實現基於股票收盤價的時間序列的統計(用Python實現)
時間序列是按時間順序的一組真實的數字,比如股票的交易數據。通過分析時間序列,能挖掘出這組序列背後包含的規律,從而有效地預測未來的數據。在這部分里,將講述基於時間序列的常用統計方法。
1 用rolling方法計算移動平均值
當時間序列的樣本數波動較大時,從中不大容易分析出未來的發展趨勢的時候,可以使用移動平均法來消除隨機波動的影響。可以說,移動平均法是針對時間序列的常用分析方法,其基本思想是,根據時間序列樣本數據、逐步向後推移,依次計算指定窗口序列的平均值。
股票的移動平均線是個比較常見的範例,通過它可以分析未來股價的走勢。從技術上來講,可以通過pandas的rolling方法,以指定時間窗口的方式來計算移動均值,在如下的CalMA.py範例中,就將演示通過收盤價,演示通過rolling方法計算移動平均線的做法。
1 #coding=utf-8
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 filename='D:\\work\\data\\ch9\\6007852019-06-012020-01-31.csv'
5 df = pd.read_csv(filename,encoding='gbk',index_col=0)
6 fig = plt.figure()
7 ax = fig.add_subplot(111)
8 df['Close'].plot(color="green",label='收盤價')
9 df['Close'].rolling(window=5).mean().plot(color="red",label='5日均線')
10 plt.legend(loc='best') # 繪製圖例
11 ax.grid(True) # 帶網格線
12 plt.title("演示時間序列的移動平均線")
13 plt.rcParams['font.sans-serif']=['SimHei']
14 plt.setp(plt.gca().get_xticklabels(), rotation=30)
15 plt.show()在這個範例中,用到了matplotlib可視化控件,具體而言,在通過第5行的代碼從csv文件得到數據後,先是通過第8行的plot方法,依次連接df對象里每天收盤價的點,從而繪製了描述「收盤價」的折線。
在第9行rolling方法里,通過window參數指定了移動分析的窗口是5天,再結合mean方法,繪製了基於收盤價的5天移動平均線。請注意在第8行和第9行繪製兩條折線時,均通過label參數設置了圖例,所以在之後的第10行里,能通過legend方法設置圖例效果。
另外值得注意的可視化細節還有,在第11行里,通過grid方法設置了網格線,通過第12行和第13行的代碼設置了中文標題,在第14行里指定了x軸坐標文字標籤需要旋轉30度。
運行上述代碼,大家能看到如下圖所示的效果。如果對比其中的收盤價和移動平均線,會發現後者平滑了許多,從中大家能感受到,基於時間序列的移動平均線能一定程度消除隨機性的波動,能更有效地展示樣本數據的波動趨勢。
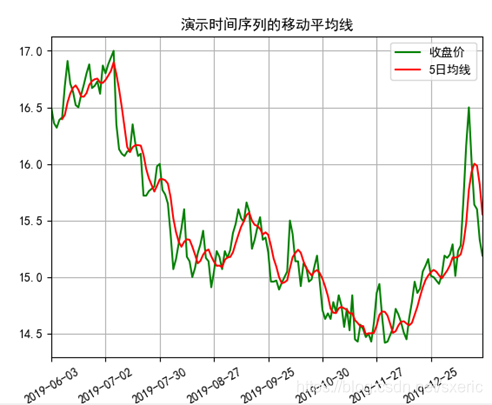
2 收盤價基於時間序列的自相關性分析
相關性是指兩組數據間是否有關聯,即一組數據的變動是否會影響到另一組數據。而自相關性,則是指同一個時間序列上兩個不同點的變量間是否有關聯。
這裡還是拿股票收盤價舉例,在這個場景里,自相關性是指兩個交易日的收盤價之間是否有關聯性。和相關性一樣,自相關性同樣是用-1到1的一個數來表示,其中0同樣表示不相關,1同樣表示完全相關,-1則表示完全反向相關。自相關性在統計學上有什麼意義呢?
