統計學三大相關性係數:pearson,spearman,kendall
- 2021 年 2 月 14 日
- 筆記
目錄
-
- person correlation coefficient(皮爾森相關性係數-r)
- spearman correlation coefficient(斯皮爾曼相關性係數-p)
- kendall correlation coefficient(肯德爾相關性係數-k)
- R語言計算correlation
在文獻以及各種報告中,我們可以看到描述數據之間的相關性:pearson correlation,spearman correlation,kendall correlation。它們分別是什麼呢?計算公式?怎樣用R語言簡單實現計算呢?本文一一介紹~
建議前期閱讀:協方差與相關係數-「傻傻」也能分清
總的來講,三個相關性係數(pearson, spearman, kendall)反應的都是兩個變量之間變化趨勢的方向以及程度,其值範圍為-1到+1,0表示兩個變量不相關,正值表示正相關,負值表示負相關,值越大表示相關性越強
person correlation coefficient(皮爾森相關性係數-r)
公式: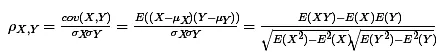
兩個變量(X, Y)的皮爾森相關性係數(ρX,Y)等於它們之間的協方差cov(X,Y)除以它們各自標準差的乘積(σX, σY)。(分母是變量的標準差,這就意味着變量的標準差不能為0(分母不能為0),也就是說你每個變量所包含值不能都是相同的。如果沒有變化,方差為0,那麼是無法計算的)
方差是表示一個變量的波動情況,方差越小表示數據越集中,越大表示數據越離散;
標準差:等於(或近似等於)方差的開根號;
協方差:可以理解成兩個變量之間的方差,其取值可以是負無窮到正無窮,它可以表示兩個變量之間的變化趨勢,但是不能表示它們之間的程度
局限性:
- 實驗數據通常假設是成對的來自於正態分佈的總體。為啥通常會假設為正態分佈呢?因為我們在求皮爾森相關性係數以後,通常還會用t檢驗之類的方法來進行皮爾森相關性係數檢驗。
- 實驗數據之間的差距不能太大,或者說皮爾森相關性係數受異常值的影響比較大。因為根據公式可以看到是直接是用x,y的值進行計算。相對應的spearman correlation對異常值不敏感,因為它是屬於rank test,具體見下面介紹。
spearman correlation coefficient(斯皮爾曼相關性係數-p)
通常也叫斯皮爾曼秩相關係數。
「秩」,可以理解成就是一種順序或者排序,那麼它就是根據原始數據的排序位置進行求解,而不是直接是用x,y的值進行求解(因此對異常值不敏感,也不要求正態分佈)。
公式: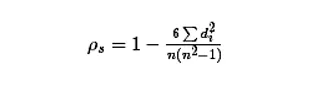
計算過程就是:
- 獲得秩次:記下原始X Y值得排序位置(X』, Y』),(X』, Y』)的值就稱為秩次
- 對兩個變量(X, Y)的數據進行排序
- 計算兩個變量秩次的差值,也就是上面公式中的di,n就是變量中數據的個數
- 最後帶入公式就可求解結果。
舉個例子吧,假設我們實驗的數據如下: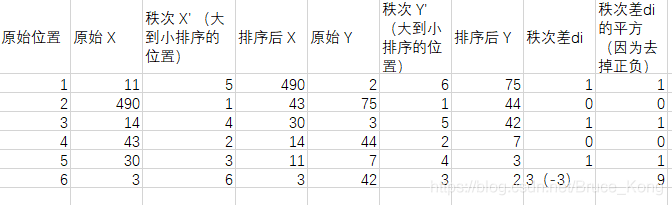

帶入公式,求得斯皮爾曼相關性係數:ρ(s)= 1-6*(1+1+1+9)/6*35=0.657
不用管X和Y這兩個變量具體的值到底差了多少,只需要算一下它們每個值所處的排列位置的差值,就可以求出相關性係數了。(如果原始數據中有重複值,則在求秩次時要以它們的平均值為準)
優勢:
- 即便在變量值沒有變化的情況下,也不會出現像皮爾森係數那樣分母為0而無法計算的情況。
- 即使出現異常值,由於異常值的秩次通常不會有明顯的變化(比如過大或者過小,那要麼排第一,要麼排最後),所以對斯皮爾曼相關性係數的影響也非常小
- 斯皮爾曼相關性係數沒有那些數據條件要求,適用的範圍廣
pearson和spearman都是衡量連續型變量間的相關性,那麼如果是分類變量呢?
kendall correlation coefficient(肯德爾相關性係數-k)
肯德爾相關性係數,又稱肯德爾秩相關係數,它也是一種秩相關係數,不過它所計算的對象是分類變量。分類變量可以理解成有類別的變量,可以分為無序的,比如性別(男、女)、血型(A、B、O、AB),以及有序的,比如肥胖等級(重度肥胖,中度肥胖、輕度肥胖、不肥胖)。通常需要求相關性係數的都是有序分類變量。
例子:比如評委對選手的評分(優、中、差等),我們想看兩個(或者多個)評委對幾位選手的評價標準是否一致;或者醫院的尿糖化驗報告,想檢驗各個醫院對尿糖的化驗結果是否一致,這時候就可以使用肯德爾相關性係數進行衡量。
由於數據情況不同,求得肯德爾相關性係數的計算公式不一樣,一般有3種計算公式,在這裡就不繁瑣地列出計算公式了,具體感興趣的話可以自行搜尋資料。
R語言計算correlation
x <- c(seq(10))
y <- c(seq(11,20))
res <- cor.test(x, y,method = "pearson") # method 參數修改:「spearman","kendall"
# 具體見 ?cor.test
參考鏈接:聊聊統計學三大相關性係數


