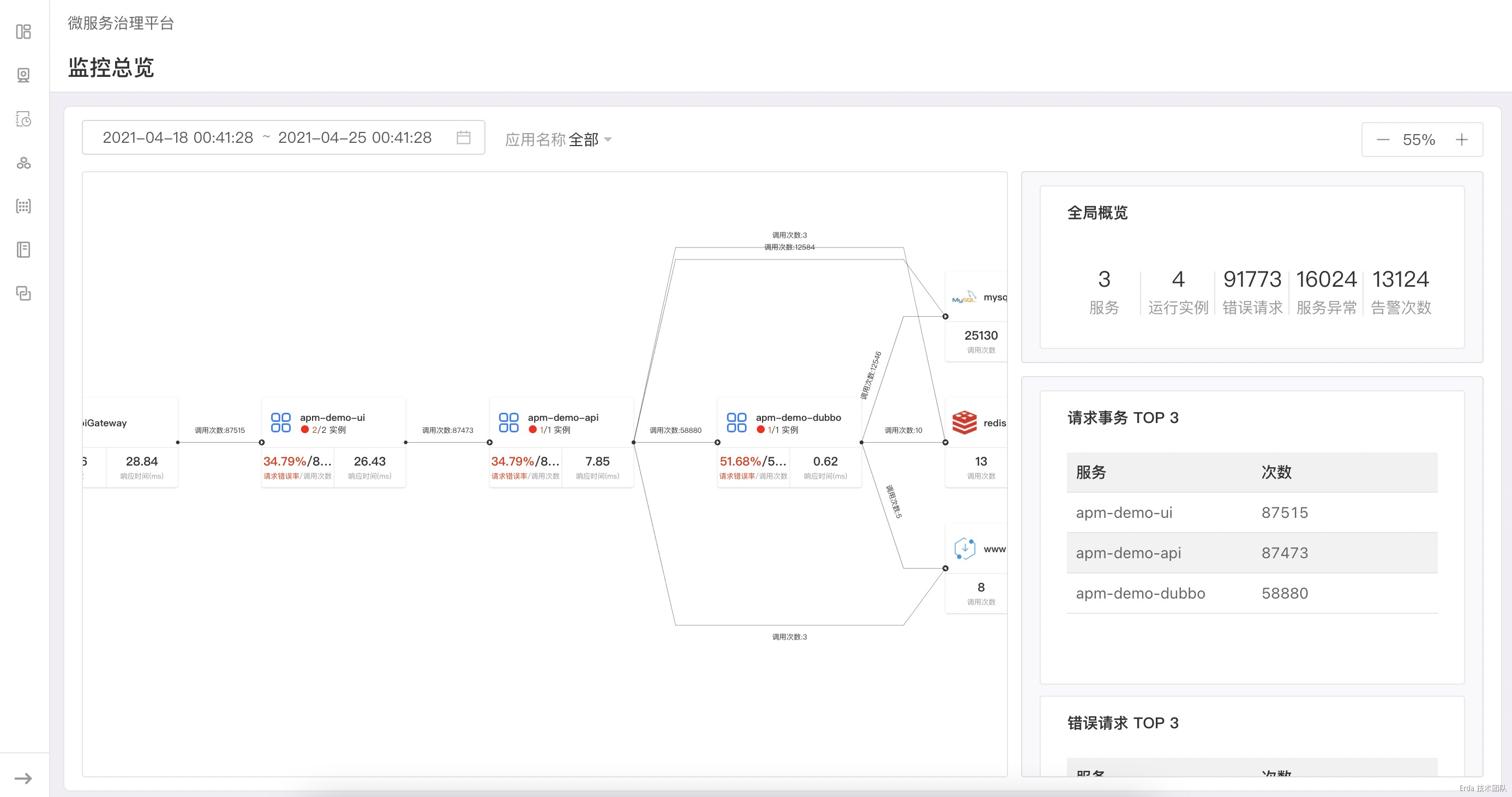
當點擊服務節點時,狀態欄會顯示服務的狀態概覽、事務調用概覽和 QPS 折線圖
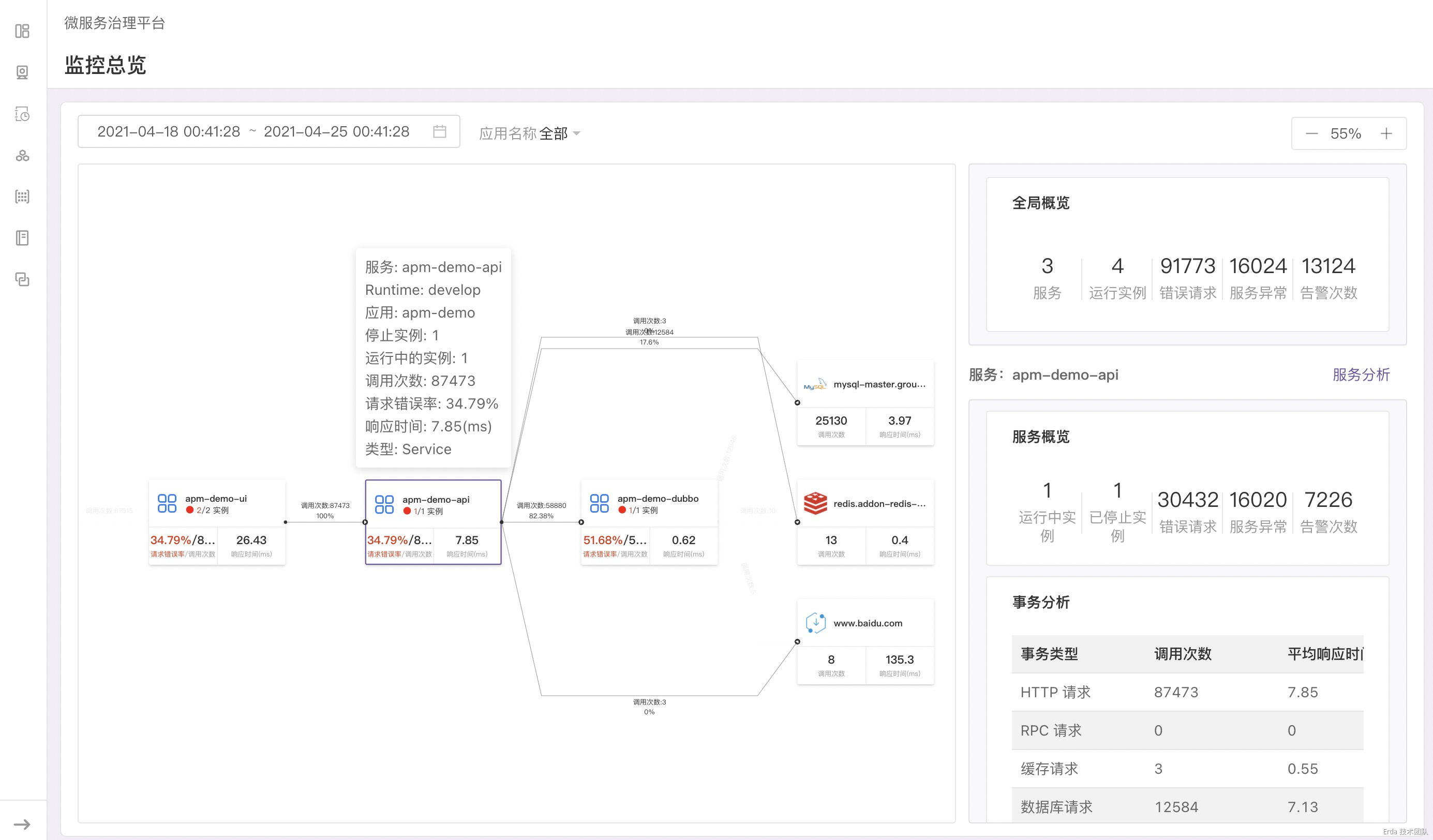
再進一步:如何觀測服務
基於可觀測拓撲,我們可以很容易在全局的視角下觀察系統的整體狀態,同時我們還提供了一種從拓撲下鑽到服務以便快速定位服務故障的觀測方式。當發現服務異常時,我們允許鏈接到服務分析,在該頁面提供了事務、異常和進程三個維度的觀測分析。
