從官方文檔中探索MySQL分頁的幾種方式及分頁優化
- 2021 年 2 月 2 日
- 筆記
概覽
相比於Oracle,SQL Server 等數據庫,MySQL分頁的方式簡單得多了,官方自帶了分頁語法 limit 語句:
select * from test_t LIMIT {[offset,] row_count | row_count OFFSET offset}
例如:要獲取第12行到第21行的記錄可以這樣寫:
select * from test_t limit 11,10;
或者
select * from test_t limit 10 offset 11;
當然簡單的用法可以這樣使用,但是如果遇到數據量比較大的情況下和分頁在中間或後面部分的話,這樣使用會有性能問題。等會再看一下優化後的另外一種分頁方式。
從官網中探索
想着
limit語句既然是官方語言,那樣官方文檔中一定會有的介紹MySQL分頁的方式和優化的相關的建議吧,後面我看了一下其實與想像中的有挺大差別的,官方文檔不是很全面🤐
關於MySQL 分頁方式的官方文檔解讀
先來看看官網文檔中是怎麼樣描述 limit語句的 :
The LIMIT clause can be used to constrain the number of rows returned by the SELECT statement. LIMIT takes one or two numeric arguments, which must both be nonnegative integer constants, with these exceptions:
Within prepared statements, LIMIT parameters can be specified using ? placeholder markers.
