Redis持久化——內存快照(RDB)
我們都知道Redis是內存數據庫,它將自己的數據存儲的內存中。這樣一旦服務器進程退出(斷電、重啟等原因),那麼數據將會丟失。為了解決這個問題,Redis提供兩種持久化的方式來將數據持久化到硬盤上,即內存快照(RDB)與AOF日誌。
1 什麼是內存快照
所謂內存快照,顧名思義就是給內存拍個照,在某個時刻把內存中的數據記錄下來,以文件的形式保存到硬盤上,這樣即使宕機,數據依然存在。在服務器重啟後只需要把「照片」中的數據恢復即可。
RDB持久化就是把當前進程的數據在某個時刻生成快照(一個壓縮的二進制文件)保存到硬盤的過程,觸發RDB持久化過程分為手動觸發和自動觸發。
1.1 RDB文件的創建
RDB文件的創建可以手動觸發,也可以自動觸發。
1.1 手動觸發
手動觸發分別對應save和bgsave命令:
1.1.1 save命令
save命令會阻塞當前Redis服務器,直到RDB過程完成為止。在服務器進程阻塞期間,服務器不能處理任何命令請求。因此,當save命令正在執行時,客戶端發送的所有命令都會被拒絕,知道save命令執行完畢。
redis>save //等待,直到RDB文件創建完畢
ok
注意:
Redis的單線程模型就決定了,我們要盡量避免所有會阻塞主線程的操作,由於Save命令執行期間阻塞服務器進程,對於內存比較大的實例會造成長時間阻塞,因此線上環境不建議使用。
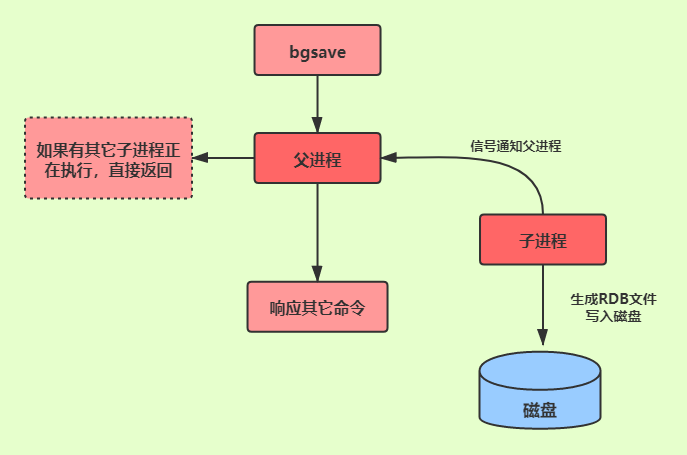
1.1.2 bgsave命令
bgsave命令會派生出一個子進程(而不是線程),由子進程進行RDB文件創建,而父進程繼續處理命令。
redis>bgsave
Background saving started //直接返回,由子進程進行RDB文件創建
redis> //繼續處理其它命令
注意:
- 在bgsave命令執行的時候,為了避免父進程與子進程同時執行兩個rdbSave的調用而產生競爭條件,客戶端發送的save命令會被服務器拒絕。
- 如果bgsave命令正在執行,bgrewriteaof(aof重寫)命令會被延遲到bgsave命令之後執行,如果bgrewriteaof命令正在執行,那麼客戶端發送的bgsave命令會被服務器拒絕。
- 雖然bgsave命令是由子進程進行RDB文件的生成,但是fork()創建子進程的時候會阻塞父進程(詳情請往下看)。
1.2 自動觸發
因為bgsave命令可以在不阻塞服務器進程的情況下保存,所以redis可以通過設置服務器配置的save選項,讓服務器每隔一段時間自動執行一次bgsave命令。如:我們向服務器設置如下配置(這也是redis默認的配置):
save 900 1
save 300 10
save 60 10000
那麼只要滿足如下條件中的一個bgsave命令就會被執行:
- 服務器在900秒內對數據庫進行了至少1次修改
- 服務器在300秒內對數據庫進行了至少10次修改
- 服務器在60秒內對數據庫進行了至少10000次修改
1.2 RDB文件的載入
在Redis啟動的時候,只要檢測到RDB文件的存在,就會自動加載RDB文件。需要注意的是
-
因為AOF文件的更新頻率通常比RDB文件的更新頻率高,所以口如果服務器開啟了AOF持久化功能,那麼服務器會優先使用AOF文件來還原數據庫狀態。
-
只有在AOF持久化功能處於關閉狀態時,服務器才會使用RDB文件來還原數據庫狀態。
注意:服務器在載入RDB文件期間,會一直處於阻塞狀態,直到載入工作完成為止
2 內存快照的問題
了解了什麼是Redis的RDB持久化,我們來思考兩個問題。
2.1 快照的時候數據可以修改嗎
Redis RDB持久化是對某一時刻的內存中的全量數據進行拍照。這讓我們不得不思考,快照的時候數據可以修改嗎?
首先,如果我們使用save命令做持久化,那麼由於Redis單線程模型的原因,在持久化的過程中會阻塞,是不能執行其它命令的。也許有人會說可以使用bgave命令,但使用bgsave就沒有問題了嗎?
