Redis集群數據沒法拆分時的搭建策略
在上一篇文章中,針對服務器單點、單例、單機存在的問題:
- 單點故障
- 容量有限
- 可支持的連接有限(性能不足)
提出了解決的辦法:根據AKF原則搭建集群,大意是先X軸拆分,創建單機的鏡像,組成主主、主備、主從模型,然後Y軸拆分,根據業務將不同的訪問分配在不同的業務Redis上,對於同一業務的Redis,如果還不足以支撐並發訪問,那麼可以繼續Z軸拆分,也就是根據數據拆分,詳細情況參照:Redis集群拆分原則之AKF
結合上面提出一個新問題,如果一個服務,業務數據沒法拆分,或者說不容易拆分呢?也就是沒辦法沿着Y-Z軸拆解,那麼如何集群呢?
解決思路:
一致性Hash
哈希槽
一致性Hash
說到一致性Hash,就得先搞明白為什麼要有一致性Hash,介紹一致性Hash算法之前,先簡單回顧一下分佈式以及Hash算法,便於理解為什麼要有一致性Hash算法。
分佈式
當我們也無需求很複雜時,單台機器IO以及帶寬等都會成為瓶頸,所以對業務進行拆分,部署在不同的機器上,當有請求訪問時,根據某些特點將這些請求分散到各個服務器上,這所有的服務器組成的網絡,我們稱之為集群,這能提高服務器的性能以及利用率。
如果有一個請求過來存數據,調度器將數據存在了A服務器上,下次客戶端再來請求這份數據,該如何迅速判斷數據存在哪台服務器呢?這時候引出了哈希的概念。
哈希函數
對於一個函數:
\]
如果兩個哈希值是不相同的,那麼這兩個哈希值的原始輸入也是不相同的。這個特性是哈希函數具有確定性的結果,具有這種性質的哈希函數稱為單向哈希函數。
但另一方面,哈希函數的輸入和輸出不是唯一對應關係的,如果兩個哈希值相同,兩個輸入值很可能是相同的,但也可能不同,如果值相同稱為「哈希碰撞(collision)」,這通常是兩個不同長度的輸入值,刻意計算出相同的輸出值。輸入一些數據計算出哈希值,然後部分改變輸入值,一個具有強混淆特性的哈希函數會產生一個完全不同的哈希值。哈希函數是不可逆的,也就是沒法根據哈希值來反推輸入值。
那麼對於集群而言,每一個請求都有一個標識ID,如果構造標識到服務器的哈希函數,就可以讓同一請求固定的達到服務器,因為ID是不變的:
\]
為了均勻分佈在不同的服務器上,這是一個跟服務器數量N有關的哈希函數,常見的有取模運算,即:
\]
但是這時候有個問題,由於是集群,那麼服務器數量可能會有變化,例如今天請求量非常大要增加服務器數量,N變大之後,原有的Hash值就失效了,需要重新對存儲的請求值做哈希,由於請求值是一個龐大的數據集.這樣造成了巨大的不便,需要改進我們的Hash算法。這時候引出了一致性Hash的思路。
一致性Hash
一致性哈希的思路是,將哈希函數與服務器數量解綁,如果我們用16個二進制標識哈希值,那麼哈希值有一個範圍區間\([0,65536]\),我們將這個區間65536平均分成N份,N是服務器數量,然後將這些服務器節點等距離安排在一個圓環上
假設服務器數量是4,那麼對於所有請求,哈希值必定是介於\([0,65536]\)之間,當節點計算哈希後對應環上某一個點,這時候順時針尋找離自己最近的服務節點作為存儲節點,例如:當請求哈希值介於\([0,16384]\)之間時,將請求分配到Server 1,如果請求哈希值介於\((16384,32768]\)之間時,將請求分配到Server 2,後面同理,這樣做有一個什麼好處呢,如果這時候需要新增加一個服務器,假設是Server 5:

那麼需要重新計算Hash值的僅僅為\([0,8192]\)這部分請求,將其分配到Server 5上。

這地方有兩點要注意,很多博客都沒有提到:
一是原有節點信息本應該歸server 2 存儲,新增加了Server 5 之後根據新的規則會映射到Server 5上,那麼之前存儲在Server 1 上的數據需要重新取出來放在Server 5 上嗎?
答案是否定的,只需要查找數據,在最近的點沒找到,往下(順時針)再查找一個點就行了,也可以再查找兩個點(防止插入了兩台新的服務節點)
二是,刪除某個服務器節點
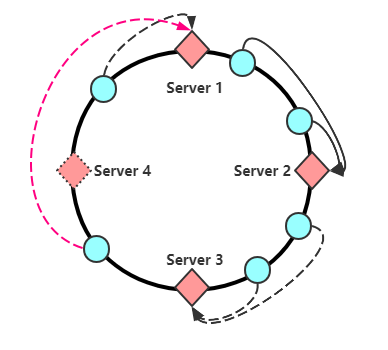
如圖,刪除服務器Server 4 之後,會將原有分佈在Server4 上的請求全都壓在Server1上,如果Server1 hold不住,那麼可能掛掉,掛掉之後數據又轉移給Server2,如此循環會造成所有節點崩潰,也就是雪崩的情況。這種雪崩可以靠下面的虛擬節點引入解決
虛擬節點的引入
我們已經知道,添加和刪除節點都會影響緩存數據的分佈。儘管hash算法具有分佈均勻的特性,但是當集群中server數量很少時,他們可能在環中的分佈並不是特別均勻,進而導致緩存數據不能均勻分佈到所有的server上,例如都分配在某一個或幾個哈希區間,那麼有很多服務器可能就沒在這個分佈式系統中提供作用。
為解決這個問題,需要使用虛擬節點, 虛擬節點的思想:為每個物理節點(server)在環上分配100~200個點,這樣環上的節點較多,就能抑制分佈不均勻。當為cache定位目標server時,如果定位到虛擬節點上,就表示cache真正的存儲位置是在該虛擬節點代表的實際物理server上。另外,如果每個實際server節點的負載能力不同,可以賦予不同的權重,根據權重分配不同數量的虛擬節點。定位算法不變,只是多了一步虛擬節點到真實節點映射的過程
為什麼說這樣能解決雪崩的發生呢,因為即使一台服務器掛了,他應對的虛擬節點也會消失,那也就是新來的數據依舊可在原區間內隨機或者根據某種規律分配到其他節點上。
注意:真實節點不放置到哈希環上,只有虛擬節點才會放上去。
另外沒法做數據庫用(待補充)
哈希槽
了解哈希槽前景知識還是普通哈希,前面講了哈希存在的問題是,當服務節點變化時,假如是增加到N+1,要對所有數據重新對服務器數量N+1取模,這在分佈式中是難以接受的,太浪費時間。
那麼,可不可以先假設我將來會有很多機器,例如一萬台,對一萬台取模,然後構建映射將取模值(哈希值)分區呢?Redis 集群的哈希槽就是這種思路:
用我們的Key值,對12取模,那麼範圍是在\([0,11]\)之間,這兒的\([0,11]\)就是我們所說的槽值,然後將這個範圍區間切割成N份,N為服務器數量,如圖:

之後如果新增了Redis服務器,只需要將映射的槽值對應的數據移動去新服務器就行了:
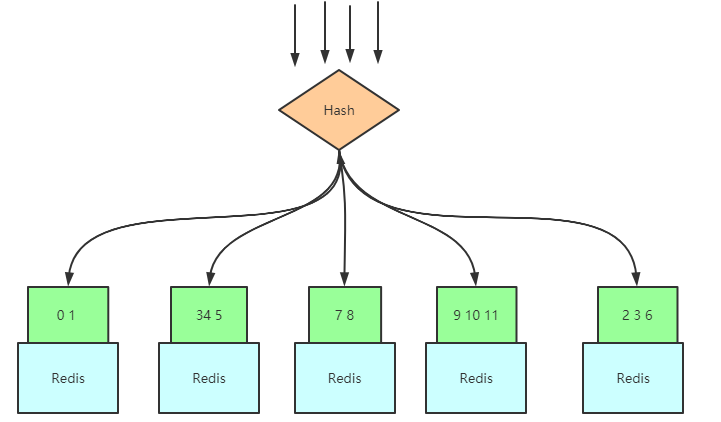
基於哈希槽的cluster集群
當客戶端來獲取數據時,隨便連接到哪一個服務器上,服務器內置上面說的Hash算法,對請求Id進行Hash得到哈希值,每一個服務器內置一個表,這個表將哈希值對應的哈希槽與數據存儲服務節點做一個映射,也就是請求壓到任一台服務器,有數據的話會返回數據,沒有的話會返回存儲所需數據的服務器節點位置:

哈希槽與一致性哈希區別
它並不是閉合的,key的定位規則是根據CRC-16(key)%16384的值來判斷屬於哪個槽區,從而判斷該key屬於哪個節點,而一致性哈希是根據hash(key)的值來順時針找第一個hash(ip)的節點,從而確定key存儲在哪個節點。
一致性哈希是創建虛擬節點來實現節點宕機後的數據轉移並保證數據的安全性和集群的可用性的。redis cluster是採用master節點有多個slave節點機制來保證數據的完整性的,master節點寫入數據,slave節點同步數據。當master節點掛機後,slave節點會通過選舉機制選舉出一個節點變成master節點,實現高可用。但是這裡有一點需要考慮,如果master節點存在熱點緩存,某一個時刻某個key的訪問急劇增高,這時該mater節點可能操勞過度而死,隨後從節點選舉為主節點後,同樣宕機,一次類推,造成緩存雪崩。

