kubernetes Service:讓客戶端發現pod並與之通信
- 2019 年 10 月 3 日
- 筆記
5.1.Service介紹
5.1.1.Serice簡介
5.1.1.1什麼是Service
service是k8s中的一個重要概念,主要是提供負載均衡和服務自動發現。
Service 是由 kube-proxy 組件,加上 iptables 來共同實現的。
5.1.1.2.Service的創建
創建Service的方法有兩種:
1.通過kubectl expose創建
#kubectl expose deployment nginx --port=88 --type=NodePort --target-port=80 --name=nginx-service 這一步說是將服務暴露出去,實際上是在服務前面加一個負載均衡,因為pod可能分佈在不同的結點上。 –port:暴露出去的端口 –type=NodePort:使用結點+端口方式訪問服務 –target-port:容器的端口 –name:創建service指定的名稱
2.通過yaml文件創建
創建一個名為hostnames-yaohong的服務,將在端口80接收請求並將鏈接路由到具有標籤選擇器是app=hostnames的pod的9376端口上。
使用kubectl creat來創建serivice
apiVersion: v1 kind: Service metadata: name: hostnames-yaohong spec: selector: app: hostnames ports: - name: default protocol: TCP port: 80 //該服務的可用端口 targetPort: 9376 //具有app=hostnames標籤的pod都屬於該服務
5.1.1.3.檢測服務
使用如下命令來檢查服務:
$ kubectl get svc NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kubernetes ClusterIP 10.187.0.1 <none> 443/TCP 18d
5.1.1.4.在運行的容器中遠程執行命令
使用kubectl exec 命令來遠程執行容器中命令
$ kubectl -n kube-system exec coredns-7b8dbb87dd-pb9hk -- ls / bin coredns dev etc home lib media mnt proc root run sbin srv sys tmp usr var
雙橫杠(--)代表kubectl命令項的結束,在雙橫杠後面的內容是指pod內部需要執行的命令。
5.2.連接集群外部的服務
5.2.1.介紹服務endpoint
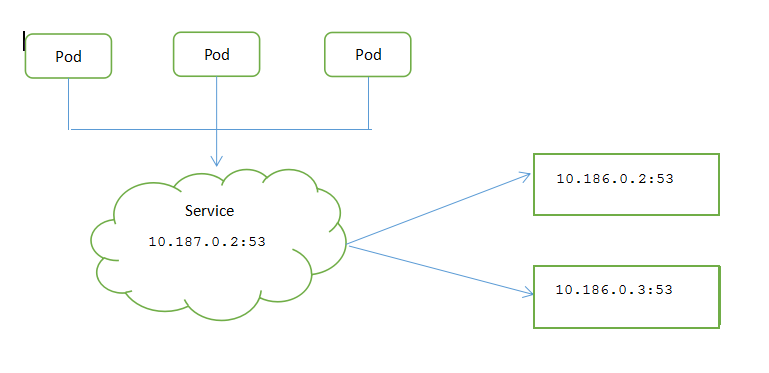
服務並不是和pod直接相連的,介於他們之間的就是Endpoint資源。
Endpoint資源就是暴露一個服務的IP地址和端口列表。
通過service查看endpoint方法如下:
$ kubectl -n kube-system get svc kube-dns NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE kube-dns ClusterI P 10.187.0.2 <none> 53/UDP,53/TCP 19d $ kubectl -n kube-system describe svc kube-dns Name: kube-dns Namespace: kube-system Labels: addonmanager.kubernetes.io/mode=Reconcile k8s-app=kube-dns kubernetes.io/cluster-service=true kubernetes.io/name=CoreDNS Annotations: kubectl.kubernetes.io/last-applied-configuration: {"apiVersion":"v1","kind":"Service","metadata":{"annotations":{"prometheus.io/scrape":"true"},"labels":{"addonmanager.kubernetes.io/mode":... prometheus.io/scrape: true Selector: k8s-app=kube-dns Type: ClusterIP IP: 10.187.0.2 Port: dns 53/UDP TargetPort: 53/UDP Endpoints: 10.186.0.2:53,10.186.0.3:53 //代表服務endpoint的pod的ip和端口列表 Port: dns-tcp 53/TCP TargetPort: 53/TCP Endpoints: 10.186.0.2:53,10.186.0.3:53 Session Affinity: None Events: <none>
