分佈式全局唯一ID生成策略
- 2019 年 10 月 3 日
- 筆記
一、背景
分佈式系統中我們會對一些數據量大的業務進行分拆,如:用戶表,訂單表。因為數據量巨大一張表無法承接,就會對其進行分庫分表。
但一旦涉及到分庫分表,就會引申出分佈式系統中唯一主鍵ID的生成問題。
1.1 唯一ID的特性
- 整個系統
ID唯一; - ID是數字類型,而且是趨勢遞增;
- ID簡短,查詢效率快。
1.2 遞增與趨勢遞增
| 遞增 | 趨勢遞增 |
|---|---|
| 第一次生成的ID為12,下一次生成的ID是13,再下一次生成的ID是14。 | 什麼是?如:在一段時間內,生成的ID是遞增的趨勢。如:再一段時間內生成的ID在【0,1000】之間,過段時間生成的ID在【1000,2000】之間。但在【0-1000】區間內的時候,ID生成有可能第一次是12,第二次是10,第三次是14。 |
二、方案
2.1 UUID
UUID全稱:Universally Unique Identifier。標準型式包含32個16進制數字,以連字號分為五段,形式為8-4-4-4-12的36個字符,示例:9628f6e9-70ca-45aa-9f7c-77afe0d26e05。
- 優點:
- 代碼實現簡單;
- 本機生成,沒有性能問題;
- 因為是全球唯一的
ID,所以遷移數據容易。
- 缺點:
- 每次生成的
ID是無序的,無法保證趨勢遞增; UUID的字符串存儲,查詢效率慢;- 存儲空間大;
ID本身無業務含義,不可讀。
- 應用場景:
- 類似生成token令牌的場景;
- 不適用一些要求有趨勢遞增的ID場景,不適合作為高性能需求的場景下的數據庫主鍵。
也有在線生成
UUID的網站,如果你的項目上用到了UUID,可以用來生成臨時的測試數據。https://www.uuidgenerator.net/
2.2 MySQL主鍵自增
利用了MySQL的主鍵自增auto_increment,默認每次ID加1。
優點:
- 數字化,
ID遞增; - 查詢效率高;
- 具有一定的業務可讀。
- 缺點:
- 存在單點問題,如果
MySQL掛了,就沒法生成ID了; - 數據庫壓力大,高並發抗不住。
2.3 MySQL多實例主鍵自增
這個方案就是解決MySQL的單點問題,在auto_increment基本上面,設置step步長

如上,每台的初始值分別為1,2,3…N,步長為N(這個案例步長為4)
- 優點:解決了單點問題;
- 缺點:一旦把步長定好後,就無法擴容;而且單個數據庫的壓力大,數據庫自身性能無法滿足高並發。
- 應用場景:數據不需要擴容的場景。
2.4 基於Redis實現
-
單機:
Redis的incr函數在單機上是原子操作,可以保證唯一且遞增。 -
集群:單機
Redis可能無法支撐高並發。集群情況下,可以使用步長的方式。比如有5個Redis節點組成的集群,它們生成的ID分別為:
A: 1,6,11,16,21 B: 2,7,12,17,22 C: 3,8,13,18,23 D: 4,9,14,19,24 E: 5,10,15,20,25- 優點:有序遞增,可讀性強。
- 缺點:佔用帶寬,每次要向
Redis進行請求。
三、優化方案
3.1、改造數據庫主鍵自增
數據庫的自增主鍵的特性,可以實現分佈式ID,適合做userId,正好符合如何永不遷移數據和避免熱點? 但這個方案有嚴重的問題:
- 一旦步長定下來,不容易擴容;
- 數據庫壓力山大。
- 為什麼壓力大?
因為我們每次獲取ID的時候,都要去數據庫請求一次。那我們可以不可以不要每次去取?
