ElasticSearch 文檔及操作
- 2021 年 2 月 22 日
- 筆記
- ElasticSearch 筆記
公號:碼農充電站pro
主頁://codeshellme.github.io
本節介紹 ES 文檔,索引及其基本操作。
1,ES 中的文檔
在 ES 中,文檔(Document)是可搜索數據的最小存儲單位,相當於關係數據庫中的一條記錄。
文檔以 Json 數據格式保存在 ES 中,Json 中保存着多個鍵值對,它可以保存不同類型的數據,比如:
- 字符串類型
- 數字類型
- 布爾類型
- 數組類型
- 日期類型
- 二進制類型
- 範圍類型
Python 語言中的字典類型,就是 Json 數據格式。
文檔中的數據類型可以指定,也可以由 ES 自動推斷。
每個文檔中都有一個 Unique ID,用於唯一標識一個文檔。Unique ID 可以由用戶指定,也可以由 ES 自動生成。
Unique ID 實際上是一個字符串。
比如下面的 Json 就是一個文檔:
{
"name" : "XiaoMing",
"age" : 19,
"gender" : "male"
}
1.1,文檔元數據
將上面那個 Json 數據存儲到 ES 後,會像下面這樣:
{
"_index": "person",
"_type": "_doc",
"_id": "2344563",
"_version": 1,
"_source": {
"name": "XiaoMing",
"age": 19,
"gender": "male"
}
}
其中以下劃線開頭的字段就是元數據:
_index:文檔所屬的索引。_type:文檔的類型。ES 7.0 開始,一個索引只能有一種_type。_id:文檔的唯一 ID。_source:文檔的原始 Json 數據。_version:文檔更新的次數。
你可以查看這裡,了解「為什麼單個Index下,不再支持多個Tyeps?」。
更多關於元數據的信息,可以參考這裡。
1.2,文檔的刪除與更新
ES 中文檔的刪除操作不會馬上將其刪除,而是會將其標記到 del 文件中,在後期合適的時候(比如 Merge 階段)會真正的刪除。
ES 中的文檔是不可變更的,更新操作會將舊的文檔標記為刪除,同時增加一個新的字段,並且文檔的 version 加 1。
1.3,文檔中的字段數
在 ES 中,一個文檔默認最多可以有 1000 個字段,可以通過 index.mapping.total_fields.limit 進行設置。
注意在設計 ES 中的數據結構時,不要使文檔的字段數過多,這樣會使得 mapping 很大,增加集群的負擔。
2,ES 中的索引
ES 中的文檔都會存儲在某個索引(Index)中,索引是文檔的容器,是一類文檔的集合,相當於關係型數據庫中的表的概念。
ES 中可以創建很多不同的索引,表示不同的文檔集合。
每個索引都可以定義自己的 Mappings 和 Settings:
Mappings:用於設置文檔字段的類型。Settings:用於設置不同的數據分佈。
對於索引的一些參數設置,有些參數可以動態修改,有些參數在索引創建後不能修改,可參考這裡。
ES 與傳統數據庫類比
如果將 ES 中的基本概念類比到傳統數據庫中,它們的對應關係如下:
| ES | 傳統數據庫 |
|---|---|
| 索引 | 表 |
| 文檔 | 行 |
| 字段 | 列 |
| Mapping | 表定義 |
| DSL | SQL 語句 |
索引相關 API
下面給出一些查看索引相關信息的 API:
# 查看索引相關信息
GET index_name
# 查看索引的文檔總數
GET index_name/_count
# 查看指定索引的前10條文檔
POST index_name/_search
{
}
#_cat indices API
# 查看所有的索引名以 index_prefix 為前綴的索引
GET /_cat/indices/index_prefix*?v&s=index
# 查看狀態為 green 的索引
GET /_cat/indices?v&health=green
# 按照文檔個數排序
GET /_cat/indices?v&s=docs.count:desc
# 查看指定索引的指定信息
GET /_cat/indices/index_prefix*?pri&v&h=health,index,pri,rep,docs.count,mt
# 查看索引使用的內存大小
GET /_cat/indices?v&h=i,tm&s=tm:desc
3,GET 操作
GET 操作可以獲取指定文檔的內容。
GET index_name/_count:獲取指定索引中的文檔數。
GET index_name/_doc/id:獲取指定索引中的指定文檔。
GET index_name/_doc:不允許該操作。
GET index_name:獲取指定索引的 Mappings 和 Settings。
4,POST / PUT 操作
POST/PUT 操作用於創建文檔。
按照 POST / PUT 方法來區分
POST index_name/_doc:
POST index_name/_doc:不指定 ID,總是會插入新的文檔,文檔數加 1。POST/PUT index_name/_doc/id:指定 ID- 當 id 存在時,會覆蓋之前的,並且 version 會加 1,文檔數不增加。
