前端數據結構–散列表(哈希表)
散列表的由來
前面說了數組、鏈表,他們各自有自己的特點:
- 數組:具有隨機訪問的特點,可以快速的根據下標訪問到數據,缺點是插入、刪除需要移動數據
- 鏈表:插入、刪除只需要改變結點之間的引用,缺點是查找數據需要從根結點遍歷訪問
散列表是組合了數組和鏈表的優勢,規避它們的不足而產生新的一種數據結構。散列表是一種常用的數據存儲技術,散列後的數據可以快速地插入或取用。
什麼是散列表
散列表英文叫 Hash table,也叫哈希表,是根據關鍵碼值(Key value)而直接進行訪問的數據結構。也就是說,它通過把關鍵碼值映射到表中一個位置來訪問記錄,以加快查找速度。這個映射函數叫做散列函數,存放記錄的數組叫散列表 如下圖所示
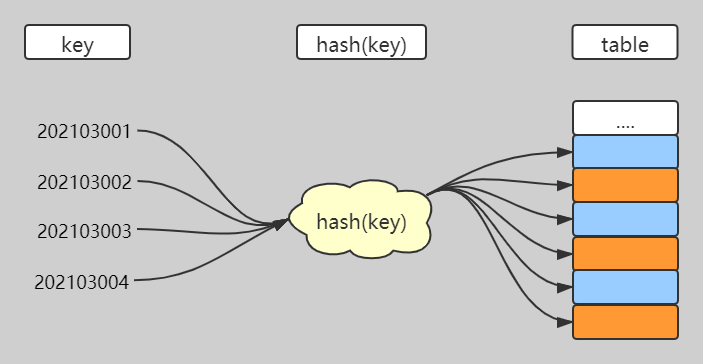
上面的定義可能不那麼清晰,可以嘗試這樣理解, 散列表就是通過散列函數(也叫哈希函數)將元素的鍵映射為數組下標(轉化後的值叫做散列值或哈希值),然後在對應下標的位置存儲記錄值、或者查找記錄值,這種數據結構稱為散列表。
如圖散列表用的是數組支持下標隨機訪問特性,所以散列表其實就是數組的一種擴展,由數組演化而來。可以說,如果沒有數組,就沒有散列表。我們通過散列函數把元素的鍵值映射為下標,然後將數據存儲在數組中對應下標的位置。當我們按照鍵值查詢元素時,我們用同樣的散列函數,將鍵值轉化數組下標,從對應的數組下標的位置取數據。
散列函數
從上面可以看出散列函數在散列表中起着非常核心的作用,散列函數,顧名思義,它是一個函數。我們可以把它定義成 hash(key),其中 key 表示鍵值,hash(key) 的值表示經過散列函數計算得到的散列值,即數組的下標。
基本特點
- 散列函數計算得到的散列值是一個非負整數
- 如果 key1 = key2,那 hash(key1) == hash(key2)
- 如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)
第一點:因為數組下標是從 0 開始的,所以散列函數生成的散列值也要是非負整數。
第二點:相同的 key,經過散列函數得到的散列值也應該是相同的。
