線程池源碼分析
概述
在 java 中,線程池 ThreadPoolExecutor 是一個繞不過去的類,它是享元模式思想的體現,通過在容器中創建一定數量的線程加以重複利用,從而避免頻繁創建線程帶來的額外開銷。一個設置合理的線程池可以提高任務響應的速度,並且避免線程數超過硬件能力帶來的意外情況。
在本文,將深入線程池源碼,了解線程池的底層實現與運行機制。
一、構造方法
ThreadPoolExecutor 類一共提供了四個構造方法,我們基於參數最完整構造方法了解一下線程池創建所需要的變量:
public ThreadPoolExecutor(int corePoolSize, // 核心線程數
int maximumPoolSize, // 最大線程數
long keepAliveTime, // 非核心線程閑置存活時間
TimeUnit unit, // 時間單位
BlockingQueue<Runnable> workQueue, // 工作隊列
ThreadFactory threadFactory, // 創建線程使用的線程工廠
RejectedExecutionHandler handler // 拒絕策略) {
}
- 核心線程數:即長期存在的線程數,當線程池中運行線程未達到核心線程數時會優先創建新線程;
- 最大線程數:當核心線程已滿,工作隊列已滿,同時線程池中線程總數未超過最大線程數,會創建非核心線程;
- 非核心線程閑置存活時間:當非核心線程閑置的時的最大存活時間;
- 時間單位:非核心線程閑置存活時間的時間單位;
- 任務隊列:當核心線程滿後,任務會優先加入工作隊列,等等待核心線程消費;
- 線程工廠:線程池創建新線程時使用的線程工廠;
- 拒絕策略:當工作隊列與線程池都滿時,用於執行的策略;
二、線程池狀態
1.線程池狀態
線程池擁有一個 AtomicInteger 類型的成員變量 ctl ,通過位運算分別使用 ctl 的高位低位以便在一個值中存儲線程數量以及線程池狀態。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
// 29(32-3)
private static final int COUNT_BITS = Integer.SIZE - 3;
// 允許的最大工作線程(2^29-1 約5億)
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 運行狀態。線程池接受並處理新任務
private static final int RUNNING = -1 << COUNT_BITS;
// 關閉狀態。線程池不能接受新任務,處理完剩餘任務後關閉。調用shutdown()方法會進入該狀態。
private static final int SHUTDOWN = 0 << COUNT_BITS;
// 停止狀態。線程池不能接受新任務,並且嘗試中斷舊任務。調用shutdownNow()方法會進入該狀態。
private static final int STOP = 1 << COUNT_BITS;
// 整理狀態。由關閉狀態轉變,線程池任務隊列為空時進入該狀態,會調用terminated()方法。
private static final int TIDYING = 2 << COUNT_BITS;
// 終止狀態。terminated()方法執行完畢後進入該狀態,線程池徹底停止。
private static final int TERMINATED = 3 << COUNT_BITS;
2.線程狀態的計算
這裡比較不好理解的是上述-1的位運算,下面我們來分析一下:
在計算機中,二進制負數一般用補碼錶示,即源碼取反再加一。但又有這種說法,即將最高位作為符號位,0為正數,1為負數。實際上兩者是可以結合在一起看的。假如數字是單位元組數,1 位元組對應8 bit,即八位,現在,我們要計算 – 1。
按照第二種說法,最高位為符號位,則有 1/000 0001,然後按第一種說法取反後+1,並且符號位不變,則有 1/111 1110 + 1,即 1/111 1111。
現在回到 -1 << COUNT_BITS這行代碼:
一個 int 是 4 個位元組,對應 32 bit,按上述過程 -1 轉為二進制即為 1/111……1111(32個1), COUNT_BITS是 29,-1 左移 29 位,最終得到 111.0…0000。
同理,計算其他的幾種狀態,可知分別是:
| 狀態 | 二進制 |
|---|---|
| RUNNING | 111…0….00 |
| SHUTDOWN | 000…0….00 |
| STOP | 001…0….00 |
| TIDYING | 010…0….00 |
| TERMINATED | 011…0….00 |
其中,我們可以知道 SHUTDOWN 狀態轉為十進制也是 0 ,而 RUNNING 作為有符號數,它的最高位是 1,說明轉為十進制以後是個負數,其他的狀態最高位都是 0,轉為十進制之後都是正數,也就是說,我們可以這麼認為:
小於 SHUTDOWN 的就是 RUNNING,大於 SHUTDOWN 就是停止或者停止中。
這也是後面狀態計算的一些寫法的基礎。比如 isRunning()方法:
private static boolean isRunning(int c) {
return c < SHUTDOWN;
