ElasticSearch DSL 查詢
- 2021 年 2 月 23 日
- 筆記
- ElasticSearch 筆記
公號:碼農充電站pro
主頁://codeshellme.github.io
DSL(Domain Specific Language)查詢也叫做 Request Body 查詢,它比 URI 查詢更高階,能支持更複雜的查詢。
1,分頁
默認情況下,查詢按照算分排序,返回前 10 條記錄。
ES 也支持分頁,分頁使用 from-size:
- from:從第幾個文檔開始返回,默認為 0。
- size:返回的文檔數,默認為 10。
示例:
POST /index_name/_search
{
"from":10,
"size":20,
"query":{
"match_all": {}
}
}
1.1,深度分頁問題
ES 是一個分佈式系統,數據保存在多個分片中,那麼查詢時就需要查詢多個分片。
比如一個查詢 from = 990; size = 10,那麼 ES 需要在每個分片上都獲取 1000 個文檔:
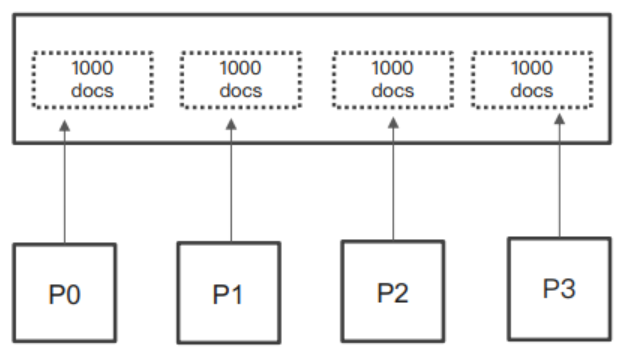
然後通過 Coordinating 節點匯總結果,最後再通過排序獲取前 1000 個文檔。
這種方式,當頁數很深的時候,就會佔用很多內存,從而給 ES 集群帶來很大的開銷,這就是深度分頁問題。
因此,ES 為了避免此類問題帶來的巨大開銷,有個默認的限制 index.max_result_window,from + size 必須小於等於 10000,否則就會報錯。
比如:
POST index_name/_search
{
"from": 10000, # 報錯
"size": 1,
"query": {
"match_all": {}
}
}
POST index_name/_search
{
"from": 0, # 報錯
"size": 10001,
"query": {
"match_all": {}
}
}
為了解決深度分頁問題,ES 有兩種解決方案:Search After 和 Scroll。
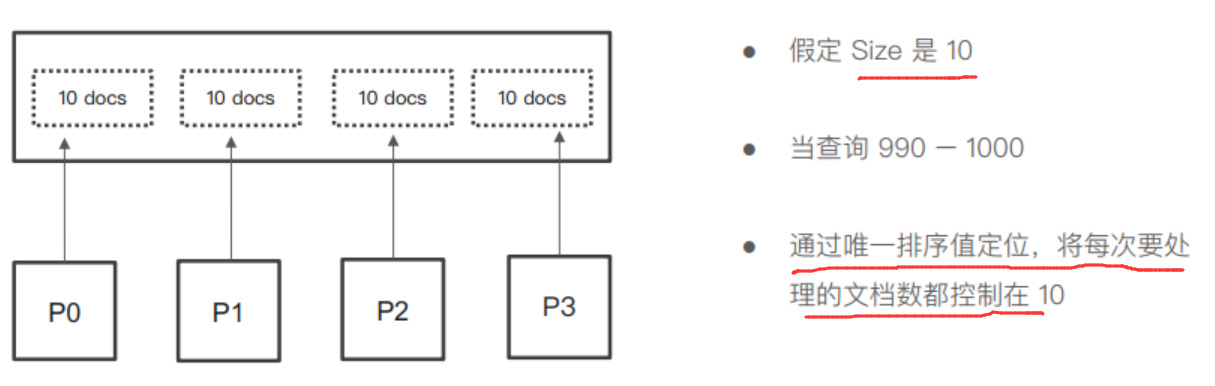
1.2,Search After
Search After 通過實時獲取下一頁的文檔信息來實現,使用方法:
- 第一步搜索需要指定 sort,並且保證值是唯一的(通過sort by id 來保證)。
- 隨後的搜索,都使用上一次搜索的最後一個文檔的 sort 值進行搜索。
Search After 的方式不支持指定頁數,只能一頁一頁的往下翻。
Search After 的原理:
示例:
# 插入一些數據
DELETE users
POST users/_doc
{"name":"user1","age":10}
POST users/_doc
{"name":"user2","age":11}
POST users/_doc
{"name":"user2","age":12}
POST users/_doc
{"name":"user2","age":13}
# 第一次搜索
POST users/_search
{
"size": 1, # size 值
"query": {
"match_all": {}
},
"sort": [
{"age": "desc"} ,
{"_id": "asc"} # sort by id
]
}
# 此時返回的文檔中有一個 sort 值
# "sort" : [13, "4dR-IHcB71-f4JZcrL2z"]
# 之後的每一次搜索都需要用到上一次搜索結果的最後一個文檔的 sort 值
POST users/_search
{
"size": 1,
"query": {
"match_all": {}
},
"search_after": [ # 上一次搜索結果的最後一個文檔的 sort 值放在這裡
13, "4dR-IHcB71-f4JZcrL2z"],
"sort": [
{"age": "desc"} ,
{"_id": "asc"}
]
}
1.3,Scroll
Scroll 通過創建一個快照來實現,方法:
- 每次查詢時,輸入上一次的
Scroll Id。
Scroll 方式的缺點是,當有新的數據寫入時,新寫入的數據無法被查到(第一次建立快照時有多少數據,就只能查到多少數據)。
示例:
# 寫入測試數據
DELETE users
POST users/_doc
{"name":"user1","age":10}
POST users/_doc
{"name":"user2","age":20}
