「螞蟻牙黑」太火,想玩就用ModelArts做一個!
摘要:本文將介紹如何借力一站式 AI 開發平台,「傻瓜式」操作實現生成「螞蟻牙黑「小視頻。
作者:華為雲EI專家胡琦
一夜之間,朋友圈都在「螞蟻牙黑」!網友卻擔心……”Baby, don’t worry, we have ModelArts!”,是的,咱用 ModelArts 來製作,無需擔心「有人模仿我的臉?」,也不用擔心偌大的水印。不過,使用別人的臉可能真的有法律風險!本文將介紹如何借力一站式 AI 開發平台,「傻瓜式」操作實現生成「螞蟻牙黑「小視頻。
環境準備
ModelArts 和她的最佳搭檔–對象存儲服務 OBS ,您可以理解為是「網盤」,主要要來存放數據集、模型或其他文件。

ModelArts: //www.huaweicloud.com/product/modelarts.html AI開發平台ModelArts是面向開發者的一站式AI開發平台,為機器學習與深度學習提供海量數據預處理及半自動化標註、大規模分佈式Training、自動化模型生成,及端-邊-雲模型按需部署能力,幫助用戶快速創建和部署模型,管理全周期AI工作流。

OBS: //www.huaweicloud.com/product/obs.html
對象存儲服務(Object Storage Service,OBS)提供海量、安全、高可靠、低成本的數據存儲能力,可供用戶存儲任意類型和大小的數據。適合企業備份/歸檔、視頻點播、視頻監控等多種數據存儲場景。
使用以上服務會有一定費用產生,或者您可以嘗試認證為開發者會有一定代金券贈送,當然關注 ModelArts 和加入 ModelArts 開發者社區也會有機會獲得大額代金券。
模型、素材準備
本次實現使用的是用於圖像動畫的一階運動模型,這是一種基於關鍵點和局部仿射變換的圖像動畫方法,
論文地址://arxiv.org/abs/2003.00196
下載預訓練模型及素材
最近手頭緊,非常抱歉不能為大家提供 OBS 路徑直接下載,我已將預訓練模型及素材上傳到 AI Gallery 數據集,請自行下載到您的 OBS 中。當然如果您有可快速下載的地址,歡迎分享!
源文件地址://drive.google.com/drive/folders/1kZ1gCnpfU0BnpdU47pLM_TQ6RypDDqgw?usp=sharing 或者//drive.google.com/drive/folders/16inDpBRPT1UC0YMGMX3dKvRnOUsf5Dhn?usp=sharing 因為是源文件,因此不包含」螞蟻牙黑「原視頻素材,但我已添加至AI Gallery 數據集。如仍有需求,可以直接找我要,公眾號:胡琦,WeChat:Hugi66;歡迎加入 ModelArts 開發者社區,廣州地區的小夥伴可以加入我們共創 MDG 廣州站哦!
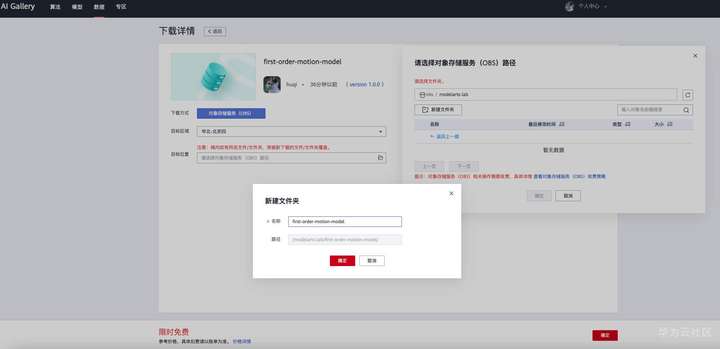
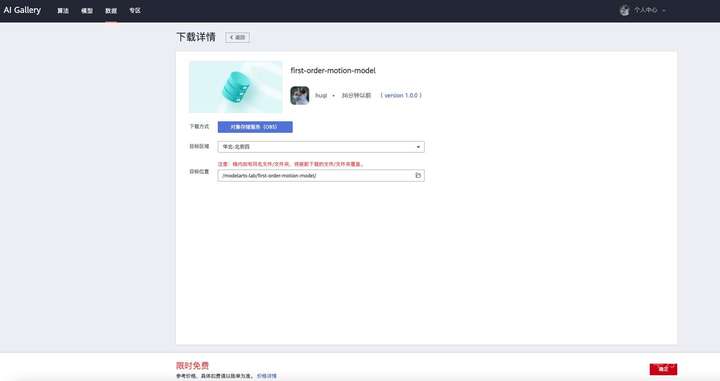
AI Gallery 是在 ModelArts 的基礎上構建的開發者生態社區,提供模型、算法、HiLens技能、數據集等內容的共享和交易。因此您可以下載分發的數據集或文件到您的 OBS ,使用時請遵守相應的政策和規則!打開 //marketplace.huaweicloud.com/markets/aihub/datasets/detail/?content_id=00bc20c3-2a00-4231-bdfd-dfa3eb62a46d 點擊下載按鈕進入下載詳情,設置 OBS 路徑,確定下載即可將模型和素材下載到自己的 OBS 中,比如我路徑是/modelarts-lab/first-order-motion-model。下載進度可以在 AI Gallery 個人中心-我的下載查看。


JUST DO IT — ModelArts 我的筆記本
接下來開始使用 ModelArts–我的筆記本 ,即開即用的在線集成開發環境,可以輕鬆的構建、訓練、調試、部署機器學習算法與模型。當前使用免費規格用於體驗, 值得留意的是 72 小時內沒有使用,會釋放資源,因此需要注意文件備份。當然還可以使用 Notebook 免費算力,記得選擇 GPU 環境哦!
