AI在出行場景的應用實踐:路線規劃、ETA、動態事件挖掘…
前言:又到春招季!作為國民級出行服務平台,高德業務快速發展,大量校招/社招名額開放,歡迎大家投遞簡歷,詳情見文末。為幫助大家更了解高德技術,我們策划了#春招專欄#的系列文章,組織各業務團隊的高年級同學以科普+應用實踐為主要內容為大家做相關介紹。
本文是#春招專欄#系列的第1篇,根據高德機器學習研發部負責人damon在AT技術講壇所分享的《AI在出行領域的應用實踐》的內容整理而成。在不影響原意的情況下對內容略作刪節。
AT技術講壇(Amap Technology Tribune)是高德發起的一檔技術交流活動,每期圍繞一個主題,我們會邀請阿里集團內外的專家以演講、QA、開放討論的方式,與大家做技術交流。
damon根據用戶在出行前,出行中和出行後如何使用導航服務,分別選取了幾個典型的業務場景來介紹AI算法在其中的應用,最後對未來做了一些展望。

以某位同學周末和朋友相約去「木屋燒烤」店擼串為例,假設這位同學選擇駕車前往目的地,我們來看下AI算法是如何在導航過程中起到作用的。
出行前,先做路線規劃,ETA(預估到達時間),不要遲到;出行中,最怕的就是遇到突發動態事件而影響到出行時間;出行後(到目的地),餐館是否還在正常營業,也需要通過技術挖掘,幫助用戶提前規避白跑一趟的風險。
下面分別介紹。
出行前-路線規劃
路線規劃,和網頁搜索,商品搜索的推薦算法很相似,為用戶推薦一條符合個人喜好的優質路線。推薦的路線要符合以下幾個條件:
- 能走:此路能通,按照路線可以到達終點。
- 好走:路線質量在當前地點時間下確保優質。
- 千人千面:不同用戶在保證路線優質的前提下,個性化調整更符合用戶偏好。
同時,在不對用戶產生誤導的前提下,提供更多的對比參考給用戶來選擇:
- 優質:相比首路線/主路線,有一定的、用戶可感受到的優勢。
- 多樣:相比首路線/主路線,儘可能有自己的特長。
路線規划算法的特點
從用戶產生出行需求,到需求得到滿足。在用戶搜索的時候,上傳的Query除了有起終點和導航策略,也會像其他搜索一樣,有隱含的需求,比如個性化和場景化。在導航業務裏面,個性化可以拆分成熟路和偏好兩個維度,熟路比較容易理解,偏好是指用戶對時間、距離、紅綠燈、收費等不同維度上的偏好。
那麼,對應的解決方案,我們引入用戶ID,存儲記憶了用戶的起終點對應的熟路信息。對用戶的偏好,類似DIN的網絡結構,對用戶歷史導航序列進行建模,獲取用戶偏好信息。
在用戶提交搜索需求之後,對導航引擎來說,也分為召回,排序和過濾幾部分。
對於導航的召回,對性能要求比較高,所以目前召回的結果較少。對排序來說,同樣是多目標,而且多目標之間要進行平衡的業務。類比到電商推薦領域,不僅希望用戶更多地對商品進行點擊瀏覽,還希望用戶在看完商品介紹之後進行購買,提高GMV。
對於地圖出行,不僅希望用戶更多的使用導航且按照推薦的路線走,還希望實走時間要儘可能短,用戶反饋盡量好。
而且,和其他領域類似,多個目標之間會存在衝突,比如電商CTR和GMV。在導航領域,讓用戶儘可能的走封閉道路,沒有出口,那肯定實走覆蓋率就上升了,但是這樣規劃的路線會繞遠,時間和距離都變差。
