WEB服務-Nginx之十-keepalived
- 2021 年 3 月 7 日
- 筆記
WEB服務-Nginx之10-keepalived
Keepalived和高可用 基本概述
高可用一般是指2台機器啟動着完全相同的業務系統,當有一台機器down機了,另外一台服務器就能快速的接管,對於訪問的用戶是無感知的。
高可用實現
- 硬件通常使用 F5
- 軟件通常使用 keepalived
keepalived軟件基於VRRP協議實現高可用(VRRP虛擬路由冗餘協議,主要用於解決單點故障問題)
VRRP誕生及原理
比如公司的網絡是通過網關進行上網的,那麼如果該路由器故障了,網關無法轉發報文了,此時所有人都無法上網了,怎麼辦?
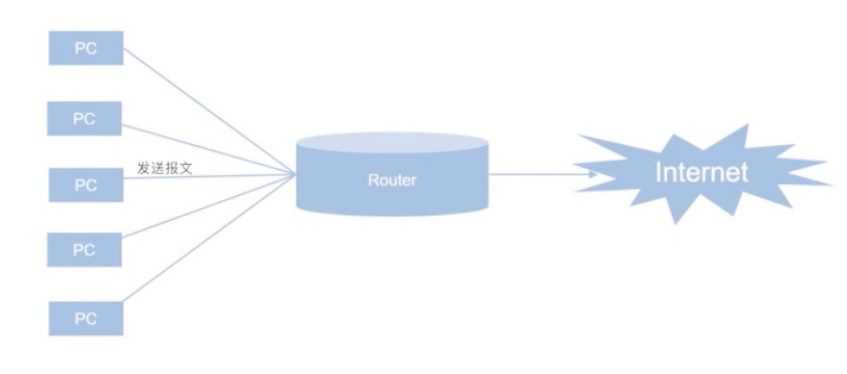
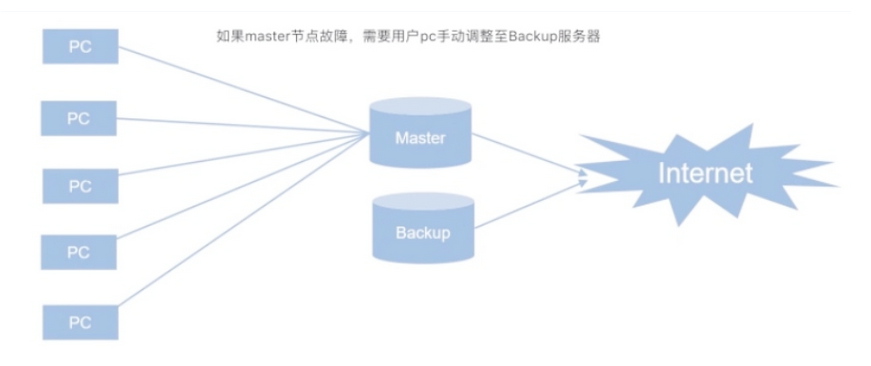
通常做法是給路由器增加一台備用,但是問題是,如果我們的主網關master故障了,用戶是需要手動指向backup的,如果用戶過多修改起來會非常麻煩。
問題一:假設用戶將指向都修改為backup路由器,那麼master路由器修好了怎麼辦?
問題二:假設Master網關故障,我們將backup網關配置為master網關的ip是否可以?