- 當 id 不存在時,會插入新的文檔,文檔數加 1。
PUT index_name/_create:
PUT index_name/_create:不指定 ID,不允許該操作。PUT index_name/_create/id:指定 ID- 當 id 存在時:報錯,不會插入新文檔。
- 當 id 不存在時:,會插入新的文檔,文檔數加 1。
PUT index_name/_doc:
PUT index_name/_doc:不指定 ID,不允許該操作。PUT/POST index_name/_doc/id:指定 ID- 當 id 存在時,會覆蓋之前的,並且 version 會加 1,文檔數不增加。
- 當 id 不存在時,會插入新的文檔,文檔數加 1。
PUT index_name/_doc/id?op_type=XXX
op_type=create:- 當 id 存在時,報錯,不會插入新文檔。
- 當 id 不存在時,會插入新的文檔,文檔數加 1。
op_type=index:- 當 id 存在時,會覆蓋之前的,並且 version 會加 1,文檔數不增加。
- 當 id 不存在時,會插入新的文檔,文檔數加 1。
按照是否指定 ID 來區分
指定 ID:
POST/PUT index_name/_doc/id:指定 ID,稱為 Index 操作- 相當於
PUT index_name/_doc/id?op_type=index - 當 id 存在時,會覆蓋之前的,並且 version 會加 1,文檔數不增加。
- 當 id 不存在時,會插入新的文檔,文檔數加 1。
- 相當於
PUT index_name/_doc/id?op_type=create:指定 ID,稱為 Create 操作- 相當於
PUT index_name/_create/id - 當 id 存在時,報錯,不會插入新文檔。
- 當 id 不存在時,會插入新的文檔,文檔數加 1。
- 相當於
不指定 ID:
POST index_name/_doc:不指定 ID,總是會插入新的文檔,文檔數加 1。PUT index_name/_doc:不指定 ID,不允許該操作。PUT index_name/_create:不指定 ID,不允許該操作。
5,Update 操作
Update 操作用於更新文檔的內容。
POST index_name/_update/id/:更新指定文檔的內容。更新的內容要放在 doc 字段中,否則會報錯。
- 當 id 不存在時,報錯,不更新任何內容。
- 當 id 存在時:
- 如果更新的字段與原來的相同,則不做任何操作。
- 如果更新的字段與原來的不同,則更新原有內容,並且 version 會加 1。
實際上 ES 中的文檔是不可變更的,更新操作會將舊的文檔標記為刪除,同時增加一個新的字段,並且文檔的 version 加 1。
6,Delete 操作
Delete 操作用於刪除索引或文檔。
DELETE /index_name/_doc/id:刪除某個文檔。
- 當刪除的 id 存在時,會刪除該文檔。
- 當刪除的 id 不存在時,ES 會返回
not_found。
DELETE /index_name:刪除整個索引,要謹慎使用!
- 當刪除的 index_name 存在時,會刪除整個索引內容。
- 當刪除的 index_name 不存在時,ES 會返回
404錯誤。
7,Bulk 批量操作
批量操作指的是,在一次 API 調用中,對不同的索引進行多次操作。
每次操作互不影響,即使某個操作出錯,也不影響其他操作。
返回的結果中包含了所有操作的執行結果。
Bulk 支持的操作有 Index,Create,Update,Delete。
Bulk 操作的格式如下:
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test2", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }
注意 Bulk 請求體的數據量不宜過大,建議在 5~15M。
8,Mget 批量讀取
Mget 一次讀取多個文檔的內容,設計思想類似 Bulk 操作。
Mget 操作的格式如下:
GET _mget
{
"docs" : [
{"_index" : "index_name1", "_id" : "1"},
{"_index" : "index_name2", "_id" : "2"}
]
}
也可以在 URI 中指定索引名稱:
GET /index_name/_mget
{
"docs" : [
{"_id" : "1"},
{"_id" : "2"}
]
}
還可以用 _source 字段來設置返回的內容:
GET _mget
{
"docs" : [
{"_index" : "index_name1", "_id" : "1"},
{"_index" : "index_name2", "_id" : "2", "_source" : ["f1", "f2"]}
]
}
9,Msearch 批量查詢
Msearch 操作用於批量查詢,格式如下:
POST index_name1/_msearch
{} # 索引名稱,不寫的話就是 URI 中的索引
