解析分佈式應用框架Ray架構源碼
摘要:Ray的定位是分佈式應用框架,主要目標是使能分佈式應用的開發和運行。
Ray是UC Berkeley大學 RISE lab(前AMP lab) 2017年12月 開源的新一代分佈式應用框架(剛發佈的時候定位是高性能分佈式計算框架,20年中修改定位為分佈式應用框架),通過一套引擎解決複雜場景問題,通過動態計算及狀態共享提高效率,實現研發、運行時、容災一體化
Ray架構解析
業務目標
Ray的定位是分佈式應用框架,主要目標是使能分佈式應用的開發和運行。
業務場景
具體的粗粒度使用場景包括
- 彈性負載,比如Serverless Computing
- 機器學習訓練,Ray Tune, RLlib, RaySGD提供的訓練能力
- 在線服務, 例如Ray Server提供在線學習的案例
- 數據處理, 例如Modin, Dask-On-Ray, MARS-on-Ray
- 臨時計算(例如,並行化Python應用程序,將不同的分佈式框架粘合在一起)
Ray的API讓開發者可以輕鬆的在單個分佈式應用中組合多個libraries,例如,Ray的tasks和Actors可能會call into 或called from在Ray上運行的分佈式訓練(e.g. torch.distributed)或者在線服務負載; 在這種場景下,Ray是作為一個「分佈式膠水」系統,因為它提供通用API接口並且性能足以支撐許多不同工作負載類型。
系統設計目標
- Ray架構設計的核心原則是API的簡單性和通用性
- Ray的系統的核心目標是性能(低開銷和水平可伸縮性)和可靠性。為了達成核心目標,設計過程中需要犧牲一些其他理想的目標,例如簡化的系統架構。例如,Ray使用了分佈式參考計數和分佈式內存之類的組件,這些組件增加了體系結構的複雜性,但是對於性能和可靠性而言卻是必需的。
- 為了提高性能,Ray建立在gRPC之上,並且在許多情況下可以達到或超過gRPC的原始性能。與單獨使用gRPC相比,Ray使應用程序更容易利用並行和分佈式執行以及分佈式內存共享(通過共享內存對象存儲)。
- 為了提高可靠性,Ray的內部協議旨在確保發生故障時的正確性,同時又減少了常見情況的開銷。 Ray實施了分佈式參考計數協議以確保內存安全,並提供了各種從故障中恢復的選項。
- 由於Ray使用抽象資源而不是機器來表示計算能力,因此Ray應用程序可以無縫的從便攜機環境擴展到群集,而無需更改任何代碼。 Ray通過分佈式溢出調度程序和對象管理器實現了無縫擴展,而開銷卻很低。
相關係統上下文
- 集群管理系統:Ray可以在Kubernetes或SLURM之類的集群管理系統之上運行,以提供更輕量的task和Actor而不是容器和服務。
- 並行框架:與Python並行化框架(例如multiprocessing或Celery)相比,Ray提供了更通用,更高性能的API。 Ray系統還明確支持內存共享。
- 數據處理框架: 與Spark,Flink,MARS或Dask等數據處理框架相比,Ray提供了一個low-level且較簡化的API。這使API更加靈活,更適合作為「分佈式膠水」框架。另一方面,Ray對數據模式,關係表或流數據流沒有內在的支持。僅通過庫(例如Modin,Dask-on-Ray,MARS-on-Ray)提供此類功能。