其實是不行的,因為PC第一次通過ARP廣播尋找到Master網關的MAC地址與IP地址後,會將信息寫到ARP的緩存表中,那麼PC之後連接都是通過那個緩存表的信息去連接,然後進行數據包的轉發,即使我們修改了IP但是Mac地址是沒有變化,pc的數據包依然會發送給master。(除非是PC的ARP緩存表過期,再次發起ARP廣播的時候才能獲取新的backup對應的Mac地址與IP地址)
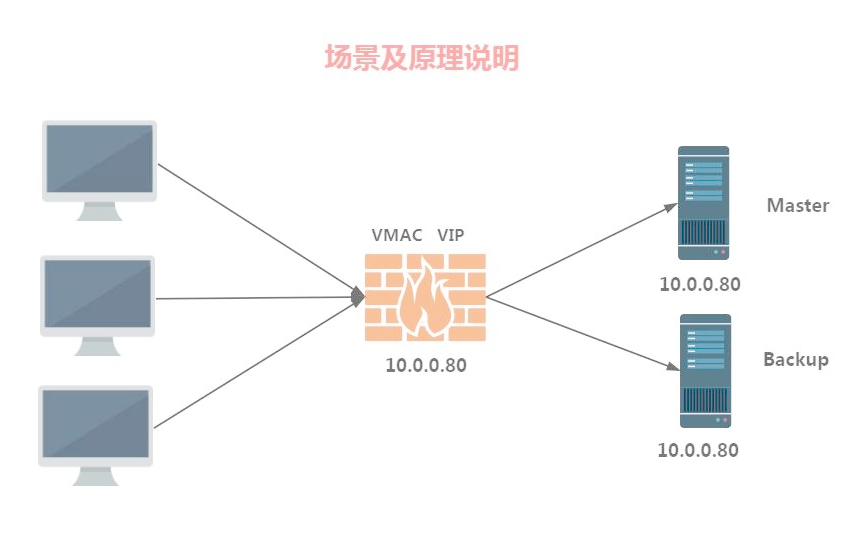
為了做到出現故障自動轉移,開發了VRRP。VRRP其實是通過軟件或者硬件的形式在Master和Backup外面增加一個虛擬的MAC地址(VMAC)與虛擬IP地址(VIP),讓PC請求VIP,那麼無論是Master處理還是Backup處理,PC僅會在ARP緩存表中記錄VMAC與VIP的信息。
高可用keepalived使用場景
通常業務系統需要保證7×24小時不DOWN機,比如公司內部的OA系統,每天公司人員都需要使用,則不允許Down機,作為業務系統來說要隨時都可用。
高可用keepalived核心概念
- 如何確定誰是主節點誰是背節點?(選舉投票,優先級)
- 當Master出現故障時,Backup自動接管,那麼Master回復後會奪權嗎?(搶佔試、非搶佔式)
- 如果兩台服務器都認為自己是Master會出現什麼問題?(腦裂)
Keepalived安裝配置
環境準備
| 作用 | IP | 角色 |
|---|---|---|
| node1 | 10.0.0.5 | Master |
| node2 | 10.0.0.6 | Backup |
| VIP | 10.0.0.3 |
安裝keepalived
[root@lb01 ~]# yum install -y keepalived
[root@lb02 ~]# yum install -y keepalived
查找配置文件
[root@lb01 ~]# rpm -qc keepalived
/etc/keepalived/keepalived.conf
/etc/sysconfig/keepalived
配置master
[root@lb01 ~]# cat > /etc/keepalived/keepalived.conf <<EOF
global_defs { # 全局配置
router_id lb01 # 標識身份->名稱
}
vrrp_instance VI_1 {
state MASTER # 標識角色狀態
interface eth0 # 網卡綁定接口
virtual_router_id 50 # 虛擬路由id
priority 150 # 優先級
advert_int 1 # 監測間隔時間
authentication { # 認證
auth_type PASS # 認證方式
auth_pass 1111 # 認證密碼
}
virtual_ipaddress {
10.0.0.3 # VIP地址
}
}
EOF
配置backup
[root@lb02 ~]# cat > /etc/keepalived/keepalived.conf <<EOF
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
EOF
對比master與Backup區別
| Keepalived配置區別 | Master節點配置 | Backup節點配置 |
|---|---|---|
| route_id(唯一標識) | router_id lb01 | router_id lb02 |
| state(角色狀態) | state MASTER | state BACKUP |
| priority(競選優先級) | priority 150 | priority 100 |
啟動Master和Backup節點的keepalived並加入開機啟動
# Master節點
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# systemctl enable keepalived
# Backup節點
[root@lb02 ~]# systemctl start keepalived
[root@lb02 ~]# systemctl enable keepalived
Keepalived搶佔式與非搶佔式
啟動兩個節點
# 由於節點1的優先級高於節點2,所以VIP在節點1上
[root@lb01 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth0
關閉節點1的keepalived
[root@lb01 ~]# systemctl stop keepalived
# 節點2聯繫不上節點1,主動接管VIP
[root@lb02 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth0
此時重新啟動Master上的keepalived,會發現VIP被Master強行搶佔
[root@lb01 ~]# systemctl start keepalived
[root@lb01 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth0
配置非搶佔式要求
- 兩個節點的state都必須配置為BACKUP
- 兩個節點都必須加上配置 nopreempt
- 其中一個節點的優先級必須要高於另外一個節點的優先級。
兩台服務器都角色狀態啟用nopreempt後,必須修改角色狀態統一為BACKUP,唯一的區分就是優先級。
Master配置
[root@lb01 ~]# cat > /etc/keepalived/keepalived.conf <<EOF
global_defs {
router_id lb01
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 150
