Apache Hudi C位!雲計算一哥AWS EMR 2020年度回顧
- 2021 年 4 月 17 日
- 筆記
1. 概述
成千上萬的客戶在Amazon EMR上使用Apache Spark,Apache Hive,Apache HBase,Apache Flink,Apache Hudi和Presto運行大規模數據分析應用程序。Amazon EMR自動管理這些框架的配置和擴縮容,並通過優化的運行時提供更高性能,並支持各種Amazon Elastic Compute Cloud(Amazon EC2)實例類型和Amazon Elastic Kubernetes Service(Amazon EKS)集群。Amazon EMR方便數據工程師和數據科學家通過Amazon EMR Studio(預覽版)和Amazon EMR Notebook輕鬆開發、可視化和調試數據科學應用程序。
可以參考來自客戶在2020 AWS re:Invent大會上的一些talk
- How Nielsen built a multi-petabyte data platform using Amazon EMR
- Contextual targeting and ad tech migration best practices
- The right tool for the job: Enabling analytics at scale at Intuit
以下博客提供了更多信息
- How the Allen Institute uses Amazon EMR and AWS Step Functions to process extremely wide transcriptomic datasets
- How the ZS COVID-19 Intelligence Engine helps Pharma & Med device manufacturers understand local healthcare needs & gaps at scale
- Dream11』s journey to building their Data Highway on AWS
- Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
回顧2020年,EMR團隊致力於以較低的價格提供更好的Amazon EMR性能,並使Amazon EMR在LakeHouse架構中更易於管理和更易於分析,本篇文章總結了過去一年的主要改進。
2. 差異化的引擎性能
Amazon EMR簡化了大數據環境和應用程序的構建和運維,可以在幾分鐘內啟動EMR群集,並且無需擔心基礎架構設置、集群設置、配置或調優。Amazon EMR負責這些任務,可以使得團隊集中精力專註業務開發。除了避免構建和管理自己的基礎架構來運行大數據應用程序的運維外,Amazon EMR還提供了比開源發行版更好的性能,並提供了100%的API兼容性。這意味着可以以更快速度運行工作負載而無需修改任何代碼。
適用於Apache Spark的Amazon EMR運行時是針對Spark進行性能優化的運行時。我們首先在2019年11月在Amazon EMR 5.28.0版中引入了適用於Apache Spark的EMR運行時,並使用TPC-DS基準的查詢來衡量相較於開源Spark 2.4的性能提升。測試結果表明相比開源版本查詢執行時間的平均快了2.4倍,總查詢運行時間快了3.2倍,最新結果表明Amazon EMR 5.30的運行速度是沒有運行時的3倍,這意味着運行PB級數據可以以不到傳統本地解決方案一半的成本進行規模分析。
我們還改善了Hive和PrestoDB的性能。2020年4月我們宣布從Amazon EMR 6.0開始支持Hive低延遲分析處理(LLAP)服務。測試表明在Amazon EMR 6.0上使用Hive LLAP比Apache Hive快兩倍。2020年5月我們在Amazon EMR 5.30中引入了PrestoDB的Amazon EMR運行時,使用TPC-DS基準查詢比較了使用運行時的Amazon EMR 5.31與未使用運行時的Amazon EMR 5.29,測試結果表明使用Amazon EMR 5.31和PrestoDB的運行時,查詢執行時間的平均值快2.6倍。
3. 更簡單的增量數據處理