多目標的平衡,如何在「帕累托最優」的情況下,進行多個目標之間的取捨、平衡,是大家一直在探索的問題,我們目前採用的是帶約束的最優化問題來進行建模,就是保證其他指標不變差的情況下,把某個指標最優化。
最後,用戶拿到導航引擎返回的路線結果,特點是信息少,用戶只能看到整條路線的總時間、總距離和收費等統計信息,對於這條路好不好走,能不能走很難知道。
而且,大部分用戶是在陌生場景下用導航,對導航依賴很重,很難決策走哪條路更好,這就導致排序在首條的方案選擇率很高,達到90%以上,這個偏置是很嚴重的,在訓練實走覆蓋率的時候,我們設計了偏置網絡,來吸收用戶這種傾向。
導航還有一個特點,一旦出錯,對用戶傷害特別大,比如遇到小路,用戶的車可能會出現刮蹭;遇到封路,用戶可能就得繞路,付出相當的時間和金錢成本。這往往會比信息搜索給用戶帶來的影響和傷害更大。所以,我們在過濾階段,對Badcase的過濾也是嚴格作為約束要求的。
路線規劃召回算法
路線規划算法,經典的是教科書上的Dijkstra算法,存在的問題就是性能比較差,線上實際應用都做了優化,這裡就不展開介紹了。
當起終點距離超過500公里,性能基本就不可接受了,雖然有啟發式A star算法,但是A star算法有可能丟最優解,並不是完美解決性能問題的方法。
解決性能問題的思路,一個是分佈式,一個是Cache,而最短路線搜索並不像網頁搜索,分佈式並不能很好的解決性能問題,所以目前工業界實際使用的算法都是基於Cache的方法。
Cache的方法就是提前把一些起終點對之間的最短路線計算好(Shortcuts),在用戶請求過來的時候,利用好這些Shortcuts,達到加快求路的目的(簡單舉例子,比如從北京到廣州,如果提前計算好了從北京到濟南,濟南到南京,南京到廣州的最短路徑,那就可以在計算北京到廣州的時候,利用這些提前計算好的最短路線)。
其中最為經典的一個算法就是CH算法(Contraction Hierarchies),在預處理階段,對所有節點進行了重要性排序,逐漸把不重要的點去掉,然後增加Shortcuts;Query查詢階段,從起點和終點分別開始雙向求路,只找重要性高的點,來達到加速的目的。
既然是Cache,就會面臨一個更新的問題,比如原始路網的路況變化了,或者原始路網某條路封路了,那麼提前緩存好的Shortcuts也需要更新。
這個時候CH的算法,由於Shortcuts結構設計不夠規律,更新就很慢,無法響應實時路況的變化。於是,路線規划算法推進到了下一代,CBR算法(Cell based Routing),這個算法通過分而治之的思想,在預處理階段,把全國路網切分成n個子圖,切分的要求是子圖之間連接的邊(邊界邊)儘可能的少。
在每個子圖內,再繼續往下切分,進而形成金字塔結構,預處理階段就是把邊界邊之間的最短路徑都提前算好,Cache下來求路的時候,就可以利用這些Shortcuts了。