我們在拍照的時候,通常攝影師是不讓我們動的,因為一動可能照片就模糊了。在Redis 進行內存快照的時候也會如此。如果我們持久化的過程中,有些數據被修改了。那麼就會破壞快照的正確性與完整性。
比如在t時刻,我們對內存進行快照,此時我們希望的是記錄下來t時刻內存中所有的數據,假設我們的RDB操作需要10s的時間,而t+2s我們執行了一個修改操作把Key1的值由A修改成了B,而此時RDB操作卻還沒有把Key1的值寫入磁盤。在t+5s的時候讀取到key1的值寫入磁盤。那麼此次快照記錄的Key1的值就是B,而不是t時刻的A。這樣就破壞了RDB文件的正確性。
RDB文件的生成是需要時間的,如果快照執行期間數據不能被修改,對於業務系統來說不能接受的。那麼Redis 是如何解決這個問題的呢?
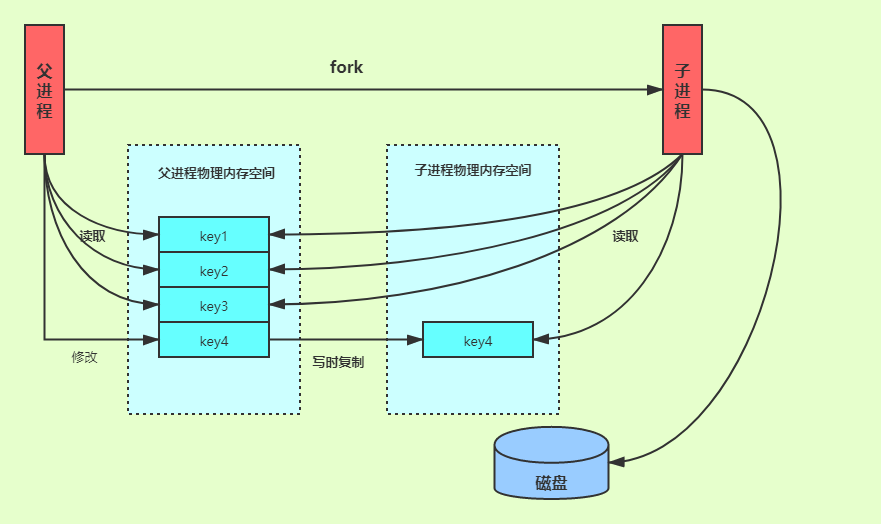
Redis 藉助了操作系統提供的寫時複製技術(Copy-On-Write, COW),可以讓在執行快照的同時,正常處理寫操作。簡單來說,bgsave fork子進程的時候,並不會完全複製主進程的內存數據,而是只複製必要的虛擬數據結構,並不為其分配真實的物理空間,它與父進程共享同一個物理內存空間。bgsave 子進程運行後,開始讀取主線程的內存數據,並把它們寫入 RDB 文件。此時,如果主線程對這些數據也都是讀操作,那麼,主線程和 bgsave 子進程相互不影響。但是,如果主線程要修改一塊數據,此時會給子進程分配一塊物理內存空間,把要修改的數據複製一份,生成該數據的副本到子進程的物理內存空間。然後,bgsave 子進程會把這個副本數據寫入 RDB 文件,而在這個過程中,主線程仍然可以直接修改原來的數據。
2.2 可以頻繁進行快照操作嗎
假設我們在t 時刻做了一次快照,然後又在 t+n 時刻做了一次快照,而在這期間,發生了數據修改。而此時宕機了,那麼,只能按照 t 時刻的快照進行恢復。那麼這n秒的數據就徹底丟失無法恢復了。
所以,要想儘可能恢複數據,就只能縮短快照執行的時間間隔,間隔的時間越小,丟失數據也就越少。那麼可以頻繁的執行快照操作嗎?
我們知道bgsave 執行時並不阻塞主線程,但是這不代表可以頻繁執行快照操作。
一方面,持久化是一個寫入磁盤的過程,頻繁將全量數據寫入磁盤,會給磁盤帶來很大壓力,頻繁執行快照也容易導致前一個快照還沒有執行完,後一個又開始了,這樣多個快照競爭有限的磁盤帶寬,容易造成惡性循環。
再者,bgsave所fork出來的子進程執行操作雖然並不會阻塞父進程的操作,但是fork出子進程的操作卻是由主進程完成的,會阻塞主進程,fork子進程需要拷貝進程必要的數據結構,其中有一項就是拷貝內存頁表(虛擬內存和物理內存的映射索引表),這個拷貝過程會消耗大量CPU資源,拷貝完成之前整個進程是會阻塞的,阻塞時間取決於整個實例的內存大小,實例越大,內存頁表越大,fork阻塞時間也就越久。
也許有人會想到是否可以做增量快照呢?也就是只對上一次快照之後的數據做快照。
首先思路肯定是可以,但是增量快照要求記住哪些數據上一次快照之後產生的。這就需要額外的元數據來記錄這些信息,會引入額外的空間消耗。這對於內存資源寶貴的 Redis 來說,並不是一個很好的方案。
如果不能頻繁執行快照操作,那麼該如何解決兩次快照之間的數據丟失的問題呢?Redis 還提供了另外一種持久化方式——AOF(append to file)日誌。
關於AOF日誌請看Redis持久化——AOF日誌