# 第一次查詢前,先建立快照,快照存在時間為 5 分鐘,一般不要太長
POST /users/_search?scroll=5m
{
"size": 1,
"query": {
"match_all" : {}
}
}
# 返回的結果中會有一個 _scroll_id
# 查詢
POST /_search/scroll
{
"scroll" : "1m", # 快照的生存時間,這裡是 1 分鐘
"scroll_id" : "xxx==" # 上一次的 _scroll_id 值
}
# 每次的查詢結果都會返回一個 _scroll_id,供下一次查詢使用
# 所有的數據被查完以後,再查詢就得不到數據了
1.4,不同分頁方式的使用場景
分頁方式共 4 種:
- 普通查詢(不使用分頁):需要實時獲取頂部的部分文檔。
- From-Size(普通分頁):適用於非深度分頁。
- Search After:需要深度分頁時使用。
- Scroll:需要全部文檔,比如導出全部數據。
2,排序
ES 默認使用算分進行排序,我們可以使用 sort-processor(不需要再計算算分)來指定排序規則;可以對某個字段進行排序,最好只對數字型和日期型字段排序。
示例:
POST /index_name/_search
{
"sort":[{"order_date":"desc"}], # 單字段排序
"query":{
"match_all": {}
}
}
POST /index_name/_search
{
"query": {
"match_all": {}
},
"sort": [ # 多字段排序
{"order_date": {"order": "desc"}},
{"_doc":{"order": "asc"}},
{"_score":{ "order": "desc"}} # 如果不指定 _score,那麼算分為 null
]
}
對 text 類型的數據進行排序會發生錯誤,可以通過打開 fielddata 參數(一般不建議這麼做),來對 text 類型進行排序:
# 打開 text的 fielddata
PUT index_name/_mapping
{
"properties": {
"customer_full_name" : { # 字段名稱
"type" : "text",
"fielddata": true, # 打開 fielddata
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
3,字段過濾
可以使用 _source 設置需要返回哪些字段。示例:
POST /index_name/_search
{
"_source":["order_date", "xxxxx"],
"query":{
"match_all": {}
}
}
_source 中可以使用通配符,比如 ["name*", "abc*"]。
4,腳本字段
可以使用腳本進行簡單的表達式運算。
POST /index_name/_search
{
"script_fields": { # 固定寫法
"new_field": { # 新的字段名稱
"script": { # 固定寫法
"lang": "painless", # 固定寫法
"source": "doc['order_date'].value+'hello'" # 腳本語句
}
}
},
"query": {
"match_all": {}
}
}
5,查詢與過濾
查詢會有相關性算分;過濾不需要進行算分,可以利用緩存,性能更好。
參考這裡。
6,全文本查詢
全文本(Full text)查詢會對搜索字符串進行分詞處理。
全文本查詢有以下 9 種:
- intervals 查詢:可以對匹配項的順序和接近度進行細粒度控制。
- match 查詢:全文本查詢中的標準查詢,包括模糊匹配、短語和近似查詢。
- match_bool_prefix 查詢:
- match_phrase 查詢:
- match_phrase_prefix 查詢:
- multi_match 查詢:
- common terms 查詢:
- query_string 查詢:
- simple_query_string 查詢:
6.1,Match 查詢
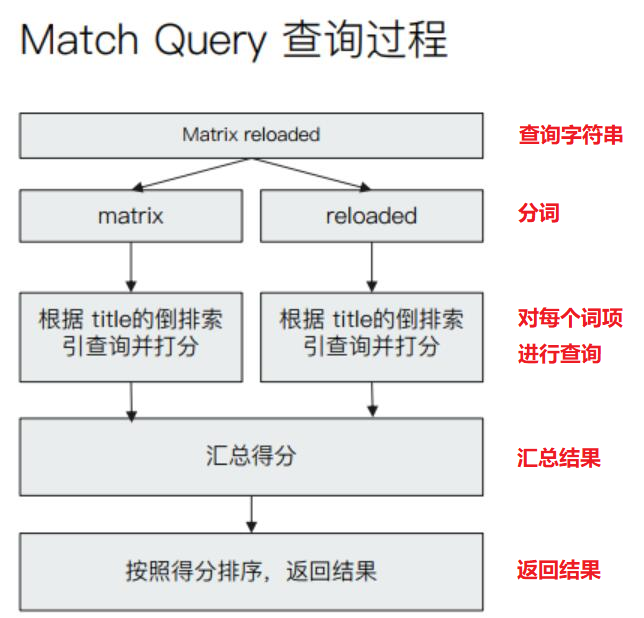
Match 查詢是全文搜索的標準查詢,與下面的幾種查詢相比,更加強大,靈活性也更大,最常使用。
Match 查詢會先對輸入字符串進行分詞,然後對每個詞項進行底層查詢,最後將結果合併。
例如對字符串 “Matrix reloaded” 進行查詢,會查到包含 “Matrix” 或者 “reloaded” 的所有結果。
示例:
POST index_name/_search
