快速讀懂 HTTP/3 協議
在 深入淺出:HTTP/2 一文中詳細介紹了 HTTP/2 新的特性,比如頭部壓縮、二進制分幀、虛擬的「流」與多路復用,性能方面比 HTTP/1 有了很大的提升。與所有性能優化過程一樣,去掉一個性能瓶頸,又會帶來新的瓶頸。對HTTP 2.0而言,TCP 很可能就是下一個性能瓶頸。這也是為什麼服務器端TCP配置對HTTP 2.0至關重要的一個原因。」
TCP 的限制
HTTP/3功能的核心是圍繞着底層的QUIC協議來實現的。在討論QUIC和UDP之前,我們有必要先列出TCP的某些限制,這也是導致QUIC發展的原因。
TCP可能會間歇性地掛起數據傳輸
如果一個序列號較低的數據段還沒有接收到,即使其他序列號較高的段已經接收到,TCP的接收機滑動窗口也不會繼續處理。這將導致TCP流瞬間掛起,在更糟糕的情況下,即使所有的段中有一個沒有收到,也會導致關閉連接。這個問題被稱為TCP流的行頭阻塞(HoL)。

TCP不支持流級復用
雖然TCP確實允許在應用層之間建立多個邏輯連接,但它不允許在一個TCP流中復用數據包。使用HTTP/2時,瀏覽器只能與服務器打開一個TCP連接,並使用同一個連接來請求多個對象,如CSS、JavaScript等文件。在接收這些對象的同時,TCP會將所有對象序列化在同一個流中。因此,它不知道TCP段的對象級分區。
TCP會產生冗餘通信
TCP連接握手會有冗餘的消息交換序列,即使是與已知主機建立的連接也是如此。
QUIC 協議
這裡先貼一下 HTTP/3 的協議棧圖,讓你對它有個大概的了解。

QUIC協議在以下設計選擇的基礎上,通過引入一些底層傳輸機制的改變,解決了這些問題。
- 1)選擇UDP作為底層傳輸層協議:在TCP之上建立新的傳輸機制,將繼承TCP的上述所有缺點。因此,UDP是一個明智的選擇。此外,QUIC是在用戶層構建的,所以不需要每次協議升級時進行內核修改。
- 2)流復用和流控:QUIC引入了連接上的多路流復用的概念。QUIC通過設計實現了單獨的、針對每個流的流控,解決了整個連接的行頭阻塞問題。

- 3)靈活的擁塞控制機制:TCP的擁塞控制機制是剛性的。該協議每次檢測到擁塞時,都會將擁塞窗口大小減少一半。相比之下,QUIC的擁塞控制設計得更加靈活,可以更有效地利用可用的網絡帶寬,從而獲得更好的吞吐量。
- 4)更好的錯誤處理能力:QUIC使用增強的丟失恢復機制和轉發糾錯功能,以更好地處理錯誤數據包。該功能對於那些只能通過緩慢的無線網絡訪問互聯網的用戶來說是一個福音,因為這些網絡用戶在傳輸過程中經常出現高錯誤率。
-
5)更快的握手:QUIC使用相同的TLS模塊進行安全連接。然而,與TCP不同的是,QUIC的握手機制經過優化,避免了每次兩個已知的對等者之間建立通信時的冗餘協議交換。

通過在QUIC之上構建基於HTTP/3的應用層,您可以獲得增強型傳輸機制的所有優勢,同時保留HTTP/2的語法和語義。但是,你也必須注意到,HTTP/2不能直接與QUIC集成,因為從應用到傳輸的底層幀映射是不兼容的。因此,IETF的HTTP工作組建議將HTTP/3作為新的HTTP版本,並根據QUIC協議的幀格式要求修改了幀映射。
除此之外,HTTP/3還使用了一種新的HTTP頭壓縮機制,稱為QPACK,是對HTTP/2中使用的HPACK的增強。在QPACK下,HTTP頭可以在不同的QUIC流中不按順序到達。與HTTP/2中的TCP確保數據包的按順序傳遞不同,QUIC流是不按順序傳遞的,在不同的流中可能包含不同的HTTP頭。因此,QPACK使用查找表機制對報頭進行編碼和解碼。
因此想要了解 HTTP/3,QUIC 是繞不過去的,下面主要通過幾個重要的特性讓大家對 QUIC 有更深的理解。
QUIC 的特點
零 RTT 建立連接
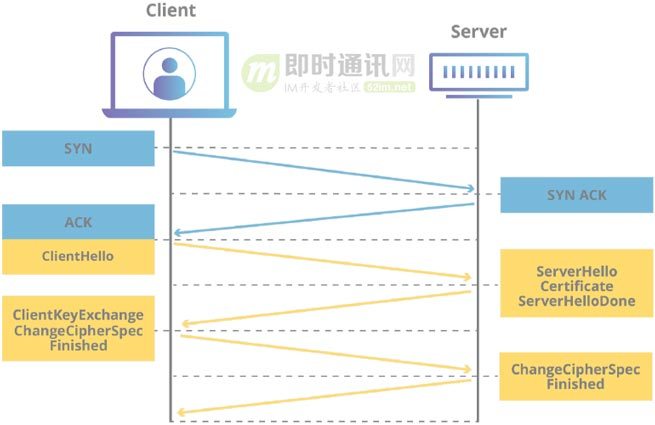
