從網絡請求過程看OkHttp攔截器
- 2021 年 4 月 6 日
- 筆記
前言
之前我們結合設計模式簡單說了下OkHttp的大體流程,今天就繼續說說它的核心部分——攔截器。
因為攔截器組成的鏈其實是完成了網絡通信的整個流程,所以我們今天就從這個角度說說各攔截器的功能。
首先,做一下簡單回顧,從getResponseWithInterceptorChain方法開始。
簡單回顧(getResponseWithInterceptorChain)
internal fun getResponseWithInterceptorChain(): Response {
// Build a full stack of interceptors.
val interceptors = mutableListOf<Interceptor>()
interceptors += client.interceptors
interceptors += RetryAndFollowUpInterceptor(client)
interceptors += BridgeInterceptor(client.cookieJar)
interceptors += CacheInterceptor(client.cache)
interceptors += ConnectInterceptor
if (!forWebSocket) {
interceptors += client.networkInterceptors
}
interceptors += CallServerInterceptor(forWebSocket)
val chain = RealInterceptorChain(
interceptors = interceptors
//...
)
val response = chain.proceed(originalRequest)
}
這些攔截器會形成一條鏈,組織了請求接口的所有工作。

以上為上節內容,不了解的朋友可以返回上一篇文章看看。
假如我來設計攔截器
先拋開攔截器的這些概念不談,我們回顧下網絡通信過程,看看實現一個網絡框架至少要有哪些功能。
請求過程:封裝請求報文、建立TCP連接、向連接中發送數據響應過程:從連接中讀取數據、處理解析響應報文
而之前說過攔截器的基本代碼格式是這樣:
override fun intercept(chain: Interceptor.Chain): Response {
//做事情A
response = realChain.proceed(request)
//做事情B
}
也就是分為 請求前工作,請求傳遞,獲取響應後工作 三部分。
那我們試試能不能把上面的功能分一分,設計出幾個攔截器?
攔截器1: 處理請求前的請求報文封裝,處理響應後的響應報文分析
誒,不錯吧,攔截器1就用來處理 請求報文和響應報文的一些封裝和解析工作。就叫它封裝攔截器吧。
攔截器2: 處理請求前的建立TCP連接
肯定需要一個攔截器用來建立TCP連接,但是響應後好像沒什麼需要做連接方面的工作了?那就先這樣,叫它連接攔截器吧。
攔截器3:處理請求前的數據請求(寫到數據流中)處理響應後的數據獲取(從數據流拿數據)
這個攔截器就負責TCP連接後的 I/O操作,也就是從流中讀取和獲取數據。就叫它 數據IO攔截器 吧。
好了,三個攔截器好像足夠了,我得意滿滿的偷看了一眼okhttp攔截器代碼,7個???我去。。
那再思考思考🤔…,還有什麼情況沒考慮到呢?比如失敗重試?返回301重定向?緩存的使用?用戶自己對請求的統一處理?
所以又可以模擬出幾個新的攔截器:
攔截器4:處理響應後的失敗重試和重定向功能
沒錯,剛才只考慮到請求成功,請求失敗了要不要重試呢?響應碼為301、302時候的重定向處理?這都屬於要重新請求的部分,肯定不能丟給用戶,需要網絡框架自己給處理好。就叫它 重試和重定向攔截器吧。
攔截器5:處理響應前的緩存復用,處理響應後的緩存響應數據。
