LSM(Log Structured Merge Trees ) 筆記
一、大幅度制約存儲介質吞吐量的原因
首先拋出結論。無論任何存儲介質(不管是機械硬盤還是SSD,抑或是內存)的順序訪問速度都遠遠高出隨機訪問的速度。

二、傳統數據庫的實現機制
傳統數據庫,比如Mysql使用的b+樹索引,對讀友好。但容易造成隨機寫。比如新插入一個值到數據庫,首先我們要讀取b+樹,判斷新插入的值放在樹的什麼位置,其次在特定的位置寫入新值,並做一系列調整,分裂,使之滿足b+樹的特性。這不可避免的造成了磁盤的隨機訪問,大數據量的插入速度很慢。當然這也符合歷史發展趨勢,早起的IT行業,數據量和數據增長速度有限,只要擁有良好的查詢性能,即可滿足需求。
但隨着硬件性能的提升,業務形態的變化,現今的互聯網系統,往往面臨著數據的大量、高速產生。如何加快存儲速度,成了關鍵。於是LSM Tree應運而生。
三、LSM Tree的歷史由來
LSM Tree的最早概念,誕生於1996年google的「BigTable」論文。後世多種數據庫產品對LSM Tree的具體實現,都有一些小的差異。採用LSM Tree作為存儲結構的數據庫有,Google的LevelDB, Facebook的RockDB(RockDB來源於LevelDB), Cassandra,HBase等。
四、提高寫吞吐量的思路
既然順序寫比起隨機寫速度更快。那得想辦法將數據順序寫。
4.1 一種方式是數據來後,直接順序落盤
這擁有很高的寫速度。但是當我們想要查尋一個數據的時候,由於存儲下的數據本身是無序的(寫的值本身無法控制順序),無法使用任何算法進行優化,只能挨個查詢,讀取速度是很慢的。
4.2 另一種方式,是保證落盤的數據是順序寫入的同時,還保證這些數據是有序的
而請求寫入的數據本身是無序且不可預測的,如何保證落盤的數據是有序的呢?這就需要利用內存訪問速度比硬盤快的原理。將寫入的請求,先在內存中緩存起來,按一定的有序結構組織,達到一定量後,再寫入硬盤,從而使得硬盤順序寫入了有序的數據。提高數據的寫入速度同時,方便了後續基於有序數據的查找(有序的數據結構,可以通過二分查找等算法進行進行快速查詢,具體查找算法,得看是哪種有序結構)
五、 LSM Tree結構圖
LSM tree即利用了上述第二種方式。具體結構圖如下:
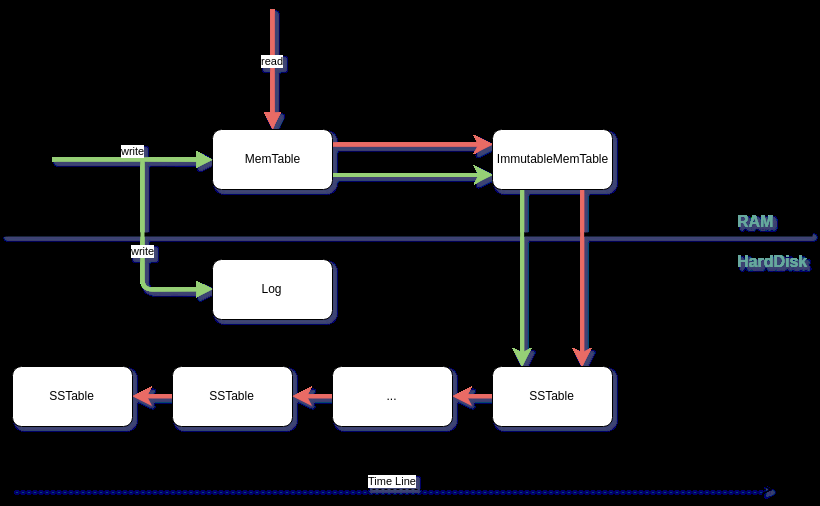
5.1 寫入時,為什麼要先寫一份log
為了防止寫入的數據,在斷電時丟失。所以先順序寫一份log到硬盤,方便數據恢復。
5.2 什麼是MemTable
寫入數據的內存緩存,MemTable中存儲的是有序的數據。什麼才是有序的數據結構?不同的實現可能不相同。LevelDB使用的是SkipList。Hbase使用的是B Tree。
5.3 什麼是ImmutableMemTable
MemTable中的數據隨時在增加,當其增加到一定量後,將其變為不可變數據,ImmutableMemTable。新生成一份MemTable用於後續的數據寫入。ImmutableMemTable中的數據,將被寫入到硬盤中的SSTable.