用一張圖可以形象地看出 HTTP/2 和 HTTP/3 建立連接的差別。
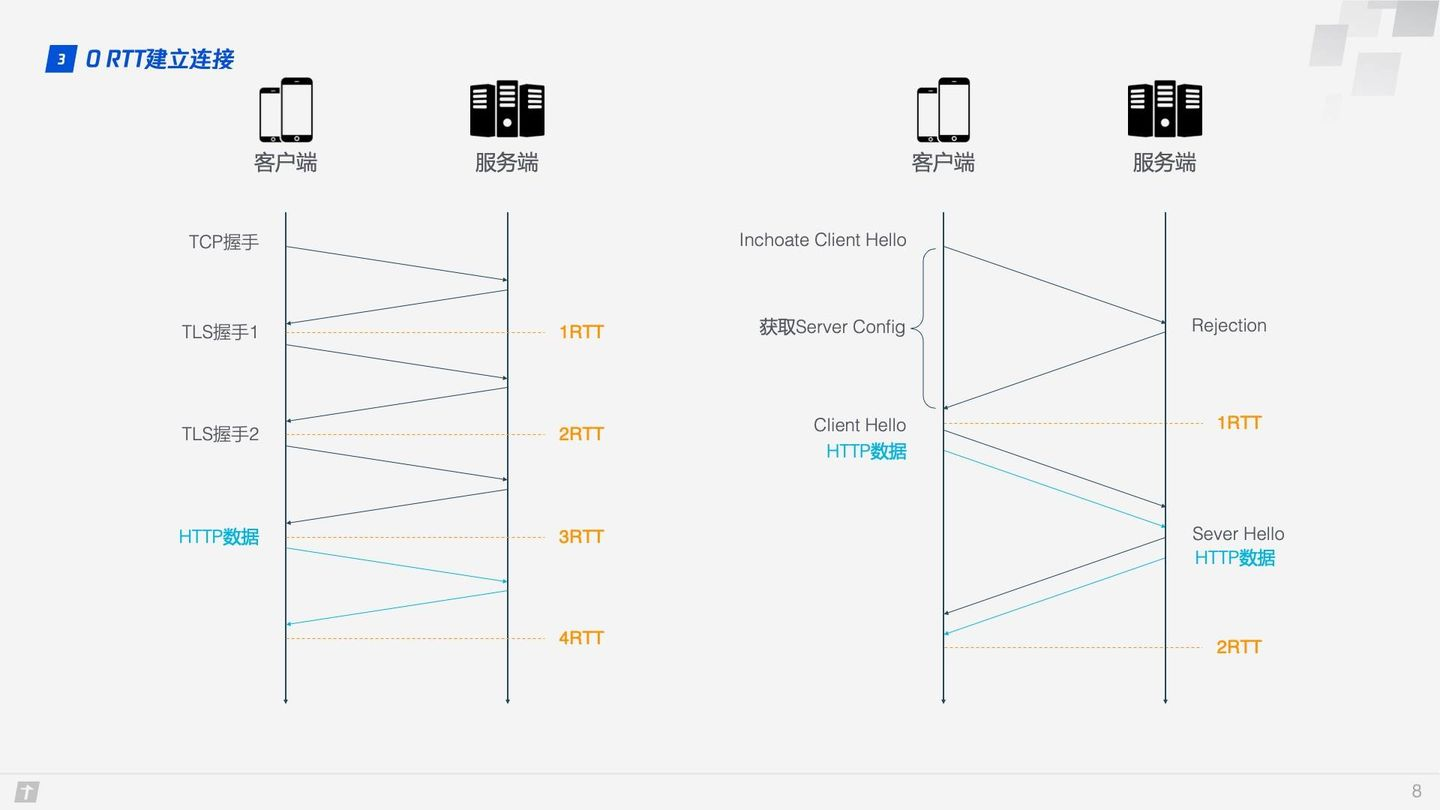
HTTP/2 的連接需要 3 RTT,如果考慮會話復用,即把第一次握手算出來的對稱密鑰緩存起來,那麼也需要 2 RTT,更進一步的,如果 TLS 升級到 1.3,那麼 HTTP/2 連接需要 2 RTT,考慮會話復用則需要 1 RTT。有人會說 HTTP/2 不一定需要 HTTPS,握手過程還可以簡化。這沒毛病,HTTP/2 的標準的確不需要基於 HTTPS,但實際上所有瀏覽器的實現都要求 HTTP/2 必須基於 HTTPS,所以 HTTP/2 的加密連接必不可少。而 HTTP/3 首次連接只需要 1 RTT,後面的連接更是只需 0 RTT,意味着客戶端發給服務端的第一個包就帶有請求數據,這一點 HTTP/2 難以望其項背。那這背後是什麼原理呢?我們具體看下 QUIC 的連接過程。
-
Step1:首次連接時,客戶端發送 Inchoate Client Hello 給服務端,用於請求連接;
-
Step2:服務端生成 g、p、a,根據 g、p 和 a 算出 A,然後將 g、p、A 放到 Server Config 中再發送 Rejection 消息給客戶端;
-
Step3:客戶端接收到 g、p、A 後,自己再生成 b,根據 g、p、b 算出 B,根據 A、p、b 算出初始密鑰 K。B 和 K 算好後,客戶端會用 K 加密 HTTP 數據,連同 B 一起發送給服務端;
-
Step4:服務端接收到 B 後,根據 a、p、B 生成與客戶端同樣的密鑰,再用這密鑰解密收到的 HTTP 數據。為了進一步的安全(前向安全性),服務端會更新自己的隨機數 a 和公鑰,再生成新的密鑰 S,然後把公鑰通過 Server Hello 發送給客戶端。連同 Server Hello 消息,還有 HTTP 返回數據;
-
Step5:客戶端收到 Server Hello 後,生成與服務端一致的新密鑰 S,後面的傳輸都使用 S 加密。
這樣,QUIC 從請求連接到正式接發 HTTP 數據一共花了 1 RTT,這 1 個 RTT 主要是為了獲取 Server Config,後面的連接如果客戶端緩存了 Server Config,那麼就可以直接發送 HTTP 數據,實現 0 RTT 建立連接。

這裡使用的是 DH 密鑰交換算法,DH 算法的核心就是服務端生成 a、g、p 3 個隨機數,a 自己持有,g 和 p 要傳輸給客戶端,而客戶端會生成 b 這 1 個隨機數,通過 DH 算法客戶端和服務端可以算出同樣的密鑰。在這過程中 a 和 b 並不參與網絡傳輸,安全性大大提高。因為 p 和 g 是大數,所以即使在網絡中傳輸的 p、g、A、B 都被劫持,那麼靠現在的計算機算力也沒法破解密鑰。
連接遷移
TCP 連接基於四元組(源 IP、源端口、目的 IP、目的端口),切換網絡時至少會有一個因素髮生變化,導致連接發生變化。當連接發生變化時,如果還使用原來的 TCP 連接,則會導致連接失敗,就得等原來的連接超時後重新建立連接,所以我們有時候發現切換到一個新網絡時,即使新網絡狀況良好,但內容還是需要加載很久。如果實現得好,當檢測到網絡變化時立刻建立新的 TCP 連接,即使這樣,建立新的連接還是需要幾百毫秒的時間。
QUIC 的連接不受四元組的影響,當這四個元素髮生變化時,原連接依然維持。那這是怎麼做到的呢?道理很簡單,QUIC 連接不以四元組作為標識,而是使用一個 64 位的隨機數,這個隨機數被稱為 Connection ID,即使 IP 或者端口發生變化,只要 Connection ID 沒有變化,那麼連接依然可以維持。

隊頭阻塞/多路復用
HTTP/1.1 和 HTTP/2 都存在隊頭阻塞問題(Head of line blocking),那什麼是隊頭阻塞呢?