還有一個網絡請求有可能的需求就是關於緩存,這個緩存的概念可能有些朋友了解的不多,其實它多用於瀏覽器中。
瀏覽器緩存一般分為兩部分:強制緩存和協商緩存。
強制緩存就是服務器會告訴客戶端該怎麼緩存,例如 cache-Control 字段,隨便舉幾個例子:
private:所有內容只有客戶端可以緩存,Cache-Control的默認取值max-age=xxx:表示緩存內容將在xxx秒後失效no-cache:客戶端緩存內容,但是是否使用緩存則需要經過協商緩存來驗證決定no-store:所有內容都不會被緩存,即不使用強制緩存,也不使用協商緩存
協商緩存就是需要客戶端和服務器進行協商後再決定是否使用緩存,比如強制緩存過期失效了,就要再次請求服務器,並帶上緩存標誌,例如Etag。
客戶端再次進行請求的時候,請求頭帶上If-None-Match,也就是之前服務器返回的Etag值。
Etag值就是文件的唯一標示,服務器通過某個算法對資源進行計算,取得一串值(類似於文件的md5值),之後將該值通過etag返回給客戶端
然後服務器就會將Etag值和服務器本身文件的Etag值進行比較,如果一樣則數據沒改變,就返回304,代表你要請求的數據沒改變,你直接用就行啦。
如果不一致,就返回新的數據,這時候的響應碼就是正常的200。
這個攔截器就是用於處理這些情況,我們就叫它 緩存攔截器 吧。
- 攔截器6: 自定義攔截器
最後就是自定義的攔截器了,要給開發者一個可以自定義的攔截器,用於統一處理請求或響應數據。
這下好像齊了,至於之前說的7個攔截器還有1個,留個懸念最後再說。
最後再給他們排個序吧:
- 1、自定義攔截器的公共參數處理。
- 2、封裝攔截器封裝請求報文
- 3、緩存攔截器的緩存復用。
- 4、連接攔截器建立TCP連接。
- 5、IO攔截器的數據寫入。
- 6、IO攔截器的數據讀取。
- 7、緩存攔截器保存響應數據緩存。
- 8、封裝攔截器分析響應報文
- 9、重試和重定向攔截器處理重試和重定向情況。
- 10、自定義攔截器統一處理響應數據。
有點繞,來張圖瞧一瞧:
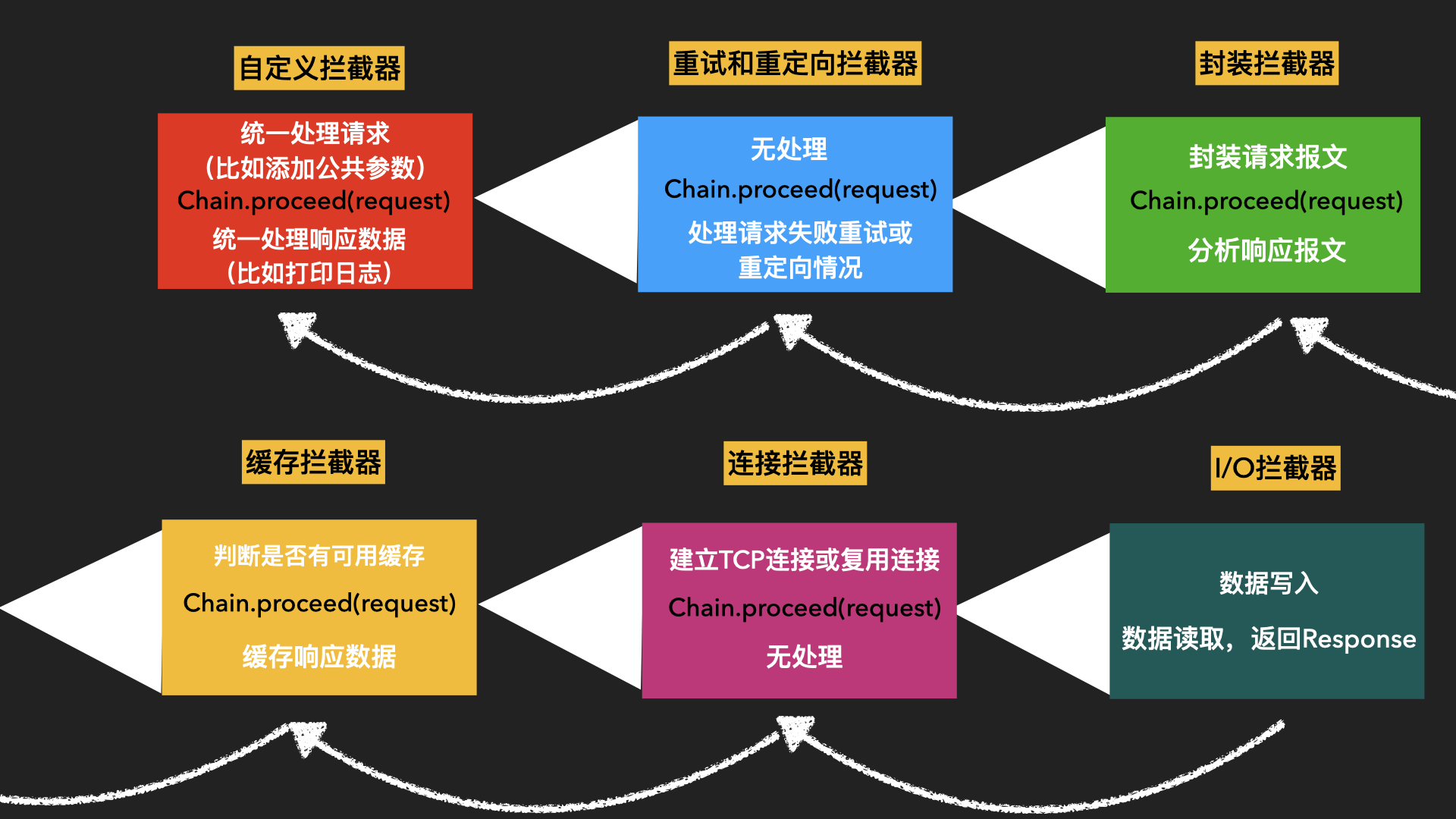
所以,攔截器的順序也基本固定了:
- 1、自定義攔截器
- 2、重試和重定向攔截器
- 3、封裝攔截器
- 4、緩存攔截器
- 5、連接攔截器
- 6、IO攔截器
下面具體看看吧。
自定義攔截器
在請求之前,我們一般創建自己的自定義攔截器,用於添加一些接口公共參數,比如把token加到Header中。
class MyInterceptor() : Interceptor {
override fun intercept(chain: Interceptor.Chain): Response {
var request = chain.request()
request = request.newBuilder()
.addHeader("token", "token")
.url(url)
.build()
return chain.proceed(request)
}
要注意的是,別忘了調用chain.proceed,否則這條鏈就無法繼續下去了。
在獲取響應之後,我們一般用攔截器進行結果打印,比如常用的HttpLoggingInterceptor。
addInterceptor(
HttpLoggingInterceptor().apply {
level = HttpLoggingInterceptor.Level.BODY
}
)
重試和重定向攔截器(RetryAndFollowUpInterceptor)
為了方便理解,我對源碼進行了修剪✂️:
class RetryAndFollowUpInterceptor(private val client: OkHttpClient) : Interceptor {
@Throws(IOException::class)