Within stored programs, LIMIT parameters can be specified using integer-valued routine parameters or local variables.
來自://dev.mysql.com/doc/refman/5.6/en/limit-optimization.html
翻譯成中文,大概意思就是:「limit 語句可以用到 select 語句中去限制返回結果的行數。limit 子語句可以帶一個或兩個參數,這些參數都必須是非負整數常量,但有以下例外:一個是預執行語句中可以用?替代,另外一個是在存儲程序中用表達式替代」
簡單來說,就是 limit 是用來限制查詢返回行數的(這裡舉例的是 select 語句中limit的用法,在update 等語句中也有相關 limit 的介紹,大概類似)。
好吧,講了等會沒講🤣
接着,在官網文檔中舉例了 limit 的一些簡單用法示例,還有一些其他說明。
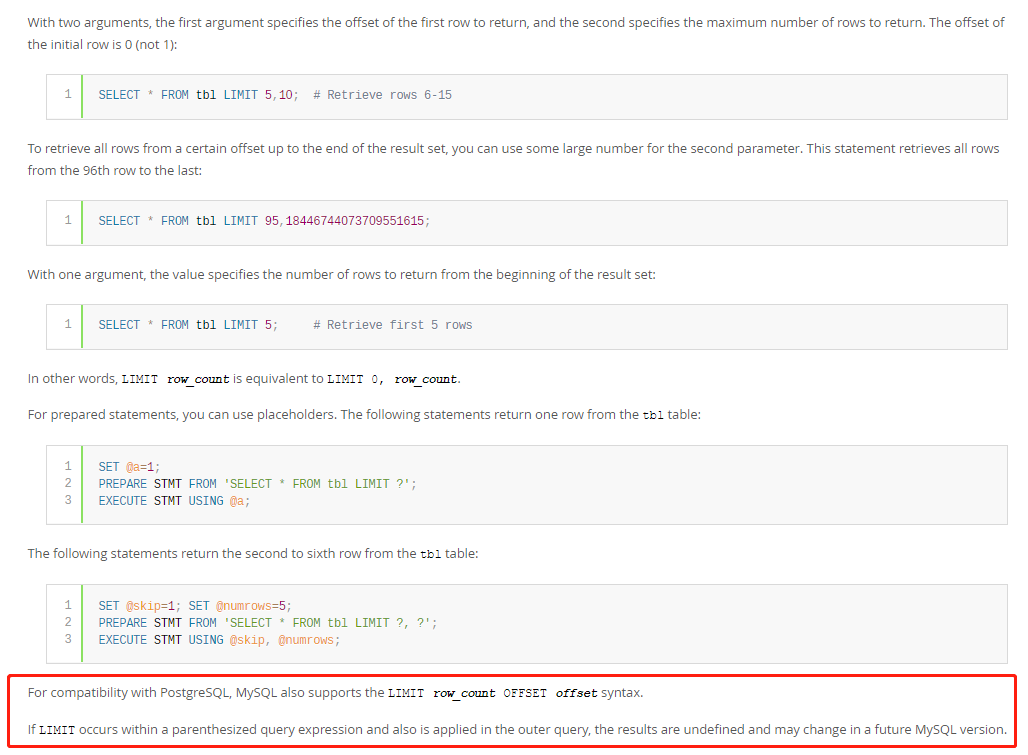
可以重點關注下後面紅框部分的兩句描述。
第一句為:為了兼容PostgreSQL,MySQL 也支持 limit offset 這種方式的語句
這裡說的是,MySQL 分頁 除了可以這樣寫
select * from test_t limit 11,10
也可以這樣寫
select * from test_t limit 10 offset 11
offset 這種方式,我之前還真沒見過MySQL這樣用的😂,又得到一個冷知識。
至於為什麼需要兼容 PostgreSQL ,我搜了一下網上資料,估計是 當時PostgreSQL 很火,可以讓用戶沒有什麼成本就遷移到MySQL上
第二句為:如果LIMIT出現在帶圓括號的查詢表達式中,並且也應用在外部查詢中,則查詢的結果未準確定義,並且可能在將來的MySQL版本中更改。