CBR的優點是,在預處理階段,路網的切分是分層的,每一層都足夠小,在更新這一層的Shortcuts的時候,可以把數據都放到CPU的L1 Cache里去,所以計算速度特別快。
總結一下CBR和CH的區別:
- Query查詢性能,CH更快,CH是0.1ms級別,CBR是1-2ms級別。
- Shortcuts更新性能,CH全國路網更新最快能做到10分鐘,而CBR能做到15秒更新全國,可以滿足實時路況變化和路網實時更新的需求。
- CH的Shortcuts不規律,導致不同策略之間(躲避擁堵,高速優先等)不能很好的復用Shortscuts的起終點結構,所以不同策略需要單獨重建Shortcuts,內存佔用非常大。
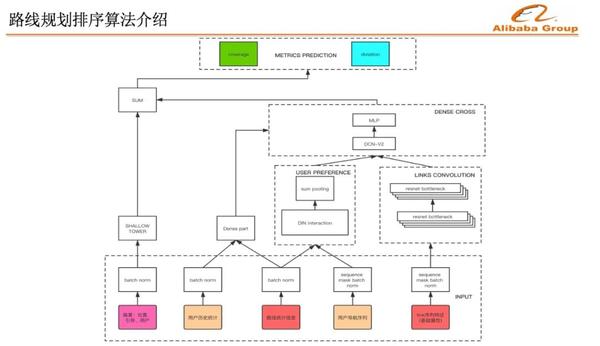
這是我們排序的網絡結構,左邊是用戶偏置網絡,把路線排序的順序,以及引導路線之間的相似度信息輸入進去,期望儘可能消除掉偏置帶來的影響。中間輸入的用戶歷史統計信息和用戶導航序列信息,用來提取用戶的個性化偏好。優化的主要目標是實走覆蓋率。
新一代的路線規划算法,要求提供隨時間推演的能力。比如8:00從起點出發,後面要走 1 2 3 ..n條路到達目的地,假設8:10走到第2條道路,8:20走到第3條道路,那麼我們在8:00計算Shortcuts的時候,就不能只用到8:00的路況,需要把後續進入某個道路的時刻考慮進來,用那個時刻的路況來計算,這就是TDR求路算法,目前是高德首創的,能真正實現躲避未來的擁堵,並利用未來的暢通來規劃路徑。
出行前-ETA(預估到達時間)
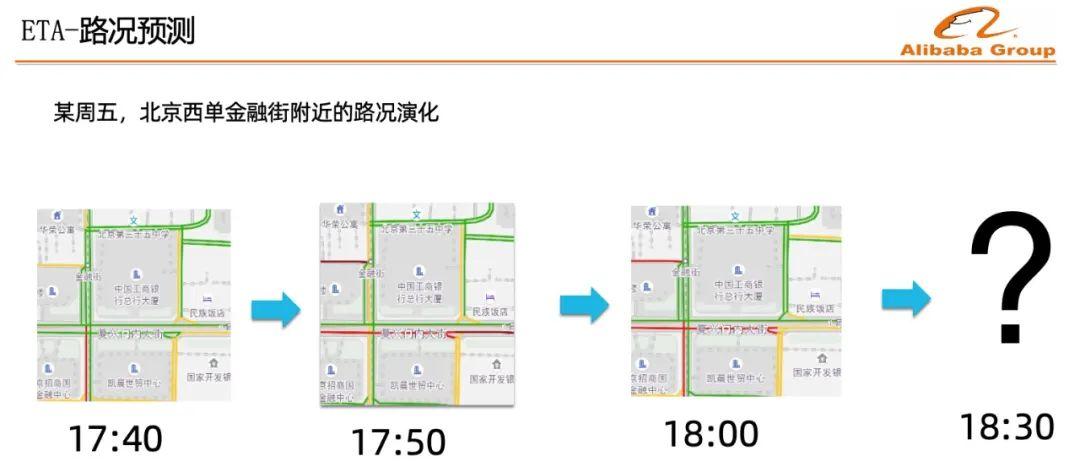
上面三幅圖,選取的是北京西單金融街附近的區域,展示了在三個相鄰時間點上的交通狀況。其中綠色、黃色、紅色代表交通路況不同的狀態。
假設現在是18點整,路況預測的目標就是預估未來時刻的交通狀況,需要依賴每條道路的歷史信息,以及周邊鄰居的道路擁堵信息,對時空兩個維度進行建模。
對時間序列的建模,用RNN,LSTM等SEQ2SEQ的序列,也有採用CNN,TCN等。對空間信息的建模,目前主流的方法是用GRAPH.
儘管模型在不斷升級,越來越複雜,但是對於突發事件導致的擁堵,根據歷史統計信息,很難預測精準,比如去年9月份在上海世博園區舉行外灘大會,世博園平時很少有人去,歷史路況都是暢通,而在開會期間,車很多導致很堵。
這個時候靠歷史信息是很難預測準確,我們需要一個能代表未來的信號,才能預測,這就是路線規劃的信息,如果想去世博園的人很多,那麼規劃的量就會很多,我們根據規劃的量,就能知道未來有很多人想要去世博園,就會導致世博園擁堵。
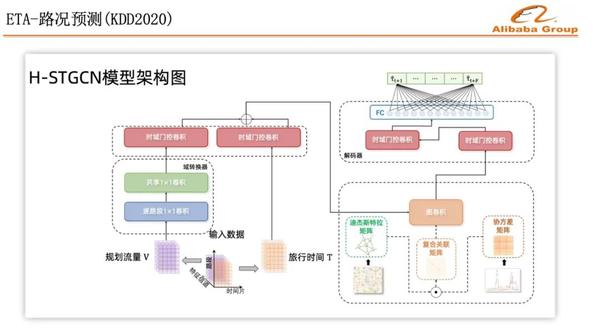
所以,我們把規劃的量,通過一個流量往時間域的轉換,引入到路況預測模型,效果取得明顯提升,尤其是在突發擁堵的時候,高德的這個研究成果被KDD2020收錄,並且已經在業務場景中得到了應用,有興趣的同學可以詳細查看我們的論文。
行中-用文本數據挖掘動態交通事件