override fun intercept(chain: Interceptor.Chain): Response {
while (true) {
try {
try {
response = realChain.proceed(request)
} catch (e: RouteException) {
//路由錯誤
continue
} catch (e: IOException) {
// 請求錯誤
continue
}
//獲取響應碼判斷是否需要重定向
val followUp = followUpRequest(response, exchange)
if (followUp == null) {
//沒有重定向
return response
}
//賦予重定向請求,再次進入下一次循環
request = followUp
}
}
}
}
這樣代碼就很清晰了,重試和重定向的處理都是需要重新請求,所以這裡用到了while循環。
- 當發生請求過程中錯誤的時候,就需要重試,也就是通過continue進入下一次循環,重新走到
realChain.proceed方法進行網絡請求。 - 當請求結果需要
重定向的時候,就賦予新的請求,並進入下一次循環,重新請求網絡。 - 當請求結果沒有重定向,那麼就直接返回
response響應結果。
封裝攔截器(BridgeInterceptor)
class BridgeInterceptor(private val cookieJar: CookieJar) : Interceptor {
@Throws(IOException::class)
override fun intercept(chain: Interceptor.Chain): Response {
//添加頭部信息
requestBuilder.header("Content-Type", contentType.toString())
requestBuilder.header("Host", userRequest.url.toHostHeader())
requestBuilder.header("Connection", "Keep-Alive")
requestBuilder.header("Accept-Encoding", "gzip")
requestBuilder.header("Cookie", cookieHeader(cookies))
requestBuilder.header("User-Agent", userAgent)
val networkResponse = chain.proceed(requestBuilder.build())
//解壓
val responseBuilder = networkResponse.newBuilder()
.request(userRequest)
if (transparentGzip &&
"gzip".equals(networkResponse.header("Content-Encoding"), ignoreCase = true) &&
networkResponse.promisesBody()) {
val responseBody = networkResponse.body
if (responseBody != null) {
val gzipSource = GzipSource(responseBody.source())
responseBuilder.body(RealResponseBody(contentType, -1L, gzipSource.buffer()))
}
}
return responseBuilder.build()
}
請求前的代碼很簡單,就是添加了一些必要的頭部信息,包括Content-Type、Host、Cookie等等,封裝成一個完整的請求報文,然後交給下一個攔截器。
而獲取響應後的代碼就有點不是很明白了,gzip是啥?GzipSource又是什麼類?