}
3.線程狀態與工作線程數的獲取
// 根據當前運行狀態和工作線程數獲取當前的 ctl
private static int ctlOf(int rs, int wc) { return rs | wc; }
// 獲取運行狀態
private static int runStateOf(int c) { return c & ~CAPACITY; }
// 獲取工作線程數
private static int workerCountOf(int c) { return c & CAPACITY; }
前面獲取狀態的時候調用了 ctlOf()方法,根據前面,我們可以知道,CAPACITY實際上是 29 位,而線程狀態用的是 32 – 30 共 3 位,也就是說,ctl 共 32 位,高3 位用於表示線程池狀態,而低 29 位表示工作線程的數量。
這樣上述三個方法就很好理解了:
-
ctlOf():獲取 ctl。將工作線程數量與運行狀態進行於運算,假如我們處於 RUNNING,並且有 1 個工作線程,那麼 ctl = 111….000 | 000…. 001,最終得到 111 ….. 001;
-
runStateOf():獲取運行狀態。繼續根據上文的數據,
~CAPACITY取反即為 111….000,與運行狀態 111…0000 與運算,最終得到 111….000,相當於低位掩碼,消去低 29 位; -
workerCountOf():獲取工作線程數。同理,
c & CAPACITY里的 CAPACITY 相當於高位掩碼,用於消去高 3 位,最終得到 00…001,即工作線程數。
同理,如果要增加工作線程數,就直接通過 CAS 去遞增 ctl,比如新建線程中使用的公共方法:
private boolean compareAndIncrementWorkerCount(int expect) {
// 通過 CAS 遞增 ctl
return ctl.compareAndSet(expect, expect + 1);
}
要改變線程池狀態,就根據當前工作線程和要改變的狀態去合成新的 ctl,然後 CAS 改變 ctl,比如 shutdown()中涉及的相關代碼:
private void advanceRunState(int targetState) {
for (;;) {
int c = ctl.get();
if (runStateAtLeast(c, targetState) ||
// 通過 CAS 改變 ctl
ctl.compareAndSet(c, ctlOf(targetState, workerCountOf(c))))
break;
}
}
三、任務的創建與執行
線程池任務提交方法是 execute(),根據代碼可知,當一個任務進來時,分四種情況:
- 當前工作線程數小於核心線程數,啟動新線程;
- 當前工作線程數大於核心線程數,但是未大於最大線程數,嘗試添加到工作隊列;
- 當前線程池核心線程和隊列都滿了,嘗試創建新非核心線程。
- 非核心線程創建失敗,說明線程池徹底滿了,執行拒絕策略。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
// 1.當前工作線程數小於核心線程數,啟動新線程
if (workerCountOf(c) < corePoolSize) {
// 添加任務
if (addWorker(command, true))
return;
c = ctl.get();
}
// 2. 當前工作線程數大於核心線程數,但是未大於最大線程數,嘗試添加到工作隊列
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
// 如果當前線程處於非運行態,並且移除當前任務成功,則拒絕任務(防止添加到一半就shutdown)
if (! isRunning(recheck) && remove(command))
reject(command);
// 如果當前沒有工作線程了,就啟動新線程
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
// 3.當前線程池核心線程和隊列都滿了,嘗試創建新非核心線程
else if (!addWorker(command, false))
// 4.線程池徹底滿了,執行拒絕策略
reject(command);
}
1.添加任務
添加任務依靠 addWorker()方法,這個方法很長,但是主要就幹了兩件事:
- CAS 讓 ctl 的工作線程數 +1;
- 啟動新的線程;
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
// 1.改變 ctl 使工作線程+1
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 如果當前不處於運行狀態,傳入任務為空,並且任務隊列為空的時候拒絕添加新任務
// 即線程池 shutdown 時不讓添加新任務,但是運行繼續跑完任務隊列里的任務。
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
// 線程不允許超過最大線程數,核心線程不允許超過最大核心線程數
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
