如何避免微服務設計中的耦合問題
如何避免微服務設計中的耦合問題
譯自:How to Avoid Coupling in Microservices Design
Distributed monolith (分佈一體式)是一個幽默的詞,用來暗指那些設計欠佳的架構。如果忽略了微服務設計實踐,不僅會無法克服一體式帶來的缺點,也會導致出現新的、複雜的問題或惡化已存在的問題。當你在自豪地稱之為微服務架構的同時,由於設計上缺少足夠目的性的,最終的架構與隨機爆破而成的碎片沒有什麼區別。
避免分佈一體式的第一步非常簡單:避免同時實現微服務。一體式是簡單的,因為無需考慮分佈式系統存在的複雜性。一個數據庫,一個日誌存儲位置,一個監控系統,更簡單的問題定位,以及端到端測試等等。除非你有充分的理由去使用微服務,否則最好採用同樣的理念。
本文將主要關注微服務設計中的松耦合的重要性。我將給出一些簡單的、可以避免耦合和導致分佈一體式架構設計的例子。
微服務中的松耦合?
兩個系統中,如果修改任意一方的設計、實現或行為不會對另一方造成影響,則稱兩個服務是松耦合的。當涉及到微服務時有可能會發生耦合,即對一個微服務的修改,會立即直接或間接地影響到與其他所有微服務的協作。
下面看一些設計中存在耦合的場景。
數據庫共享
數據庫共享是實現耦合的一種常見方式。當一個服務修改其實現時,會導致修改另外一個服務的實現。
選擇數據存儲、方案、以及請求的語言等細節應該對客戶端不可見,如果共享了數據庫,則可能會暴露所有的實現細節。為什麼要隱藏實現細節?這是因為如果暴露了實現細節,那麼未來對實現細節進行調整時將有可能會導致客戶端代碼不可用,除非客戶端也同步做了相應的修改(這種方式是不可行或不可持續的)。在圖1的左側,Customers 與 Orders共享了數據庫,因此Orders可以訪問Customers 的數據模型細節,當這些細節發生變化時,有可能會導致異常。
應該如何處理?
一種方式是像圖1的右側那樣,讓Customers 提供一個API,Orders客戶以通過該API獲取customer的數據。只要Customers的合同不變,則數據格式也不會發生變化。Orders 無需知道數據的來源,且Customers 可以自主決定將該數據替換為另一個流數據源,而無需擔心對其他服務的影響。
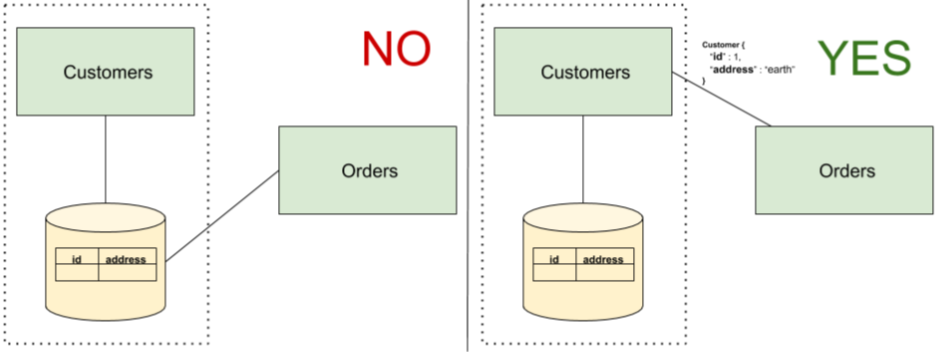
Fig. 1 — Implementation coupling through database sharing
代碼共享
除了使用獨立的數據庫,微服務還有可能掉入共享庫耦合的陷阱中。除了耦合造成的問題外,共享庫的膨脹也可能導致需要通過不斷更新來滿足客戶端的需求。因此共享代碼應該盡量輕量,且盡量減少依賴性,並且應排除特定領域的邏輯。
在圖2的左側,Customers 在與Orders共享的庫中定義了customer 對象。Customers 使用該對象模型來響應對customer 數據的請求。Orders 使用相同的對象來讀取(請求的)響應body。如果Customers 打算對customer 對象的內部結構進行調整時,如將地址字段切分為多條地址線,這種情況會導致Orders 服務崩潰。注意這種不正確的模式也可能會影響客戶對編程語言的選擇,例如當Customers 決定切換到一個不同的編程語言,它需要考慮使用其對象模型實現的所有服務。
應該如何處理?