gzip壓縮是基於deflate中的算法進行壓縮的,gzip會產生自己的數據格式,gzip壓縮對於所需要壓縮的文件,首先使用LZ77算法進行壓縮,再對得到的結果進行huffman編碼,根據實際情況判斷是要用動態huffman編碼還是靜態huffman編碼,最後生成相應的gz壓縮文件。
簡單的說,gzip就是一種壓縮方式,可以將數據進行壓縮,在添加頭部信息的時候就添加了這樣一個頭部:
requestBuilder.header("Accept-Encoding", "gzip")
這一句其實就是在告訴服務器,客戶端所能接受的文件的壓縮格式,這裡設置了gzip之後,服務器看到了就能把響應報文數據進行gzip壓縮再傳輸,提高傳輸效率,節省流量。
所以請求之後的這段關於gzip的處理其實就是客戶端對壓縮數據進行解壓縮,而GzipSource是okio庫裏面一個進行解壓縮讀取數據的類。
緩存攔截器(CacheInterceptor)
繼續看緩存攔截器—CacheInterceptor。
class CacheInterceptor(internal val cache: Cache?) : Interceptor {
@Throws(IOException::class)
override fun intercept(chain: Interceptor.Chain): Response {
//取緩存
val cacheCandidate = cache?.get(chain.request())
//緩存策略類
val strategy = CacheStrategy.Factory(now, chain.request(), cacheCandidate).compute()
val networkRequest = strategy.networkRequest
val cacheResponse = strategy.cacheResponse
// 如果不允許使用網絡,並且緩存數據為空
if (networkRequest == null && cacheResponse == null) {
return Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(HTTP_GATEWAY_TIMEOUT)//504
.message("Unsatisfiable Request (only-if-cached)")
.body(EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build().also {
listener.satisfactionFailure(call, it)
}
}
// 如果不允許使用網絡,但是有緩存
if (networkRequest == null) {
return cacheResponse!!.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build().also {
listener.cacheHit(call, it)
}
}
networkResponse = chain.proceed(networkRequest)
// 如果緩存不為空
if (cacheResponse != null) {
//304,表示數據未修改
if (networkResponse?.code == HTTP_NOT_MODIFIED) {
cache.update(cacheResponse, response)
return response
}
}
//如果開發者設置了緩存,則將響應數據緩存
if (cache != null) {
if (response.promisesBody() && CacheStrategy.isCacheable(response, networkRequest)) {
//緩存header
val cacheRequest = cache.put(response)
//緩存body
return cacheWritingResponse(cacheRequest, response)
}
}
return response
}
}
還是分兩部分看:
請求之前,通過request獲取了緩存,然後判斷緩存為空,就直接返回code為504的結果。如果有緩存並且緩存可用,則直接返回緩存。請求之後,如果返回304代表服務器數據沒修改,則直接返回緩存。如果cache不為空,那麼就把response緩存下來。
這樣看是不是和上面我們說過的緩存機制對應上了?請求之前就是處理強制緩存的情況,請求之後就會處理協商緩存的情況。
但是還是有幾個問題需要弄懂:
1、緩存是怎麼存儲和獲取的?
2、每次請求都會去存儲和獲取緩存嗎?
3、緩存策略(CacheStrategy)到底是怎麼處理網絡和緩存的?networkRequest什麼時候為空?
首先,看看緩存哪裡取的:
val cacheCandidate = cache?.get(chain.request())
internal fun get(request: Request): Response? {
val key = key(request.url)
val snapshot: DiskLruCache.Snapshot = try {
cache[key] ?: return null
}
val entry: Entry = try {
Entry(snapshot.getSource(ENTRY_METADATA))
}
val response = entry.response(snapshot)
if (!entry.matches(request, response)) {
response.body?.closeQuietly()
return null
}
return response
}
通過cache.get方法獲取了response緩存,get方法中主要是用到了請求Request的url來作為獲取緩存的標誌。
所以我們可以推斷,緩存的獲取是通過請求的url作為key來獲取的。
那麼cache又是哪裡來的呢?