// CAS 遞增工作線程數
if (compareAndIncrementWorkerCount(c))
// 失敗了就重新回到上面的retry處繼續往下執行
break retry;
// 更新 ctl
c = ctl.get();
// 如果運行狀態改變了就全部從來
if (runStateOf(c) != rs)
continue retry;
}
}
// 2.啟動新線程
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
// 創建新線程
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
// 加鎖
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
int rs = runStateOf(ctl.get());
// 如果線程池處於運行狀態,或者沒有新任務的SHUTDOWN狀態(即SHUTDOW以後還在消費工作隊列里的任務)
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
// 線程是否在未啟動前就已經啟動了
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
// 如果集合中的工作線程數大於最大線程數,則將池中最大線程數改為當前工作線程數
if (s > largestPoolSize)
largestPoolSize = s;
// 線程創建完成
workerAdded = true;
}
} finally {
mainLock.unlock();
}
// 如果線程成功創建,就啟動線程,並且更改啟動狀態為成功
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
// 如果線程啟動不成功,就執行失敗策略
if (! workerStarted)
// 啟動失敗策略,從當前工作線程隊列移除當前啟動失敗的線程,遞減工作線程數,然後嘗試關閉線程池(如果當前任務就是線程池最後一個任務)
addWorkerFailed(w);
}
return workerStarted;
}
2. 任務對象Worker
根據上文,不難發現,在線程池中線程往往以 Worker 對象的方式存在,那麼這個 Worker 又是何方神聖?
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
// 工作線程
final Thread thread;
// 要執行的任務
Runnable firstTask;
// 線程執行過的任務數
volatile long completedTasks;
// 通過線程工廠創建工作線程
Worker(Runnable firstTask) {
setState(-1);
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
// 執行任務
public void run() {
runWorker(this);
}
... ...
}
這個 Worker 類繼承了 AQS,也就是說,他本身就相當於一個同步隊列,結合他的成員變量 thread 和 firstTask,可以知道他實際上就是我們線程池中所說的「線程」。除了父類 AQS 本身提供的獨佔鎖以外,Worker 還提供了一些檢查任務線程運行狀態以及中斷線程相關的方法。
此外,線程池中還有一個工作隊列 workers,用於保存當前全部的 Worker:
private final HashSet<Worker> workers = new HashSet<Worker>();
3.任務的啟動
當調用 Worker.run()的時候,其實調用的是 runWorker()方法。
runWorker()方法實際上就是調用線程執行任務的方法,他的邏輯大題是這樣的:
- 拿到入參的新 Worker,一直循環獲取 Worker 里的任務;
- 加鎖然後執行任務;
- 如果執行完任務流程,並且沒有發生異常導致 Worker 掛掉,就直接復用 Worker(在獲取任務的方法
getTask()中循環等待任務); - 如果執行完任務流程後發現發生異常導致 Worker 掛掉,就從工作隊列中移除當前 Worker,並且補充一個新的;
如果整個流程執行完畢,就刪除當前的 Worker。
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // 新創建的Worker默認state為-1,AQS的unlock方法會將其改為0,此後允許使用interruptIfStarted()方法進行中斷
// 完成任務以後是否需要移除當前Worker,即當前任務是否意外退出
boolean completedAbruptly = true;
try {
// 循環獲取任務
while (task != null || (task = getTask()) != null) {
// 加鎖,防止 shundown 時中斷正在運行的任務
w.lock();
// 如果線程池狀態為 STOP 或更後面的狀態,中斷線程任務
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