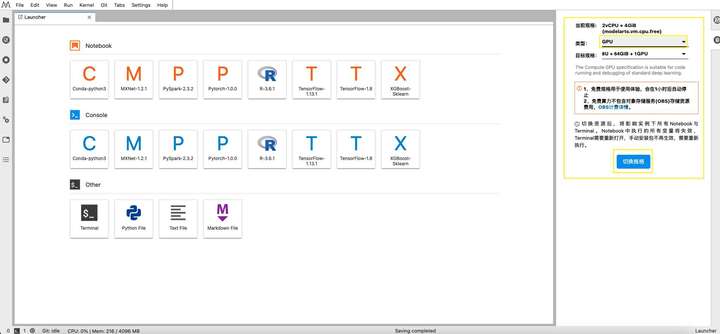
當我們使用我的筆記本時默認開啟的是 CPU 環境,因此我們需要切換到 GPU 環境。目前 ModelArts-我的筆記本 支持8 vCPU + 64 GiB + 1 x Tesla V100-PCIE-32GB。
新建Pytorch 1.0的.ipynb文件,開始我們的「螞蟻呀嘿」體驗之旅。
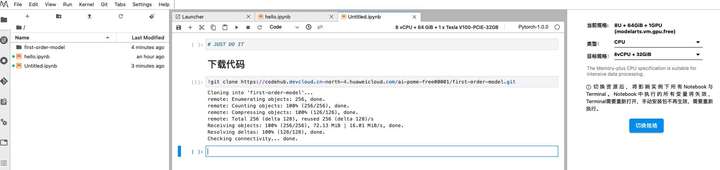
下載代碼
!git clone https://github.com/AliaksandrSiarohin/first-order-model # or !git clone https://codehub.devcloud.cn-north-4.huaweicloud.com/ai-pome-free00001/first-order-model.git
github 速度慢,建議轉存到華為雲代碼託管平台再拉取。
此處提供我已經緩存好的代碼倉庫地址,因此不再演示如何將 github 代碼遷移到 codehub。(不保證我的賬號欠費而無法訪問,因此建議大家以自己的方式上傳代碼到 Notebook !)
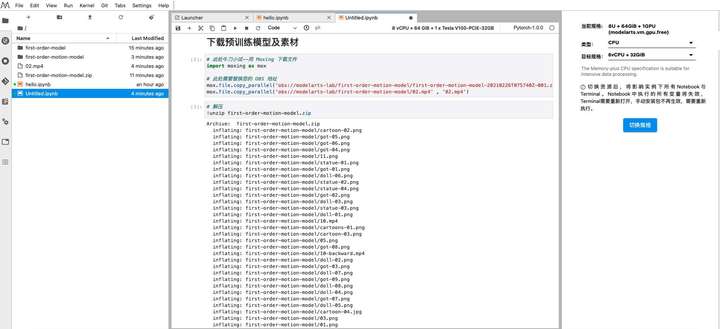
利用 Moxing 拷貝文件到 JupyterLab,將之前下載到 OBS 中的模型和素材通過 Moxing 拷貝過來,此處注意替換為您的 OBS 路徑。02.mp4是「螞蟻呀嘿」的模版視頻,
# 此處牛刀小試--用 Moxing 下載文件 import moxing as mox # 此處需要替換您的 OBS 地址 mox.file.copy_parallel('obs://modelarts-lab/first-order-motion-model/first-order-motion-model-20210226T075740Z-001.zip' , 'first-order-motion-model.zip') mox.file.copy_parallel('obs://modelarts-lab/first-order-motion-model/02.mp4' , '02.mp4')
# 解壓 !unzip first-order-motion-model.zip # 模版視頻 !mv 02.mp4 first-order-motion-model/
-
JUST DO IT
準備工作完成之後,擼起袖子就是干!切換到first-order-model目錄,然後將 source_image_path中的路徑替換為」您的臉」所在的路徑,臉的照片可以直接通過 Notebook 的文件上傳功能上傳。當然您還可以將默認的「螞蟻牙黑」視頻替換為您自定義的視頻,格式為 mp4。一路執行可以查看到合成前的預覽。
cd first-order-model import imageio import numpy as np import matplotlib.pyplot as plt import matplotlib.animation as animation from skimage.transform import resize from IPython.display import HTML import warnings warnings.filterwarnings("ignore") # 此處替換為您的圖片路徑,圖片最好為 256*256,這裡默認為普京大帝 source_image_path = '/home/ma-user/work/first-order-motion-model/02.png' source_image = imageio.imread(source_image_path) # 此處可替換為您的視頻路徑,這裡默認為「螞蟻牙黑」 reader_path = '/home/ma-user/work/first-order-motion-model/02.mp4' reader = imageio.get_reader(reader_path) # 調整圖片和視頻大小為 256x256 source_image = resize(source_image, (256, 256))[..., :3] fps = reader.get_meta_data()['fps'] driving_video = [] try: for im in reader: driving_video.append(im) except RuntimeError: pass reader.close() driving_video = [resize(frame, (256, 256))[..., :3] for frame in driving_video] def display(source, driving, generated=None): fig = plt.figure(figsize=(8 + 4 * (generated is not None), 6)) ims = [] for i in range(len(driving)): cols = [source] cols.append(driving[i]) if generated is not None: cols.append(generated[i]) im = plt.imshow(np.concatenate(cols, axis=1), animated=True) plt.axis('off') ims.append([im]) ani = animation.ArtistAnimation(fig, ims, interval=50, repeat_delay=1000) plt.close() return ani HTML(display(source_image, driving_video).to_html5_video())