- Actor框架:與諸如Erlang和Akka之類的專用actor框架不同,Ray與現有的編程語言集成,從而支持跨語言操作和語言本機庫的使用。 Ray系統還透明地管理無狀態計算的並行性,並明確支持參與者之間的內存共享。
- HPC系統:HPC系統都支持MPI消息傳遞接口,MPI是比task和actor更底層的接口。這可以使應用程序具有更大的靈活性,但是開發的複雜度加大了很多。這些系統和庫中的許多(例如NCCL,MPI)也提供了優化的集體通信原語(例如allreduce)。 Ray應用程序可以通過初始化各組Ray Actor之間的通信組來利用此類原語(例如,就像RaySGD的torch distributed)。
系統設計
邏輯架構:
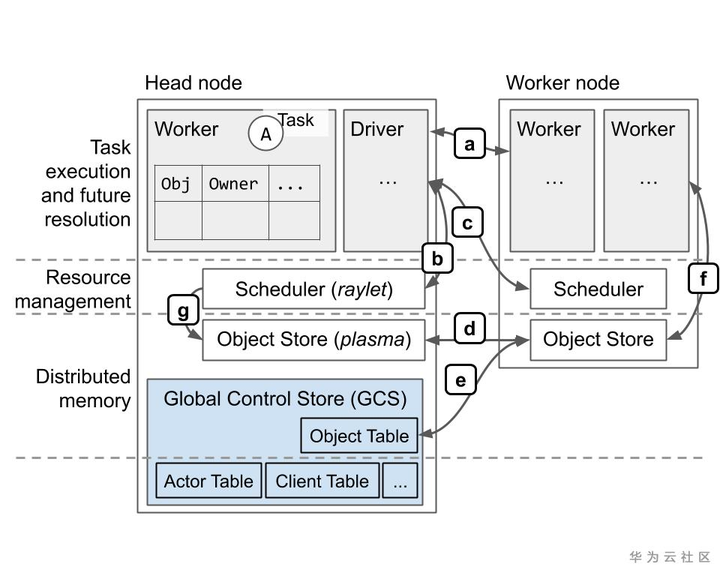
領域模型
- Task:在與調用者不同的進程上執行的單個函數調用。任務可以是無狀態的(@ ray.remote函數)或有狀態的(@ ray.remote類的方法-請參見下面的Actor)。任務與調用者異步執行:.remote()調用立即返回一個ObjectRef,可用於檢索返回值。
- Object:應用程序值。這可以由任務返回,也可以通過ray.put創建。對象是不可變的:創建後就無法修改。工人可以使用ObjectRef引用對象。
- Actor:有狀態的工作進程(@ ray.remote類的實例)。 Actor任務必須使用句柄或對Actor的特定實例的Python引用來提交。
- Driver: 程序根目錄。這是運行ray.init()的代碼。
- Job:源自同一驅動程序的(遞歸)任務,對象和參與者的集合
集群設計
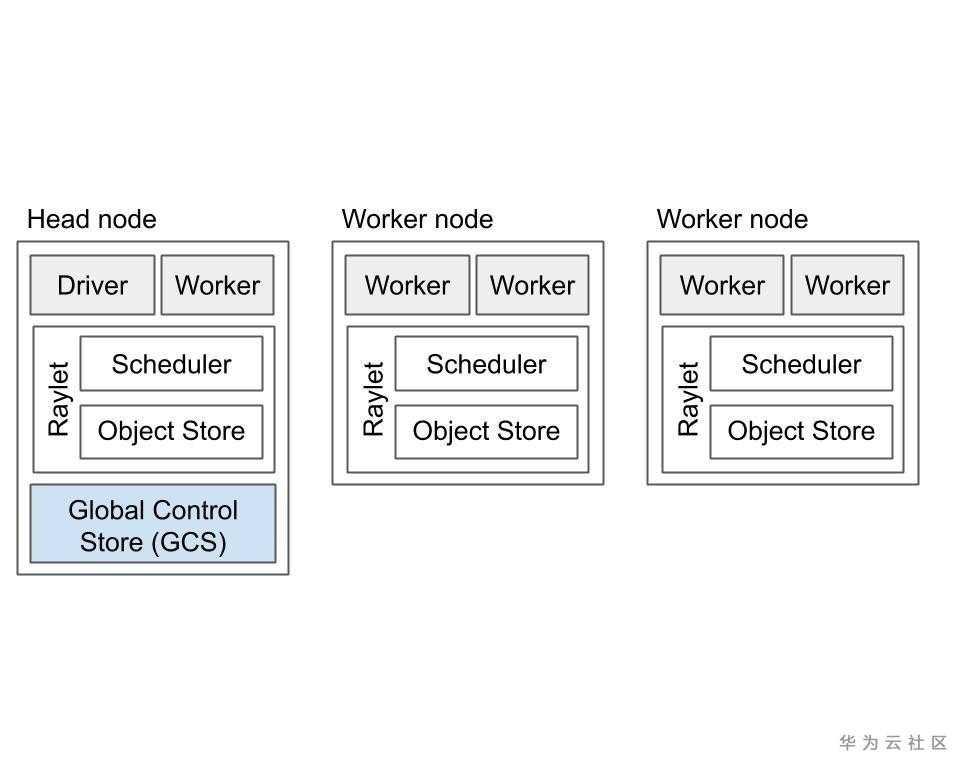
如上圖所示,Ray集群包括一組同類的worker節點和一個集中的全局控制存儲(GCS)實例。
部分系統元數據由GCS管理,GCS是基於可插拔數據存儲的服務,這些元數據也由worker本地緩存,例如Actor的地址。 GCS管理的元數據訪問頻率較低,但可能被群集中的大多數或所有worker使用,例如,群集的當前節點成員身份。這是為了確保GCS性能對於應用程序性能影響不大。
Ownership
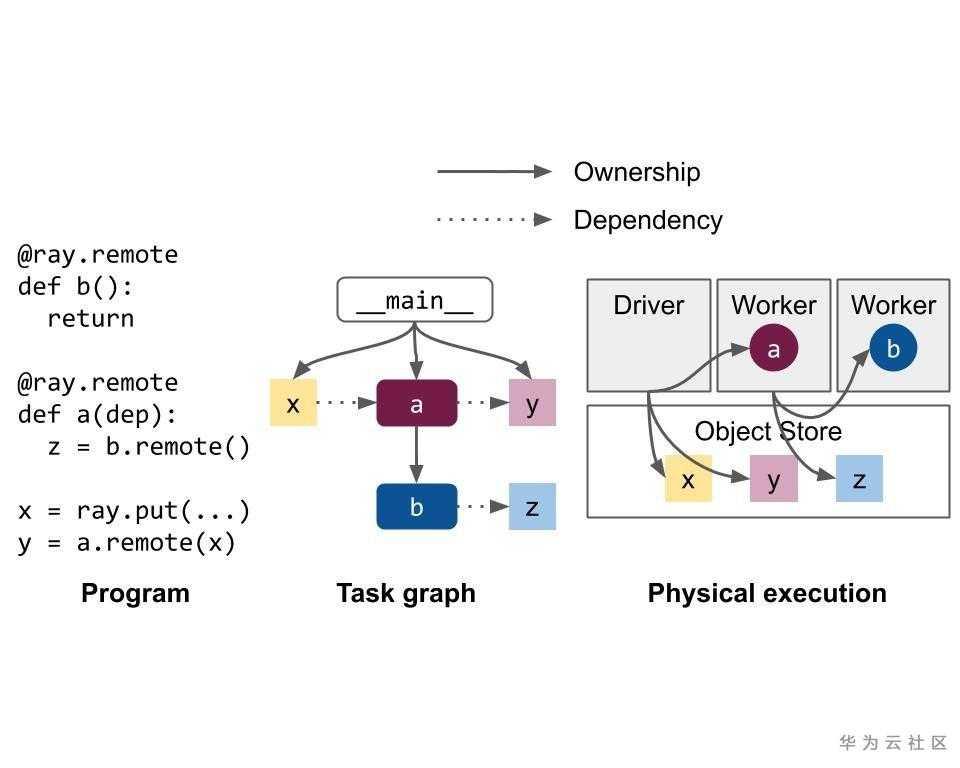
- 大部分系統元數據是根據去中心化理念(ownership)進行管理的:每個工作進程都管理和擁有它提交的任務以及這些任務返回的「 ObjectRef」。Owner負責確保任務的執行並促進將ObjectRef解析為其基礎值。類似地,worker擁有通過「 ray.put」調用創建的任何對象。
- OwnerShip的設計具有以下優點(與Ray版本<0.8中使用的更集中的設計相比):
- 低任務延遲(〜1 RTT,<200us)。經常訪問的系統元數據對於必須對其進行更新的過程而言是本地的。