// 鉤子方法,默認空實現,需要自己提供
beforeExecute(wt, task);
Throwable thrown = null;
try {
// 執行任務
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 鉤子方法
afterExecute(task, thrown);
}
} finally {
task = null;
// 任務執行完畢
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
// 根據completedAbruptly決定是否要移除意外退出的Worker,並補充新的Worker
// 也就是說,如果上述過程順利完成,工作線程沒有掛掉,就不刪除,下次繼續用,否則就幹掉它再補充一個。
processWorkerExit(w, completedAbruptly);
}
}
4.任務的獲取與超時處理
在 runWorker()方法中,通過 getTask()方法去獲取任務。值得注意的是,超時處理也在此處,簡單的來說,整套流程是這樣的:
- 判斷線程池是否關閉,工作隊列是否為空,如果是說明沒任務了,直接返回null,否則接着往下判斷;
- 判斷當前是否存在非核心線程,如果是說明需要進行超時處理;
- 獲取任務,如果不需要超時處理,則直接從任務隊列獲取任務,否則根據 keepaliveTime 阻塞一段時間後獲取任務,如果獲取不到,說明非核心線程超時,返回 null 交給
runWorker()中的processWorkerExit()方法去刪除;
換句話說,runWorker()方法一旦執行完畢,必然會刪除當前的 Worker,而通過 getTask()拿任務的 Worker,在線程池正常運行的狀態下,核心線程只會一直在 for 循環中等待直到拿到任務,而非核心線程超時以後拿不到任務就會返回一個 null,然後回到 runWorker()中走完processWorkerExit()方法被刪除。
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
// 如果線程池關閉了,並且工作隊列里的任務都完成了,或者線程池直接進入了 STOP 或更進一步的狀態,就不返回新任務
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
// 獲取當前工作線程
int wc = workerCountOf(c);
// 核心線程是否超時(默認false)或當前是否存在非核心線程,即判斷當前當前是否需要進行超時控制
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
// 判斷線程是否超過最大線程數或存在非核心線程
if ((wc > maximumPoolSize || (timed && timedOut))
// 並且除非任務隊列為空,否則池中最少有一個線程
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
// 獲取任務
Runnable r = timed ?
// 阻塞 keepaliveTime 以獲取任務,如果在 keepaliveTime 時間內沒有獲取到任務,則返回 null.
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
// 如果獲取不到任務,說明非核心線程超時了,下一輪判斷確認是否退出循環。
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
四、線程池的中斷
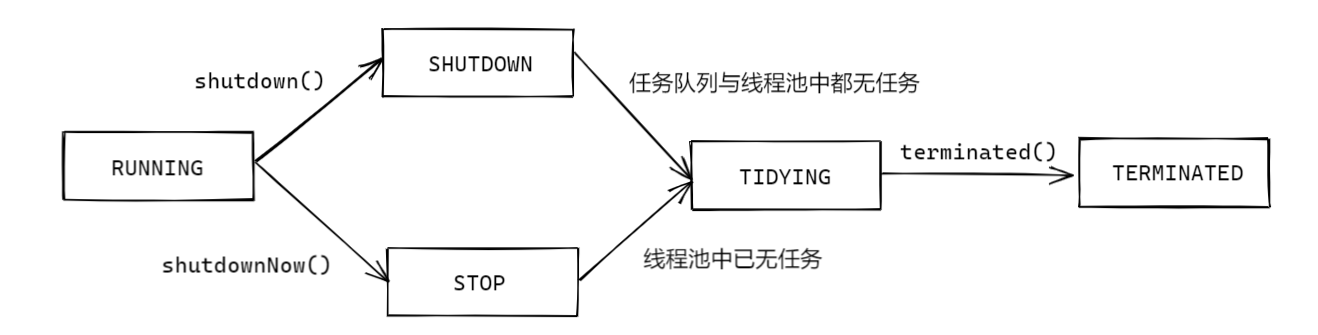
線程池的中斷方法分為三種:
shutdown():中斷線程池,不再添加新任務,同時等待當前進行和隊列中的任務完成;shutdownNow():立即中斷線程池,不再添加新任務,同時中斷所有工作中的任務,不再處理任務隊列中任務。
1.shutdown
shutdown 是有序關閉。主要幹了三件事:
- 改變當前線程池狀態為 SHUTDOWN;
- 將當前工作隊列中的全部線程標記為中斷;
- 完成上述過程後將線程池狀態改為 TIDYING
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
// 加鎖
mainLock.lock();
try {
checkShutdownAccess();
// 改變當前線程池狀態
advanceRunState(SHUTDOWN);
// 中斷當前線程
interruptIdleWorkers();
// 鉤子函數,默認空實現
onShutdown(); // hook for ScheduledThreadPoolExecutor
} finally {
mainLock.unlock();
}
tryTerminate();
}
其中,interruptIdleWorkers()方法如下:
private void interruptIdleWorkers(boolean onlyOne) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// 遍歷工作隊列中的全部 Worker