val cache: Cache? = builder.cache
interceptors += CacheInterceptor(client.cache)
class CacheInterceptor(internal val cache: Cache?) : Interceptor
沒錯,就是實例化CacheInterceptor的時候傳進去的,所以這個cache是需要我們創建OkHttpClient的時候設置的,比如這樣:
val okHttpClient =
OkHttpClient().newBuilder()
.cache(Cache(cacheDir, 10 * 1024 * 1024))
.build()
這樣設置之後,okhttp就知道cache存在哪裡,大小為多少,然後就可以進行服務器響應的緩存處理了。
所以第二個問題也解決了,並不是每次請求都會去處理緩存,而是開發者需要去設置緩存的存儲目錄和大小,才會針對緩存進行這一系列的處理操作。
最後再看看緩存策略方法 CacheStrategy.Factory().compute()
class CacheStrategy internal constructor(
val networkRequest: Request?,
val cacheResponse: Response?
)
fun compute(): CacheStrategy {
val candidate = computeCandidate()
return candidate
}
private fun computeCandidate(): CacheStrategy {
//沒有緩存情況下,返回空緩存
if (cacheResponse == null) {
return CacheStrategy(request, null)
}
//...
//緩存控制不是 no-cache,且未過期
if (!responseCaching.noCache && ageMillis + minFreshMillis < freshMillis + maxStaleMillis) {
val builder = cacheResponse.newBuilder()
return CacheStrategy(null, builder.build())
}
return CacheStrategy(conditionalRequest, cacheResponse)
}
在這個緩存策略生存的過程中,只有一種情況下會返回緩存,也就是緩存控制不是no-cache,並且緩存沒過期情況下,就返回緩存,然後設置networkRequest為空。
所以也就對應上一開始緩存攔截器中的獲取緩存後的判斷:
// 如果不允許使用網絡,但是有緩存,則直接返回緩存
if (networkRequest == null) {
return cacheResponse!!.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build().also {
listener.cacheHit(call, it)
}
}
連接攔截器(ConnectInterceptor)
繼續,連接攔截器,之前說了是關於TCP連接的。
object ConnectInterceptor : Interceptor {
@Throws(IOException::class)
override fun intercept(chain: Interceptor.Chain): Response {
val realChain = chain as RealInterceptorChain
val exchange = realChain.call.initExchange(chain)
val connectedChain = realChain.copy(exchange = exchange)
return connectedChain.proceed(realChain.request)
}
}
代碼看着倒是挺少的,但其實這裏面很複雜很複雜,不着急,我們慢慢說。
這段代碼就執行了一個方法就是initExchange方法:
internal fun initExchange(chain: RealInterceptorChain): Exchange {
val codec = exchangeFinder.find(client, chain)