{
"query": {
"match": {
"title": "last christmas" # 表示包含 last 或 christmas
}
}
}
POST index_name/_search
{
"query": {
"match": {
"title": { # 表示包含 last 且 包含 christmas,不一定挨着
"query": "last christmas",
"operator": "and"
}
}
}
}
6.2,Match Phrase 查詢
使用 match_phrase 關鍵字。示例:
POST index_name/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love" # "one love" 相當於一個單詞
}
}
}
}
POST index_name/_search
{
"query": {
"match_phrase": {
"title":{
"query": "one love",
"slop": 1 # "one" 和 "love" 之間可以有 1 個字符
}
}
}
}
6.3,Query String 查詢
使用 query_string 關鍵字。示例:
POST index_name/_search
{
"query": {
"query_string": {
"default_field": "name", # 默認查詢字段,相當於 URI 查詢中的 df
"query": "Ruan AND Yiming" # 可以使用邏輯運算符
}
}
}
# 多 fields 與 分組
POST index_name/_search
{
"query": {
"query_string": {
"fields":["name","about"], # 多個 fields
"query": "(Ruan AND Yiming) OR (Java AND Elasticsearch)" # 支持分組
}
}
}
POST index_name/_search
{
"query":{
"query_string":{
"fields":["title","year"],
"query": "2012"
}
}
}
6.4,Simple Query String 查詢
使用 simple_query_string 關鍵字。
特點:
- query 字段中不支持
AND OR NOT,會當成普通字符串。AND用+替代OR用|替代NOT用-替代
- Term 之間默認的關係是
OR,可以指定default_operator來修改。
示例:
# Simple Query 默認的 operator 是 OR
POST index_name/_search
{
"query": {
"simple_query_string": {
"query": "Ruan AND Yiming", # 這裡的 AND 會當成普通的字符串
"fields": ["name"]
}
}
}
POST index_name/_search
{
"query": {
"simple_query_string": {
"query": "Ruan Yiming",
"fields": ["name"],
"default_operator": "AND"
}
}
}
GET index_name/_search
{
"query":{
"simple_query_string":{
"query":"Beautiful +mind",
"fields":["title"]
}
}
}
6.5,Multi-match 查詢
一個字符串在多個字段中查詢的情況,如何匹配最終的結果。(還有一個 dis-max 查詢也是針對這種情況的)
一個字符串在多個字段中查詢的情況,Multi-match 有 6 種處理方式,如下:
- best_fields:最終得分為分數最高的那個字段,默認的處理方式。
- most_fields:算分相加。不支持 AND 操作。
- cross_fields:跨字段搜索,將一個查詢字符串在多個字段(就像一個字段)上搜索。
- phrase:
- phrase_prefix:
- bool_prefix:
示例:
POST index_name/_search
{
"query": {
"multi_match" : { # multi_match 查詢
"query": "brown fox", # 查詢字符串
"type": "best_fields", # 處理方式
"fields": [ "subject", "message" ], # 在多個字段中查詢,fields 是一個數組