第三點:理論上key和散列值是一一對應的,但是種現實是很有可能一個key對應了多個散列值的情況,這就會存在衝突的情況,這取決於散列函數的設計。
設計散列函數
散列函數設計的好壞,決定了散列表衝突的概率大小,也直接決定了散列表的性能。一個好的散列函數基本滿足兩個原則
1、計算hash值簡單
過於複雜的散列函數,會消耗很多計算時間,也就間接地影響到散列表的性能,因此散列涵的計算要簡單、快速。
2、散列函數計算出來的地址要分佈均勻
散列函數生成的值要儘可能隨機並且均勻分佈,這樣才能避免或者最小化散列衝突,即便出現衝突,散列到每個槽里的數據也會比較平均,這樣可以保證存儲空間的合理使用。
實際工作中,我們還需要綜合考慮各種因素。這些因素有關鍵字的長度、特點、分佈、還有散列表的大小等。
常用設計散列函數基本思路:
1、直接地址法
1 hash(key) = a * key + b // a、b為常數
這種方法計算最簡單,不會產生衝突,適合關鍵字的分佈比較連續,而且長度較小的情況,如果關鍵字不連續,空位就會比較多,就會造成存儲空間的浪費。
假如我們有 20 名選手參加學校運動會。為了方便記錄成績,每個選手胸前都會貼上自己的參賽號碼。這 20 名選手的號碼依次是 1 到 20。現在希望實現這樣一個功能,通過號碼快速找到對應的選手信息。
我們可以把號碼為 1 的選手,我們放到數組中下標為 1 的位置;號碼為 2 的選手,我們放到數組中下標為 2 的位置。以此類推,號碼為 k 的選手放到數組中下標為 k 的位置。即我們的哈希函數只要返回對應的key 即可;
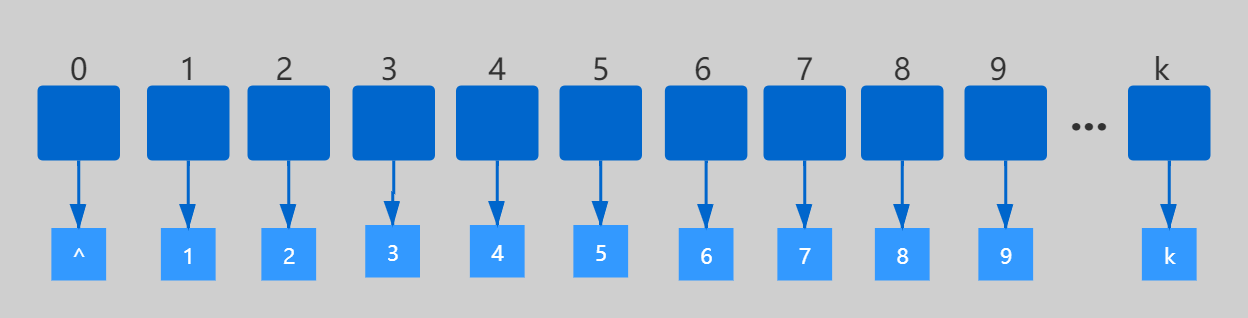
1 function hash (key) { 2 return key 3 }
2、數字分析法
1 function hash (key) { 2 return String(key).substring(6) 3 }
3、平方取中法
4、摺疊法
5、除留餘數法
除留餘數法是使用的比較多的一種,公式為:
1 hash(key) = key % p
如果散列表的表長為m,p為小於等於m的最大的質數,在一般情況下,對質數取余會讓衝突更少,數據元素在散列表分佈的更均勻。