這裡說的就是,例如這樣的 SQL 結果有可能以後會發生變化:
SELECT * FROM d_comment WHERE id IN (SELECT id FROM `d_app_info` ORDER BY id LIMIT 1,10) ORDER BY id LIMIT 0,10
挺懷疑它這裡的描述的,這樣的用法不是很正常嗎?🙄會有什麼影響嗎?。我這裡的用的是MySQL 5.6(2013年)版本的文檔,於是我切換到的MySQL 5.8(2020年)的版本,發現這裡的描述還是不變🙃。過了7年這裡的描述還是沒變,這以後都應該不會變化了吧。。。
但是當我執行上面的 SQL的時候,papa打臉了

提示這個錯誤:
This version of MySQL doesn't yet support 'LIMIT & IN/ALL/ANY/SOME subquery'
於是又去搜索了一下,發現在官方文檔中就說明了,就不能這樣使用
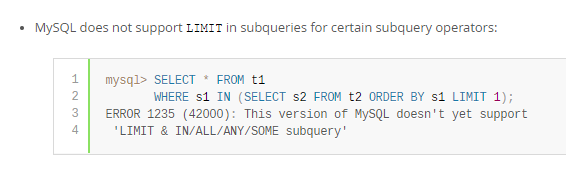
來自://dev.mysql.com/doc/refman/8.0/en/subquery-restrictions.html
需要改寫成這樣,嵌多一層子查詢:
SELECT id,dt FROM d_comment WHERE id IN ( SELECT * FROM (SELECT id FROM `d_app_info` ORDER BY app_name,id LIMIT 1,10) t2 ) ORDER BY id LIMIT 0,10;
或者用多表關聯查詢來解決(這種方式在分頁數量多的時候性能更好些)
SELECT a.id,a.dt FROM d_comment a , (SELECT id FROM `d_app_info` ORDER BY app_name,id LIMIT 1,10) b WHERE a.id=b.id ORDER BY a.id ;