"tie_breaker": 0.3
}
}
}
7,Term 查詢
Term 查詢與全文本查詢不同的是,Term 查詢不會對查詢字符串進行分詞處理,Term 查詢會在字段匹配精確值。
Term 查詢輸入字符串作為一個整體,在倒排索引中查找匹配的詞項,並且會計算相關性評分。
Term 查詢包括以下 11 種:
- exists 查詢
- fuzzy 查詢
- ids 查詢
- prefix 查詢
- range 查詢
- regexp 查詢
- term 查詢:如果某個文檔的指定字段包含某個確切值,則返回該文檔。
- terms 查詢
- terms_set 查詢
- type 查詢
- wildcard 查詢
7.0,結構化數據與查詢
結構化查詢是對結構化數據的查詢,可以使用 Term 語句進行查詢。
結構化數據有着固定的格式,包括:
- 日期:日期比較,日期範圍運算等。
- 布爾值:邏輯運算。
- 數字:數字大小比較,範圍比較等。
- 某些文本數據:比如標籤數據,關鍵詞等。
結構化查詢是對結構化數據的邏輯運算,運算結果只有「是」和「否」。
7.1,term 查詢
如果某個文檔的指定字段包含某個確切值,則返回該文檔。
1,示例 1 精確匹配
下面舉一個 term 查詢的例子,首先插入一個文檔:
POST /products/_bulk
{ "index": { "_id": 1 }}
{ "productID" : "XHDK-A-1293-#fJ3","desc":"iPhone" }
該文檔插入時,會使用默認的分詞器進行分詞處理。
使用 term 查詢:
POST /products/_search
{
"query": {
"term": {
"desc": {
# "value": "iPhone" # 會對 iPhone 精確匹配查詢。
# 文檔插入時,iPhone 變成了 iphone
# 所以查 iPhone 查不到任何內容
"value":"iphone" # 查 iphone 能查到
}
}
}
}
keyword 子字段
ES 默認會對 text 類型的數據建立一個 keyword 子字段,用於精確匹配,這稱為 ES 的多字段屬性。
keyword 子字段將原始數據原封不動的存儲了下來。
可以通過 mapping 查看,如下所示:
"desc" : { # 字段名稱
"type" : "text", # text 數據類型
"fields" : {
"keyword" : { # keyword 子字段
"type" : "keyword", # keyword 子類型
"ignore_above" : 256
}
}
}
下面使用 keyword 子字段進行查詢:
POST /products/_search
{
"query": {
"term": {
"desc.keyword": { # 在 desc 字段的 keyword 子字段中查詢
"value": "iPhone" # 能查到
//"value":"iphone" # 查不到
}
}
}
}
2,示例 2 查詢布爾值
term 查詢有算分:
POST index_name/_search
{
"query": { # 固定寫法
"term": { # term 查詢,固定寫法
"avaliable": true # 查詢 avaliable 字段的值為 true 的文檔
}
}
}
如果不需要算分,可以使用 constant_score 查詢,示例:
POST index_name/_search
{
"query": {
"constant_score": { # constant_score 查詢,固定寫法
"filter": { # 固定寫法
"term": { # constant_score 包裝一個 term 查詢,就沒有了算分
"avaliable": true
}
}
}
}
}
7.2,range 查詢
range 查詢中有幾個常用的比較運算:
| 運算符 | 含義 |
|---|---|
| gt | 大於 |
| gte | 大於等於 |
| lt | 小於 |
| lte | 小於等於 |
1,數字類型 range 查詢
示例:
POST index_name/_search
{
"query": { # 固定寫法
"range": { # range 查詢
"age": { # 字段名稱
"gte": 10, # 10 <= age <= 20
"lte": 20
}
}
}
}
2,日期類型 range 查詢
對於日期類型有幾個常用的符號:
| 符號 | 含義 |
|---|---|
| y | 年 |
| M | 月 |
