A* 搜索算法
前言
A 星搜索算法發表於 1968 年屬於比較老、成熟的算法,由 Stanford 研究院的 Peter Hart, Nils Nilsson 以及 Bertram Raphael 發表。介紹 A 星算法本來應該先了解 A 算法,但這裡先不說 A 算法,先來感性的了解一下跟它有關的其他算法。
廣度優先搜索算法

如上圖所示,廣度優先算法,首先從起始點出發,逐步遍歷完周圍的所有點,然後再遍歷周圍點的周圍所有點,如水波一樣向外擴散,直到找到終點。但這樣的做法需要遍歷較多點,而且並不是所有方向都值得我們去變量,使算法的計算複雜度和效率都十分低。
Dijkstra 算法
要知道的是廣度優先搜索算法認為移動到所有格子的代價是一致的,但事實上不是這樣的。比如,高速路和城區路的速度就不一樣,所消耗的時間成本也就不一樣。

上圖所示,假如在綠色方格之間移動代價是褐色的三倍,也許就不能簡單的走直線了。Dijkstra 算法每決定移動一個格子都會計算它離起點所需要的代價,這個代價我們即為 \(g(n)\),\(n\) 表示移動到第 n 個方格時需要付出的代價。當然在走出第 n 步時有多個方格可以供選擇,但每個方格所需要付出的代價肯定不一樣,Dijkstra 算法會選擇最小代價的方格。如圖,它就不會簡單地穿過綠色到達終點了。當 \(g(n)\) 為到起點的歐式距離或者曼哈頓距離的線性關係,那麼 Dijkstra 算法就退化為廣度優先搜索算法。
最佳優先搜索算法
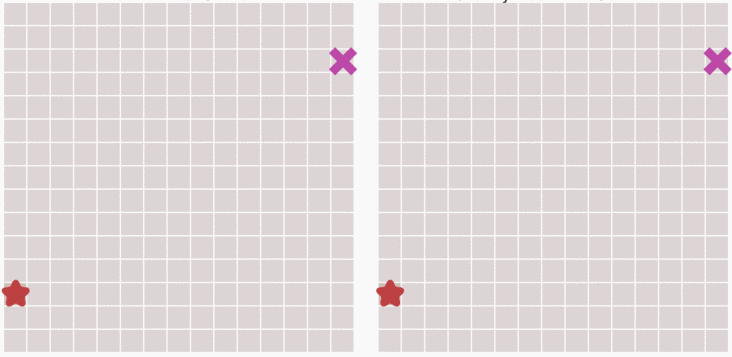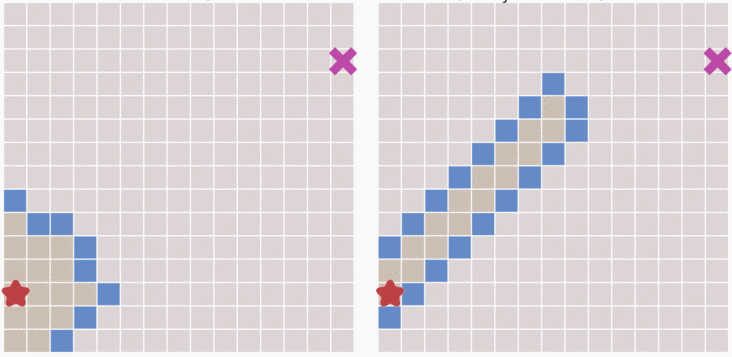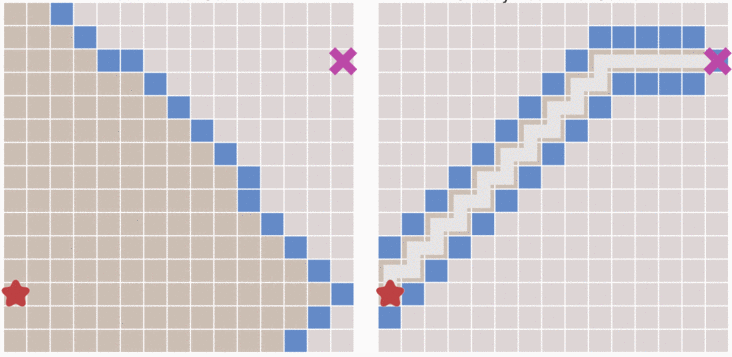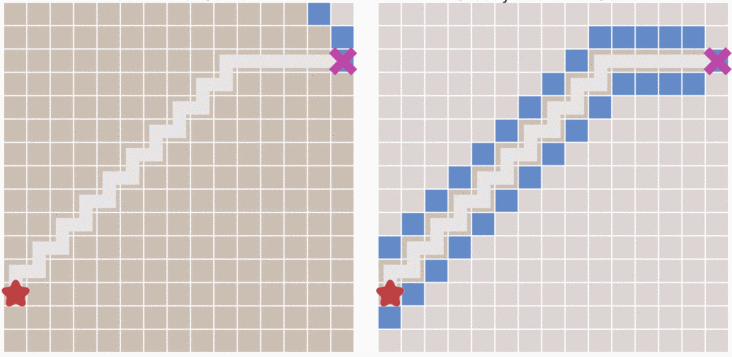
Dijkstra 算法是根據距離起點的代價來計算下一步該選擇哪一個格子的,那麼如果我們最開始就預先估計下一步中的所有格子哪一個離終點更近,這樣也能更快到達終點。如上圖,所示每次選取都選擇離終點最近的格子,然後再遍歷這個格子附近的格子哪個離終點更近(一般使用 \(h(n)\) 表示第 n 個格子到終點的代價)這種算法稱之為最佳優先算法。