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
EOF
Backup配置
[root@lb02 ~]# cat > /etc/keepalived/keepalived.conf <<EOF
global_defs {
router_id lb02
}
vrrp_instance VI_1 {
state BACKUP
interface eth0
virtual_router_id 50
priority 100
advert_int 1
nopreempt
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
}
EOF
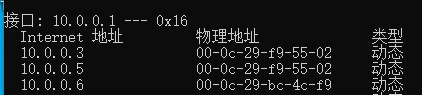
通過windows的arp去驗證,是否會切換MAC地址
# 查看VIP在節點1上面
[root@lb01 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth0
# windows查看Mac地址
C:\Users\Administrator> arp -a
# 將節點1的keepalived停掉
[root@lb01 ~]# systemctl stop keepalived
# 節點2接管VIP
[root@lb02 ~]# ip addr | grep 10.0.0.3
inet 10.0.0.3/32 scope global eth0
# 再次查看mac地址
C:\Users\Administrator> arp -a
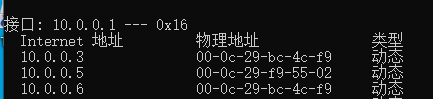
Keepalived故障腦裂
由於某些原因,導致兩台keepalived高可用服務器在指定時間內,無法檢測到對方的心跳,而此時的兩台高可用keepalived服務器又都還活着,就會導致腦裂。
腦裂(split-brain):指在一個高可用(HA)系統中,當聯繫着的兩個節點斷開聯繫時,本來為一個整體的系統,分裂為兩個獨立節點,這時兩個節點開始爭搶共享資源,結果會導致系統混亂,數據損壞。
對於無狀態服務的HA,無所謂腦裂不腦裂;但對有狀態服務(比如MySQL)的HA,必須要嚴格防止腦裂。
腦裂故障原因
1、服務器網線鬆動等網絡故障
2、服務器硬件故障發生損壞現象而崩潰
3、主備都開啟firewalld防火牆
腦裂故障現象
將節點1和節點2的防火牆都打開
[root@lb01 ~]# systemctl start firewalld
[root@lb02 ~]# systemctl start firewalld
Wireshark抓包查看

腦裂故障解決方案
如果發生腦裂,隨機kill掉一台即可解決
推薦在BACKUP上編寫檢測腳本,測試如果能ping通主節點,並且備節點還有VIP,則認為產生了腦裂
[root@lb02 ~]# cat check_split_brain.sh
#!/bin/sh
vip=10.0.0.3
lb01_ip=10.0.0.5
while true;do
ping -c 2 $lb01_ip &>/dev/null
if [ $? -eq 0 -a `ip add|grep "$vip"|wc -l` -eq 1 ];then
echo "ha is split brain.warning."
else
echo "ha is ok"
fi
sleep 5
done
Keepalived與nginx
為什麼域名解析到VIP就可以訪問nginx?
Nginx默認監聽在所有的IP地址上,VIP所在節點相當於多了VIP這麼一個IP,所以可以訪問到nginx所在機器。
但是…..如果nginx宕機,會導致用戶請求失敗,但是keepalived沒有掛掉不會進行切換,所以需要編寫一個腳本檢測Nginx的存活狀態,如果不存活則kill掉keepalived。
[root@lb01 ~]#cd /server/scripts/
[root@lb01 scripts]# vim check_web.sh
#!/bin/sh
nginxpid=$(ps -C nginx --no-header|wc -l)
# 1.判斷Nginx是否存活,如果不存活則嘗試啟動Nginx
if [ $nginxpid -eq 0 ];then
systemctl start nginx
sleep 3
# 2.等待3秒後再次獲取Nginx狀態
nginxpid=$(ps -C nginx --no-header|wc -l)
# 3.再次進行判斷, 如Nginx還不存活則停止Keepalived,讓地址進行漂移,並退出腳本
if [ $nginxpid -eq 0 ];then
systemctl stop keepalived
fi
fi
# 給腳本增加執行權限
[root@lb01 scripts]# chmod +x /server/scripts/check_web.sh
keepalived配置文件中可以直接調用此腳本
[root@lb01 ~]# cat > /etc/keepalived/keepalived.conf <<EOF
global_defs {
router_id lb01
}
#每5秒執行一次腳本,腳本執行內容不能超過5秒,否則會中斷再次重新執行腳本
vrrp_script check_web {
script "/server/scripts/check_web.sh"
interval 5
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 50
priority 150
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.0.0.3
}
# 調用並運行腳本
track_script {
check_web
}
}
EOF
注意:
- 搶佔式,僅需在Master的keepalived中調用腳本。
- 非搶佔式,需要兩台服務器都使用該腳本。