| w | 周 |
| d | 天 |
| H / h | 小時 |
| m | 分鐘 |
| s | 秒 |
| now | 現在 |
示例:
POST index_name/_search
{
"query" : { # 固定寫法
"range" : { # range 查詢
"date" : { # 字段名稱
"gte" : "now-10y" # 10年之前
}
}
}
}
7.3,exists 查詢
exists 語句可以判斷文檔是否存在某個字段。
搜索存在某個字段的文檔,示例:
POST index_name/_search
{
"query" : {
"exists": { # 存在 date 字段的文檔
"field": "date"
}
}
}
搜索不存在某個字段的文檔,需要使用布爾查詢。
示例:
POST index_name/_search
{
"query": {
"bool": { # 布爾查詢
"must_not": { # 不存在
"exists": { # 不存在 date 字段的文檔
"field": "date"
}
}
}
}
}
7.4,terms 查詢
terms 語句用於處理多值查詢,相當於一個多值版的 term 語句,可以一次查詢多個值。
示例:
POST index_name/_search
{
"query": {
"terms": { # terms 查詢
"productID.keyword": [ # 字段名稱
"QQPX-R-3956-#aD8", # 多個值
"JODL-X-1937-#pV7"
]
}
}
}
8,複合查詢
複合查詢(Compound)能夠包裝其他複合查詢或葉查詢,以組合其結果和分數,更改其行為或者將查詢轉成過濾。
複合查詢有以下 5 種:
8.1,bool 查詢
bool 查詢是一個或多個子查詢的組合,共包含以下 4 種子句:
- must:必須匹配,屬於查詢,貢獻算分。
- filter:必須匹配,屬於過濾器,不貢獻算分。
- should:選擇性匹配,只要有一個條件匹配即可,屬於查詢,貢獻算分。
- must_not:必須不匹配,屬於過濾器,不貢獻算分。
bool 查詢的多個子句之間沒有順序之分,並且可以嵌套。
示例:
POST index_name/_search
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [ # 是一個數組
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
8.2,boosting 查詢
boosting 查詢會給不同的查詢條件分配不同的級別(positive / negative),不同的級別對算分有着不同的印象,從而影響最終的算分。
positive 級別會對算分有正面影響, negative 級別會對算分有負面影響。
我們可以使用 boosting 查詢給某些文檔降級(降低算分),而不是將其從搜索結果中排除。
示例:
GET index_name/_search
{
"query": {
"boosting": { # boosting 查詢
"positive": { # positive 級別
"term": { # 匹配 apple 的會對算分有正面影響
"text": "apple"
}
},
"negative": { # negative 級別
"term": { # 匹配這個的會對算分有負面影響
"text": "pie tart fruit crumble tree"
}
},
"negative_boost": 0.5 # 降級的力度
}
}
}
8.3,constant_score 查詢
constant_score 查詢可以將查詢轉成一個過濾,可以避免算分(降低開銷),並有效利用緩存(提高性能)。
示例:
POST /index_name/_search
{
"query": {
"constant_score": { # constant_score 查詢
"filter": { # 過濾器,固定寫法
"term": { # 包裝了一個 term 查詢,將 term 查詢轉成了過濾
"productID.keyword": "XHDK-A-1293-#fJ3"
}
}
}
}
}
8.4,dis_max 查詢
一個字符串在多個字段中查詢的情況,如何匹配最終的結果。(還有一個 Multi-match 查詢也是針對這種情況的)
示例:
POST index_name/_search
{
"query": {
"bool": {
"should": [ # should 語句會綜合所有的字段的分數,最終給出一個綜合分數