直接查看endpoint信息方法如下:
#kubectl -n kube-system get endpoints kube-dns NAME ENDPOINTS AGE kube-dns 10.186.0.2:53,10.186.0.3:53,10.186.0.2:53 + 1 more... 19d #kubectl -n kube-system describe endpoints kube-dns Name: kube-dns Namespace: kube-system Labels: addonmanager.kubernetes.io/mode=Reconcile k8s-app=kube-dns kubernetes.io/cluster-service=true kubernetes.io/name=CoreDNS Annotations: <none> Subsets: Addresses: 10.186.0.2,10.186.0.3 NotReadyAddresses: <none> Ports: Name Port Protocol ---- ---- -------- dns 53 UDP dns-tcp 53 TCP Events: <none>
5.2.2.手動配置服務的endpoint
如果創建pod時不包含選擇器,則k8s將不會創建endpoint資源。這樣就需要創建endpoint來指的服務的對應的endpoint列表。
service中創建endpoint資源,其中一個作用就是用於service知道包含哪些pod。
5.2.3.為外部服務創建別名
除了手動配置來訪問外部服務外,還可以使用完全限定域名(FQDN)訪問外部服務。
apiVersion: v1 kind: Service metadata: name: Service-yaohong spec: type: ExternalName //代碼的type被設置成了ExternalName
externalName: someapi.somecompany.com // 實際服務的完全限定域名(FQDN)
port: - port: 80
服務創建完成後,pod可以通過external-service.default.svc.cluster.local域名(甚至是external-service)連接外部服務。
5.3.將服務暴露給外部客戶端
有3種方式在外部訪問服務:
1.將服務的類型設置成NodePort;
2.將服務的類型設置成LoadBalance;
3.創建一個Ingress資源。
5.3.1.使用nodeport類型的服務
NodePort 服務是引導外部流量到你的服務的最原始方式。NodePort,正如這個名字所示,在所有節點(虛擬機)上開放一個特定端口,任何發送到該端口的流量都被轉發到對應服務。
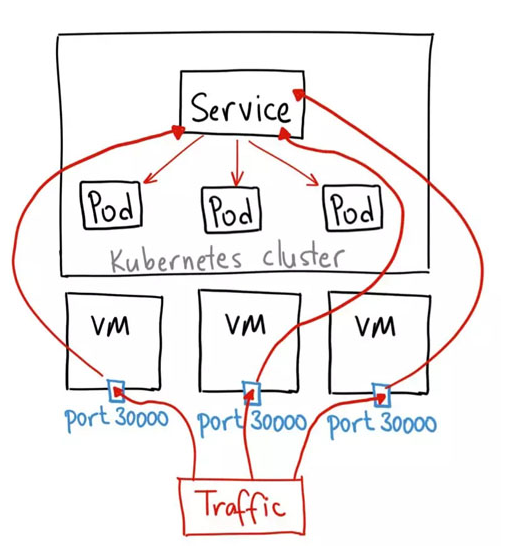
YAML 文件類似如下:
apiVersion: v1 kind: Service metadata: name: Service-yaohong spec: type: NodePort //為NodePort設置服務類型 ports: - port: 80 targetPort: 8080 nodeport: 30123 //通過集群節點的30123端口可以訪問服務 selector: app: yh
這種方法有許多缺點:
1.每個端口只能是一種服務
2.端口範圍只能是 30000-32767
如果節點/VM 的 IP 地址發生變化,你需要能處理這種情況
基於以上原因,我不建議在生產環境上用這種方式暴露服務。如果你運行的服務不要求一直可用,或者對成本比較敏感,你可以使用這種方法。這樣的應用的最佳例子是 demo 應用,或者某些臨時應用。
5.3.2.通過Loadbalance將服務暴露出來
LoadBalancer 服務是暴露服務到 internet 的標準方式。在 GKE 上,這種方式會啟動一個 Network Load Balancer[2],它將給你一個單獨的 IP 地址,轉發所有流量到你的服務。
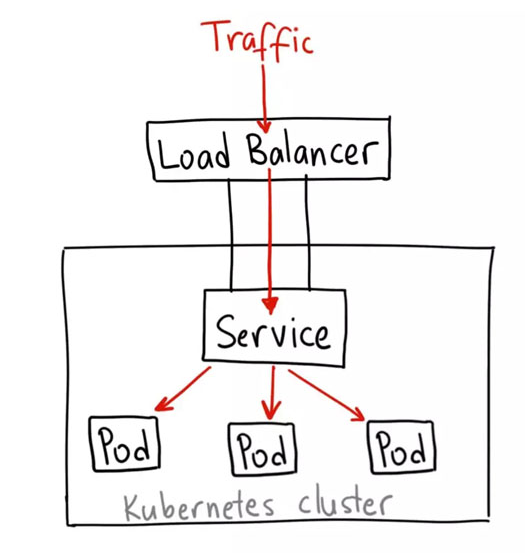
通過如下方法來定義服務使用負載均衡
apiVersion: v1 kind: Service metadata: name: loadBalancer-yaohong spec: type: LoadBalancer //該服務從k8s集群的基礎架構獲取負載均衡器 ports: - port: 80 targetPort: 8080 selector: app: yh
何時使用這種方式?