當然這種算法很容易受到估計函數 \(h(n)\) 的影響,如果估計函數取得不當也許就不是最短路徑了。
A * 搜索算法
A 星算法則是整合上述的優缺點,首先來明白幾個概念:
♠ \(g(n)\) 代表移動到第 n 個方格時距離起點的代價。\(g(n)\) 的大小肯定是跟之前的 n-1 個格子的選擇有關的,但是每次選擇肯定都是選擇代價最小的格子(如果僅用 \(g(n)\) 來衡量)。
♣ \(h(n)\) 代表移動到第 n 個方格時距離終點的估計代價(往往我們並不完全知道這個格子距離終點需要多少代價)。\(h(n)\) 的大小範圍(也就是第 n 步能選擇的範圍)當然也是跟之前的 n-1 個格子的選擇有關的,但是每次選擇肯定都是選擇代價最小的格子(如果僅用 \(h(n)\) 來衡量)。
♥ \(f(n)\) 是整體的估價函數,一般 \(f(n) = g(n) + h(n)\)。
算法細節
一般會用兩個表來記錄整個找路徑的過程,一個稱之為 open 表(用於存儲可能的選擇),另外一個稱之為 closed 表(用於存儲已經做的選擇):
- 首先將初始的節點 \(s_0\)(可以理解為起點的格子)放入 open 表中,因為沒有其他選擇-_-。此時 \(f(s_0) = g(s_0) + h(s_0)\);
- 如果 open 表為空,表示上一步沒有留下可以被選擇的節點,則問題無解,退出搜索;
- 把 open 表的第一個節點取出來放入 closed 表,並記該節點為 \(n\)(即第 n 步選擇的節點)。
- 考察節點 n 是否為目標節點,若是,找到問題解,退出。
- 若節點 n 不可以擴展,則轉到第二步;
- 擴展節點 n(即查看這個格子周圍的格子),生成子節點 \(n_i \ (i=1,2,3,\dots)\),首先這些子節點得不在 closed 表中,也不再 open 表中,然後放入 open 表中。計算每個子節點的估價值 \(f(n_i)\),並按估價值從小到大的順序排好。
- 轉至第二步。
由上述算可知,open 表用一個優先隊列,closed 表用一個鏈表就可以了。
A * 算法的一些性質
首先介紹 \(f^*(n)\) 的定義:其為從初始節點 \(s_0\) 出發,經過節點 n 達到目標節點的真實計算的最小代價值(不存在估計),易得如果此點在最優路徑上,那麼 \(f^*\) 為選擇最優路徑時的代價值,並且在最優路徑上的所有點有:\(f^*(n_0) = f^*(n_1) = f^*(n_2) = f^*(n_3) = \dots\)(因為 \(f^*\) 在計算經過某一個點的時候必然計算了也只計算了最優路徑上其他所有的點。)
又由於 \(f^*(n) = g^*(n) + h^*(n)\),因此 \(g^*(n)\) 為從初始節點 \(s_0\) 出發,**經過節點 n ** 時的最短路徑的代價值,雖然這條路徑很容易算出來,並且有可能還沒找到最短的那一條,所以 \(g(n)\) 依然是對 \(g^*(n)\) 的估計。\(h^*(n)\) 則是從節點 n 出發到目標節點的最短路徑的代價值,如果有多個目標節點選擇最短的那一條。
A * 算法對上述進行了限制:
♥ \(g(n)\) 是對 \(g^*(n)\) 的估計,且有 \(g(n) \gt g^*(n) \ge 0\)。
♦ \(h(n)\) 會被設計為 \(h^*(n)\) 的下界,且有 \(h^*(n) \gt h^(n)\)。
可納性
首先,搜索算法能在有限步內找到一條初始節點到目標節點的最佳路徑,並在此路徑上結束,則稱該搜索算法是可納的。(先只考慮有限圖)對於有限圖,如果從初始節點到目標節點有路徑存在,則 A * 算法一定能成功結束。
這裡在設計 A 星算法的 \(f(n)\) 需要滿足其是遞增的。那就可以簡單證明一下了,因為從 \(s_0\) 離開 open 進入 closed,必有最優路徑上的 \(n_1\) 加入 open,則有:
f(n_1) &= g(n_1) + h(n_1) \\
&= g^*(n) + h(n_1) \\
&\le g^*(n) + h^*(n) = f^*(n_1) = f^*(s_0) = f(s_0)
\end{aligned}
\]
由於 \(f(n)\) 是遞增易得:\(f(n_1)=f(s_0)\),而其餘點的 \(f\) 都是大於或等於 \(f(s_0)\) 的,因此肯定會選擇 \(n_1\) 進行擴展,而當 \(n_1\) 進入 closed,\(n_2\) 又會加入 open。由此,可預料算法不僅會成功結束,還會以最優路徑而結束。
最優性
A 星算法的搜索效率其實極大取決於 \(h(n)\),因為 \(h(n) \le h^*(n)\) 的,所以它越大可以擴展的節點就越少,搜索的效率就越高。此外,關於 \(h(n)\) 的設計還需要滿足:
對於任意節點 \(n_i\) 到其子節點 \(n_j\) 有:\(h(n_i) \le h(n_j) + c(n_i,n_j)\)。其中 \(c(n_i,n_j)\) 代表從父節點到子節點需要的代價,其實可以表示為 \(g(n_j) – g(n_i)\)。ze上式可表達為:
\]
這不就是說 \(f\) 是遞增的嗎,因此 A 星算法只要在有限域內存在最優路徑,滿足對 \(g,h\) 的設計下一定能取得最優解。


