集群故障處理之處理思路以及聽診三板斧(三十三)
- 2019 年 10 月 3 日
- 筆記
前言
本篇主要分享一些處理故障和問題絕招,比如聽診三板斧:
1)查看日誌
2)查看資源詳情和事件
3)查看資源配置(YAML)
如果還是不太好分析,那就祭出神器——kubectl-debug。
最後,僅需根據問題對症下藥即可。
目錄
-
進一步診斷分析——聽診三板斧
-
容器調測
-
對症下藥
進一步診斷分析——聽診三板斧
在初診階段,我們往往只能獲得一些表面的信息,比如節點掛了,Pod崩潰了,網絡不通等等,這時,我們需要根據我們初診的方向和範圍使用一些工具以及結合日誌進行具體的診斷。
這裡筆者推崇聽診三板斧:
-
查看日誌
-
查看資源詳情和事件
-
查看資源配置
查看日誌
大部分情況下,想要獲得具體的病因,查看日誌是最為直接的方式,因此,我們需要學會如何查看日誌。
1.使用journalctl查看服務日誌
主流的Linux系統基本上都採用Systemd來集中管理和配置系統,如果使用的是Systemd機制,我們可以使用journalctl命令來查看服務日誌:
比如docker:
journalctl -u docker
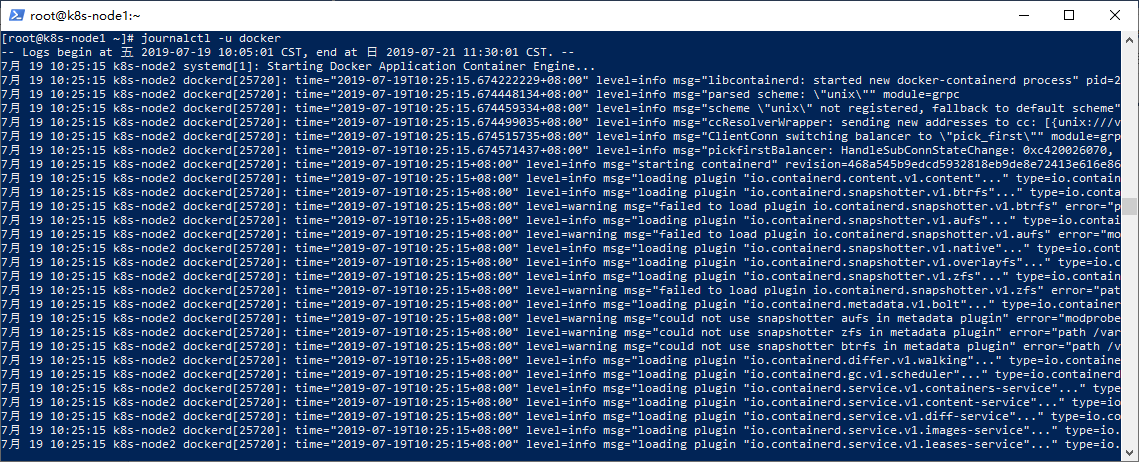

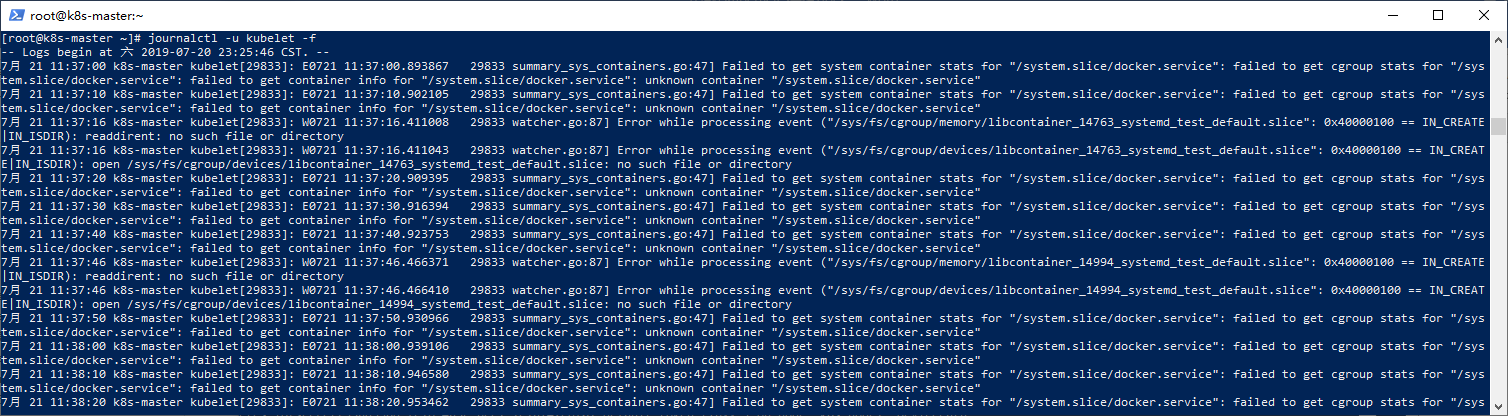
查看並追蹤kubelet的日誌:
journalctl -u kubelet -f

2.使用“kubectl logs”查看容器日誌
我們的應用運行在Pod之中,以及k8s的一些組件,例如kube-apiserver、coredns、etcd、kube-controller-manager、kube-proxy、kube-scheduler等,也都運行在Pod之中(靜態Pod),那麼如何查看這些組件以及應用的日誌呢?這裡就要用到前面提到的“kubectl logs”命令。
語法如下所示:
kubectl logs [-f] [-p] (POD | TYPE/NAME) [-c CONTAINER] [options]
主要的參數說明如下表所示:
|
參數 |
說明 |
|
-f, –follow |
是否持續追蹤日誌,默認為false,指定了之後會持續輸出日誌。 |
|
-p, –previous |
輸出Pod中曾經運行過,但目前已終止的容器的日誌。 |
|
-c, –container |
容器名稱。 |
|
–since |
僅返回相對時間範圍(如5s、2m或3h)內的日誌。默認返回所有日誌。 |
|
–since-time |
僅返回指定時間之後的日誌,默認返回所有。只能同時使用since和since-time中的一種。 |
|
–tail |
要顯示的最新的日誌條數,默認為-1,顯示所有。 |
|
–timestamps |
輸出的日誌中包含時間戳。 |
|
-l, –selector |
使用Label選擇器過濾 |
了解了主要的參數和說明,我們查看幾個示例:
-
查看Pod“mssql-58b6bff865-xdxx8”的日誌
kubectl logs mssql-58b6bff865-xdxx8
-
查看24小時內的日誌
kubectl logs mssql-58b6bff865-xdxx8 --since 24h