- 如果時間序列上,兩個相近的值不相關,即相關係數為0,則表示該時間序列上的各個點間沒有關聯,那麼就沒有必要再通過觀察規律來預測未來的數據。具體在股票收盤價案例上,如果本交易日收盤價和上個交易日收盤價間沒有關聯,那麼就沒必要再分析之前交易日的收盤價來預測未來交易日的收盤價。也就是說,只有當時間序列上不同點的值之間有相關性,才有必要分析過去的規律,以此來推算未來的值。
- 平穩序列的自相關係數應當很快會收斂(或叫衰減)到零。平穩序列是指,該時間序列里數據的變動規律會基本維持不變,這樣才可以用從過去數據里分析出的規律來推算出未來的值。在股票收盤價案例中,當天收盤價可以和未來一周內的收盤價有關聯,但在平穩序列里,當天收盤價和未來長遠的(假設是50天)某天收盤價沒關聯。相反則說明任何一天收盤價的變動會影響很長一段時間,日積月累,那麼在預測未來某天收盤價時還要考慮過去太多影響時間很長的規律,那麼該時間序列的變動規律就會變得過於複雜,從而會導致不可測,
也就是說,針對一個時間序列,只有當該序列里相近時間的數據有關聯,且間隔很長的數據間無關聯,該序列才有被統計分析的意義。自相關性的算法不簡單,不過可以通過statsmodels庫里封裝的方法來計算時間序列里的自相關性。
在使用這個庫前,依然需要通過pip3 install statsmodels的命令來安裝,作者安裝的是當前最新的0.11.1版本。安裝後,為了能正確使用,還需要安裝mkl和scipy庫。在如下的AcfDemo.py範例中,將通過股票收盤價的案例,讓大家直觀地感受到時間序列里的自相關性。
1 #coding=utf-8
2 import pandas as pd
3 import statsmodels.api as stats
4 filename='D:\\work\\data\\ch9\\6007852019-06-012020-01-31.csv'
5 df = pd.read_csv(filename,encoding='gbk',index_col=0)
6 stats.graphics.tsa.plot_acf(df['Close'],use_vlines=True,lags=50, title = 'ACF Demo')在第3行里,引入了計算自相關係數的statsmodels庫,在第5行里,從指定的文件里讀到股票收盤價的數據,並在第6行,通過stats.graphics.tsa.plot_acf方法來計算並繪製收盤價的相關性係數的圖表。
該方法的use_vlines參數表示是否要設置點到x軸的連線,這裡取值是True,表示需要設置,lags參數表示計算當天數據到後面50天的自相關係數,而title參數則表示該圖表的標題。運行本範例,能看到如下圖所示的效果。
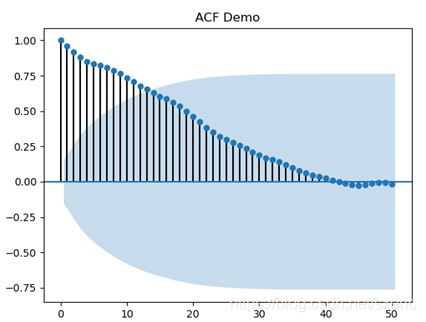
從上圖中能看到,x軸的刻度從0到50,這和lags參數的取值相匹配,而y軸的刻度從-1到1,表示自相關性的係數。再進一步分析,從上圖裡能看出如下的統計方面的意義。
- x軸取值為0的自相關係數是1,表示當天數據和自身完全相關。
- x軸靠近0的一些自相關係數非常接近1,再如,第13天和第14天第15天的自相關係數相對差別不大,這說明當天收盤價對未來近期的收盤價有一定的影響。
- 隨着x軸取值的變大,自相關係數是逐步衰減的,當在靠近40的位置基本衰減為0。這說明某天收盤價的變動不會對長遠未來的數據有影響,進而說明該序列是平穩的。