- 高吞吐量(每個客戶端約10k任務/秒;線性擴展到集群中數百萬個任務/秒),因為系統元數據通過嵌套的遠程函數調用自然分佈在多個worker進程中。
- 簡化的架構。owner集中了安全垃圾收集對象和系統元數據所需的邏輯。
- 提高了可靠性。可以根據應用程序結構將工作程序故障彼此隔離,例如,一個遠程調用的故障不會影響另一個。
- OwnerShip附帶的一些權衡取捨是:
- 要解析「 ObjectRef」,對象的owner必須是可及的。這意味着對象必須與其owner綁定。有關對象恢復和持久性的更多信息,請參見object故障和object溢出。
- 目前無法轉讓ownership。
核心組件
- Ray實例由一個或多個工作節點組成,每個工作節點由以下物理進程組成:
- 一個或多個工作進程,負責任務的提交和執行。工作進程要麼是無狀態的(可以執行任何@ray.remote函數),要麼是Actor(只能根據其@ray.remote類執行方法)。每個worker進程都與特定的作業關聯。初始工作線程的默認數量等於計算機上的CPU數量。每個worker存儲ownership表和小對象:
a. Ownership 表。工作線程具有引用的對象的系統元數據,例如,用於存儲引用計數。
b. in-process store,用於存儲小對象。 - Raylet。raylet在同一群集上的所有作業之間共享。raylet有兩個主線程:
a. 調度器。負責資源管理和滿足存儲在分佈式對象存儲中的任務參數。群集中的單個調度程序包括Ray分佈式調度程序。
b. 共享內存對象存儲(也稱為Plasma Object Store)。負責存儲和傳輸大型對象。集群中的單個對象存儲包括Ray分佈式對象存儲。
每個工作進程和raylet都被分配了一個唯一的20位元組標識符以及一個IP地址和端口。相同的地址和端口可以被後續組件重用(例如,如果以前的工作進程死亡),但唯一ID永遠不會被重用(即,它們在進程死亡時被標記為墓碑)。工作進程與其本地raylet進程共享命運。
- 其中一個工作節點被指定為Head節點。除了上述進程外,Head節點還託管:
- 全局控制存儲(GCS)。GCS是一個鍵值服務器,包含系統級元數據,如對象和參與者的位置。GCS目前還不支持高可用,後續版本中GCS可以在任何和多個節點上運行,而不是指定的頭節點上運行。
- Driver進程(es)。Driver是一個特殊的工作進程,它執行頂級應用程序(例如,Python中的__main__)。它可以提交任務,但不能執行任何任務本身。Driver進程可以在任何節點上運行。
交互設計
應用的Driver可以通過以下方式之一連接到Ray:
- 調用`ray.init()』,沒有參數。這將啟動一個嵌入式單節點Ray實例,應用可以立即使用該實例。
- 通過指定ray.init(地址=<GCS addr>)連接到現有的Ray集群。在後端,Driver將以指定的地址連接到GCS,並查找群集其他組件的地址,例如其本地raylet地址。Driver必須與Ray群集的現有節點之一合部。這是因為Ray的共享內存功能,所以合部是必要的前提。