質數又稱素數,除了1和自身,不能被其他自然數整除的數 如(2,3,5,7,11,13,17,…)
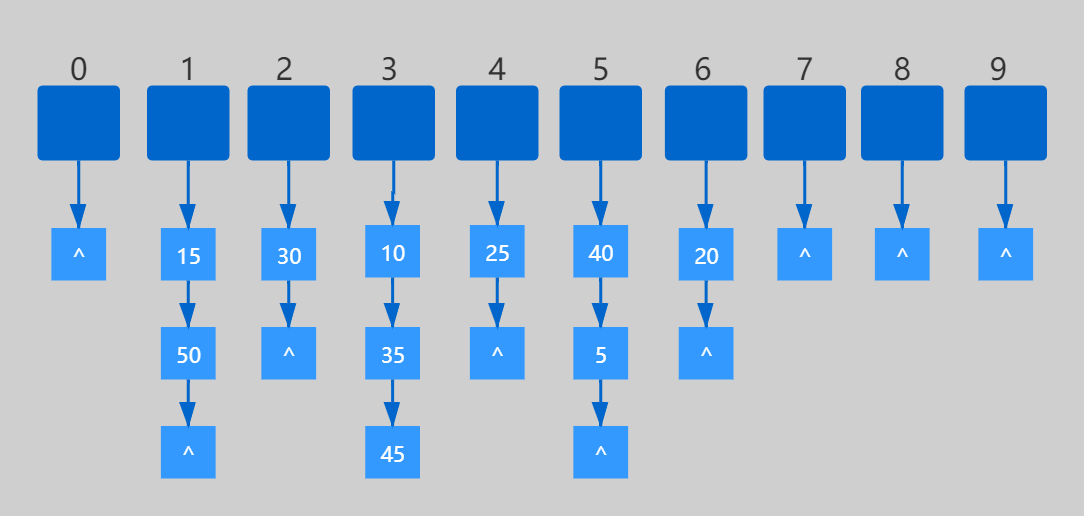
如有數據 { 10,15,20,25,30,35,40,45,50 },表長為10,那麼我們對 7 取余如下,其中 ^ 表示為空的鏈表:
6、隨機數法
選擇一個隨機函數,用關鍵字作為隨機函數的種子,返回值作為散列地址,即
hash(key) = radmom(key)
可結合除留餘數
總結散列函數基本設計原則
散列函數設計沒有固定的方法,需要結合實際情況考慮如下因素:
- 要清楚關鍵字分佈的情況、範圍、規律,結合上面常用幾種方法,寫出散列函數
- 散列表的大小要合理,太大浪費空間太小則容易產生衝突
- 散列表的數據分佈要均勻,不要一些下標中有很多元素,其他的沒有或者很少
- 散列函數代碼要精簡,追求的是簡單高效、分佈均勻
散列衝突
再好的散列函數也無法避免散列衝突,因為散列值是非負整數,總量是有限的,但是現實世界中要處理的鍵值是無限的,將無限的數據映射到有限的集合,肯定避免不了衝突。即便像業界著名的MD5、SHA、CRC等哈希算法,也無法完全避免這種散列衝突。而且,因為數組的存儲空間有限,也會加大散列衝突的概率。
我們常用的散列衝突解決方法有兩類,開放尋址法(open addressing)和鏈表法(chaining)。下面簡單介紹下鏈表法
鏈表法
鏈表法是一種更加常用的散列衝突解決辦法,在散列表中,每個下標會對應一條鏈表,所有散列值相同的元素我們都放到相同槽位對應的鏈表中。
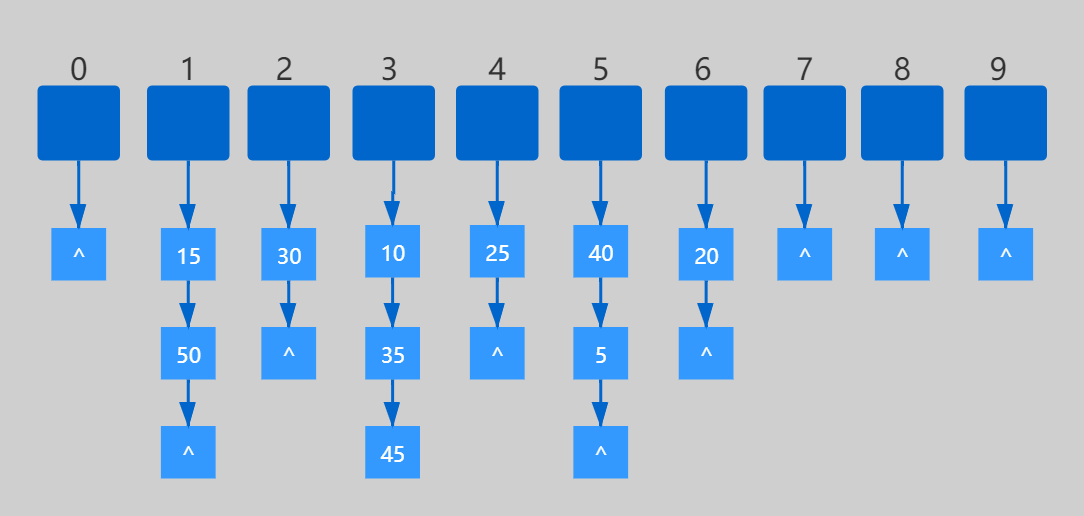
每一個數組下標對應的鏈表可以是單鏈表也可以是雙鏈表。
當插入的時候,我們只需要通過散列函數計算出對應的下標,將其插入到對應鏈表中即可,所以插入的時間複雜度是 O(1)。
當查找、刪除一個元素時,我們同樣通過散列函數計算出對應下標,然後遍歷鏈表查找或者刪除。
前端哈希數據結構
javascript 中的Object、Set、WeakSet、Map、WeakMap 都是哈希結構。