如果你想要直接暴露服務,這就是默認方式。所有通往你指定的端口的流量都會被轉發到對應的服務。它沒有過濾條件,沒有路由等。這意味着你幾乎可以發送任何種類的流量到該服務,像 HTTP,TCP,UDP,Websocket,gRPC 或其它任意種類。
這個方式的最大缺點是每一個用 LoadBalancer 暴露的服務都會有它自己的 IP 地址,每個用到的 LoadBalancer 都需要付費,這將是非常昂貴的。
5.4.通過Ingress暴露服務
為什麼使用Ingress,一個重要的原因是LoadBalancer服務都需要創建自己的負載均衡器,以及獨有的公有Ip地址,而Ingress只需要一個公網Ip就能為許多服務提供訪問。
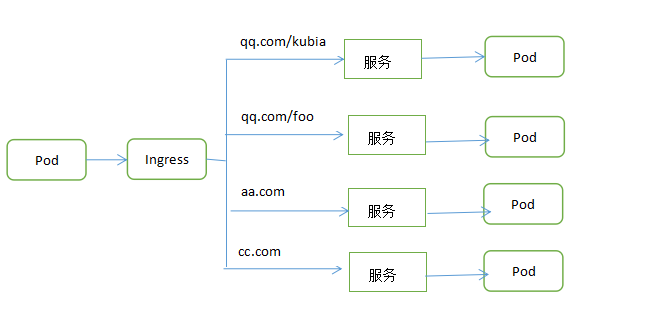
5.4.1.創建Ingress資源
Ingress 事實上不是一種服務類型。相反,它處於多個服務的前端,扮演着“智能路由”或者集群入口的角色。
你可以用 Ingress 來做許多不同的事情,各種不同類型的 Ingress 控制器也有不同的能力。

編寫如下ingress.yml文件
kind: Ingress metadata: name: ingressyaohong spec: rules: - host: kubia.example.com http: paths: - path: / backend: serviceName: kubia-nodeport servicePort: 80
通過如下命令進行查看ingress
# kubectl create -f ingress.yml
5.4.2.通過Ingress訪問服務
通過kubectl get ing命令進行查看ingress
# kubectl get ing NAME HOSTS ADDRESS PORTS AGE ingressyaohong kubia.example.com 80 2m
了解Ingress的工作原理
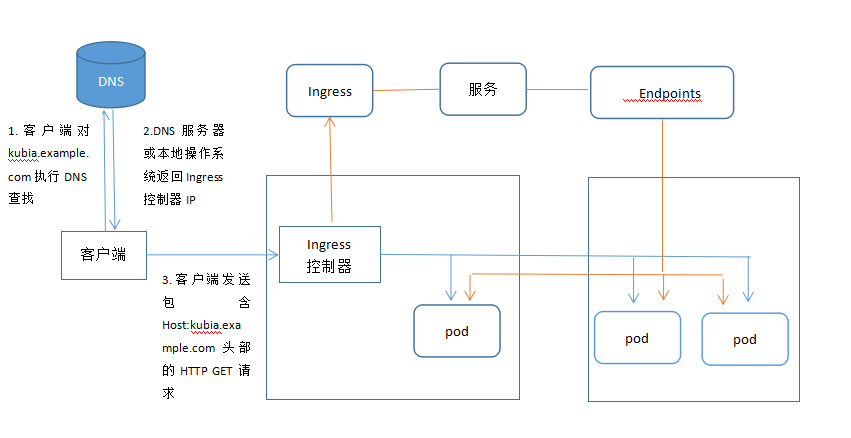
何時使用這種方式?