val result = Exchange(this, eventListener, exchangeFinder, codec)
return result
}
fun find(
client: OkHttpClient,
chain: RealInterceptorChain
): ExchangeCodec {
try {
val resultConnection = findHealthyConnection(
connectTimeout = chain.connectTimeoutMillis,
readTimeout = chain.readTimeoutMillis,
writeTimeout = chain.writeTimeoutMillis,
pingIntervalMillis = client.pingIntervalMillis,
connectionRetryEnabled = client.retryOnConnectionFailure,
doExtensiveHealthChecks = chain.request.method != "GET"
)
return resultConnection.newCodec(client, chain)
}
}
好像有一點眉目了,找到一個ExchangeCodec類,並封裝成一個Exchange類。
ExchangeCodec:是一個連接所用的編碼解碼器,用於編碼HTTP請求和解碼HTTP響應。Exchange:封裝這個編碼解碼器的一個工具類,用於管理ExchangeCodec,處理實際的 I/O。
明白了,這個連接攔截器(ConnectInterceptor)就是找到一個可用連接唄,也就是TCP連接,這個連接就是用於HTTP請求和響應的。
你可以把它可以理解為一個管道,有了這個管道,才能把數據丟進去,也才可以從管道裏面取數據。
而這個ExchangeCodec,編碼解碼器就是用來讀取和輸送到這個管道的一個工具,相當於把你的數據封裝成這個連接(管道)需要的格式。
我咋知道的?我貼一段ExchangeCodec代碼你就明白了:
//Http1ExchangeCodec.java
fun writeRequest(headers: Headers, requestLine: String) {
check(state == STATE_IDLE) { "state: $state" }
sink.writeUtf8(requestLine).writeUtf8("\r\n")
for (i in 0 until headers.size) {
sink.writeUtf8(headers.name(i))
.writeUtf8(": ")
.writeUtf8(headers.value(i))
.writeUtf8("\r\n")
}
sink.writeUtf8("\r\n")
state = STATE_OPEN_REQUEST_BODY
}
這裡貼的是Http1ExchangeCodec的write代碼,也就是Http1的編碼解碼器。
很明顯,就是將Header信息一行一行寫到sink中,然後再由sink交給輸出流,具體就不分析了。只要知道這個編碼解碼器就是用來處理連接中進行輸送的數據即可。
然後就是這個攔截器的關鍵了,連接到底是怎麼獲取的呢?繼續看看:
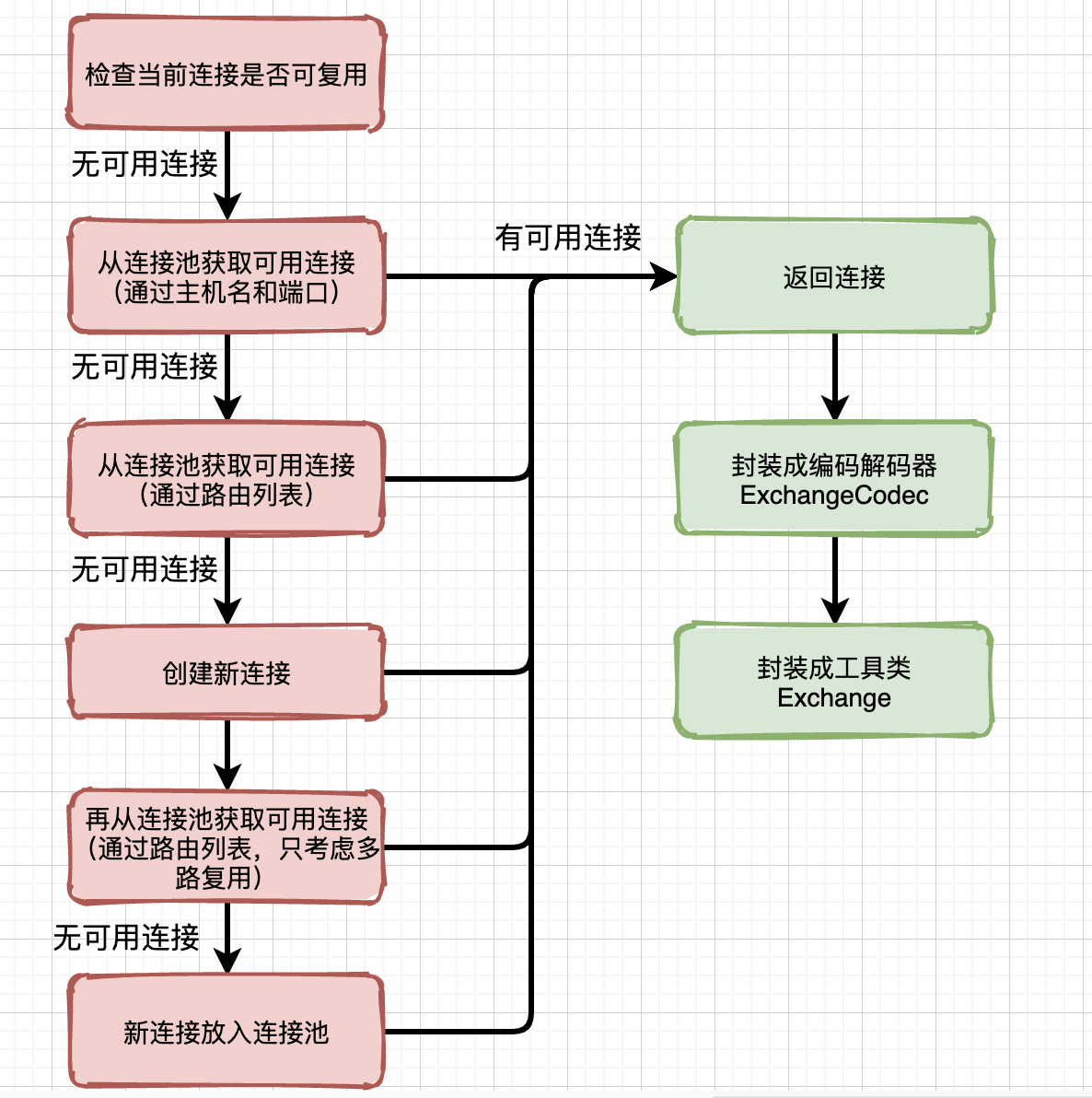
private fun findConnection(): RealConnection {
// 1、復用當前連接
val callConnection = call.connection
if (callConnection != null) {
//檢查這個連接是否可用和可復用
if (callConnection.noNewExchanges || !sameHostAndPort(callConnection.route().address.url)) {
toClose = call.releaseConnectionNoEvents()
}
return callConnection
}
//2、從連接池中獲取可用連接
if (connectionPool.callAcquirePooledConnection(address, call, null, false)) {
val result = call.connection!!