Apache Hudi (Hadoop Upserts, Deletes and Incrementals)是一個開源數據管理框架,用於簡化增量數據處理和數據管道開發,基於Apache Hudi,可以在Amazon Simple Storage Service(Amazon S3)數據湖中執行記錄級的插入,更新和刪除,從而簡化構建變更數據捕獲(CDC)管道,藉助此功能你可以遵守數據隱私法規並簡化數據提取管道,以處理來自流式管道輸入和事務系統CDC等來源的遲到或更新的記錄。Apache Hudi與開源大數據分析框架(例如Apache Spark,Apache Hive和Presto)集成,並以Apache Parquet和Apache Avro等開放格式維護Amazon S3或HDFS中的數據。
我們從2019年11月的Amazon EMR 5.28版本開始支持Apache Hudi。2020年6月Apache Hudi從孵化器畢業,並發佈了0.6.0版本,我們在Amazon EMR 5.31.0、6.2.0及更高版本支持了該版本。Amazon EMR團隊與Apache Hudi社區合作開發了一個新的引導功能特性,該功能用於將Parquet數據集轉化為Hudi數據集,而無需重寫數據集。此引導功能可加快從現有數據集遷移至Apache Hudi數據集過程,經過測試,使用Amazon S3上的1 TB Parquet數據集,引導執行的速度比批量插入快五倍。
在2020年6月,從Amazon EMR版本5.30.0開始支持了HoodieDeltaStreamer實用程序,該實用程序提供了一種從許多來源(包括AWS數據遷移服務(AWS DMS))提取數據的簡便方法,通過此集成,可以以無縫,高效和連續的方式將數據從上游關係數據庫提取到S3數據湖中。有關更多信息,請參閱使用Amazon EMR和AWS數據庫遷移服務上的Apache Hudi將記錄級別變更從關係數據庫應用於Amazon S3數據湖
Amazon Athena和Amazon Redshift Spectrum增加了對基於S3的數據湖中的Apache Hudi數據集查詢的支持。Athena於2020年7月宣布支持查詢Hudi表,而Redshift Spectrum 9月宣布支持查詢Hudi表。你可以繼續使用Amazon EMR中的Apache Hudi對數據集進行更改,然後從Athena和Redshift Spectrum查詢Apache Hudi寫入時複製(CoW)數據集的最新快照。
4. 差異化的實例性能
除了通過Amazon EMR運行時提供更好的軟件性能外,EMR團隊還提供了更多的實例選項,可以選擇為工作負載提供最佳性能和成本的實例,可以根據應用程序的要求選擇在群集中配置哪些類型的EC2實例(標準,高內存,高CPU,高I / O),並完全自定義群集來滿足需求。
2020年12月,我們宣布Amazon EMR現在支持6.1.0、5.31.0及更高版本的M6g,C6g和R6g實例,可以使得能夠使用由AWS Graviton2處理器實例,AWS使用64位Arm Neoverse內核定製設計了Graviton2處理器,為Amazon EC2中運行的雲工作負載提供最佳的價格性能。儘管性能優勢會因工作負載的不同特性而有所不同,基於TPC-DS 3 TB基準測試表明,Apache Spark的EMR運行時與Graviton2相比,性能提高了15%,成本降低了30%。
5. 更容易的集群優化
我們還使優化EMR群集變得更加容易。2020年7月我們推出了Amazon EMR Managed Scaling,這項新功能可自動調整EMR集群大小,從而以最低的成本實現最佳性能。EMR託管擴展無需預先預測工作負載模式,也無需先深入了解應用程序框架(例如Apache Spark或Apache Hive)的規則,相反只需要指定集群最小和最大計算資源限制,Amazon EMR會根據工作負載監視關鍵指標並優化集群大小以實現最佳資源利用率,Amazon EMR可以在高峰期擴大集群規模,並在閑置期間優雅地縮減集群規模,從而將成本降低20–60%。
Amazon EMR 5.30.1及更高版本上的基於Apache Spark,Apache Hive和YARN的工作負載均支持EMR託管擴展,EMR託管擴展支持EMR實例隊列,可以無縫擴展競價型實例、按需實例以及保留的一部分實例,它們都在同一集群中,可以利用Managed Scaling獲取最低成本配置的集群。
2020年10月,我們宣布Amazon EMR支持配置EC2競價型實例的容量優化分配策略,容量優化分配策略會自動利用可用的備用容量,同時仍然可以利用競價型實例提供的大幅折扣,這為Amazon EMR提供了更多選擇。