- 使用Ray客戶端`ray.util.connect()’從遠程計算機(例如筆記本電腦)連接。默認情況下,每個Ray群集都會在可以接收遠程客戶端連接的頭節點上啟動一個Ray Client Server,用來接收遠程client連接。但是由於網絡延遲,直接從客戶端運行的某些操作可能會更慢。
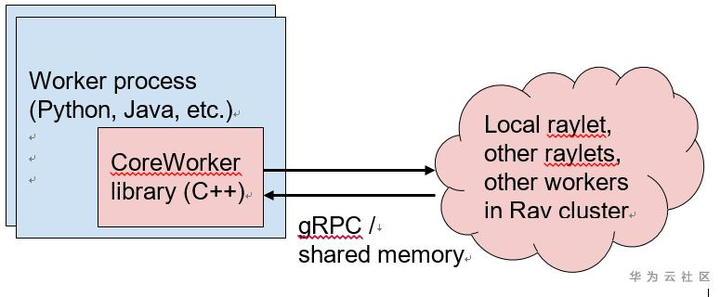
Runtime
- 所有Ray核心組件都是用C++實現的。Ray通過一個名為「core worker」的通用嵌入式C++庫支持Python和Java。此庫實現ownership表、進程內存儲,並管理與其他工作器和Raylet的gRPC通信。由於庫是用C++實現的,所有語言運行時都共享Ray工作協議的通用高性能實現。
Task的lifetime
Owner負責確保提交的Task的執行,並促進將返回的ObjectRef解析為其基礎值。如下圖,提交Task的進程被視為結果的Owner,並負責從raylet獲取資源以執行Task,Driver擁有A的結果,Worker 1擁有B的結果。
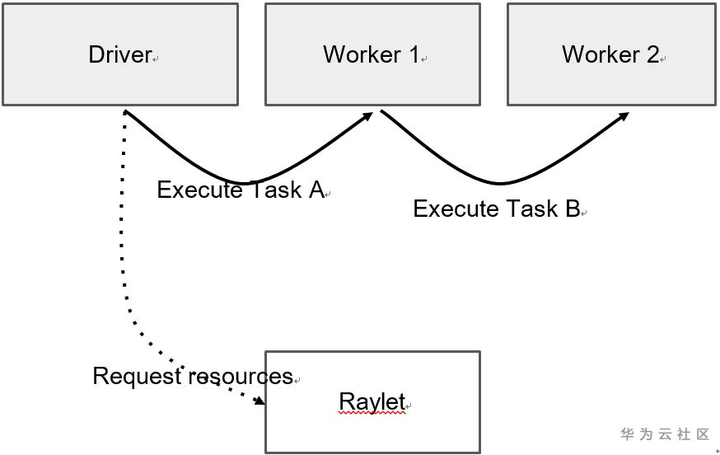
- 提交Task時,Owner會等待所有依賴項就緒,即作為參數傳遞給Task的ObjectRefs(請參見Object的lifetime)變得可用。依賴項不需要是本地的;Owner一旦認為依賴項在群集中的任何地方可用,就會立即就緒。當依賴關係就緒時,Owner從分佈式調度程序請求資源以執行任務,一旦資源可用,調度程序就會授予請求,並使用分配給owner的worker的地址進行響應。
- Owner將task spec通過gRPC發送給租用的worker來調度任務。執行任務後,worker必須存儲返回值。如果返回值較小,則工作線程將值直接inline返回給Owner,Owner將其複製到其進程中對象存儲區。如果返回值很大,則worker將對象存儲在其本地共享內存存儲中,並向所有者返回分佈式內存中的ref。讓owner可以引用對象,不必將對象提取到其本地節點。
- 當Task以ObjectRef作為其參數提交時,必須在worker開始執行之前解析對象值。如果該值較小,則它將直接從所有者的進程中對象存儲複製到任務說明中,在任務說明中,執行worker線程可以引用它。如果該值較大,則必須從分佈式內存中提取對象,以便worker在其本地共享內存存儲中具有副本。scheduler通過查找對象的位置並從其他節點請求副本來協調此對象傳輸。
- 容錯:任務可能會以錯誤結束。Ray區分了兩種類型的任務錯誤:
- 應用程序級。這是工作進程處於活動狀態,但任務以錯誤結束的任何場景。例如,在Python中拋出IndexError的任務。
- 系統級。這是工作進程意外死亡的任何場景。例如,隔離故障的進程,或者如果工作程序的本地raylet死亡。
- 由於應用程序級錯誤而失敗的任務永遠不會重試。異常被捕獲並存儲為任務的返回值。由於系統級錯誤而失敗的任務可以自動重試到指定的嘗試次數。
- 代碼參考:
- src/ray/core_worker/core_worker.cc
- src/ray/common/task/task_spec.h