然後,我與外層沒有 limit 的 SQL 執行對比了一下:
SELECT id,dt FROM d_comment WHERE id IN ( SELECT * FROM (SELECT id FROM `d_app_info` ORDER BY app_name,id LIMIT 1,10) t2 ) ORDER BY id ;
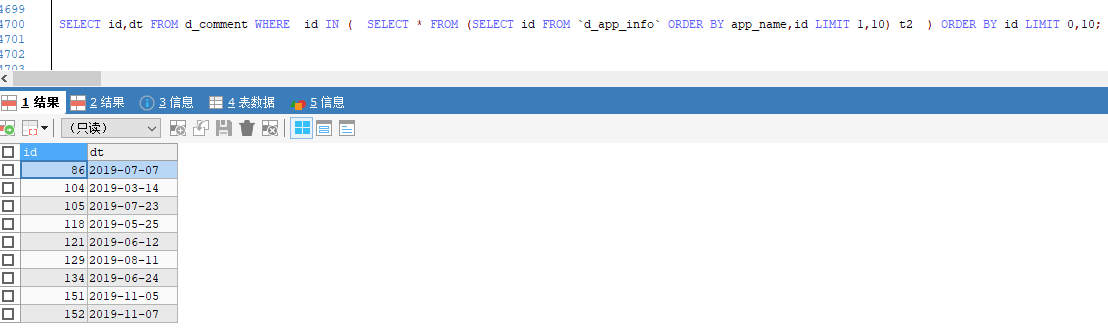
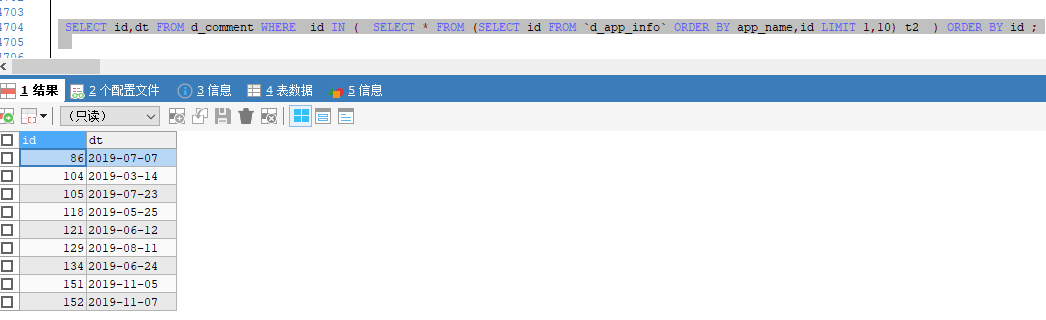
結果是一樣的,與預想的一樣,這裡的應該是不需要管了🙃,除了注意一下要嵌套多一層
關於MySQL limit 優化相關的官方文檔解讀
想着官方文檔上也會有分頁相關優化的介紹,於是在官方文檔的搜索欄輸入 limit 或 page 上搜索了一下,發現與 limit 優化相關的只有以下這個:
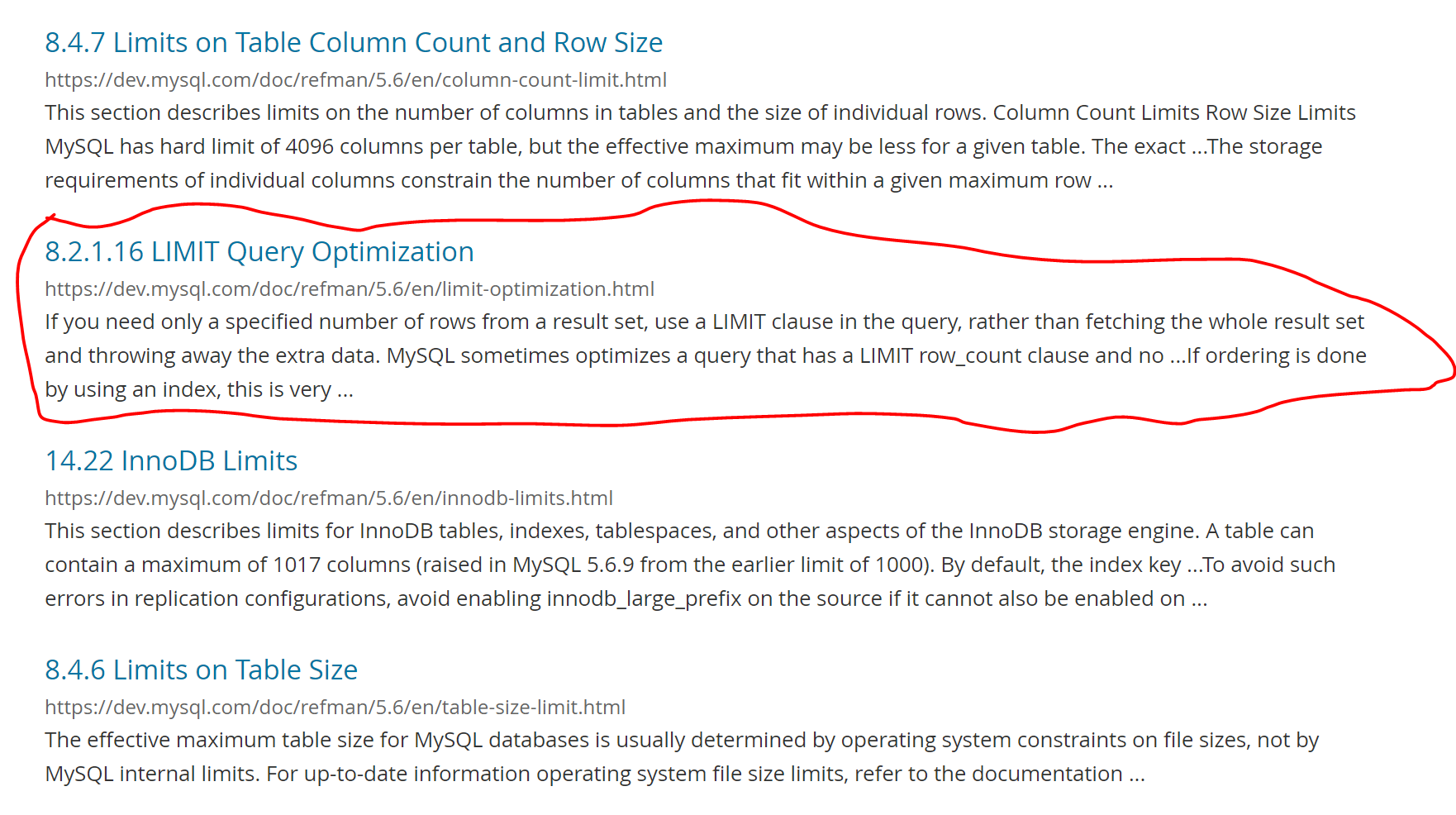
LIMIT Query Optimization
If you need only a specified number of rows from a result set, use a LIMIT clause in the query, rather than fetching the whole result set and throwing away the extra data.
MySQL sometimes optimizes a query that has a LIMIT row_count clause and no HAVING clause:
引用自://dev.mysql.com/doc/refman/5.6/en/limit-optimization.html