for (Worker w : workers) {
Thread t = w.thread;
if (!t.isInterrupted() && w.tryLock()) {
try {
// 標記為中斷
t.interrupt();
} catch (SecurityException ignore) {
} finally {
w.unlock();
}
}
if (onlyOne)
break;
}
} finally {
mainLock.unlock();
}
}
2.shutdownNow
shutdownNow() 與 shutdown()流程類似,但是會直接將狀態轉為 STOP,在 addWorker() 或者getTask()等處理任務的相關方法里,會針對 STOP 或更進一步的狀態做區分,將不會再處理任務隊列中的任務,配合drainQueue()方法以刪除任務隊列中的任務。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
// 改變當前線程池狀態
advanceRunState(STOP);
// 中斷當前線程
interruptWorkers();
// 刪除任務隊列中的任務
tasks = drainQueue();
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}
五、拒絕策略
當任務隊列已滿,並且線程池中線程也到達最大線程數的時候,就會調用拒絕策略。也就是reject()方法
final void reject(Runnable command) {
handler.rejectedExecution(command, this);
}
拒絕策略共分四種:
- AbortPolicy:拒絕策略,直接拋出異常,默認策略;
- CallerRunsPolicy:調用者運行策略,用調用者所在的線程來執行任務;
- DiscardOldestPolicy:棄老策略,無聲無息的丟棄阻塞隊列中靠最前的任務,並執行當前任務;
- DiscardPolicy:丟棄策略,直接無聲無息的丟棄任務;
我們可以簡單的了解一下他們的實現:
AbortPolicy
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
CallerRunsPolicy
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
r.run();
}
}
DiscardOldestPolicy
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
if (!e.isShutdown()) {
// 彈出隊頭元素
e.getQueue().poll();
e.execute(r);
}
}
DiscardPolicy
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
// Does nothing
}
六、線程池的鉤子函數
和 HashMap 與 LinkedHashMap 中的行為有點類似,在線程池的代碼中,有些方法調用了一些具有空實現的方法,這些方法是提供給用戶去繼承並重寫的鉤子函數,主要包括三個:
beforeExecute():在執行任務之前回調afterExecute():在任務執行完後回調terminated():在線程池中的所有任務執行完畢後回調
通過繼承 ThreadPoolExecutor 類,並重寫以上三個方法,我們可以進行監控或者輸出日誌,更方便的了解線程池的狀態。
值得一提的是,afterExecute()方法的入參類型是(Runnable r, Throwable t),也就是說,如果線程運行中拋出異常,我們也可以通過該方法去捕獲異常並作出相應的處理。
七、總結
線程池提供了四個構造方法,參數最全的構造方法參數按順序有:核心線程數,最大線程數,非核心線程閑置存活時間,存活時間單位,任務隊列,線程工廠,拒絕策略。
線程池共有五種狀態,分別是:RUNNING,SHUTDOWN,STOP,TYDYING,TERMINATED,它們與工作線程數量一同記錄在成員變量 ctl 中,其中高 3 位用於記錄狀態,低 29 位用於記錄工作線程數,實際使用中通過位運算去獲取。
線程池中任務線程以繼承了 AQS 的 Worker 類的實例形式存在。當添加任務時,會有四種情況:核心線程不滿,優先創建核心線程;核心線程滿,優先添加任務隊列;核心線程與隊列都滿,創建非核心線程;線程和隊列都滿,則執行拒絕策略。
其中,拒絕策略分為四類,默認的拒絕策略 AbortPolicy;調用者運行策略 CallerRunsPolicy;棄老策略 DiscardOldestPolicy;丟棄策略 DiscardPolicy。
線程池的中斷有兩個方法:shutdown()與 shutdownNow(),兩者都會讓線程池不再接受新任務,但是 shutdown()會等待當前與任務隊列中的任務執行完畢,而 shutdownNow()會直接中斷當前任務,忽略並刪除任務隊列中的任務。
線程池提供了beforeExecute(),afterExecute(),terminated()三個鉤子函數,其中,afterExecute()的入參含有拋出的異常,因此可以藉由該方法處理線程池中線程拋出的異常。