- src/ray/core_worker/transport/direct_task_transport.cc
- src/ray/core_worker/transport/依賴關係_解析器.cc
- src/ray/core_worker/task_manager.cc
- src/ray/protobuf/common.proto
Object的lifetime
下圖Ray中的分佈式內存管理。worker可以創建和獲取對象。owner負責確定對象何時安全釋放。
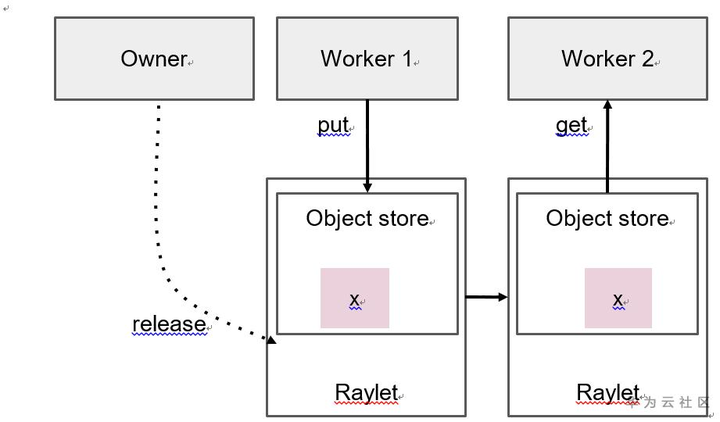
- 對象的owner就是通過提交創建task或調用ray.put創建初始ObjectRef的worker。owner管理對象的生存期。Ray保證,如果owner是活的,對象最終可能會被解析為其值(或者在worker失敗的情況下引發錯誤)。如果owner已死亡,則獲取對象值的嘗試永遠不會hang,但可能會引發異常,即使對象仍有物理副本。
- 每個worker存儲其擁有的對象的引用計數。有關如何跟蹤引用的詳細信息,請參閱引用計數。Reference僅在下面兩種操作期間計算:
1.將ObjectRef或包含ObjectRef的對象作為參數傳遞給Task。
2.從Task中返回ObjectRef或包含ObjectRef的對象。 - 對象可以存儲在owner的進程內內存存儲中,也可以存儲在分佈式對象存儲中。此決定旨在減少每個對象的內存佔用空間和解析時間。
- 當沒有故障時,owner保證,只要對象仍在作用域中(非零引用計數),對象的至少一個副本最終將可用。。
- 有兩種方法可以將ObjectRef解析為其值:
1.在ObjectRef上調用ray.get。
2.將ObjectRef作為參數傳遞給任務。執行工作程序將解析ObjectRefs,並將任務參數替換為解析的值。 - 當對象較小時,可以通過直接從owner的進程內存儲中檢索它來解析。大對象存儲在分佈式對象存儲中,必須使用分佈式協議解析。
- 當沒有故障時,解析將保證最終成功(但可能會引發應用程序級異常,例如worker segfault)。如果存在故障,解析可能會引發系統級異常,但永遠不會掛起。如果對象存儲在分佈式內存中,並且對象的所有副本都因raylet故障而丟失,則該對象可能會失敗。Ray還提供了一個選項,可以通過重建自動恢復此類丟失的對象。如果對象的所有者進程死亡,對象也可能失敗。
- 代碼參考:
- src/ray/core_worker/store_Provider/memory_store/memory_store.cc
- src/ray/core_worker/store_Provider/plasma_store_provider.cc
- src/ray/core_worker/reference_count.cc
- src/ray/object_manager/object_manager.cc
Actor的lifetime
