MySQL索引
本文主要介紹MySQL里InnoDB引擎的索引。
在MySQL的InnoDB引擎里,索引以B+樹的形式存儲,數據都是存儲在B+樹里的。
主鍵索引和非主鍵索引
如下圖所示,現在有一張表,這張表有兩個字段、兩個索引,其中id字段使用了主鍵索引,num字段使用了非主鍵索引。
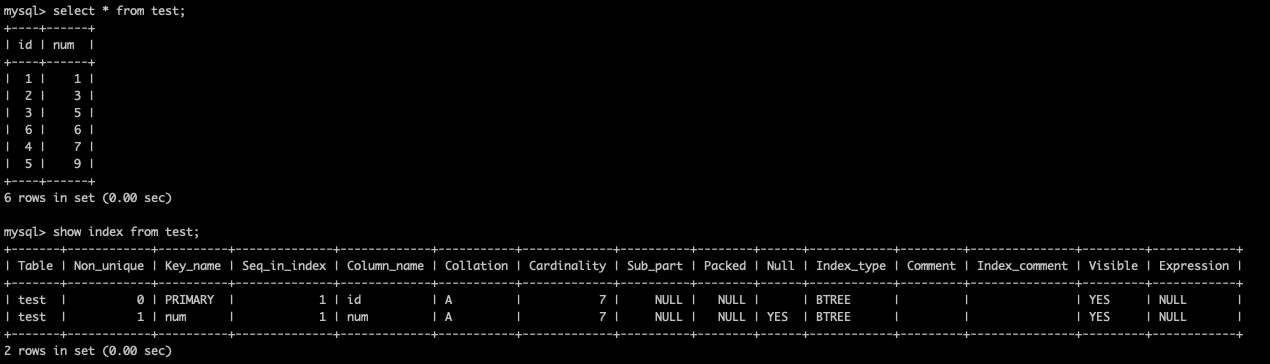
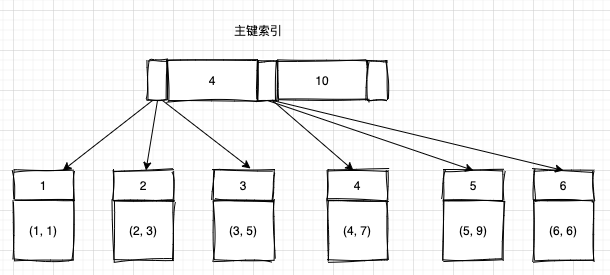
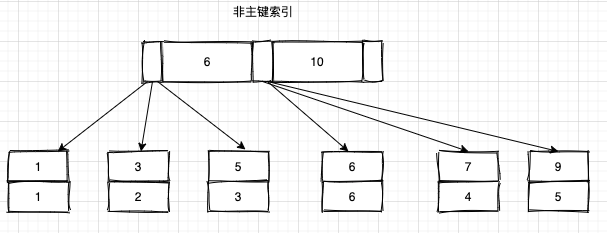
主鍵索引和非主鍵索引的數據結構如下圖所示:
- 在主鍵索引裏面,對應行數據會存儲到主鍵索引的葉子節點,所以主鍵索引又叫做聚簇索引
- 在非主鍵索引裏面,索引葉子結點存儲的是主鍵值,在InnoDB裏面,非主鍵索引又叫做二級索引
從主鍵索引和非主鍵索引結構的不同可以看出來,如果使用主鍵索引和非主鍵索引查詢一條數據時,查詢流程是有差別的:
- 使用主鍵索引查詢數據時,只需要找到對應葉子節點,就可以找到對應數據行,就查詢到對應數據
- 使用非主鍵索引查詢時,需要先去非主鍵索引數裏面找到對應葉子節點,得到主鍵值,然後再去主鍵索引查詢行數據,這個過程也稱為回表
目前在工作時,使用的數據庫主鍵一般是自增的數字主鍵,沒有業務語義,而業務主鍵會使用單獨一個唯一性索引維護,這個主要從兩方面考慮:
- 一方面是使用自增的數字主鍵插入數據是對於整個樹來說是順序寫,不會從中間新增一條,這樣就避免數據庫頁分裂的問題
- 使用數字主鍵而不是業務主鍵是因為業務主鍵比較大,一般會加上日期和分庫分表位,這樣的業務主鍵作為數據庫主鍵的話,就會讓每個二級索引都包含這個值,二級索引佔用的空間會比使用自增的數字主鍵要大一些
所以結合這些因素我們數據庫主鍵使用的是自增的數字主鍵而不是業務主鍵。
普通索引和唯一性索引
剛才在上面提到了唯一性索引,這裡對普通索引,也就是非唯一性索引和唯一性索引進行討論。
唯一性索引顧名思義就是會對新增或者修改的數據進行唯一性校驗,如果沒有相同索引值的數據,這個變更才允許執行到數據庫。
普通索引和唯一性索引因為這點不同,在執行查詢操作和修改操作時會有一些不同。
使用一個例子看一下普通索引和唯一性索引查詢的區別,可以參考上面那張表,主鍵id也是唯一鍵,在查詢同一條數據(1, 1)時,InnoDB執行流程會有一些不同:
- 唯一性索引: 使用select * from where id = 1查詢數據(1, 1)時,查找到id = 1葉子節點後,因為索引具有唯一性,就會停止檢索
- 普通索引: 使用select * from test where num = 1查詢(1, 1)時,查找到num = 1葉子節點後,會查找下一條記錄,直到找到第一條num != 1的記錄為止
看完查詢流程,再看更新流程有什麼不同。
更新流程要分兩種不同的場景,一個場景是要更新的數據所在的頁在內存里,一個場景是要更新的數據所在的頁不在內存里。
對於第一種場景,更新流程如下:
- 唯一性索引: 找到更新後的數據在索引里的位置,判斷是否有衝突,如果沒有衝突,就執行更新操作
- 普通索引: 找到更新後的數據在索引里的位置,執行更新操作
可以看出,在第一種場景下,不同點就在於判斷是否有衝突。
對於第二種場景,更新流程如下:
- 唯一性索引: 將數據頁讀入內存里,判斷是否有衝突,如果沒有衝突,就執行更新操作
- 普通索引: 將更新記錄到change buffer
可以看出,在第二種場景下,普通索引不會吧數據也讀入內存里,可以理解為InnoDB的優化,減少隨機讀。
buffer pool和change buffer