-
創建模型並加載 checkpoints
這一步完成之後,我們便得到了「螞蟻呀嘿」的視頻了–「generated.mp4」,這就結束了?不過,問題來了……
from demo import load_checkpoints generator, kp_detector = load_checkpoints(config_path='config/vox-256.yaml', checkpoint_path='/home/ma-user/work/first-order-motion-model/vox-cpk.pth.tar')
from demo import make_animation from skimage import img_as_ubyte predictions = make_animation(source_image, driving_video, generator, kp_detector, relative=True) # 保存結果視頻 imageio.mimsave('../generated.mp4', [img_as_ubyte(frame) for frame in predictions], fps=fps) # 在 Notebook 根目錄能找,/home/ma-user/work/ HTML(display(source_image, driving_video, predictions).to_html5_video())


-
後續操作
如果您和我一樣直接下載並打開上面操作的產物–generated.mp4,您一定會和我一樣困惑:聲音呢?是的,聲音丟失了,因為核心代碼只處理圖像,聲音需要我們自行找回,因為我們使用moviepy。不僅如此,我們還可以為視頻加水印。
-
安裝 moviepy 為視頻剪輯做準備
# 安裝視頻剪輯神器 moviepy
!pip install moviepy
-
為視頻添加背景音樂
# 為生成的視頻加上源視頻聲音 from moviepy.editor import * videoclip_1 = VideoFileClip(reader_path) videoclip_2 = VideoFileClip("../generated.mp4") audio_1 = videoclip_1.audio videoclip_3 = videoclip_2.set_audio(audio_1) videoclip_3.write_videofile("../result.mp4", audio_codec="aac")
-
別人花錢去水印,而我還要加水印,歡迎加入MDG!
# 還可以給視頻加水印 video = VideoFileClip("../result.mp4") # 水印圖片請自行上傳 logo = (ImageClip("/home/ma-user/work/first-order-motion-model/water.png") .set_duration(video.duration) # 水印持續時間 .resize(height=50) # 水印的高度,會等比縮放 .margin(right=0, top=0, opacity=1) # 水印邊距和透明度 .set_pos(("left","top"))) # 水印的位置 final = CompositeVideoClip([video, logo]) final.write_videofile("../result_water.mp4", audio_codec="aac") final_reader = imageio.get_reader("../result_water.mp4") fps = final_reader.get_meta_data()['fps'] result_water_video = [] try: for im in final_reader: result_water_video.append(im) except RuntimeError: pass reader.close() result_water_video = [resize(frame, (256, 256))[..., :3] for frame in result_water_video] HTML(display(source_image, driving_video, result_water_video).to_html5_video())
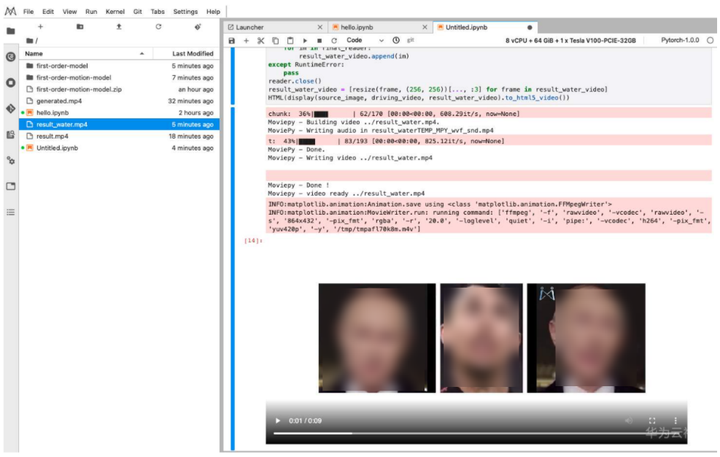
至此,本次實現先告一段落,關於「多人運動」–合照的解決辦法還沒來得及探索,歡迎您在評論區分享指導,感謝!
本文分享自華為雲社區《”螞蟻牙黑”,快用 ModelArts 自己實現一個!》,原文作者:胡琦 。