繼續向餐館前進,導航途中,最怕遇到擁堵,封路等事件,所以高德會想盡一切辦法挖掘這些動態事件,幫助用戶規避開。現在高德用到了多個維度的數據源,其中的行業和互聯網情報都是文本數據,要用到NLP的技術來挖掘。
介紹一下怎麼用AI算法來挖掘動態事件。
下面一段文本就是典型的來自於網絡媒體的信息:
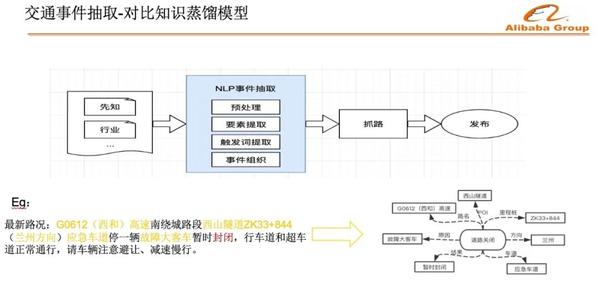
G0612(西和)高速南繞城路段西山隧道ZK33+844(蘭州方向)應急車道停一輛故障大客車暫時封閉,行車道和超車道正常通行,請車輛注意避讓、減速慢行。
這段信息是非結構化的,需要我們做預處理,要素提取,再進行事件的組織,組織成架構化的信息,才能自動化的應用。
很自然的,針對要素提取,我們用BERT模型建模,但是BERT模型太複雜,性能比較差,線上實際應用帶來很大的挑戰。
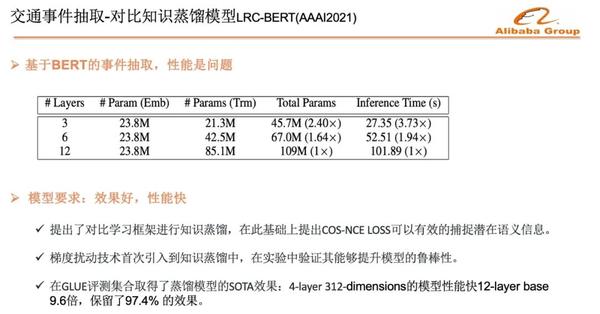
我們採取了知識蒸餾的方法,訓練一個簡單的Student的網絡,來解決性能問題。知識蒸餾最主要的是如何捕捉潛在語義信息。高德在業界率先提出了用對比學習框架進行知識蒸餾,同時,在計算樣本之間距離的時候,提出COS-距離代替歐氏距離的方法,能夠讓模型有效的學習到潛在語義表達信息。
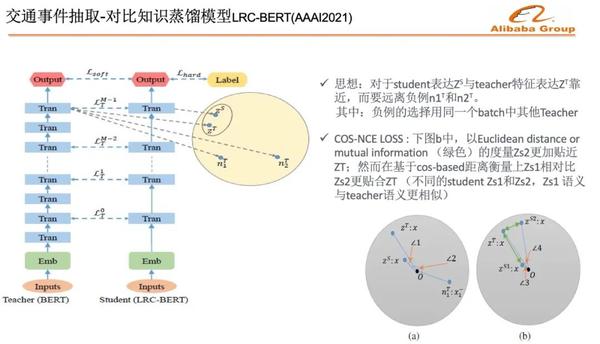
對於Student表達的特徵向量與Teacher特徵向量距離靠近,而要遠離負例。使用餘弦距離,比如歐式距離,能夠更好適應Teacher網絡和Student網絡,輸出的特徵向量長度分佈不一致的問題,這個工作成果發表在了AAAI2021上。
出行後-POI數據過期(增強現勢性)的問題
人們在高德地圖上會看到很多地理位置興趣點(Point of Interest,縮寫為POI),例如餐廳、超市、景點、酒店、車站、停車場等。對POI數據的評價維度包括現勢性、準確性、完備性和豐富性。
其中,現勢性就是地圖所提供的地理空間信息反映當前最新情況的程度,簡而言之,增強現勢性就是指儘可能快速地發現已停業、搬遷、更名、拆遷的過期冗餘POI數據,並將其處理成下線狀態的過程。這部分可以參考我們之前發佈的文章《高德地理位置興趣點現勢性增強演進之路》。
以上僅是AI算法在出行場景應用的一些舉例,更多的技術方案歡迎大家來和我們一起探討。
出行前景-全局調度
對網頁搜索來說,結果是信息,可以無限複製,互不影響;對電商搜索來說,結果是商品,可以認為商品足夠多,不夠再生產,所以也可以認為互不影響。
不同的是,導航搜索出來的道路資源是有限的,你用的多了,我就用的少。比如,一條路暢通,我們把人導過去,那麼這條路就堵死了,所以我們要做全局調度,提高道路資源的使用率。
我們希望全局調度系統能和交通信號燈打通,在一個交通仿真的環境下,用多智能體強化學習的方法,學習到更大規模的交通系統上如何統籌協調車輛、交通燈,充分利用道路資源,進一步緩解擁堵。我們一起來探索!
春招火熱進行中,2022屆畢業生看過來!
春招火熱進行中,2022屆畢業生看過來!
春招火熱進行中,2022屆畢業生看過來!