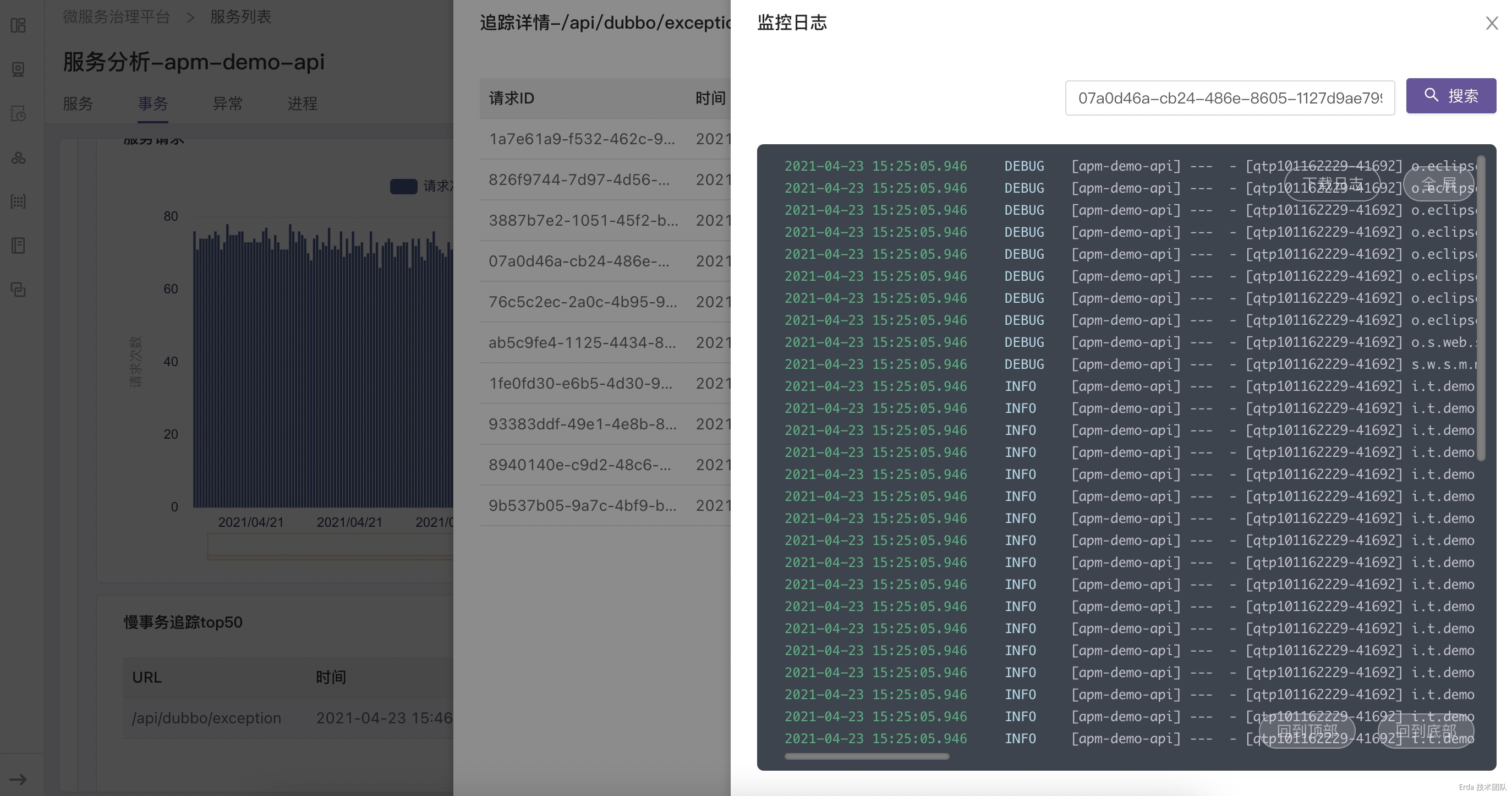
拿上面提到的接口異常為例,我們的故障排查方式為:在事務分析頁查詢觸發異常的接口 */exception ,然後點擊請求或延遲趨勢圖上的數據點關聯接口採樣到的慢事務追蹤和錯誤事務追蹤,在彈出的追蹤列表中查看請求鏈路詳情和請求關聯的日誌定位錯誤根源。
找到故障的事務請求
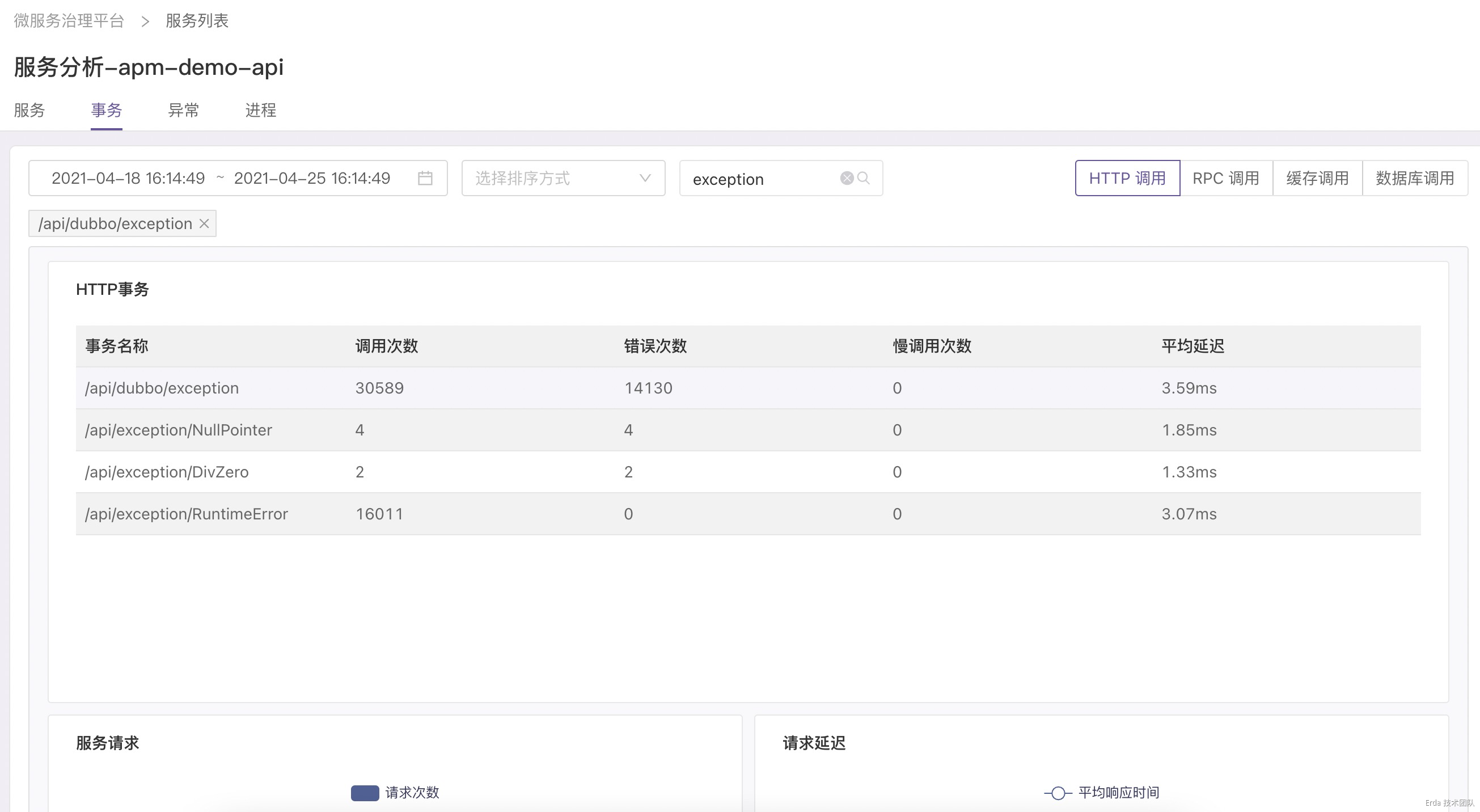