{"query" : {"match_all" : {}},"size":1}
{"index" : "index_name2"} # 改變了索引名稱
{"query" : {"match_all" : {}},"size":2}
URI 中也可以不寫索引名稱,此時請求體里必須寫索引名稱:
POST _msearch
{"index" : "index_name1"} # 索引名稱
{"query" : {"match_all" : {}},"size":1}
{"index" : "index_name2"} # 索引名稱
{"query" : {"match_all" : {}},"size":2}
上文中介紹了 3 種批量操作,分別是 Bulk,Mget,Msearch。注意在使用批量操作時,數據量不宜過大,避免出現性能問題。
10,ES 常見錯誤碼
當我們的請求發生錯誤的時候,ES 會返回相應的錯誤碼,常見的錯誤碼如下:
| 錯誤碼 | 含義 |
|---|---|
| 429 | 集群過於繁忙 |
| 4XX | 請求格式錯誤 |
| 500 | 集群內部錯誤 |
11,Reindex 重建索引
有時候我們需要重建索引,比如以下情況:
- 索引的
mappings發生改變:比如字段類型或者分詞器等發生更改。 - 索引的
settings發生改變:比如索引的主分片數發生更改。 - 集群內或集群間需要做數據遷移。
ES 中提供兩種重建 API:
- Update by query:在現有索引上重建索引。
- Reindex:在其它索引上重建索引。
11.1,添加子字段
先在一個索引中插入數據:
DELETE blogs/
# 寫入文檔
PUT blogs/_doc/1
{
"content":"Hadoop is cool",
"keyword":"hadoop"
}
# 查看自動生成的 Mapping
GET blogs/_mapping
# 查詢文檔
POST blogs/_search
{
"query": {
"match": {
"content": "Hadoop"
}
}
}
# 可以查到數據
現在修改 mapping(添加子字段是允許的),為 content 字段加入一個子字段:
# 修改 Mapping,增加子字段,使用英文分詞器
PUT blogs/_mapping
{
"properties" : {
"content" : { # content 字段
"type" : "text",
"fields" : { # 加入一個子字段
"english" : { # 子字段名稱
"type" : "text", # 子字段類型
"analyzer":"english" # 子字段分詞器
}
}
}
}
}
# 查看新的 Mapping
GET blogs/_mapping
修改 mapping 之後再查詢文檔:
# 使用 english 子字段查詢 Mapping 變更前寫入的文檔
# 查不到文檔
POST blogs/_search
{
"query": {
"match": {
"content.english": "Hadoop"
}
}
}
# 注意:不使用 english 子字段是可以查詢到之前的文檔的
POST blogs/_search
{
"query": {
"match": {
"content": "Hadoop"
}
}
}
結果發現,使用 english 子字段是查不到之前的文檔的。這時候就需要重建索引。
11.2,Update by query
下面使用 Update by query 對索引進行重建:
# Update所有文檔
POST blogs/_update_by_query
{
}
重建索引之後,不管是使用 english 子字段還是不使用,都可以查出文檔。
Update by query 操作還可以設置一些條件:
- uri-params
- request-body:通過設置一個 query 條件,來指定對哪些數據進行重建。
request-body 示例:
POST tech_blogs/_update_by_query?pipeline=blog_pipeline
{
"query": { # 將 query 的查詢結果進行重建
"bool": {
"must_not": {
"exists": {"field": "views"}
}
}
}
}
11.3,修改字段類型
在原有 mapping 上,修改字段類型是不允許的:
# 會發生錯誤
PUT blogs/_mapping
{
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"english" : {
"type" : "text",
"analyzer" : "english"
}
}
},
"keyword" : { # 修改 keyword 字段的類型
"type" : "keyword"
}
}
}
這時候只能創建一個新的索引,設置正確的字段類型,然後再將原有索引中的數據,重建到新索引中。
建立一個新的索引 blogs_new:
# 創建新的索引並且設定新的Mapping
PUT blogs_new/
{
"mappings": {
"properties" : {
"content" : {