{ "match": { "title": "Brown fox" }},
{ "match": { "body": "Brown fox" }}
]
}
}
}
POST index_name/_search
{
"query": {
"dis_max": { # dis_max 語句不會綜合所有字段的分數,而把每個字段單獨來看
"queries": [ # 最終結果是所有的字段中分數最高的
{ "match": { "title": "Quick pets" }},
{ "match": { "body": "Quick pets" }}
]
}
}
}
8.5,function_score 查詢
function_score 查詢可以在查詢結束後,對每一個匹配的文檔進行重新算分,然後再根據新的算分進行排序。
它提供了以下 5 種算分函數:
- script_score:自定義腳本。
- weight:為文檔設置一個權重。
- random_score:隨機算分排序。
- field_value_factor:使用該數值來修改算分。
- decay functions: gauss, linear, exp:以某個字段為標準,距離某個值越近,得分越高。
1,field_value_factor 示例
首先插入測試數據:
DELETE blogs
PUT /blogs/_doc/1
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 0
}
PUT /blogs/_doc/2
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 100
}
PUT /blogs/_doc/3
{
"title": "About popularity",
"content": "In this post we will talk about...",
"votes": 1000000
}
查詢示例1:
新的算分 = 老的算分 * 投票數
POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": { # 該查詢會有一個算分
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": { # 最終的算分要乘以 votes 字段的值
"field": "votes"
}
}
}
}
上面這種算法當出現這兩種情況的時候,會出現問題:
- 投票數為 0
- 投票數特別大
查詢示例2,引入平滑函數:
新的算分 = 老的算分 * 平滑函數(投票數)
POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" # 在原來的基礎上加了一個平滑函數
} # 新的算分 = 老的算分 * log(1 + 投票數)
}
}
}
平滑函數有下面這些:

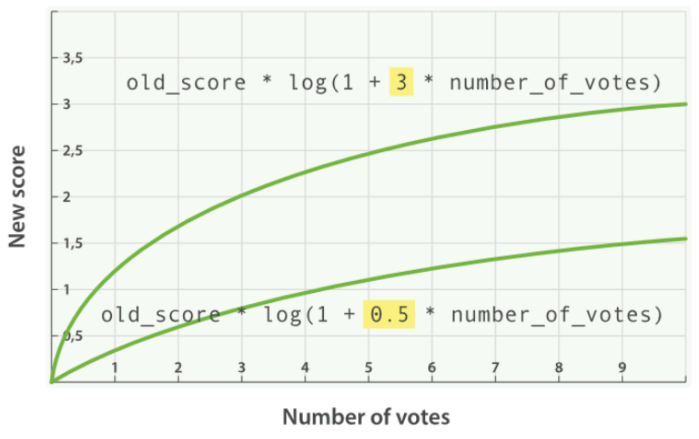
查詢示例3,引入 factor :
新的算分 = 老的算分 * 平滑函數(factor * 投票數)
POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" ,
"factor": 0.1
}
}
}
}
引入 factor 之後的算分曲線:
2,Boost Mode 和 Max Boost 參數
Boost Mode:
- Multiply:算分與函數值的乘積。
- Sum:算分與函數值的和。
- Min / Max:算分與函數值的最小/最大值。
- Replace:使用函數值替代算分。
Max Boost 可以將算分控制在一個最大值。
示例:
POST /blogs/_search
{
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "popularity",
"fields": [ "title", "content" ]
}
},
"field_value_factor": {
"field": "votes",
"modifier": "log1p" ,
"factor": 0.1
},
"boost_mode": "sum",
"max_boost": 3
}
}
}
3,random_score 示例
示例:
POST /blogs/_search
{
"query": {
"function_score": {
"random_score": { # 將原來的查詢結果隨機排序
"seed": 911119 # 隨機種子
}
}
}
}
(本節完。)
推薦閱讀:
歡迎關注作者公眾號,獲取更多技術乾貨。