TCP 是個面向連接的協議,即發送請求後需要收到 ACK 消息,以確認對方已接收到數據。如果每次請求都要在收到上次請求的 ACK 消息後再請求,那麼效率無疑很低。後來 HTTP/1.1 提出了 Pipelining 技術,允許一個 TCP 連接同時發送多個請求,這樣就大大提升了傳輸效率。

在這個背景下,下面就來談 HTTP/1.1 的隊頭阻塞。下圖中,一個 TCP 連接同時傳輸 10 個請求,其中第 1、2、3 個請求已被客戶端接收,但第 4 個請求丟失,那麼後面第 5 – 10 個請求都被阻塞,需要等第 4 個請求處理完畢才能被處理,這樣就浪費了帶寬資源。
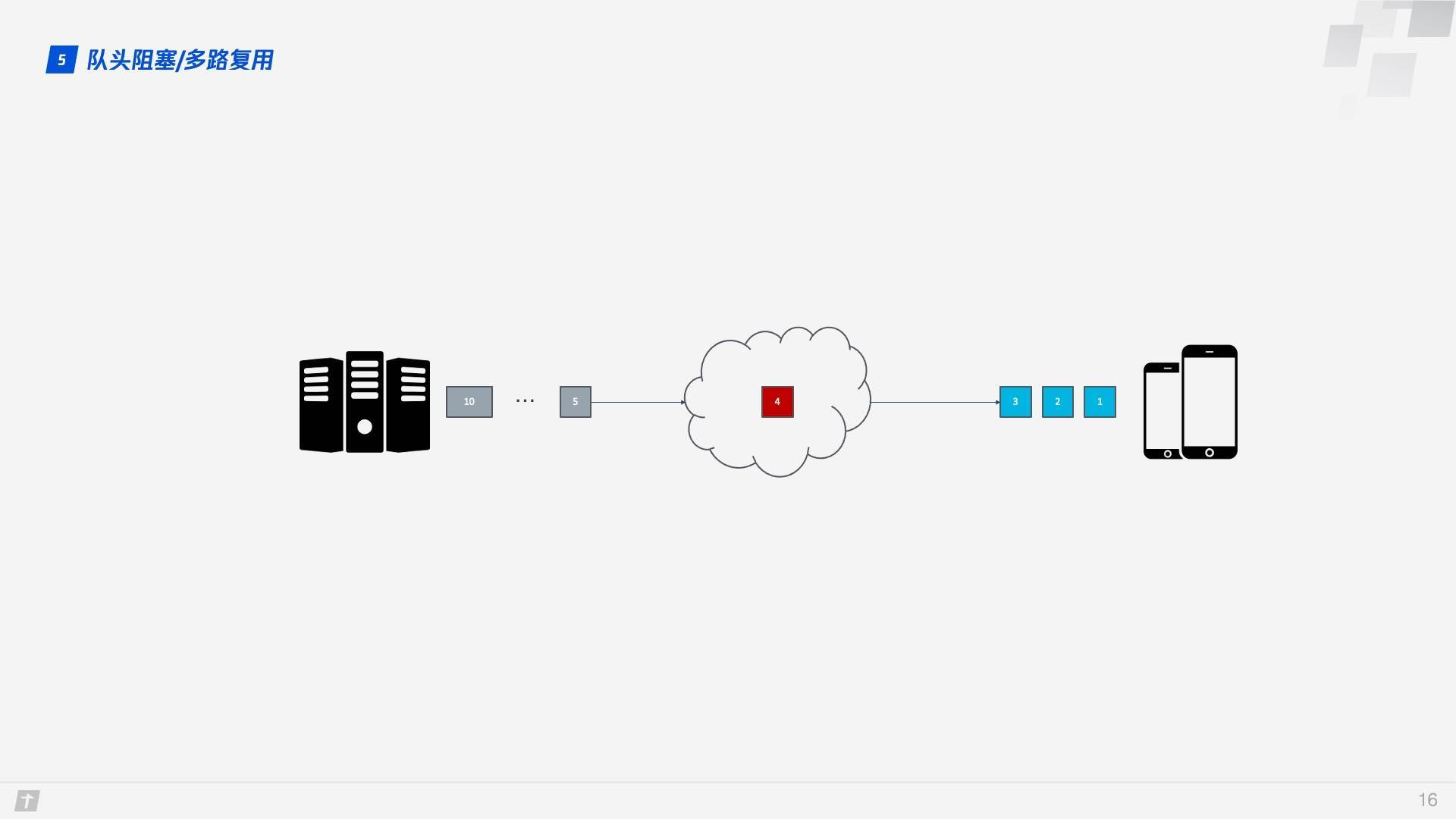
因此,HTTP 一般又允許每個主機建立 6 個 TCP 連接,這樣可以更加充分地利用帶寬資源,但每個連接中隊頭阻塞的問題還是存在。
HTTP/2 的多路復用解決了上述的隊頭阻塞問題。不像 HTTP/1.1 中只有上一個請求的所有數據包被傳輸完畢下一個請求的數據包才可以被傳輸,HTTP/2 中每個請求都被拆分成多個 Frame 通過一條 TCP 連接同時被傳輸,這樣即使一個請求被阻塞,也不會影響其他的請求。如下圖所示,不同顏色代表不同的請求,相同顏色的色塊代表請求被切分的 Frame。
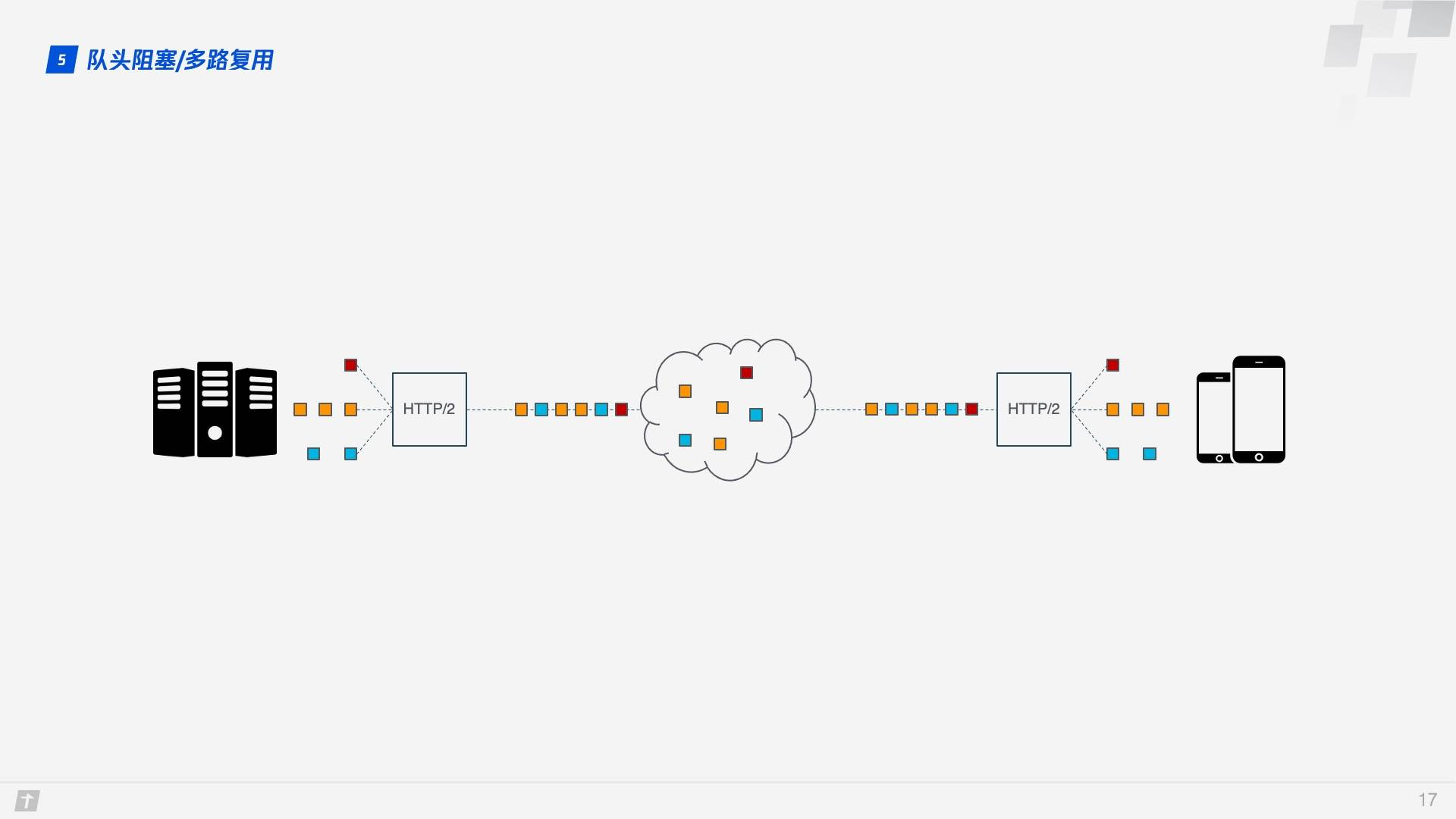
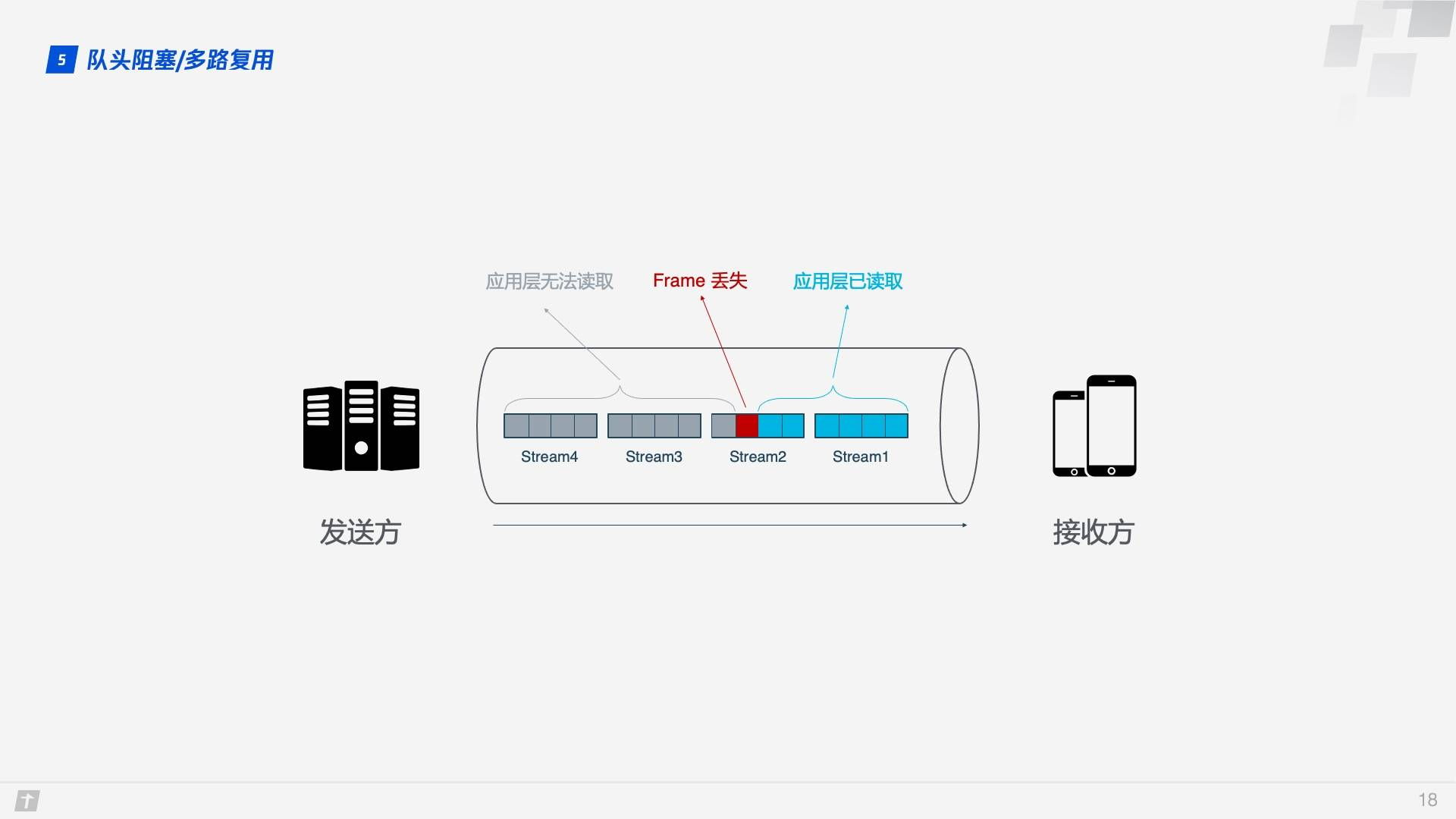
事情還沒完,HTTP/2 雖然可以解決「請求」這個粒度的阻塞,但 HTTP/2 的基礎 TCP 協議本身卻也存在着隊頭阻塞的問題。HTTP/2 的每個請求都會被拆分成多個 Frame,不同請求的 Frame 組合成 Stream,Stream 是 TCP 上的邏輯傳輸單元,這樣 HTTP/2 就達到了一條連接同時發送多條請求的目標,這就是多路復用的原理。我們看一個例子,在一條 TCP 連接上同時發送 4 個 Stream,其中 Stream1 已正確送達,Stream2 中的第 3 個 Frame 丟失,TCP 處理數據時有嚴格的前後順序,先發送的 Frame 要先被處理,這樣就會要求發送方重新發送第 3 個 Frame,Stream3 和 Stream4 雖然已到達但卻不能被處理,那麼這時整條連接都被阻塞。