官方文檔,這部分主要介紹的在包含limit row_count 這種語句的各種類型查詢的情況下,MySQL會做了哪些優化。其中大部分是用不到的,這裡重點介紹一下2種比較有趣的特點。
一,查詢總行數的另一種方法
查詢分頁的總行數,我們一般情況下是使用的, select count(*) 去實現的。文檔中介紹了另外一種方式,通過 select FOUND_ROWS(); 語句,不過這種方式的需要修改獲取limit 數據的SQL 。例如:如果在SQL中同時執行這兩條語句,就可以分別獲取到分頁的數據和分頁總行數。
# 這個SQL 比平時的分頁SQL 多了 SQL_CALC_FOUND_ROWS 修飾
SELECT SQL_CALC_FOUND_ROWS id,`name` FROM `d_common_all_select_info` ORDER BY `name` LIMIT 0,10;
# 這條SQL返回的為總行數,不過統計方式與select count(*) 有些不同,另外需要與上面的SQL 同時執行
SELECT FOUND_ROWS();
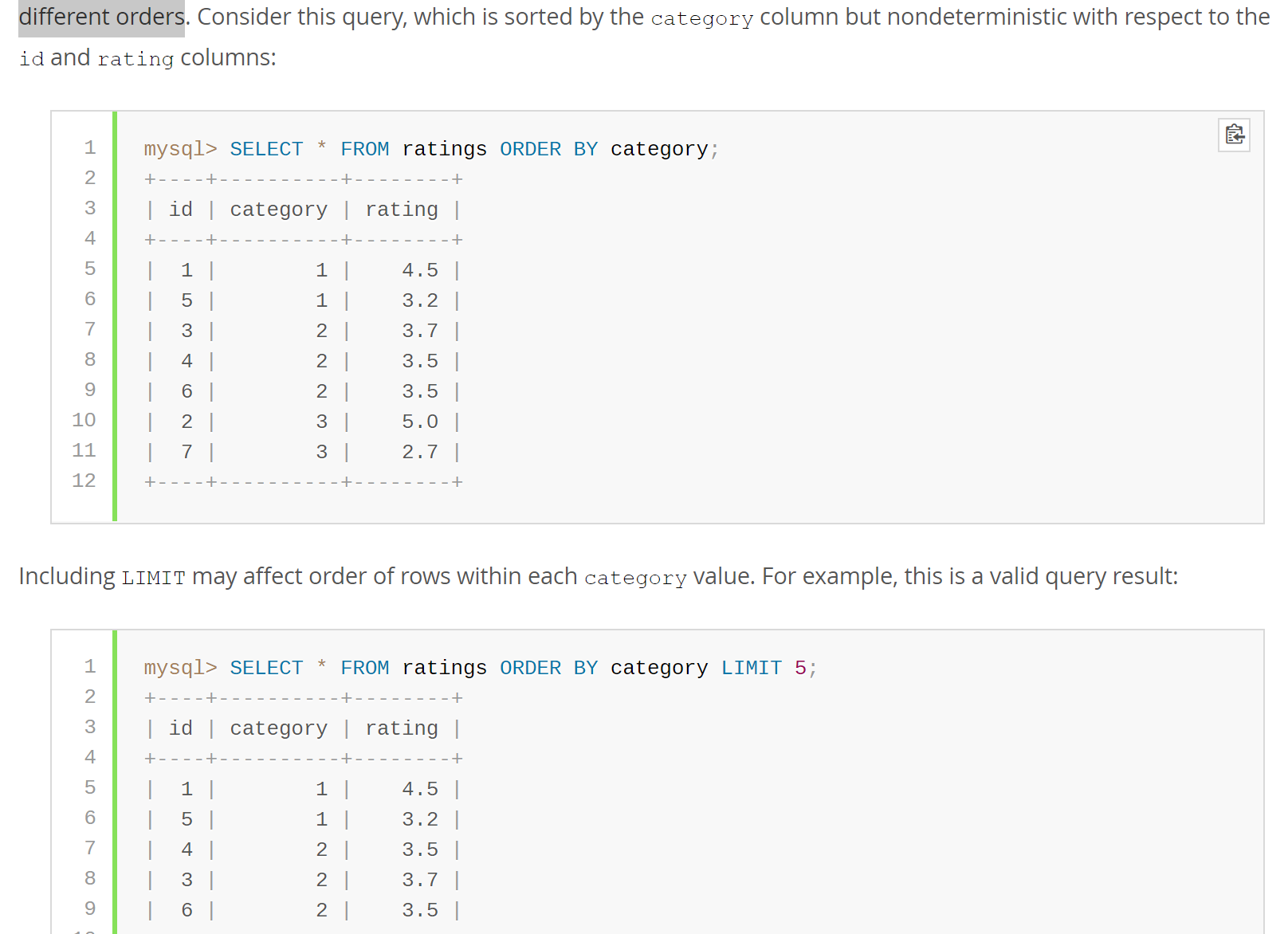
二,查詢的order by 的順序問題
If multiple rows have identical values in the ORDER BY columns, the server is free to return those rows in any order, and may do so differently depending on the overall execution plan. In other words, the sort order of those rows is nondeterministic with respect to the nonordered columns.