自動關聯該請求的調用鏈路
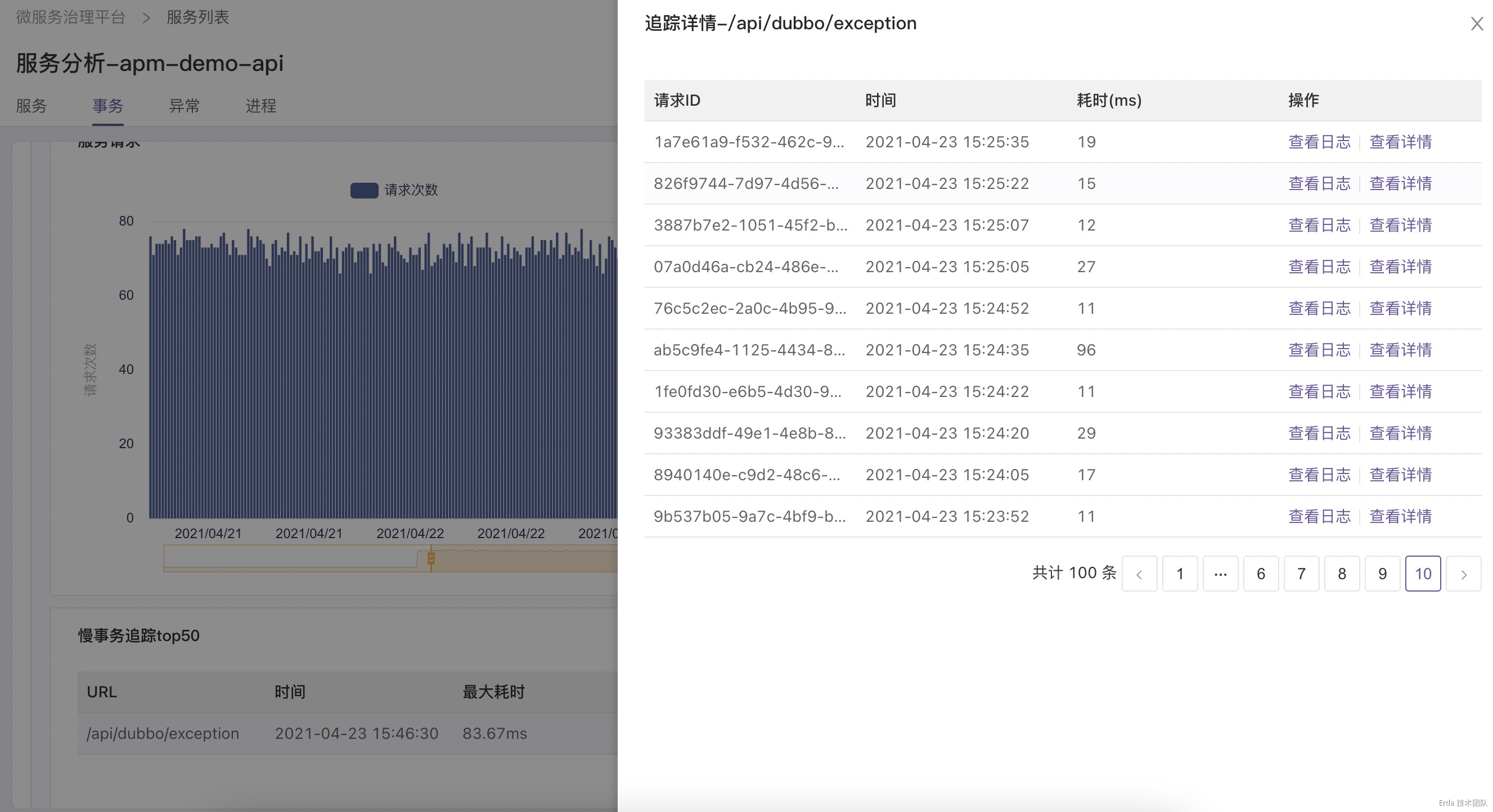
為請求鏈路自動關聯日誌上下文
結語:我們要走向哪裡
基於本文篇幅的限制不再過多的去展示產品細節,我們藉助上面的場景拋磚引玉提出一個可觀測性 APM 產品設計的方向:基於系統和服務觀測的角度把不同數據在後端融合分析,而不是刻意強調系統支持可觀測性三種數據的分別查詢,在產品功能和交互邏輯上儘可能對用戶屏蔽 Metrics、Tracing、Logging 的割裂。除此之外,我們也將繼續探索代碼級診斷、全鏈路分析和智能運維在可觀測性領域的無限可能性。
附:專題目錄
產品篇
- 我們如何定義 APM
- 數據大盤,隨心所欲
- 你需要什麼樣的告警產品
- 徹底打通監控和日誌的邊界
基礎技術篇
- 詳解 Metrics , Tracing 和 Logging
- 剖析 Java Agent
- NodeJS 的自動探針實現
- 瀏覽器探針知多少
- 可擴展 Telegraf
- 容器化日誌採集的實踐
- 流消息的處理利器: Kafka
- 基於 Flink 實現實時計算
- 為什麼我們需要時序數據庫
- ElasticSearch 在時序數據場景的應用
- 了解高性能NoSQL: Cassandra
架構設計篇
- 異構系統的可觀測數據採集架構設計
- 流分析和告警引擎架構設計
- 查詢計算和存儲分離的彈性監控架構設計
參考
《DevOps專題 |監控,可觀測性與數據存儲》
《Metrics, tracing 和 logging 的關係》