可以請求數據庫得到ID的時候,可設計成獲得的ID是一個ID區間段。
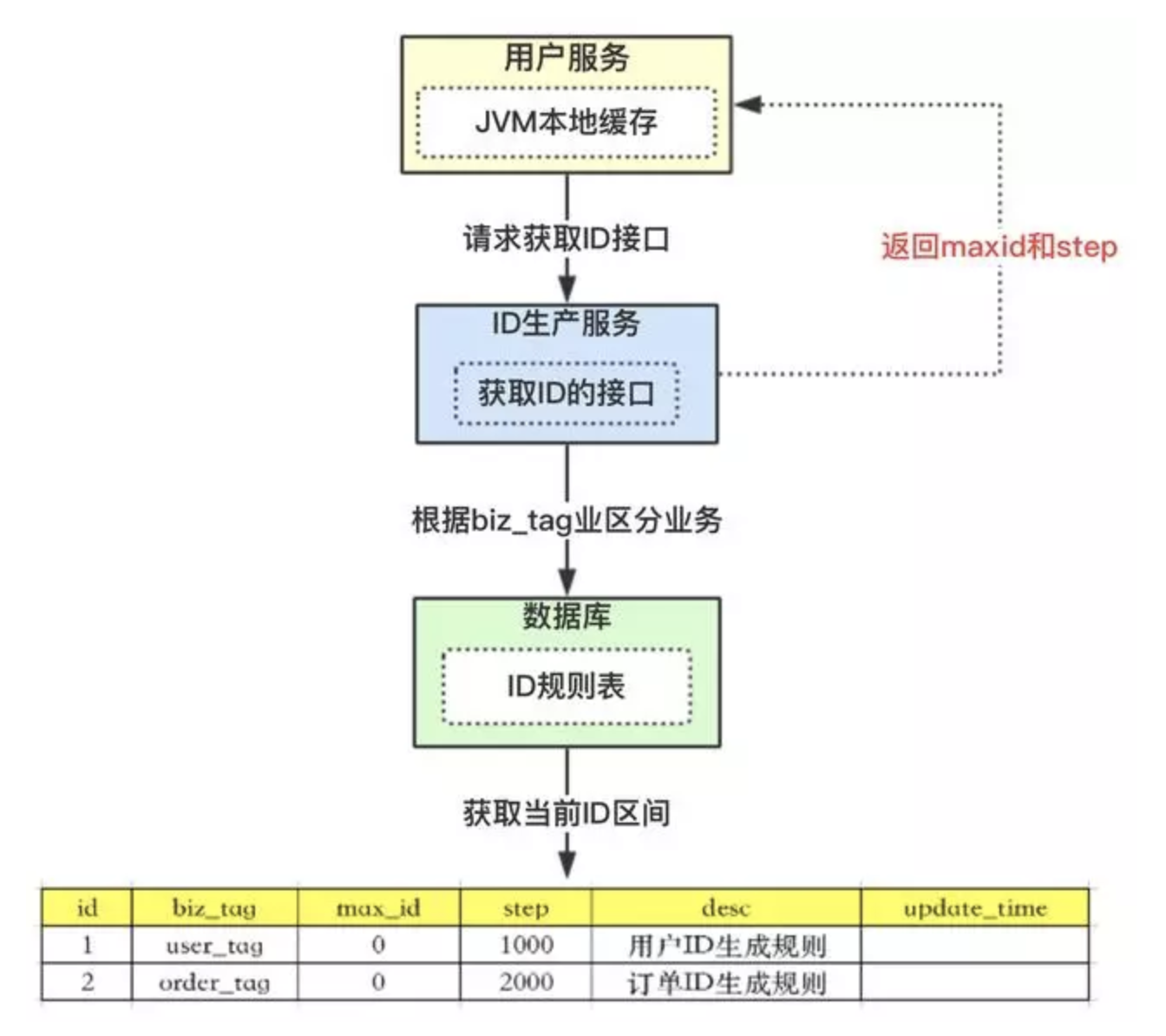
- 上圖
ID規則表含義:
id表示為主鍵,無業務含義;biz_tag為了表示業務,因為整體系統中會有很多業務需要生成ID,這樣可以共用一張表維護;max_id表示現在整體系統中已經分配的最大ID;desc描述;update_time表示每次取的ID時間;
- 整體流程:
- 【用戶服務】在註冊一個用戶時,需要一個用戶
ID;會請求【生成ID服務(是獨立的應用)】的接口; - 【生成
ID服務】會去查詢數據庫,找到user_tag的id,現在的max_id為0,step=1000; - 【生成
ID服務】把max_id和step返回給【用戶服務】;並且把max_id更新為max_id = max_id + step,即更新為1000; - 【用戶服務】獲得
max_id=0,step=1000; - 這個用戶服務可以用
ID=【max_id + 1,max_id+step】區間的ID,即為【1,1000】; - 【用戶服務】會把這個區間保存到
jvm中; - 【用戶服務】需要用到
ID的時候,在區間【1,1000】中依次獲取ID,可採用AtomicLong中的getAndIncrement方法; -
如果把區間的值用完了,再去請求【生產
ID服務】接口,獲取到max_id為1000,即可以用【max_id + 1,max_id+step】區間的ID,即為【1001,2000】。 - 該方案就非常完美的解決了數據庫自增的問題,而且可以自行定義
max_id的起點,和step步長,非常方便擴容; -
也解決了數據庫壓力的問題,因為在一段區間內,是在
jvm內存中獲取的,而不需要每次請求數據庫。即使數據庫宕機了,系統也不受影響,ID還能維持一段時間。
3.2 競爭問題
以上方案中,如果是多個用戶服務,同時獲取ID,同時去請求【ID服務】,在獲取max_id的時候會存在並發問題。如:
用戶服務
A,取到的max_id=1000;用戶服務B取到的也是max_id=1000,那就出現了問題,ID重複了。
解決方案是:加分佈式鎖,保證同一時刻只有一個用戶服務獲取max_id。
3.3 突發阻塞問題
因為競爭問題,所有隻有一個用戶服務去操作數據庫,其他二個會被阻塞。出現的現象就是一會兒突然系統耗時變長,怎麼去解決?