Customers 和 Orders 應該在獨立依賴庫中包含customers 對象的拷貝。只要Customers 遵循”合同”,則所有服務都可以正常運行。
記住,每次發生變更時,你不需要將一堆崩潰的服務黏合到一起,只需要專註於創建一個靈活的架構,並丟掉分佈一體式。

Fig. 2–Implementation coupling through code sharing
同步通信
當由於服務(呼叫者)期望另一個服務(被呼叫者)的即時響應而無法繼續處理時,便會發生暫時性耦合。由於被呼叫者存在響應延遲,因此有可能會對呼叫者的響應時間造成不利影響。被調用者必須保持開啟狀態,並能夠正常響應。這種情況通常發生在同步通信的場景下。
如圖3所示,Customers 準備數據的時間越長,Orders 在響應客戶端之前等待的時間也就越長。換句話說,Customers 的響應延遲導致了Orders 的響應延遲。這種處理方式也可能導致級聯錯誤,如果Customers 無法響應,Orders 最終也會因為超時而無法響應。如果在一段時間內,Customers 一直很慢且無法響應,則可能會導致Orders 打開大量到Customers的連接,最終導致內存耗盡而失敗。為了提供一個滿意的服務,Orders 應該消除暫時性耦合存在的基礎。沒有人希望憤怒的顧客排隊等待他們的訂單到達,分佈一體式的創建者也不例外。
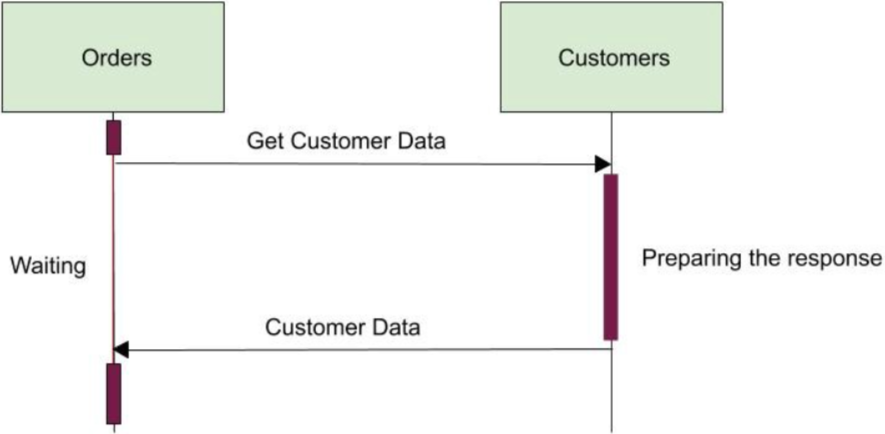
Fig. 3 — Temporal coupling caused by synchronous communication between services
應該如何處理?
問題的答案依賴於你需要一個長期的還是一個短期的解決方案。如果你需要繼續使用同步調用,則需要通過緩存(請求的)響應或使用熔斷模式控制級聯失敗的方式來降低暫時性的依賴。一種更好的方式是切換到異步通信,使用輪詢或依賴像Kafka這樣的消息代理來傳遞消息。當採用異步通信時,服務應該考慮和下游服務達成最終一致性狀態的延遲對響應時間的影響,並做出必要的調整來防止”合同”的中斷。服務級別的協定是”合同”的重要組成部分。
共享測試環境
當持續集成或持續發佈一個服務需要依賴另一個服務時,就會發生部署耦合。微服務意味着敏捷,獨立的部署和處理是實現該目標的必要條件。
一個典型的例子是:部署的服務共享相同的測試環境。假設一個服務在最終部署到生產環境前需要做一個簡單的性能測試。如果該服務與其他服務共享相同的測試環境(有可能同時運行性能測試),有可能會導致測試環境崩潰或由於發生非預期的高流量而導致資源飽和,最終有可能會導致部署失敗。

Fig. 4 — Deployment coupling caused by sharing test environments
在圖4的左側,Delivery 和Orders使用相同的Customers 服務來模擬進行性能測試。Orders 團隊最初設計該模擬服務的目的是為了在給定資源量的情況下模仿客戶的行為。在添加了Delivery 之後,計算的資源量將會失效,同時運行兩個服務的性能測試將會導致部署失敗。因此,必須重新配置模擬服務,以使用更多資源來模仿相同的響應率。
應該如何處理?
很簡答,不要和任何服務共享模擬服務。
運行集成測試的下游服務
這也是一種部署耦合。當針對一個微服務的實例進行功能測試時,該微服務實例會在非測試環境中直接調用下游服務。這種依賴性會導致下游服務必須在整個測試階段保持運行狀態。任何可用性延遲或下游服務的響應時間都可能會導致測試、構建流程以及部署同時失敗。
應該如何處理?
