看YouTube學做廣播體操?機械人即將掌握人類所有動作 | 一周AI最火論文
- 2019 年 12 月 2 日
- 筆記

大數據文摘專欄作品
作者:Christopher Dossman
編譯:Olivia、Vicky、雲舟
嗚啦啦啦啦啦啦啦大家好,本周的AIScholar Weekly欄目又和大家見面啦!
AI ScholarWeekly是AI領域的學術專欄,致力於為你帶來最新潮、最全面、最深度的AI學術概覽,一網打盡每周AI學術的前沿資訊。
每周更新,做AI科研,每周從這一篇開始就夠啦!
本周關鍵詞: 智能機械人、姿態估計、沉浸式交互
本周最佳學術研究
能夠「觀看和學習」YouTube視頻的機械人
機械人世界正在迅速地發展,很快我們就會目睹機械人掌握更多之前只有人類能夠掌握的技能。在這篇論文中,研究人員提出了一個激動人心的課題——指導機械人複製視頻中的動作。他們解決了機械人對協同動作計劃學習的挑戰。
研究的目標是讓機械人在互聯網上「觀看」視頻、提取視頻中的動作序列並將其轉換為可執行的計劃,使其既可以自主執行、也可以作為機械人團隊和人機團隊中的一部分來執行。

為了演示該框架的適用性,研究人員輸入了一個YouTube視頻,該視頻演示了一個完整的協作烹飪任務。該框架假定視頻中的目標已被標記,並使用一個最新的目標檢測模型為每個目標限定一個邊界。
技術世界正處於一個令人興奮的發展階段,尤其是在機械人技術等機器學習技術不斷進步的當下。更令人激動的是,互聯網中包含的大量視頻內容都可以被機械人用以執行人機團隊和機械人團隊中的協同任務。
在本文演示中,兩個機械臂重現了一個簡單的烹飪視頻。這是朝着機械人通過在線觀看視頻來執行一系列操作計劃的目標,邁出的重要一步。本文方法的局限性來自最新的目標檢測技術需要滿足的前提假設等。
原文:
https://arxiv.org/abs/1911.10686
用於六維姿態估計的多視圖匹配網絡
本文中,研究人員提出了一種新技術,用於估計單個RGB圖像中的六維姿態。
該方法結合了目標檢測和分割方法,通過將輸入圖像與渲染圖像進行匹配來估計、優化和跟蹤目標的姿態。
首先,研究人員使用Mask R-CNN來檢測和分割輸入圖像中感興趣的目標;然後,使用多視圖匹配模型來估計該目標的6D姿態;最後,使用單視圖匹配模型完善姿態估計。該方法獲得的準確度可與常規RGB姿態估計的最新方法(如PoseCNN + DeepIM)得到的準確度相媲美。

本文為如何擴展獨特的模型用於估計、改進和跟蹤目標的姿態,提供了新的研究思路。
本項研究提出的方法展示了網絡如何自動協助優化和跟蹤過程。該方法擴展了一個用於姿態估計、改進和跟蹤的姿態優化網絡DeepIM,而無需使用外部的初始姿態估計方法。
因此,初始姿態估計網絡(如PoseCNN)可能會被可用度高的目標檢測網絡所取代,而該目標檢測網絡已通過大型訓練數據集進行了訓練。
原文:
https://arxiv.org/abs/1911.12330
使用圖像分析和檢測社會關係
本文中,兩名研究人員提出了一種可用於圖像集中的面部圖表示的方法。該方法根據面部表情、親近程度、同時出現和頭部朝向來分析在一個社交活動中有多少人被聯繫起來。為了實現這一目標,研究人員定義了集合中每對目標之間的「連通性」測量值,該值代表了他們之間的關聯程度。
在下圖中,節點表示集合中的主題,邊緣表示節點之間的連接。節點越近,主題之間的聯繫就越緊密。
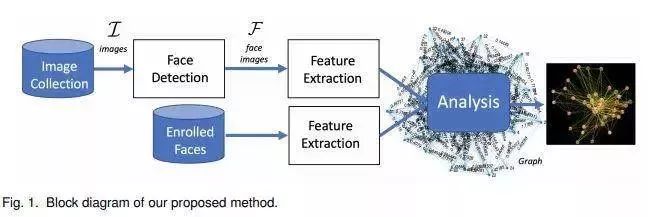
研究人員還開發了圖形用戶界面,用戶可以在界面中單擊節點或邊緣來展示存在相連主題的圖像集。
文中通過分析婚禮慶典、情景喜劇視頻、排球比賽以及從Twitter提取的帶有標籤的圖像提供了較為準確的結果。
的確,人臉識別和分析的最新技術還遠遠不夠完美。因此,為了對社會關係進行更強有力地分析,任何有助於檢測和衡量圖像集中個人互動的貢獻都很重要。
本文提供的工具對於檢測圖像集中現有的社會關係非常有幫助。未來,研究人員希望通過分析連通性矩陣,將檢測目標增加到三人或更多。
原文:
https://arxiv.org/abs/1911.11970
以智能手機為觸摸板在大型沉浸式顯示器中進行多人交互
自誕生之日起,智能手機就完成了許多曾經被定義為Impossible Mission的任務。在這次的研究中,智能手機可以用作多人空間交互界面的觸摸板了!
這項工作背後的研究人員提出了多種方法,合併了用戶物理位置、輸入設備(如智能手機和藍牙麥克風)等信息,並將個人和共享屏幕區域進行自動情境化,使多個用戶同時與一個大型的沉浸式屏幕進行交互。
個人互動區域出現在矩形封閉屏幕的兩側,用戶可以在其中自由移動,選擇空間,並操縱或生成相關圖像。中間的共享屏幕區域可供多個用戶同時使用,這一區域會基於用戶選擇的圖像和預先定義的環境來生成布局。
該方法允許多個用戶以自然的方式與較大的視覺沉浸式空間進行交互。
它可以將各種個人設備和語音與空間智能集成在一起,定義個人和共享交互區域,這為利用空間進行應用(包括課堂學習、協作、遊戲等)提供了可能性。
視頻演示:
https://arxiv.org/abs/1911.11751v1
實現有效的Mix-and-Match圖像生成
在本文中,研究人員介紹了一個叫做MixNMatch的條件生成模型,它可以學習從真實圖像中分離編碼背景、對象姿態、形狀和紋理因素等。MixNMatch提供了圖像生成中的細粒度控制,其中每個因子都可被唯一地控制。