上面提到了change buffer,這裡對buffer pool和change buffer進行介紹。
buffer pool是內存里的一個區域,是InnoDB訪問表和索引數據時會使用的高速緩存。buffer pool會存儲經常訪問的數據,加快處理速度。
為了提高大容量讀取操作的效率buffer pool被分成了多個頁,使用鏈表來實現,buffer pool使用LRU優化算法來淘汰很長時間不使用的數據頁。
整個buffer pool分成新生代(New Sublist)、老年代(Old Sublist)兩部分,如下圖所示:
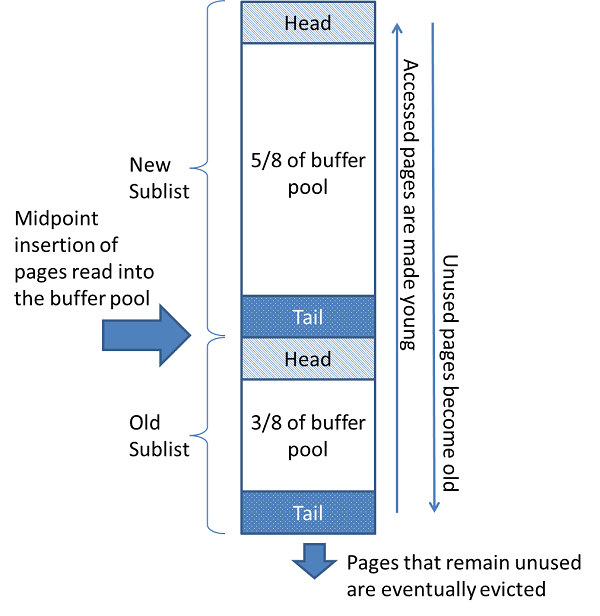
常用的頁面保存在新生代,不常用的頁面保存在老年代,後續清除緩存里的數據會從老年代來清除。
buffer pool運行方式如下:
- buffer pool新生代和老年代交界的地方是中點,當InnoDB把數據頁讀到內存里時,會先讀到中點,也就是老年代的頭部,這裡讀到內存里的頁面不只包括本次操作要讀取到的數據,也可能包括預讀的數據
- 訪問老年代的數據會把對應數據變的年輕,也就是說會把老年代的數據移到新生代的頭部,上面說到讀到內存里的數據,有一部分是本次操作要讀取到的數據,還有一部分是預讀的數據,本次操作要讀取到的數據會因為立即被讀到而放到新生代的頭部,預讀的數據則不會
- 在運行過程中,老年代尾部的數據會被淘汰,新生代尾部的數據會進入老年代
從上面運行方式可以看出來,InnoDB使用的LRU算法不會把所用讀到的數據都更新到頭部,只會把老年代讀到的數據更新到新生代的頭部,這樣可以減少緩存數據交換的頻率,提高了性能。
說完了buffer pool,再來看下change buffer,change buffer會使用buffer pool內存的一部分空間,也會把變更寫到磁盤裡。
在上面普通索引和唯一性索引裏面,可以看出change buffer的引用可以減少數據庫的隨機讀操作,如果一條數據對應的數據頁不在buffer pool裏面,那麼如果是普通索引,就會把這條數據的變更以change buffer的形式體現,不需要這條數據對應的數據頁再讀到內存里。
如下圖所示,在二級索引上修改的數據會被緩存到change buffer,change buffer會在訪問目標數據頁時執行merge操作,把改動變更到對應數據頁,同時系統有後台線程也會定期執行merge操作,數據庫在正常關閉(shutdown)的過程中也會執行merge操作。

索引使用
覆蓋索引
覆蓋索引是用來減少回表次數的,如果要查詢的結果在索引上包含了,那麼獲取到對應的值直接返回即可,不需要在執行回表操作了。
最左前綴索引
最左前綴索引用於提高索引的命中率,假如有索引(A, B, C),那麼使用A就可以命中這個索引,同時如果索引A是字符串,那麼A like ‘abc%’這樣的模糊查詢也能命中最左前綴索引。
索引下推
索引下推在MySQL 5.6以及5.6以後版本支持,也是用於減少回表用的。
對於索引(A, B, C),使用where A like ‘abc%’ and B = ‘b’ and C = ‘c’會命中最左前綴索引,在沒有索引下推的情況下,MySQL會找到每一個葉子節點,找到每一個主鍵,回表查B和C的值是否符合要求。
在有索引下推的情況下,MySQL會在索引查詢階段就判斷索引上的值是否滿足B = ‘b’和C = ‘c’,在索引上過濾到結果,只需要拿滿足條件的主鍵回表即可,減少回表次數。
前綴索引
前綴索引可以使用一個字符串的前幾位作為索引值,減少索引的大小,前綴索引不能使用覆蓋索引。