5.4 什麼是SSTable
SSTable 全稱Sorted String Table。實際上就是被寫入數據的有序存儲文件,所以叫sorted.
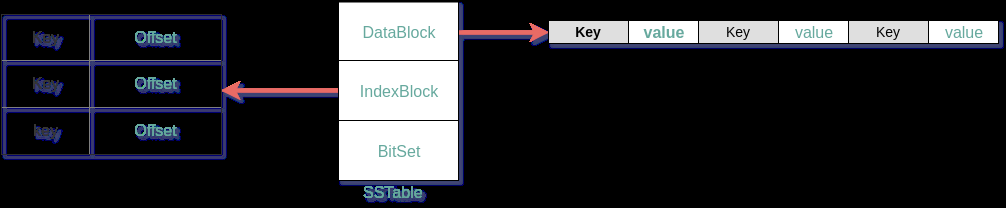
SSTable文件有DataBlock,IndexBlock,BitSet(不同的實現,有可能沒有)
- DataBlock 一個SSTable包含多個數據塊,數據按KeyValue的形式有序組織。
- IndexBlock 記錄每個數據塊中最大的那個Key的Offset
- BitSet 使用Bloom Filter來將一個Key映射到BitSet中
數據的有序組織、IndexBlock、BitSet。這些數據結構,都是為了提高數據讀取時的速度。那數據是如何進行讀取的呢?
5.5 如何進行數據讀取
讀取的大概流程如下

由於SSTable是順序創建,所以最新的SSTable中包含了最新的值。再查找SSTable時,依次查找最新的SSTable。
每一個SSTable的查詢流程如下
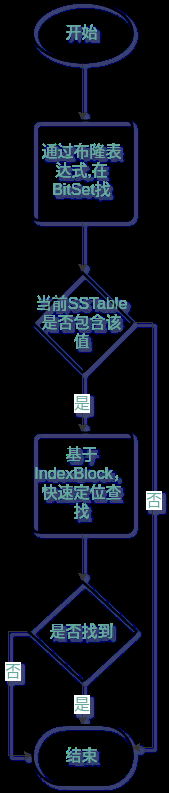
布隆表達式的原理是以極小的數據容量,去存儲大量數據存在的可能性。所以如果通過BitSet的布隆表達式查詢該Key存在時,只是一個理論存在可能,接下來要通過IndexBlock真正進行查詢。而如果布隆表達式在BitSet中沒有找到,那就是真的沒有,可以快速跳過,進入下一個SSTable查找。布隆表達式的運用,能夠大大提高查找效率。
5.6 如何進行數據的刪除和更新
為了保證數據的順序寫,所有SSTable都不會因為刪除和更新而在原數據所在位置進行更改。在更新時,僅僅插入一個最新的值去寫到新的SSTable中。在刪除時,依然是插入一個基於該Key的刪除標記,寫入最新的SSTable中。由於查找某個Key是基於時間新鮮度,反向依次查找SSTable,所以讀取某個Key始終讀的是最新的值。
5.7 SSTable的合併
隨着日積月累,SSTable的文件數會增多,導致查找時性能下降。同時由於數據的更新或刪除。讓老的SSTable中數據的有效性降低,太多的過期數據佔用SSTable,同樣會降低查詢效率。所以一般數據庫引擎,定期都會有一個SSTable的合併操作。移除過時數據,將多個小SSTable合併成大的SSTable。
5.8 最近讀取的SSTable IndexBlock緩存
在大內存的條件下,部分數據庫還會將最近讀取的SSTable 索引,緩存至內存。這進一步加速了查找的過程。
六、參考文獻
//www.benstopford.com/2015/02/14/log-structured-merge-trees/
//www.cnblogs.com/haippy/archive/2011/12/04/2276064.html
//blog.csdn.net/u014774781/article/details/52105708
//en.wikipedia.org/wiki/Log-structured_merge-tree
//www.igvita.com/2012/02/06/sstable-and-log-structured-storage-leveldb/
歡迎關注我的個人公眾號”西北偏北UP”,記錄代碼人生,行業思考,科技評論