不僅如此,由於 HTTP/2 必須使用 HTTPS,而 HTTPS 使用的 TLS 協議也存在隊頭阻塞問題。TLS 基於 Record 組織數據,將一堆數據放在一起(即一個 Record)加密,加密完後又拆分成多個 TCP 包傳輸。一般每個 Record 16K,包含 12 個 TCP 包,這樣如果 12 個 TCP 包中有任何一個包丟失,那麼整個 Record 都無法解密。
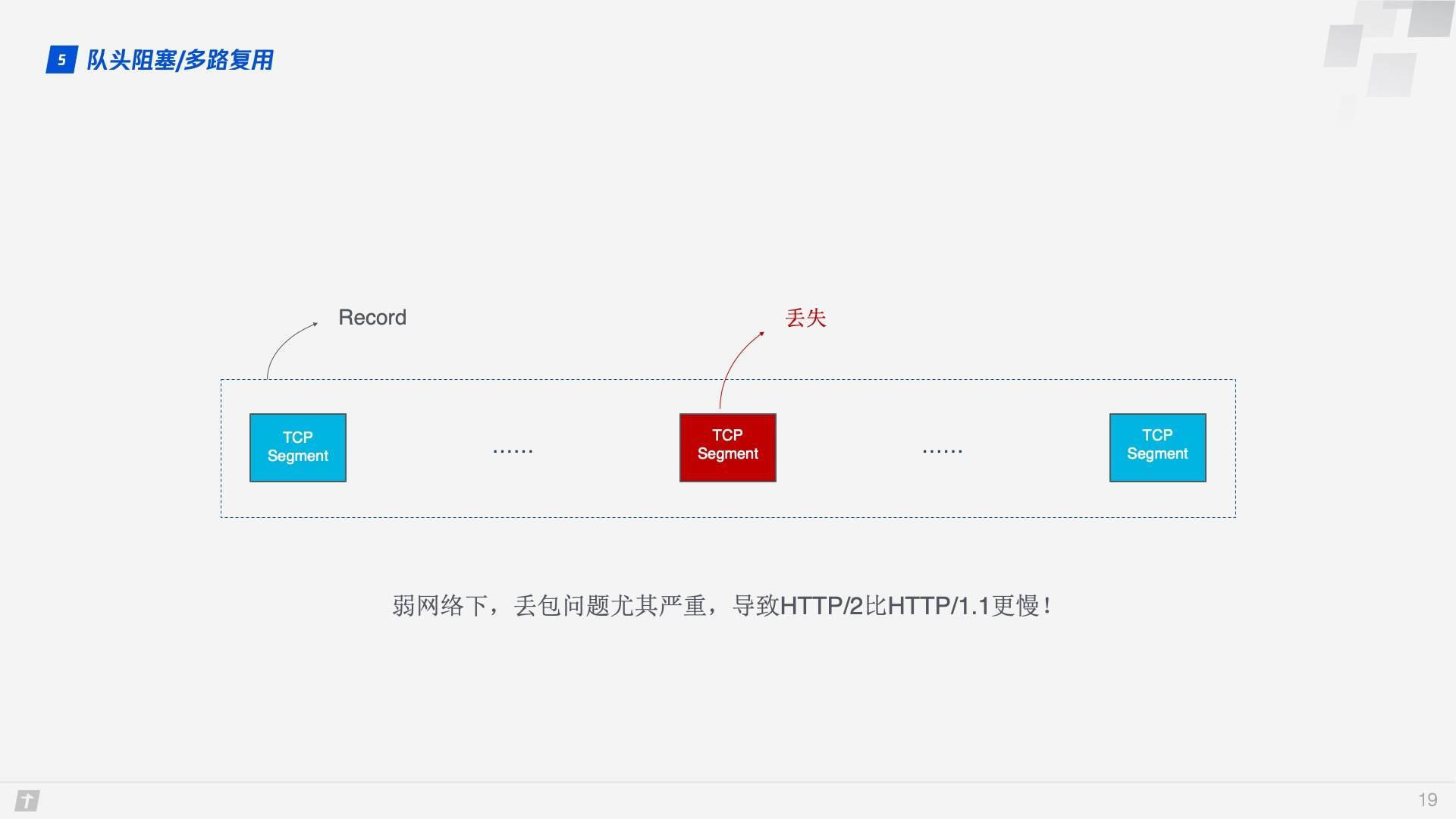
隊頭阻塞會導致 HTTP/2 在更容易丟包的弱網絡環境下比 HTTP/1.1 更慢!
那 QUIC 是如何解決隊頭阻塞問題的呢?主要有兩點。
-
QUIC 的傳輸單元是 Packet,加密單元也是 Packet,整個加密、傳輸、解密都基於 Packet,這樣就能避免 TLS 的隊頭阻塞問題;
-
QUIC 基於 UDP,UDP 的數據包在接收端沒有處理順序,即使中間丟失一個包,也不會阻塞整條連接,其他的資源會被正常處理。

擁塞控制
擁塞控制的目的是避免過多的數據一下子湧入網絡,導致網絡超出最大負荷。QUIC 的擁塞控制與 TCP 類似,並在此基礎上做了改進。所以我們先簡單介紹下 TCP 的擁塞控制。
TCP 擁塞控制由 4 個核心算法組成:慢啟動、擁塞避免、快速重傳和快速恢復,理解了這 4 個算法,對 TCP 的擁塞控制也就有了大概了解。
-
慢啟動:發送方向接收方發送 1 個單位的數據,收到對方確認後會發送 2 個單位的數據,然後依次是 4 個、8 個……呈指數級增長,這個過程就是在不斷試探網絡的擁塞程度,超出閾值則會導致網絡擁塞;
-
擁塞避免:指數增長不可能是無限的,到達某個限制(慢啟動閾值)之後,指數增長變為線性增長;
-
快速重傳:發送方每一次發送時都會設置一個超時計時器,超時後即認為丟失,需要重發;
-
快速恢復:在上面快速重傳的基礎上,發送方重新發送數據時,也會啟動一個超時定時器,如果收到確認消息則進入擁塞避免階段,如果仍然超時,則回到慢啟動階段。
QUIC 重新實現了 TCP 協議的 Cubic 算法進行擁塞控制,並在此基礎上做了不少改進。下面介紹一些 QUIC 改進的擁塞控制的特性。