- 除了描述自相關係數的點和線之外,還有描述95%置信區間的藍色區域,從圖上看出,13天的自相關係數約是0.7,同時落在了藍色區域內。這表示第1天和第13天數據的自相關係數有95%的可信度,而之前沒達到95%的可信度。之前沒達到95%可信度的原因是,在本場景里的數據是從2019年6月1日開始的,實際場景里,該交易日的收盤價會受之前數據影響,但這裡數據只從6月1日開始,所以就丟失了和之前數據的關聯,從而導致可信度下降。
- 再觀察落在95%置信區間里的第13、第14和第15天的自相關係數,它們的相對差別並不大。
綜上所述得出的結論是,基於時間序列的該股收盤價,在比較短的周期內具有一定的自相關性,且可信度達到或高於95%,且該序列是平穩的,所以有分析該股收盤價序列的必要,從中得到的規律能一定程度上預測未來的走勢。對於其它的時間序列,也可以照此步驟分析其自相關性,並能照此方式得出對應的結論。
3 收盤價基於時間序列的偏自相關性分析
從上例中可以看到,如果基於時間序列的數據具有自相關性,那麼這種自相關性非常有可能會傳遞,即第n天的數據受第n-1天數據的影響,而第n-1天的數據受n-2天的影響,再以此類推,第n天的數據就有可能受之前若干數據的綜合影響。具體到收盤價的案例,即當天收盤價不僅會受前一個交易日的影響,更會間接地受之前若干個交易日的影響。
在某些統計場景里,需要剔除更早數據的間接影響,只衡量之前數據對當前數據的直接影響,這就可以用到「偏自相關係數」。
「偏自相關係數」的計算過程相當複雜,根據算法,已經剔除其中自相關係數包含的「間接影響」,在實際應用中,也可以通過調用statsmodels庫里的相關方法來實現,在如下的PacfDemo.py範例中,就將演示計算並繪製偏自相關係數的做法。
1 #coding=utf-8
2 import pandas as pd
3 import statsmodels.api as stats
4 filename='D:\\work\\data\\ch9\\6007852019-06-012020-01-31.csv'
5 df = pd.read_csv(filename,encoding='gbk',index_col=0)
6 stats.graphics.tsa.plot_pacf(df['Close'],use_vlines=True,lags=50, title = 'PACF Demo')本範例和之前求自相關性的範例很相似,差別是在第6行,調用了plot_pacf方法計算並繪製偏自相關係數,運行本範例,能看到如下圖所示的效果。
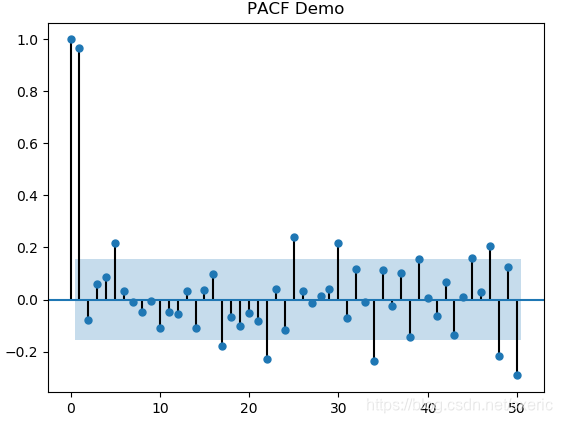
除去開始的兩個數據,大多數數據落在藍色的95%置信區間內,且偏自相關係數約在-0.15到0.15之間。這說明如果剔除更早交易日數據的影響,單純看當天和後一個交易日的收盤價,它們的相關度約在0.15左右,這個結論有95%的可信度。再綜合自相關係數,說明再預測未來的收盤價時,不能僅僅考慮前一個交易日的影響,還要引入更早交易日收盤價作為參考因素。
4 用熱力圖分析不同時間序列的相關性
之前是通過自相關係數和偏自相關係數來衡量單一時間序列里前後數據間的影響,在應用中,也會量化分析不同時間序列的相關性。
比如在制定股票的配對交易策略時,會量化計算不同股票收盤價之間的相關性,如果它們的正向相關性強,則說明它們的走勢規律非常相似。在本小節里,會以熱力圖的形式,向大家展示如下表所示的股票收盤價之間的的相關性。
表 分析相關性的股票信息一覽表
|
股票代碼 |
股票名稱 |
所屬板塊 |
|
603005 |
晶方科技 |
半導體 |
|
600360 |
華微電子 |
半導體 |
|
600640 |
號百控股 |
互聯網傳媒 |