One factor that affects the execution plan is LIMIT, so an ORDER BY query with and without LIMIT may return rows in different orders
翻譯過來並簡單來說就是,如果order by 中包含相同的值,則order by出來的結果不一定每次一樣,它返回的順序與總體執行計劃有關。例如,帶limit 和不帶limit的order by 語句,返回順序不一樣的。
所以如果order by 的列包含相同值的時候,保證每次都是相同的結果,最好在最後的加上id列(這裡假設自增id列名為id)。例如:平常要order by dt 的,然後dt中會包含相同值的最好修改為 order by dt,id
MySQL 分頁優化的兩種方法
經過多次在官方文檔中查找,沒有發現其他關於 MySQL 分頁優化的描述,但是如果在表數據量大的時候,直接使用 limit offset, row_num 這種方式去查詢的會很慢的。所以這裡再介紹一下MySQL 分頁查詢的另一種方式,並與原方式進行一些對比。
普通的limit offset,row_num 方式,會先從數據文件中查到offset + row_num 記錄,然後把前 offset 記錄拋棄掉返回的。例如:limit 1000,10 ,會從數據文件中查詢1010 行記錄,只返回的10記錄,前1000行記錄會被拋棄掉。為了優化這種的大偏移的查詢的,主要有兩種方法:延遲關聯 和 書籤記錄。其中延遲關聯應用的業務場景更加廣泛。
這裡使用一張測試表 page_test_t 來進行測試,表的行數如下(大約110萬行):
-- 查詢錶行數
SELECT TABLE_NAME, PARTITION_NAME, TABLE_ROWS, AVG_ROW_LENGTH, DATA_LENGTH FROM INFORMATION_SCHEMA.PARTITIONS WHERE TABLE_NAME='page_test_t' ;

這裡假設將 offset 設置為 600000,取 10 行記錄來對比各個分頁方法之間的查詢速度
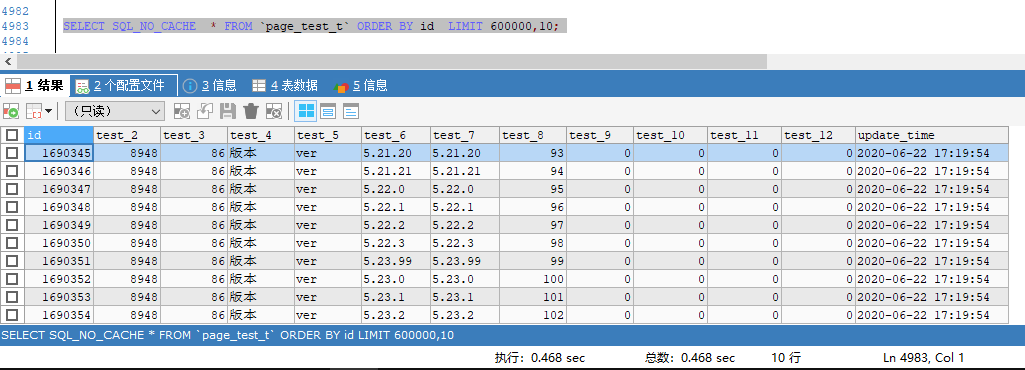
普通分頁
普通分頁,直接使用 limit offset,row_num 去查詢
SELECT SQL_NO_CACHE * FROM `d_common_all_select_info` ORDER BY id LIMIT 600000,10;
查詢10次,查詢結果與以下結果相差不超過0.01s,查詢時間耗時穩定在 0.46 s
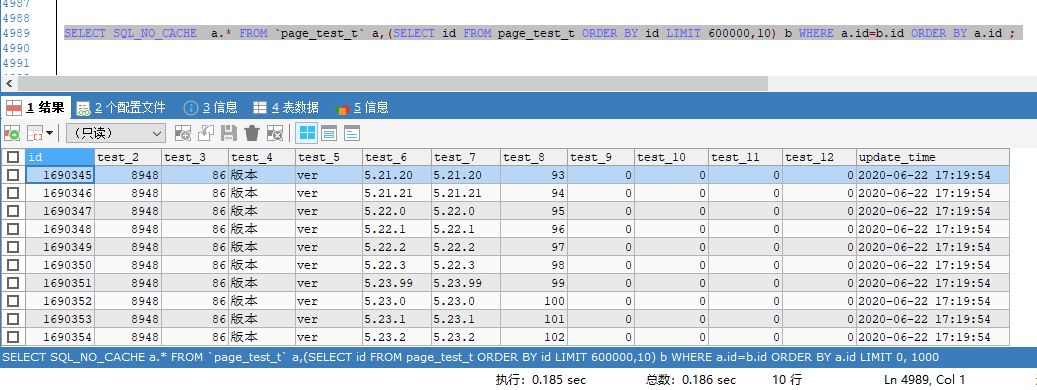
延遲關聯