"type" : "text",
"fields" : {
"english" : {
"type" : "text",
"analyzer" : "english"
}
}
},
"keyword" : {
"type" : "keyword"
}
}
}
}
11.4,Reindex
下面使用 Reindex 將原來索引中的數據,導入到新的索引中:
# Reindx API
POST _reindex
{
"source": { # 指定原有索引
"index": "blogs"
},
"dest": { # 指定目標索引
"index": "blogs_new"
}
}
Reindex API 中的 source 字段和 dest 字段還有很多參數可以設置,具體可參考其官方文檔。
另外 Reindex 請求的 URI 中也可以設置參數,可以參考這裡。
12,ES 的並發控制
同一個資源在多並發處理的時候,會發生衝突的問題。
傳統數據庫(比如 MySQL)會採用鎖的方式,在更新數據的時候對數據進行加鎖,來防止衝突。
而 ES 並沒有採用鎖,而是將並發問題交給了用戶處理。
在 ES 中可以採用兩種方式:
- 內部版本控制(ES 自帶的 version):在 URI 中使用
if_seq_no和if_primary_term - 外部版本控制(由用戶指定 version):在 URI 中使用
version和version_type=external
示例,首先插入數據:
DELETE products
PUT products/_doc/1
{
"title":"iphone",
"count":100
}
# 上面的插入操作會返回 4 個字段:
#{
# "_id" : "1",
# "_version" : 1,
# "_seq_no" : 0,
# "_primary_term" : 1
#}
12.1,內部版本控制方式
使用內部版本控制的方式:
PUT products/_doc/1?if_seq_no=0&if_primary_term=1
{
"title":"iphone",
"count":100
}
# 上面的更新操作返回下面內容:
#{
# "_id" : "1",
# "_version" : 2, # 加 1
# "_seq_no" : 1, # 加 1
# "_primary_term" : 1 # 不變
#}
如果再次執行這句更新操作,則會出錯,出錯之後由用戶決定如何處理,這就達到了解決衝突的目的。
# 再執行則會出錯,因為 seq_no=0 且 primary_term=1 的數據已經不存在了
PUT products/_doc/1?if_seq_no=0&if_primary_term=1
12.2,外部版本控制方式
先看下數據庫中的數據:
GET products/_doc/1
# 返回:
{
"_index" : "products",
"_type" : "_doc",
"_id" : "1", # id
"_version" : 2, # version
"_seq_no" : 1,
"_primary_term" : 1,
"found" : true,
"_source" : {
"title" : "iphone",
"count" : 100
}
}
使用外部版本控制的方式:
# 如果 URI 中的 version 值與 ES 中的 version 值相等,則出錯
# 下面這句操作會出錯,出錯之後,由用戶決定如何處理
PUT products/_doc/1?version=2&version_type=external
{
"title":"iphone",
"count":1000
}
# 如果 URI 中的 version 值與 ES 中的 version 值不相等,則成功
# 下面這句操作會成功
PUT products/_doc/1?version=3&version_type=external
{
"title":"iphone",
"count":1000
}
13,使用 Ingest 節點對數據預處理
Ingest 節點用於對數據預處理,它是在 ES 5.0 後引入的一種節點類型,可以達到一定的 Logstash 的功能。
默認情況下,所有的節點都是 Ingest 節點。
Ingest 節點通過添加一些 processors 來完成特定的處理,Pipeline 可以看做是一組 processors 的順序執行。
Ingest 節點的處理階段如下圖所示:

13.0,Ingest 節點與 Logstash 對比
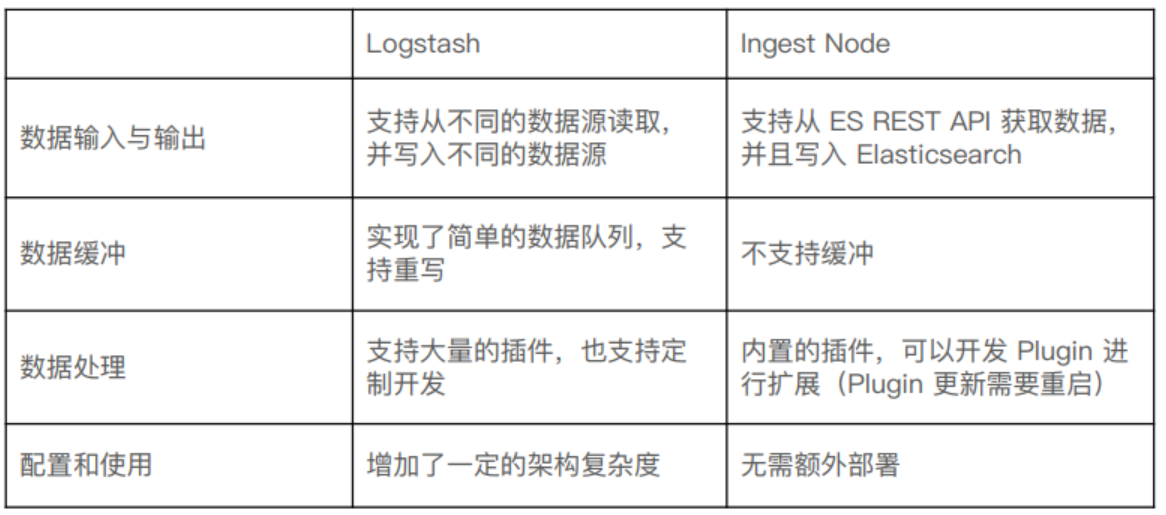
13.1,內置的 Processors
ES 中內置了很多現成的 Processors 供我們使用:
- Append:向一個數組類型的字段加入更多的值。
- Split:將字符串拆分成數組。
- Set:設置一個字段。
- Uppercase:大寫轉換。
- Lowercase:小寫轉換。
- Remove:移除一個已存在的字段。如果字段不存在,將拋出異常。
- Rename:為一個字段重命名。
- Convert:轉換一個字段的數據類型。比如將字符串類型轉換成整數類型。
- Date:日期格式轉換。