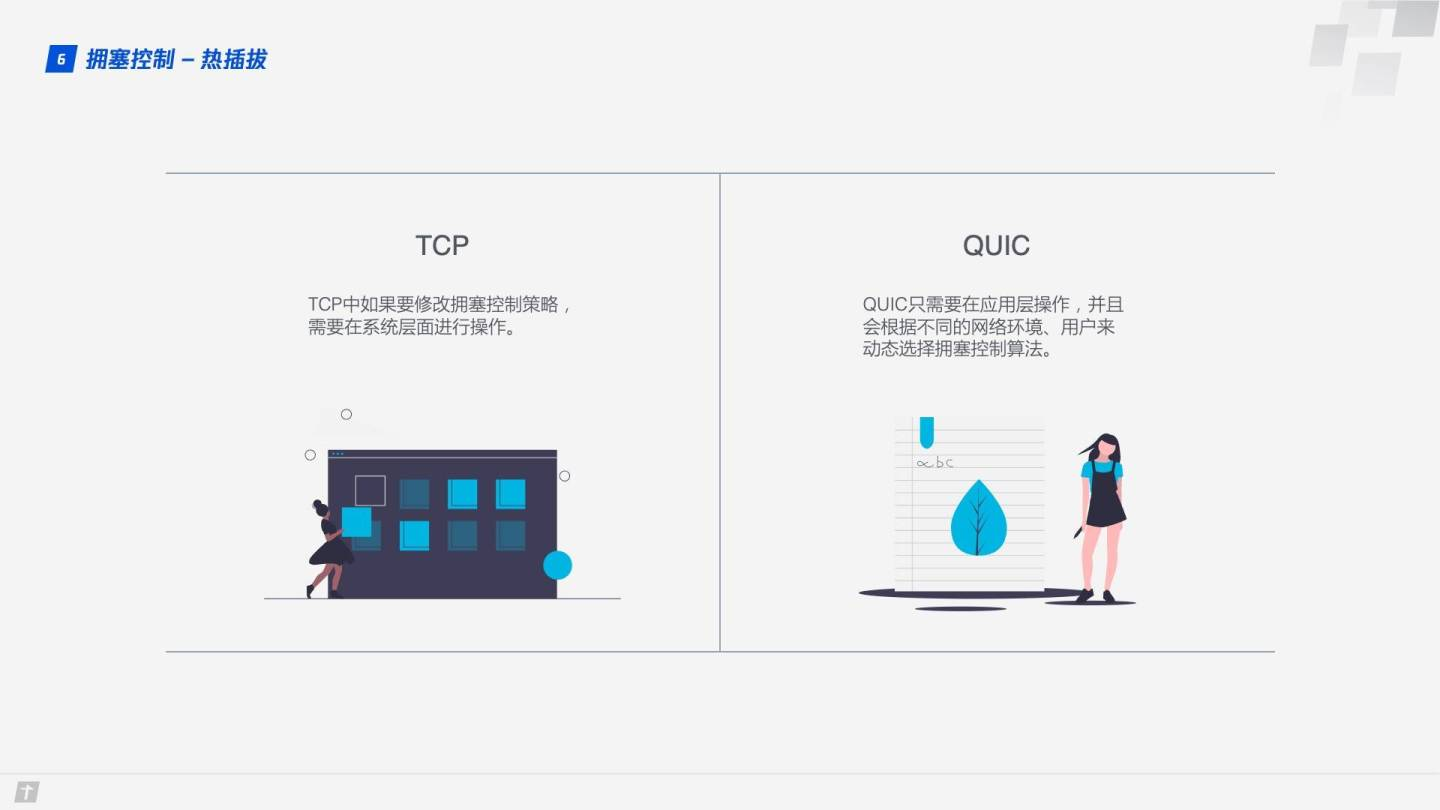
熱插拔
TCP 中如果要修改擁塞控制策略,需要在系統層面進行操作。QUIC 修改擁塞控制策略只需要在應用層操作,並且 QUIC 會根據不同的網絡環境、用戶來動態選擇擁塞控制算法
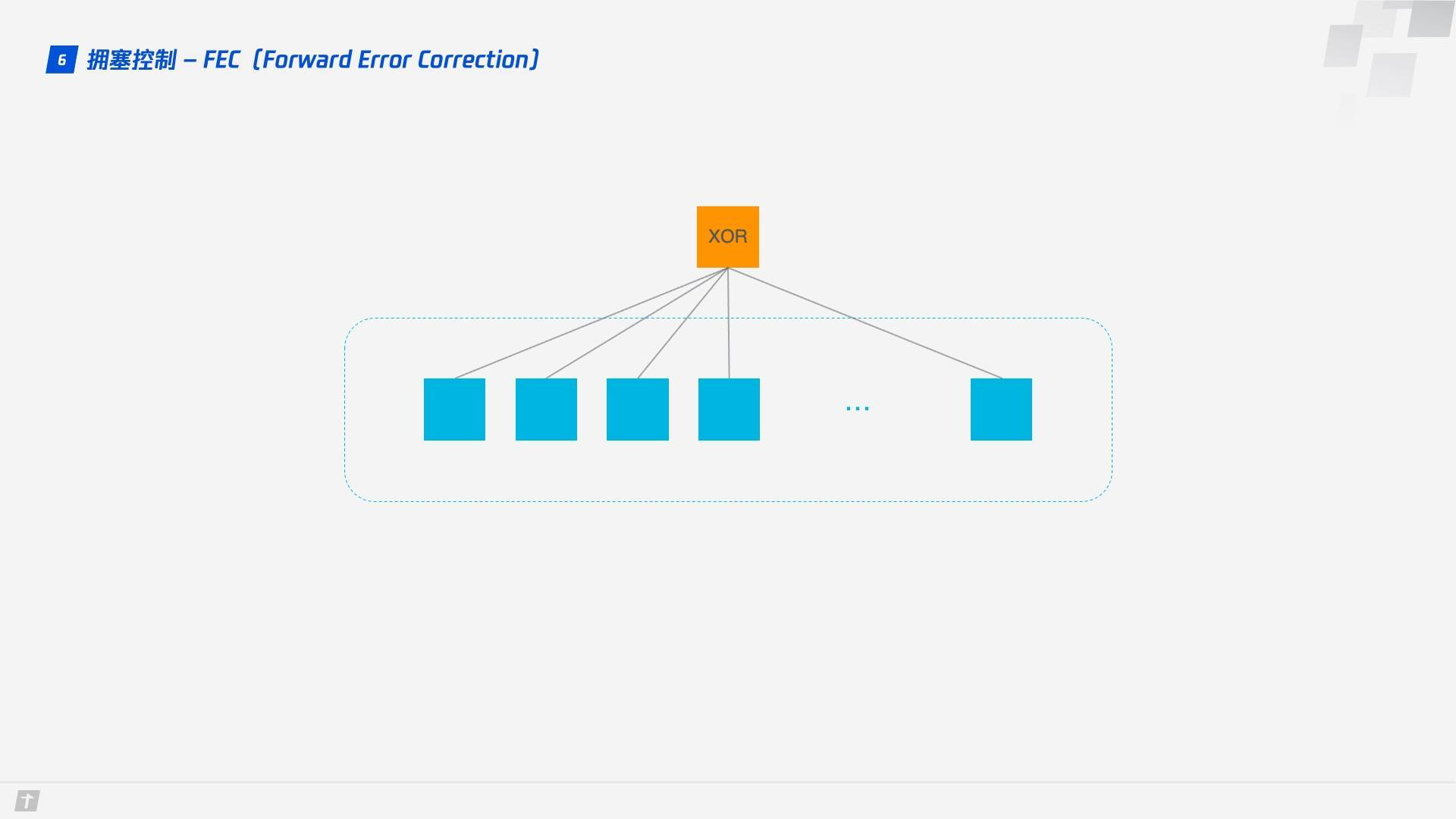
前向糾錯 FEC
QUIC 使用前向糾錯(FEC,Forward Error Correction)技術增加協議的容錯性。一段數據被切分為 10 個包後,依次對每個包進行異或運算,運算結果會作為 FEC 包與數據包一起被傳輸,如果不幸在傳輸過程中有一個數據包丟失,那麼就可以根據剩餘 9 個包以及 FEC 包推算出丟失的那個包的數據,這樣就大大增加了協議的容錯性。
這是符合現階段網絡技術的一種方案,現階段帶寬已經不是網絡傳輸的瓶頸,往返時間才是,所以新的網絡傳輸協議可以適當增加數據冗餘,減少重傳操作。
單調遞增的 Packet Number
TCP 為了保證可靠性,使用 Sequence Number 和 ACK 來確認消息是否有序到達,但這樣的設計存在缺陷。
超時發生後客戶端發起重傳,後來接收到了 ACK 確認消息,但因為原始請求和重傳請求接收到的 ACK 消息一樣,所以客戶端就鬱悶了,不知道這個 ACK 對應的是原始請求還是重傳請求。如果客戶端認為是原始請求的 ACK,但實際上是左圖的情形,則計算的採樣 RTT 偏大;如果客戶端認為是重傳請求的 ACK,但實際上是右圖的情形,又會導致採樣 RTT 偏小。圖中有幾個術語,RTO 是指超時重傳時間(Retransmission TimeOut),跟我們熟悉的 RTT(Round Trip Time,往返時間)很長得很像。採樣 RTT 會影響 RTO 計算,超時時間的準確把握很重要,長了短了都不合適。
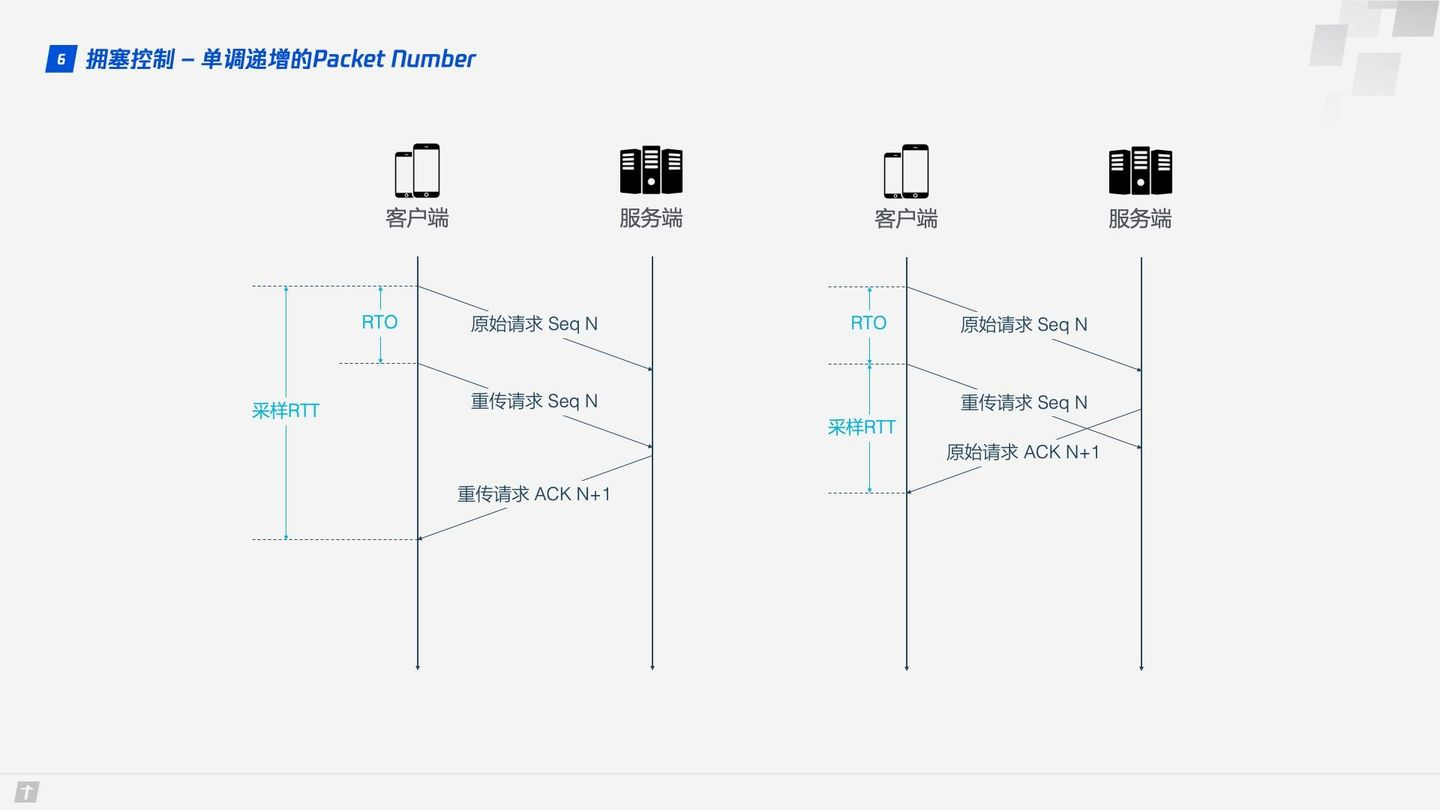
QUIC 解決了上面的歧義問題。與 Sequence Number 不同的是,Packet Number 嚴格單調遞增,如果 Packet N 丟失了,那麼重傳時 Packet 的標識不會是 N,而是比 N 大的數字,比如 N + M,這樣發送方接收到確認消息時就能方便地知道 ACK 對應的是原始請求還是重傳請求。