Actor的lifetimes和metadata (如IP和端口)是由GCS service管理的.每一個Actor的Client都會在本地緩存metadata,使用metadata通過gRPC將task發送給Actor.
如上圖,與Task提交不同,Task提交完全分散並由Task Owner管理,Actor lifetime由GCS服務集中管理。
- 在Python中創建Actor時,worker首先同步向GCS註冊Actor。這確保了在創建Actor之前,如果創建worker失敗的情況下的正確性。一旦GCS響應,Actor創建過程的其餘部分將是異步的。Worker進程在創建一個稱為Actor創建Task的特殊Task隊列。這與普通的非Actor任務類似,只是其指定的資源是在actor進程的生存期內獲取的。創建者異步解析actor創建task的依賴關係,然後將其發送到要調度的GCS服務。同時,創建actor的Python調用立即返回一個「actor句柄」,即使actor創建任務尚未調度,也可以使用該句柄。
- Actor的任務執行與普通Task 類似:它們返回futures,通過gRPC直接提交給actor進程,在解析所有ObjectRef依賴關係之前,不會運行。和普通Task主要有兩個區別:
- 執行Actor任務不需要從調度器獲取資源。這是因為在計劃其創建任務時,參與者已在其生命周期內獲得資源。
- 對於Actor的每個調用者,任務的執行順序與提交順序相同。
- 當Actor的創建者退出時,或者群集中的作用域中沒有更多掛起的任務或句柄時,將被清理。不過對於detached Actor來說不是這樣的,因為detached actor被設計為可以通過名稱引用的長Actor,必須使用ray.kill(no_restart=True)顯式清理。
- Ray還支持async actor,這些Actor可以使用asyncio event loop並發運行任務。從調用者的角度來看,向這些actor提交任務與向常規actor提交任務相同。唯一的區別是,當task在actor上運行時,它將發佈到在後台線程或線程池中運行的異步事件循環中,而不是直接在主線程上運行。
- 代碼參考:
- Core worker源碼: src/ray/core_worker/core_worker.h. 此代碼是任務調度、Actor任務調度、進程內存儲和內存管理中涉及的各種協議的主幹。
- Python: python/ray/includes/libcoreworker.pxd
- Java: src/ray/core_worker/lib/java
- src/ray/core_worker/core_worker.cc
- src/ray/core_worker/transport/direct_actor_transport.cc
- src/ray/gcs/gcs_server/gcs_actor_manager.cc
- src/ray/gcs/gcs_server/gcs_actor_scheduler.cc
- src/ray/protobuf/core_worker.proto
本文分享自華為雲社區《分佈式應用框架Ray架構源碼解析》,原文作者:Leo Xiao 。

