Zoom-Net 關係檢測論文筆記
Background
- 論文動機
- 通過加強分支間的信息共享和特徵交互,objetcs和object對之間的關係都能被很好地檢測出來,不需要語言先驗
- 論文貢獻
- 提出獨特的逆RoI pool操作
- 提出金字塔RoI pool操作單元,用於傳播全局預測特徵
Model

appearance,context and spatiality

-
Appearance Module: 模型主要關注每個RoI內部的相互依存關係。也就是說subjetc, predicate 和 object分支的特徵是獨立學習的,沒有任何信息傳遞。
-
Context-appearance Module: 直接融合三個分支中任意兩個分支的特徵,這使得subject和object特徵能夠從predicate特徵中吸收上下文信息,predicate特徵接收subject和object的信息。這些特徵被直接連接起來,忽略它們在原始圖像中的相對空間布局。
-
Spatiality-Context-Appearance Module: 相對位置等信息在CA-M並沒有充分體現。因此,作者提出SCA-M,如下圖所示:
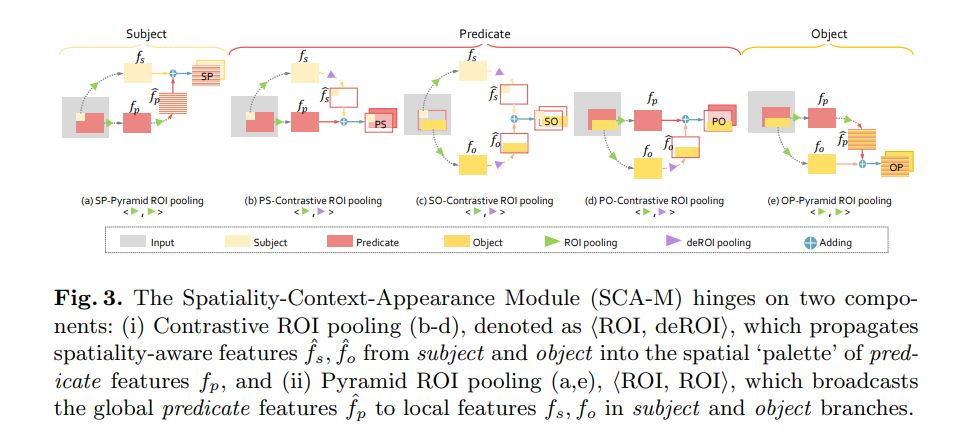
它由兩個部分組成:
Contrast RoI Pool和Pyramid RoI Pool,主要用於在不同分支間進行信息傳遞。相較於CA-M。SCA-M以空間感知的方式重構了局部和全局信息聚合,從而在捕捉關係三元組特徵間的空間和上下文關係方面具有卓越的能力。將subject, predicate和object的感興趣區域感受野分別表示為\mathcal{R}_s, \mathcal{R}_p, \mathcal{R}_o。\mathcal{R}_p表示剛好覆蓋subject和object的聯合邊界框。這三個區域經過ROI-pooled後的特徵為\mathbf{f}_t, t\in \{s,p,o\}。
- Contrastive ROI Pooling: 表示為一對<ROI,逆ROI>操作。object的特徵\mathbf{f}_o首先經過ROI pool操作,提取歸一化局部特徵,然後這些特徵會經過逆ROI pool操作,被彙集到predicat特徵的空間調色板上,以便產生空間感知的object特徵\hat{\mathbf{f}}_{o},它的尺寸與predicat特徵\mathbf{f}_P。注意,\hat{\mathbf{f}}_{o}中相對objectROI之外的區域都被設置為0。空間重現的局部特徵\hat{\mathbf{f}}_{o}可以影響全局特徵圖\mathbf{f}_p的感受野區域。逆ROI可以視為傳統ROI的逆操作,就像自上而下的反卷積和自下而上的卷積。
- 在SCA-M中,有三個 Contrastive ROI pool單元用於聚合特徵對
subject-predicate,subject-object和predicat-object,如圖3中的b-d所示。通過多個卷積層,subject和object的特徵在空間融合到predicate中,以增強表示能力。
- 在SCA-M中,有三個 Contrastive ROI pool單元用於聚合特徵對
- Pyramid ROI Pooling: 表示為一對<ROI, ROI>操作,用於傳遞全局預測特徵到subject和object分支的局部特徵。如圖3中的a和e。
- Contrastive ROI Pooling: 表示為一對<ROI,逆ROI>操作。object的特徵\mathbf{f}_o首先經過ROI pool操作,提取歸一化局部特徵,然後這些特徵會經過逆ROI pool操作,被彙集到predicat特徵的空間調色板上,以便產生空間感知的object特徵\hat{\mathbf{f}}_{o},它的尺寸與predicat特徵\mathbf{f}_P。注意,\hat{\mathbf{f}}_{o}中相對objectROI之外的區域都被設置為0。空間重現的局部特徵\hat{\mathbf{f}}_{o}可以影響全局特徵圖\mathbf{f}_p的感受野區域。逆ROI可以視為傳統ROI的逆操作,就像自上而下的反卷積和自下而上的卷積。

zoom-net: stacked SCA-M
通過堆疊多個SCA-M層,提出的ZooM-Net能夠通過動態的上下文和空間信息聚合來捕捉多尺度的特徵相互作用。
在經過模型之後,每個分支互動增強過的特徵被送入全連接層,去對subject, predicate和object進行分類。
hierarcghical relation classification
視覺關係檢測並非一個簡單的任務:
- Variety: 目標種類非常多,關係種類也是
- Ambiguity: 一些object種類的外觀非常相似
- Imbalance: 長尾分佈
為了解決上述問題,一般的方法是對數據進行清洗。作者提出構建兩個層次結構內樹,用於測量object和predicate類內的關聯性。