ACK Delay
TCP 計算 RTT 時沒有考慮接收方接收到數據到發送確認消息之間的延遲,如下圖所示,這段延遲即 ACK Delay。QUIC 考慮了這段延遲,使得 RTT 的計算更加準確。

更多的 ACK 塊
一般來說,接收方收到發送方的消息後都應該發送一個 ACK 回復,表示收到了數據。但每收到一個數據就返回一個 ACK 回復太麻煩,所以一般不會立即回復,而是接收到多個數據後再回復,TCP SACK 最多提供 3 個 ACK block。但有些場景下,比如下載,只需要服務器返回數據就好,但按照 TCP 的設計,每收到 3 個數據包就要「禮貌性」地返回一個 ACK。而 QUIC 最多可以捎帶 256 個 ACK block。在丟包率比較嚴重的網絡下,更多的 ACK block 可以減少重傳量,提升網絡效率。

流量控制
TCP 會對每個 TCP 連接進行流量控制,流量控制的意思是讓發送方不要發送太快,要讓接收方來得及接收,不然會導致數據溢出而丟失,TCP 的流量控制主要通過滑動窗口來實現的。可以看出,擁塞控制主要是控制發送方的發送策略,但沒有考慮到接收方的接收能力,流量控制是對這部分能力的補齊。
QUIC 只需要建立一條連接,在這條連接上同時傳輸多條 Stream,好比有一條道路,兩頭分別有一個倉庫,道路中有很多車輛運送物資。QUIC 的流量控制有兩個級別:連接級別(Connection Level)和 Stream 級別(Stream Level),好比既要控制這條路的總流量,不要一下子很多車輛湧進來,貨物來不及處理,也不能一個車輛一下子運送很多貨物,這樣貨物也來不及處理。
那 QUIC 是怎麼實現流量控制的呢?我們先看單條 Stream 的流量控制。Stream 還沒傳輸數據時,接收窗口(flow control receive window)就是最大接收窗口(flow control receive window),隨着接收方接收到數據後,接收窗口不斷縮小。在接收到的數據中,有的數據已被處理,而有的數據還沒來得及被處理。如下圖所示,藍色塊表示已處理數據,黃色塊表示未處理數據,這部分數據的到來,使得 Stream 的接收窗口縮小。