eventListener.connectionAcquired(call, result)
return result
}
//3、從連接池中獲取可用連接(通過一組路由routes)
if (connectionPool.callAcquirePooledConnection(address, call, routes, false)) {
val result = call.connection!!
return result
}
route = localRouteSelection.next()
// 4、創建新連接
val newConnection = RealConnection(connectionPool, route)
newConnection.connect
// 5、再獲取一次連接,防止在新建連接過程中有其他競爭連接被創建了
if (connectionPool.callAcquirePooledConnection(address, call, routes, true)) {
return result
}
//6、還是要使用創建的新連接,放入連接池,並返回
connectionPool.put(newConnection)
return newConnection
}
獲取連接的過程很複雜,為了方便看懂,我簡化了代碼,分成了6步。
- 1、檢查當前連接是否可用。
怎麼判斷可用的?主要做了兩個判斷
1)判斷是否不再接受新的連接
2)判斷和當前請求有相同的主機名和端口號。
這倒是很好理解,要這個連接是連接的同一個地方才能復用是吧,同一個地方怎麼判斷?就是判斷主機名和端口號。
還有個問題就是為什麼有當前連接??明明還沒開始連接也沒有獲取連接啊,怎麼連接就被賦值了?
還記得重試和重定向攔截器嗎?對了,就是當請求失敗需要重試的時候或者重定向的時候,這時候連接還在呢,是可以直接進行復用的。
- 2和3、從連接池中獲取可用連接
第2步和第3步都是從連接池獲取連接,有什麼不一樣嗎?
connectionPool.callAcquirePooledConnection(address, call, null, false)
connectionPool.callAcquirePooledConnection(address, call, routes, false)
好像多了一個routes字段?
這裡涉及到HTTP/2的一個技術,叫做 HTTP/2 CONNECTION COALESCING(連接合併),什麼意思呢?
假設有兩個域名,可以解析為相同的IP地址,並且是可以用相同的TLS證書(比如通配符證書),那麼客戶端可以重用相同的TCP連接從這兩個域名中獲取資源。
再看回我們的連接池,這個routes就是當前域名(主機名)可以被解析的ip地址集合,這兩個方法的區別也就是一個傳了路由地址,一個沒有傳。
繼續看callAcquirePooledConnection代碼:
internal fun isEligible(address: Address, routes: List<Route>?): Boolean {
if (address.url.host == this.route().address.url.host) {
return true
}
//HTTP/2 CONNECTION COALESCING
if (http2Connection == null) return false
if (routes == null || !routeMatchesAny(routes)) return false
if (address.hostnameVerifier !== OkHostnameVerifier) return false
return true
}
1)判斷主機名、端口號等,如果請求完全相同就直接返回這個連接。
2)如果主機名不同,還可以判斷是不是HTTP/2請求,如果是就繼續判斷路由地址,證書,如果都能匹配上,那麼這個連接也是可用的。
- 4、創建新連接
如果沒有從連接池中獲取到新連接,那麼就創建一個新連接,這裡就不多說了,其實就是調用到socket.connect進行TCP連接。
- 5、再從連接池獲取一次連接,防止在新建連接過程中有其他競爭連接被創建了
創建了新連接,為什麼還要去連接池獲取一次連接呢?