在如下CompareCorrByHeatMap.py範例中,將首先從網絡接口裡抓取指定股票的數據,在此基礎上計算股票間的相關度,並以熱力圖的形式直觀地展示不同時間序列間相關性的效果。
1 #coding=utf-8
2 import pandas as pd
3 import matplotlib.pyplot as plt
4 import pandas_datareader
5 # 603005 晶方科技 半導體
6 # 600360 華微電子 半導體
7 # 600640 號百控股 互聯網傳媒
8 stockCodes = ['603005', '600360', '600640']
9 start='2019-12-01'
10 end='2020-01-31'
11 stockCloseDF = pd.DataFrame()
12 for code in stockCodes:
13 thisClose = pandas_datareader.get_data_yahoo(code + '.ss', start, end)
14 stockCloseDF[code] = thisClose['Close'].values
15 #print(stockCloseDF) #可以觀察結果
16 fig = plt.figure()
17 ax = fig.add_subplot(111)
18 ax.set_xticklabels(stockCodes)
19 ax.set_xticks(range(len(stockCodes)))
20 ax.set_yticklabels(stockCodes)
21 ax.set_yticks(range(len(stockCodes)))
22 im = ax.imshow(stockCloseDF.corr(), cmap=plt.cm.hot_r)
23 # 添加顏色刻度條
24 plt.colorbar(im)
25 # 添加中文標題
26 plt.rcParams['font.sans-serif']=['SimHei']
27 plt.title("用熱力圖觀察股票間的相關性")
28 plt.xlabel('股票代碼')
29 plt.ylabel('股票代碼')
30 plt.show()在第8行的stockCodes變量里,定義了待分析的股票代碼,這些股票的具體信息請參考第5行到第7行的注釋,同時在第9行和第10行的代碼里,定義待分析股票的開始和結束日期。
隨後在第12行到第14行的for循環里,依次遍歷股票代碼,並從網絡接口得到對應的數據,並在第14行把三個股票的收盤價放入DataFrame類型的stockCloseDF對象里。至此完成數據的準備工作,大家也可以打開第15行的注釋,通過print語句觀察結果。
在得到數據後,會在第22行和第24行的代碼里,兩兩計算各股間的相關性,並繪製成熱力圖,並在右邊顯示圖例性質的顏色刻度條。運行本範例,能看到如下圖所示的效果。
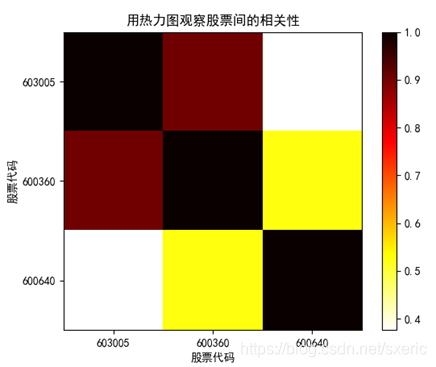
從上圖裡能看到,x軸和y軸刻度都是股票代碼,兩兩比對後,自身的相關性都是1,而603005(晶方科技)和600360(華微電子)均屬於半導體板塊,所以它們間的相關性比較高,而600640(號百控股)屬於互聯網傳媒板塊,所以它和其它兩個股票的相關性就很低。
本文出自我寫的書: Python爬蟲、數據分析與可視化:工具詳解與案例實戰,//item.jd.com/10023983398756.html

請大家關注我的公眾號:一起進步,一起掙錢,在本公眾號里,會有很多精彩文章。