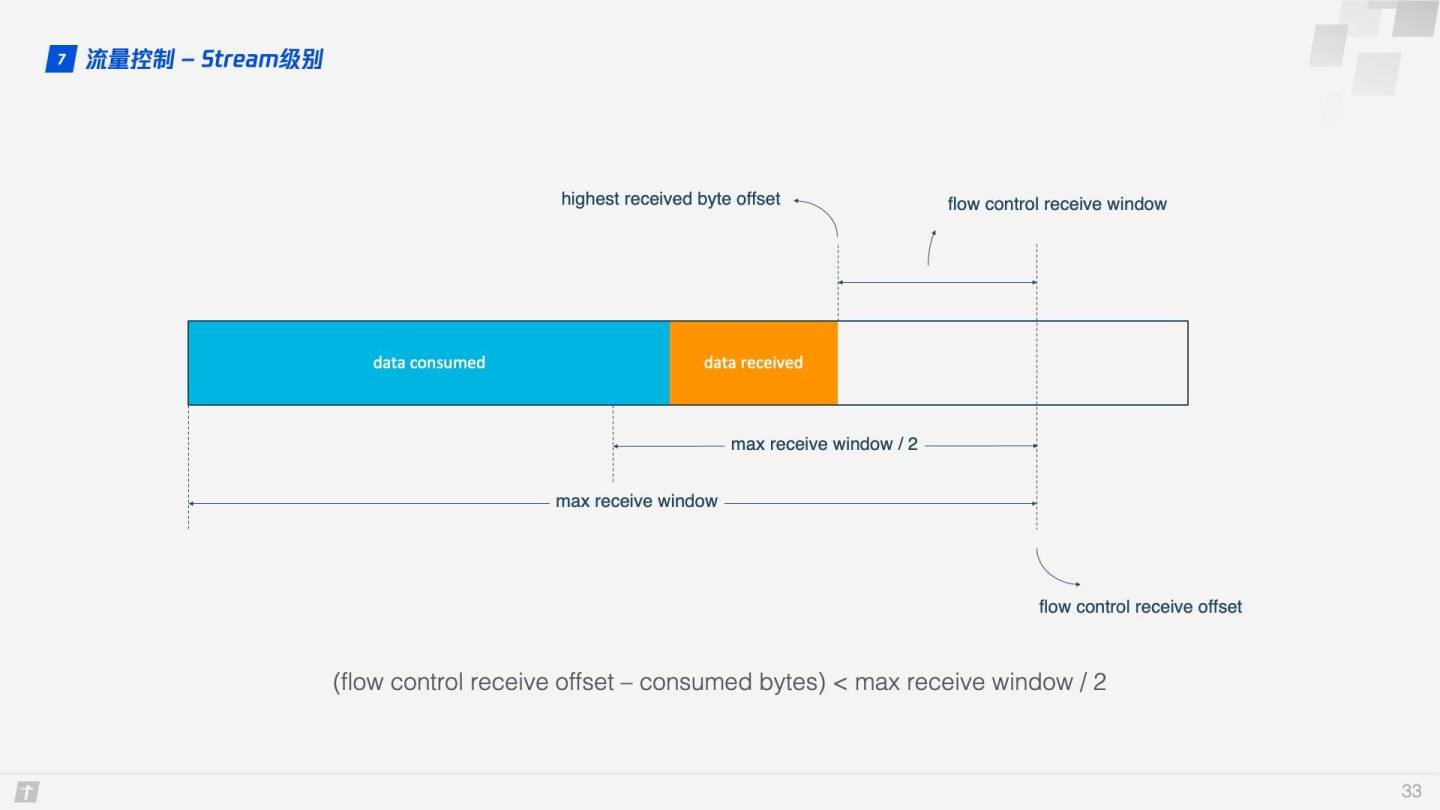
隨着數據不斷被處理,接收方就有能力處理更多數據。當滿足 (flow control receive offset – consumed bytes) < (max receive window / 2) 時,接收方會發送 WINDOW_UPDATE frame 告訴發送方你可以再多發送些數據過來。這時 flow control receive offset 就會偏移,接收窗口增大,發送方可以發送更多數據到接收方。

Stream 級別對防止接收端接收過多數據作用有限,更需要藉助 Connection 級別的流量控制。理解了 Stream 流量那麼也很好理解 Connection 流控。Stream 中,接收窗口(flow control receive window) = 最大接收窗口(max receive window) – 已接收數據(highest received byte offset) ,而對 Connection 來說:接收窗口 = Stream1 接收窗口 + Stream2 接收窗口 + … + StreamN 接收窗口 。
為什麼HTTP/3很重要?
TCP已經有40多年的歷史了。它在1981年通過RFC 793從而標準化。多年來,它經歷了多次更新,是一個非常強大的傳輸協議,可以支持互聯網流量的增長。然而,由於設計上的原因,TCP從來就不適合處理有損無線環境中的數據傳輸。在互聯網的早期,有線網絡將網絡中的每一台計算機連接起來。
現在,隨着智能手機和便攜式設備的數量超過台式機和筆記本電腦的數量,超過50%的互聯網流量已經通過無線傳輸。這種趨勢給整體的網絡瀏覽體驗帶來了問題,其中最重要的是在無線覆蓋率不足的情況下,TCP中的行頭阻塞(關於TCP在移動網絡下的不足,請閱讀《5G時代已經到來,TCP/IP老矣,尚能飯否?》)。
Google的一些初步實驗證明,QUIC作為Google部分熱門服務的底層傳輸協議,極大地提高了速度和用戶體驗。部署QUIC作為YouTube視頻的底層傳輸協議,導致YouTube視頻流的緩衝率下降了30%,這直接影響了用戶的視頻觀看體驗。在顯示谷歌搜索結果時,也有類似的改善。