因為在這個過程中,有可能有其他的請求和你一起創建了新連接,所以我們需要再去取一次連接,如果有可以用的,就直接用它,防止資源浪費。
其實這裡又涉及到HTTP2的一個知識點:多路復用。
簡單的說,就是不需要當前連接的上一個請求結束之後再去進行下一次請求,只要有連接就可以直接用。
HTTP/2引入二進制數據幀和流的概念,其中幀對數據進行順序標識,這樣在收到數據之後,就可以按照序列對數據進行合併,而不會出現合併後數據錯亂的情況。同樣是因為有了序列,服務器就可以並行的傳輸數據,這就是流所做的事情。
所以在HTTP/2中可以保證在同一個域名只建立一路連接,並且可以並發進行請求。
- 6、新連接放入連接池,並返回
最後一步好理解吧,走到這裡說明就要用這個新連接了,那麼就把它存到連接池,返回這個連接。
這個攔截器確實麻煩,大家好好梳理下吧,我也再來個圖:
IO攔截器(CallServerInterceptor)
連接拿到了,編碼解碼器有了,剩下的就是發數據,讀數據了,也就是跟I/O相關的工作。
class CallServerInterceptor(private val forWebSocket: Boolean) : Interceptor {
@Throws(IOException::class)
override fun intercept(chain: Interceptor.Chain): Response {
//寫header數據
exchange.writeRequestHeaders(request)
//寫body數據
if (HttpMethod.permitsRequestBody(request.method) && requestBody != null) {
val bufferedRequestBody = exchange.createRequestBody(request, true).buffer()
requestBody.writeTo(bufferedRequestBody)
} else {
exchange.noRequestBody()
}
//結束請求
if (requestBody == null || !requestBody.isDuplex()) {
exchange.finishRequest()
}
//獲取響應數據
var response = responseBuilder
.request(request)
.handshake(exchange.connection.handshake())
.build()
var code = response.code
response = response.newBuilder()
.body(exchange.openResponseBody(response))
.build()
return response
}
}
這個攔截器 倒是沒幹什麼活,之前的攔截器兄弟們都把準備工作幹完了,它就調用下exchange類的各種方法,寫入header,body,拿到code,response。
這活可乾的真輕鬆啊。
被遺漏的自定義攔截器(networkInterceptors)
好了,最後補上這個攔截器networkInterceptors,它也是一個自定義攔截器,位於CallServerInterceptor之前,屬於倒數第二個攔截器。
那為什麼OkHttp在有了一個自定義攔截器的前提下又提供了一個攔截器呢?
可以發現,這個攔截器的位置是比較深的位置,處在發送數據的前一刻,以及收到數據的第一刻。
這麼敏感的位置,決定了通過這個攔截器可以看到更多的信息,比如:
請求之前,OkHttp處理之後的請求報文數據,比如增加了各種header之後的數據。請求之後,OkHttp處理之前的響應報文數據,比如解壓縮之前的數據。
所以,這個攔截器就是用來網絡調試的,調試比較底層、更全面的數據。
總結
最後再回顧下每個攔截器的作用:
addInterceptor(Interceptor),這是由開發者設置的,會按照開發者的要求,在所有的攔截器處理之前進行最早的攔截處理,比如一些公共參數,Header都可以在這裡添加。RetryAndFollowUpInterceptor,這裡會對連接做一些初始化工作,以及請求失敗的重試工作,重定向的後續請求工作。BridgeInterceptor,這裡會為用戶構建一個能夠進行網絡訪問的請求,同時後續工作將網絡請求回來的響應Response轉化為用戶可用的Response,比如添加文件類型,content-length計算添加,gzip解包。CacheInterceptor,這裡主要是處理cache相關處理,會根據OkHttpClient對象的配置以及緩存策略對請求值進行緩存,而且如果本地有了可⽤的Cache,就可以在沒有網絡交互的情況下就返回緩存結果。ConnectInterceptor,這裡主要就是負責建立連接了,會建立TCP連接或者TLS連接,以及負責編碼解碼的HttpCodec。networkInterceptors,這裡也是開發者自己設置的,所以本質上和第一個攔截器差不多,但是由於位置不同,用處也不同。這個位置添加的攔截器可以看到請求和響應的數據了,所以可以做一些網絡調試。CallServerInterceptor,這裡就是進行網絡數據的請求和響應了,也就是實際的網絡I/O操作,通過socket讀寫數據。
參考
//www.jianshu.com/p/bfb13eb3a425
//segmentfault.com/a/1190000020386580
//www.jianshu.com/p/02db8b55aae9
//kaiwu.lagou.com/course/courseInfo.htm?courseId=67#/detail/pc
拜拜
感謝大家的閱讀,有一起學習的小夥伴可以關注下我的公眾號——碼上積木❤️❤️
每日一個知識點,積少成多,建立知識體系架構。
這裡有一群很好的Android小夥伴,歡迎大家加入~