Ingress 可能是暴露服務的最強大方式,但同時也是最複雜的。Ingress 控制器有各種類型,包括 Google Cloud Load Balancer, Nginx,Contour,Istio,等等。它還有各種插件,比如 cert-manager[5],它可以為你的服務自動提供 SSL 證書。
如果你想要使用同一個 IP 暴露多個服務,這些服務都是使用相同的七層協議(典型如 HTTP),那麼Ingress 就是最有用的。如果你使用本地的 GCP 集成,你只需要為一個負載均衡器付費,且由於 Ingress是“智能”的,你還可以獲取各種開箱即用的特性(比如 SSL、認證、路由等等)。
5.4.3.通過相同的Ingress暴露多少服務
1.將不同的服務映射到相同的主機不同的路徑
apiVersion: v1 kind: Ingress metadata: name: Ingress-yaohong spec: rules: - host: kubia.example.com http: paths: - path: /yh //對kubia.example.com/yh請求轉發至kubai服務 backend: serviceName: kubia servicePort:80 - path: /foo //對kubia.example.com/foo請求轉發至bar服務 backend: serviceName: bar servicePort:80
2.將不同的服務映射到不同的主機上
apiVersion: v1 kind: Ingress metadata: name: Ingress-yaohong spec: rules: - host: yh.example.com http: paths: - path: / //對yh.example.com請求轉發至kubai服務 backend: serviceName: kubia servicePort:80 - host: bar.example.com http: paths: - path: / //對bar.example.com請求轉發至bar服務 backend: serviceName: bar servicePort:80
5.4.4.配置Ingress處理TLS傳輸
客戶端和控制器之間的通信是加密的,而控制器和後端pod之間的通信則不是。
apiVersion: v1 kind: Ingress metadata: name: Ingress-yaohong spec: tls: //在這個屬性中包含所有的TLS配置 - hosts: - yh.example.com //將接收來自yh.example.com的TLS連接 serviceName: tls-secret //從tls-secret中獲得之前創立的私鑰和證書 rules: - host: yh.example.com http: paths: - path: / //對yh.example.com請求轉發至kubai服務 backend: serviceName: kubia servicePort:80
5.5.pod就緒後發出信號
5.5.1.介紹就緒探針
就緒探針有三種類型:
1.Exec探針,執行進程的地方。容器的狀態由進程的退出狀態代碼確定。
2.HTTP GET探針,向容器發送HTTP GET請求,通過響應http狀態碼判斷容器是否準備好。
3.TCP socket探針,它打開一個TCP連接到容器的指定端口,如果連接建立,則認為容器已經準備就緒。
啟動容器時,k8s設置了一個等待時間,等待時間後才會執行一次準備就緒檢查。之後就會周期性的進行調用探針,並根據就緒探針的結果採取行動。
如果某個pod未就緒成功,則會從該服務中刪除該pod,如果pod再次就緒成功,則從新添加pod。
與存活探針區別:
就緒探針如果容器未準備就緒,則不會終止或者重啟啟動。
存活探針通過殺死異常容器,並用新的正常的容器來替代他保證pod正常工作。
就緒探針只有準備好處理請求pod才會接收他的請求。
重要性;
確保客戶端只與正常的pod進行交互,並且永遠不會知道系統存在問題。
5.5.2.向pod添加就緒探針
添加的yml文件如下
apiVersion: v1 kind: deployment ... spec: ... port: containers: - name: kubia-yh imgress: luksa/kubia readinessProbe: failureThreshold: 2 httpGet: path: /ping port: 80 scheme: HTTP initialDelaySeconds: 30 periodSeconds: 5 successThreshold: 1 timeoutSeconds: 3
相關參數解釋如下:
- initialDelaySeconds:容器啟動和探針啟動之間的秒數。
- periodSeconds:檢查的頻率(以秒為單位)。默認為10秒。最小值為1。
- timeoutSeconds:檢查超時的秒數。默認為1秒。最小值為1。
- successThreshold:失敗後檢查成功的最小連續成功次數。默認為1.活躍度必須為1。最小值為1。
- failureThreshold:當Pod成功啟動且檢查失敗時,Kubernetes將在放棄之前嘗試failureThreshold次。放棄生存檢查意味着重新啟動Pod。而放棄就緒檢查,Pod將被標記為未就緒。默認為3.最小值為1。
HTTP探針在httpGet上的配置項:
- host:主機名,默認為pod的IP。
- scheme:用於連接主機的方案(HTTP或HTTPS)。默認為HTTP。
- path:探針的路徑。
- httpHeaders:在HTTP請求中設置的自定義標頭。 HTTP允許重複的請求頭。
- port:端口的名稱或編號。數字必須在1到65535的範圍內
模擬就緒探針
# kubectl exec <pod_name> -- curl http://10.187.0.139:80/ping % Total % Received % Xferd Average Speed Time Time Time Current Dload Upload Total Spent Left Speed 0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
5.6.使用headless服務發現獨立的pod
5.6.1.創建headless服務
Headless Service也是一種Service,但不同的是會定義spec:clusterIP: None,也就是不需要Cluster IP的Service。
顧名思義,Headless Service就是沒頭的Service。有什麼使用場景呢?
-
第一種:自主選擇權,有時候
client想自己來決定使用哪個Real Server,可以通過查詢DNS來獲取Real Server的信息。 -
第二種:
Headless Services還有一個用處(PS:也就是我們需要的那個特性)。Headless Service的對應的每一個Endpoints,即每一個Pod,都會有對應的DNS域名;這樣Pod之間就可以互相訪問。