MixMatch在訓練期間需要邊界框來對背景建模,但不需要其它監督。它以實際參考圖像、採樣的潛在代碼或兩者的混合作為輸入,以準確分離、編碼和組合多個因素,以生成混合匹配圖像。
自從生成對抗網絡(GAN)發現以來,圖像生成已經取得了長足的進步。這項工作演示了如何將來自四個不同圖像的各種形狀、姿勢、紋理和背景進行組合,以創建全新的圖像。
通過許多有趣的應用程序(包括sketch2color、cartoon2img和img2gif),圖像生成在實現真實圖像的最新細粒度對象類別聚類結果方面取得了顯著成果。
這一研究目前還存在着一些限制,如MixNmatch未能生成良好的對象掩碼,從而生成不完整的對象。
代碼/模型/演示:
https://github.com/Yuheng-Li/MixNMatch
原文:
https://arxiv.org/abs/1911.11758v1
其他爆款論文
一種低成本、開源和模塊化的軟機械人設計和構造套件:
https://arxiv.org/abs/1911.10290
基於數字圖像的AI診斷皮膚癌方案研究進展:
https://arxiv.org/abs/1911.11872
一種全新的結合自然語言、視覺和動作的端到端模仿學習方法:
https://arxiv.org/abs/1911.11744
有了這款Pixel Camera app ,媽媽再也不用擔心美圖秀秀拯救不了我黑燈瞎火拍的照片了:
https://ai.googleblog.com/2018/11/night-sight-seeing-in-dark-on-pixel.html
FBI,open up!新的端到端深度學習框架,可同時預測身份、活動和用戶位置:
https://arxiv.org/abs/1911.11743
數據集
圖像協調數據集:
https://github.com/bcmi/Image_Harmonization_Datasets
開放式多評分睡眠分期數據集:
https://arxiv.org/pdf/1911.03221v2.pdf
AI大事件
這個基於飛槳(Paddle Paddle)的新對象檢測框架在2019谷歌物體識別–目標檢測比賽中榮獲第二名:
https://arxiv.org/abs/1911.07171
谷歌通過Explainable AI解決黑匣子問題:
https://www.bbc.com/news/technology-50506431
讓AI來告訴你,今天你會進醫院嗎?
https://www.zdnet.com/article/ai-in-healthcare-using-algorithms-to-predict-your-risk-of-ending-up-in-hospital/
阿里巴巴在GitHub上分享了其機器學習算法平台Alink的核心代碼:
https://www.zdnet.com/article/alibaba-cloud-publishes-machine-learning-algorithm-on-github/

專欄作者介紹
Christopher Dossman是Wonder Technologies的首席數據科學家,在北京生活5年。他是深度學習系統部署方面的專家,在開發新的AI產品方面擁有豐富的經驗。除了卓越的工程經驗,他還教授了1000名學生了解深度學習基礎。
LinkedIn:
https://www.linkedin.com/in/christopherdossman/
志願者介紹
後台回復「志願者」加入我們





點「在看」的人都變好看了哦!