6. 工作負載合併
以前需要在Amazon EC2上使用完全託管的Amazon EMR或在Amazon EKS上管理Apache Spark之間選擇。在Amazon EC2上使用Amazon EMR時,可以從多種EC2實例類型中進行選擇以滿足價格和性能要求,但是不能在集群上運行多個版本的Apache Spark或其他應用程序,並且不能為非Amazon EMR應用程序使用未使用的容量。在Amazon EKS上對Apache Spark進行自我管理時必須進行繁重的安裝、管理和優化,Apache Spark才能在Kubernetes上運行,並且無法從Amazon EMR優化運行時受益。
2020年12月,我們宣布Amazon EKS上的Amazon EMR合併,這是Amazon EMR新的部署選項,可以在Amazon EKS上運行完全託管的開源大數據框架。如果已經使用Amazon EMR,則可以在同一Amazon EKS集群上將基於Amazon EMR的應用程序與其他基於Kubernetes的應用程序合併以提高資源利用率並使用常見的Amazon EKS工具簡化基礎架構管理。如果當前正在Amazon EKS上自我管理大數據框架,則現在可以使用Amazon EMR來自動進行設置和管理,並利用優化的Amazon EMR運行時來提供更好的性能。
7. 更高的開發生產力
使用Amazon EMR的目標不僅是要為大數據分析工作負載實現最佳的價格性能,而且還要提供業務新見解。
2020年11月我們發佈了Amazon MWAA,這是一項完全託管的服務,可輕鬆在AWS上運行Apache Airflow的開源版本以及構建工作流以運行提取,轉換和加載(ETL)作業和數據管道。Airflow流程使用Athena查詢從Amazon S3等來源檢索輸入,在EMR集群上執行轉換,並可以使用所得數據在Amazon SageMaker上訓練機器學習(ML)模型。使用Python編程語言,將Airflow中的工作流編寫為有向非循環圖(DAG)。
在AWS re:Invent 2020上我們介紹了EMR Studio的預覽,EMR Studio使數據科學家可以輕鬆地開發、可視化和調試用R,Python,Scala和PySpark編寫的應用程序。它提供了完全託管的Jupyter筆記本以及Spark UI和YARN Timeline Service之類的工具來簡化調試,用戶可以將應用程序所需的自定義Python庫或Jupyter內核直接安裝到EMR集群,並可以連接到代碼存儲庫(例如AWS CodeCommit,GitHub和Bitbucket)進行協作。
EMR Studio內核和應用程序在EMR群集上運行,因此使用針對Apache Spark進行了性能優化的EMR運行時可以獲得分佈式數據處理的優勢。也可以在AWS Service Catalog中創建集群模板以簡化數據科學家和數據工程師的工作負擔,並可以利用在Amazon EC2/Amazon EKS上運行的EMR集群。
8. 統一治理
在AWS我們建議使用現代化的Lakehouse架構來構建雲上數據和分析基礎架構。這不僅涉及將數據湖與數據倉庫集成在一起,而且還涉及將數據湖、數據倉庫和專用分析服務集成在一起,並實現統一的治理和數據移動。
如下圖所示,Amazon EMR與Amazon S3,Amazon Redshift等一起構成AWS上Lakelouse體系結構。
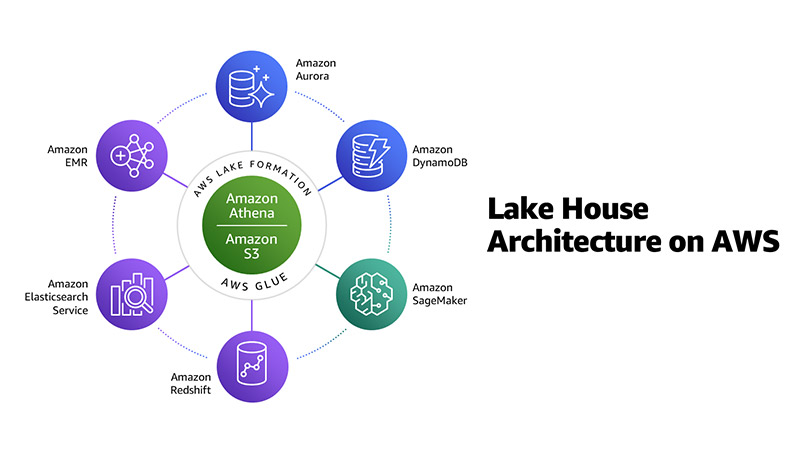
現代分析體系結構中最重要的部分之一就是可以授權、管理和審核對數據的訪問。AWS提供了細粒度的訪問控制和治理,可以從一個控制點管理跨整個數據湖的數據訪問以及專用數據存儲和分析服務。
在2021年1月Amazon EMR集成了Apache Ranger,Apache Ranger是一個開源項目,為Hadoop和相關的大數據應用程序(如Apache Hive,Apache HBase和Apache Kafka)提供授權和審核功能。從Amazon EMR 5.32開始,Apache Ranger 2.0插件可啟用對Apache SparkSQL,Amazon S3和Apache Hive授權和審核功能。可以設置多租戶EMR集群,使用Kerberos進行用戶身份驗證,使用Apache Ranger 2.0進行授權,以及為數據庫、表、列和S3對象配置細粒度的數據訪問策略。