網絡條件較差的情況下提升非常明顯,這促使谷歌更加積極地完善該協議,並最終向IETF提出標準化。
由於這些早期的試驗所帶來的所有改進,QUIC已經成為帶領萬維網走向未來的重要因素。在QUIC的支持下,HTTP從HTTP/2到HTTP/3的改頭換面,朝着這個方向合理地邁出了一步。
HTTP/3 的局限性
過渡到HTTP/3不僅涉及到應用層的變化,還涉及到底層傳輸層的變化。因此,與它的前身HTTP/2相比,HTTP/3的採用更具挑戰性,因為後者只需要改變應用層。傳輸層承受着網絡中的大量中間層審查。這些中間層,如防火牆、代理、NAT設備等會進行大量的深度數據包檢查,以滿足其功能需求。因此,新的傳輸機制的引入對IT基礎設施和運維團隊來說有一些影響。
然而,HTTP/3被廣泛採用的另一個問題是,它是基於QUIC的,在UDP上運行。大多數的Web流量,以及IETF定義的知名服務都是在TCP之上運行的。這也是為什麼長時間運行HTTP/3的UDP會話會被防火牆的默認數據包過濾策略所影響的原因。
隨着IETF正在進行的標準化工作,這些問題最終都會得到解決。此外,考慮到Google在早期QUIC實驗所顯示的積極結果,人們對HTTP/3的支持是壓倒性的,這將最終迫使中間層廠商標準化。
針對受限的IoT設備,HTTP/3由於過於繁瑣從而無法採用。許多IoT應用部署的設備的外形尺寸非常小。因此,它們的RAM和CPU功率都是有限的。為了使設備在電池功率、低比特率和有損連接等限制條件下高效運行,必須執行此要求。HTTP/3在現有的UDP之上,以QUIC的形式在傳輸層處理,增加了HTTP/3在整個協議棧中的佔用空間。這使得HTTP/3較為笨重,不適合那些IoT設備。但這種情況很少出現,而且存在專門的協議,這就避免了直接在此類設備上支持HTTP的需要。此外,還有以物聯網為核心的協議,如MQTT。
關於 HTTP 系列文章:
-
HTTP 概述
-
TCP 三次握手和四次揮手圖解(有限狀態機)
-
從你輸入網址,到看到網頁——詳解中間發生的過程
-
深入淺出 HTTPS (詳解版)
-
漫談 HTTP 連接
-
漫談 HTTP 性能優化
-
HTTP 報文格式簡介
-
深入淺出:HTTP/2