可以先按照條件分頁查詢出主鍵,然後根據主鍵的再去關聯表,查詢出所有需要列的記錄數,這樣可以避免掃描太多的數據頁。按照要求條件,可以寫出這樣的例子 SQL:
SELECT SQL_NO_CACHE a.* FROM `page_test_t` a,(SELECT id FROM page_test_t ORDER BY id LIMIT 600000,10) b WHERE a.id=b.id ORDER BY a.id ;
查詢10次,查詢結果與以下結果相差不超過0.01s,查詢時間耗時穩定在 0.18 s
書籤記錄
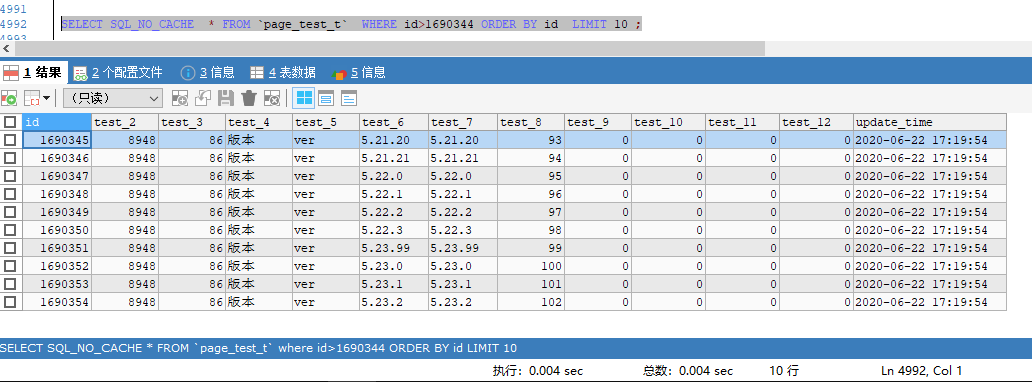
「書籤記錄」指我們可以用一個臨時變量來存儲上一次取數記錄的位置,然後在獲取下一頁的時候,可以根據這個值,來獲取大於這個值的下一頁記錄(上一頁類似),直接從該值以後開始掃描。例如,假設我們上一次獲取到了分頁 limit 599990,10 的記錄,最大的值的id為 1690344(這裡的值作為了一個書籤記錄),則我們獲取 limit 600000,10 的記錄可以這樣寫:
SELECT SQL_NO_CACHE * FROM `page_test_t` where id>1690344 ORDER BY id LIMIT 10 ;
查詢10次,查詢結果與以下結果相差不超過0.01s,查詢時間耗時穩定在 0.004 s
小結
可以看到,延遲關聯 比 普通分頁方式查詢速度快了近3倍,「書籤記錄」比普通分頁方式快了近100倍。不過「書籤記錄」只適合只有前翻頁,後翻頁這種類型的分頁交互,不能跳轉到任意頁碼,延遲關聯則可以支持,所以一般情況下,我們都可以使用延遲關聯方式來替換原普通分頁的方式。
除了這兩種方法,還有例如使用預先計算的匯總表 或者關聯到另外一張冗餘表,冗餘表中包含表的主鍵和需要做排序的數據列 等方法去優化分頁。 參考自:《高性能MySQL(第三版)》
總結
本文從SQL 的 limit 分頁語句出發,詳細介紹了 limit 的語法及簡要的概括了MySQL 官方文檔對 limit 的優化,另外對比了兩種常用的分頁優化方法 延遲關聯 和 「書籤記錄」。
參考:
//dev.mysql.com/doc/refman/5.6/en/limit-optimization.html
//dev.mysql.com/doc/refman/5.6/en/select.html
//www.liaoxuefeng.com/wiki/1177760294764384/1217864791925600
//segmentfault.com/a/1190000017059239?utm_source=sf-related
MySQL中SQL_CALC_FOUND_ROWS的用法 //www.cnblogs.com/chinesern/p/8260506.html