- JSON:將 json 字符串轉換成 JSON 類型。
- Date-index-name:將通過該處理器的文檔,分配到指定時間格式的索引中。
- Fail:當出現異常的時候,將指定的信息返回給用戶。
- Foreach:用於處理數組類型的數據。
- Pipeline:引用另一個 Pipeline。
- Trim:刪除字符換的前置和後置空格。
- Sort:對數組中的元素排序。
- Url-decode:對字符串進行 URL 解碼。
- User-agent:用於解析 User-Agent 信息。
- Html-strip:用於移除 HTML 標籤。
- Script:用 Painless 語言編寫腳本,以支持更複雜的功能。
- Painless 語言是專門為 ES 設計的,在 ES 5.x 引入,具有高性能和安全性。
- ES 6.0 開始,ES 只支持 Painless 腳本,不再支持其它語言腳本(比如 JavaScript,Python 等)。
- Painless 基於 Java 語言,並支持所有的 Java 數據類型。
- 等
13.2,測試 Processors
ES 中提供了一個 simulate 接口,用於測試 Processors。
示例:
POST _ingest/pipeline/_simulate
{
"pipeline": { # 定義 pipeline
"description": "to split blog tags", # 描述
"processors": [ # 一系列的 processors
{
"split": { # 一個 split processor
"field": "tags",
"separator": "," # 用逗號分隔
}
},
{
"set":{ # 可以設置多個 processor
"field": "views",
"value": 0
}
}
]
},
"docs": [ # 測試的文檔
{ # 第 1 個文檔
"_index": "index",
"_id": "id",
"_source": {
"title": "Introducing big data......",
"tags": "hadoop,elasticsearch,spark",
"content": "You konw, for big data"
}
},
{ # 第 2 個文檔
"_index": "index",
"_id": "idxx",
"_source": {
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
}
]
}
13.3,添加一個 Pipeline
當 Processors 測試通過後,可以向 ES 中添加(設置)一個 Pipeline,語法:
# blog_pipeline 為 pipeline 名稱
PUT _ingest/pipeline/blog_pipeline
{
"description": "a blog pipeline",
"processors": [
{
"split": { # 第 1個 Processor
"field": "tags",
"separator": ","
}
},
{
"set":{ # 第 2個 Processor
"field": "views",
"value": 0
}
}
]
}
13.4,查看 Pipeline
# 查看 Pipleline
GET _ingest/pipeline/blog_pipeline
# 刪除 Pipleline
DELETE _ingest/pipeline/blog_pipeline
13.5,測試 Pipeline
# blog_pipeline 是 Pipeline 名稱
POST _ingest/pipeline/blog_pipeline/_simulate
{
"docs": [
{ # 一個文檔
"_source": {
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
}
]
}
13.6,使用 Pipeline
使用 Pipeline 插入文檔時,文檔會先經過 Pipeline 的處理,然後再插入到 ES 中。
# URI 中指定了 Pipeline 的名字
PUT tech_blogs/_doc/2?pipeline=blog_pipeline
{
"title": "Introducing cloud computering",
"tags": "openstack,k8s",
"content": "You konw, for cloud"
}
最終插入的文檔是這樣的:
{
"title": "Introducing cloud computering",
"tags": ["openstack", "k8s"],
"content": "You konw, for cloud",
"views": 0
}
另外 update-by-query(重建索引)的 URI 中也可以設置 pipeline 參數來使用一個 Pipeline。
14,總結
上文介紹到的所有操作,可以參考 ES 的官方文檔。
(本節完。)
推薦閱讀:
Kibana,Logstash 和 Cerebro 的安裝運行
歡迎關注作者公眾號,獲取更多技術乾貨。