在集成測試中模擬下游服務(除非有充足的理由必須使用真實的下游服務)。更好的方式是將下游服務容器化,並加載到相同的微服務實例中,以此來避免網絡連接問題。
共享過多的領域數據
領域驅動設計(DDD)是將一體式服務拆分為微服務的推薦技術。一般原則是為每個業務子域啟用一個微服務。每個微服務都在其子域的邊界內運行,而不必處理其外部的任何事物。
如果微服務共享領域特定的數據,則會導致領域耦合,違背了分離邊界的初衷。服務將無法控制客戶端如何使用共享的數據。一個客戶端可能會無意間擁有其本不該擁有的數據,或因為缺乏特定領域的知識而錯誤地使用這些數據。
再者,如果服務共享了太多的領域數據,則有可能因為共享敏感數據而引入安全風險。你可能會對自己認為的敏感數據進行防護,但無法保證客戶端也做出類似的動作,這是因為對這部分數據的責任和認知已經超出了它們的範疇。
圖5展示了一個領域耦合的例子。在圖的左側,Orders向Customers 請求customer數據,然後接收到customer的信用卡號以及地址。再調用Billing,傳遞費用和商品ID,以及所有這些數據。在Billing成功向客戶收費後,Orders 會向Delivery發送相同的數據字段集。圖的右側,展示了這些微服務間期望交互的數據。如果設計合理,Billing應該是唯一一個擁有並保存賬單信息的微服務,不需要從其他服務接收這些信息。
應該如何處理?
僅共享客戶端真正需要的數據,如果客戶端需要的數據超出了領域邊界,則需要重新考慮服務邊界。
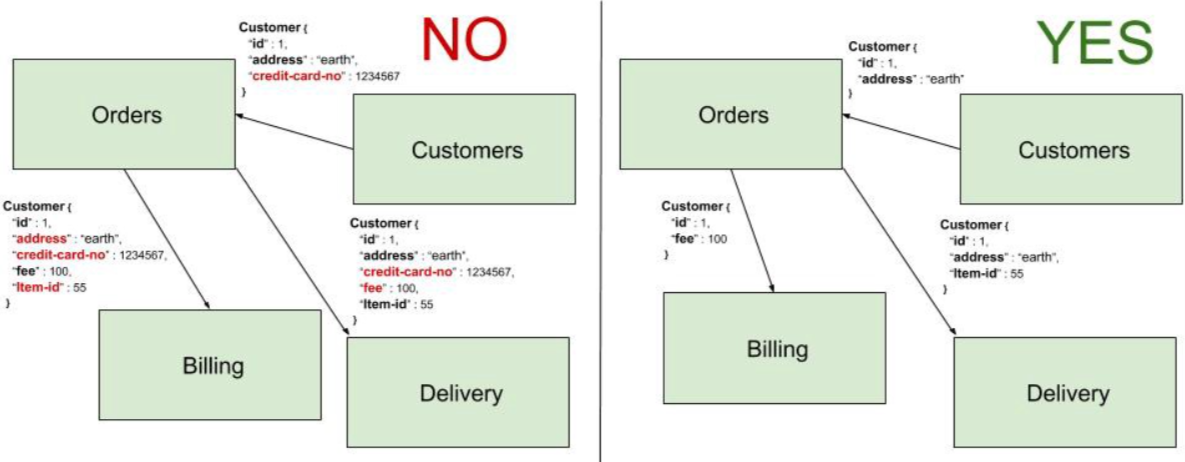
Fig. 5 — Domain coupling through excessive data sharing
總結
微服務是一個新的架構風格,如果沒有合理地採用,則有可能會降低其帶來的受益。為了避免過早地設計微服務網絡,如分佈一體式,你的系統一開始應該是個整體,然後逐步將其打散為合理的微服務。
當從一體式遷移到微服務架構時,可能有很多方式導致設計上的失誤,其中缺少松耦合是必須要注意的一點。耦合可能以多種形式出現:實現上的,臨時的,部署的以及領域上的耦合。本文中給出了每種類型的耦合的例子,以及一些建議方案來幫助避免對應的耦合場景。如果你的服務已經是分佈一體式的,不用擔心,遵循本文中討論的一些技術來採取糾正措施永遠不會太晚。
引用
- Sam Newman (2020), Monolith to Microservices. O』REILLY.
- Martin Fowler, How to break a Monolith into Microservices.