- 雙
buffer方案
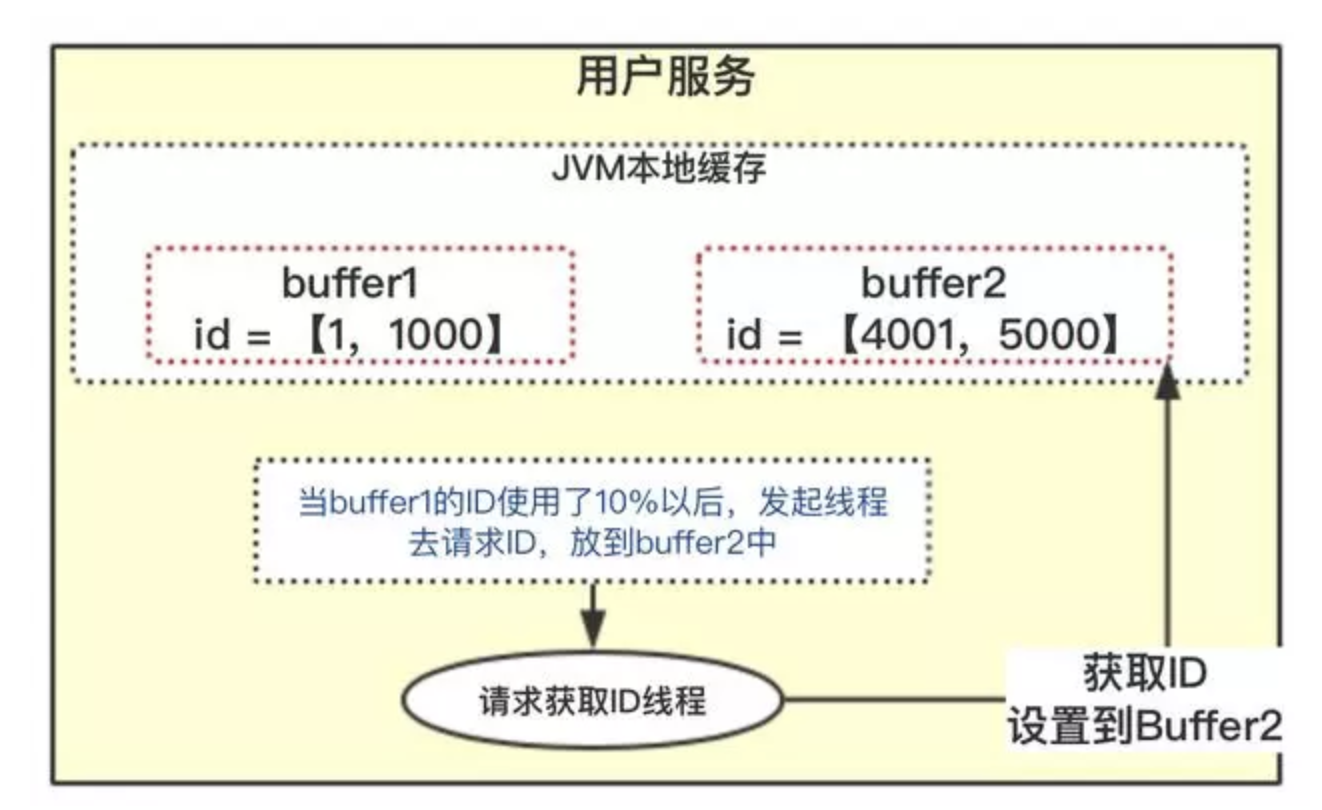
流程如下:
- 當前獲取
ID在buffer1中,每次獲取ID在buffer1中獲取; - 當
buffer1中的ID已經使用到了100,也就是達到區間的10%; - 達到了
10%,先判斷buffer2中有沒有去獲取過,如果沒有就立即發起請求獲取ID線程,此線程把獲取到的ID,設置到buffer2中; - 如果
buffer1用完了,會自動切換到buffer2; buffer2用到10%了,也會啟動線程再次獲取,設置到buffer1中;- 依次往返。
3.4 總結
- 雙
buffer的方案就達到了業務場景用的ID,都是在jvm內存中獲得的,從此不需要到數據庫中獲取了,數據庫宕機時長長點兒也沒太大影響了。 - 因為會有一個線程,會觀察什麼時候去自動獲取。兩個
buffer之間自行切換使用,就解決了突發阻塞的問題。
四、其他方式
還有一些其他的ID生成方案,比如:
- 滴滴:時間+起點編號+車牌號;
- 淘寶訂單:時間戳+用戶
ID - 其他電商:時間戳+下單渠道+用戶
ID,有的會加上訂單第一個商品的ID; MongoDB的ID:通過時間+機器碼+pid+inc共12個位元組,4+3+2+3的方式最終標識成一個24長度的十六進制字符。