-
根據Pod標籤查看日誌
kubectl logs -lapp=mssql
-
查看指定命名空間下的Pod日誌(注意系統組件的命名空間為“kube-system”)
kubectl logs kube-apiserver-k8s-master -f -n kube-system
查看資源實例詳情
除了查看日誌之外,有時候我們需要查看資源實例詳情以幫助我們解決問題。這就需要用到我們上面提到過的“kubectl describe”命令。
“kubectl describe”命令用於查看一個或多個資源的詳細情況,包括相關資源和事件。語法如下所示:
kubectl describe (-f FILENAME | TYPE [NAME_PREFIX | -l label] | TYPE/NAME)
主要的參數說明如下表所示:
|
參數 |
說明 |
|
-A,–all-namespaces |
查看所有命名空間下的資源 |
|
-f, –filename |
根據資源描述文件、目錄、Url來查看 |
|
-R, –recursive |
以遞歸方式查看-f指定的所有資源 |
|
-l, –selector |
使用Label選擇器過濾 |
|
–show-events |
顯示事件 |
了解了主要的參數和說明,我們通過示例來進行解說:
1.查看節點
查看指定節點:
kubectl describe nodes k8s-node1
查看所有節點:
kubectl describe nodes
查看指定節點以及事件:
kubectl describe nodes k8s-node1--show-events
注意,如果Node狀態為NotReady,通過查看節點事件可以有助於我們排查問題。
2.查看Pod
查看指定Pod:
kubectl describe pods gitlab-84754bd77f-7tqcb
查看指定文件描述的所有資源
kubectl describe -f teamcity.yaml
查看資源以及配置
很多應用的出錯往往都是我們的配置導致的,那麼如何查看已部署資源的配置呢?這就需要用到強大的“kubectl get”命令了。
“kubectl get”命令我們經常使用,在這之前我們經常用其來查詢資源,那麼如何使用它來查看資源配置呢?我們先來看其語法:
kubectl get [(-o|--output=)json|yaml|wide|custom-columns=...|custom-columns-file=...|go-template=...|go-template-file=...|jsonpath=...|jsonpath-file=...] (TYPE[.VERSION][.GROUP] [NAME | -l label] | TYPE[.VERSION][.GROUP]/NAME ...) [flags] [options]
如上述語法所示,“kubectl get”擁有強大的格式化輸出能力,支持“json”、“yaml”等,在上面的kubectl一節中我們已經講解過了,這裡我們就主要用到“-o”來查看資源配置,具體如以下實例所示:
-
查看指定Pod配置
kubectl get pods mssql-58b6bff865-xdxx8 -o yaml
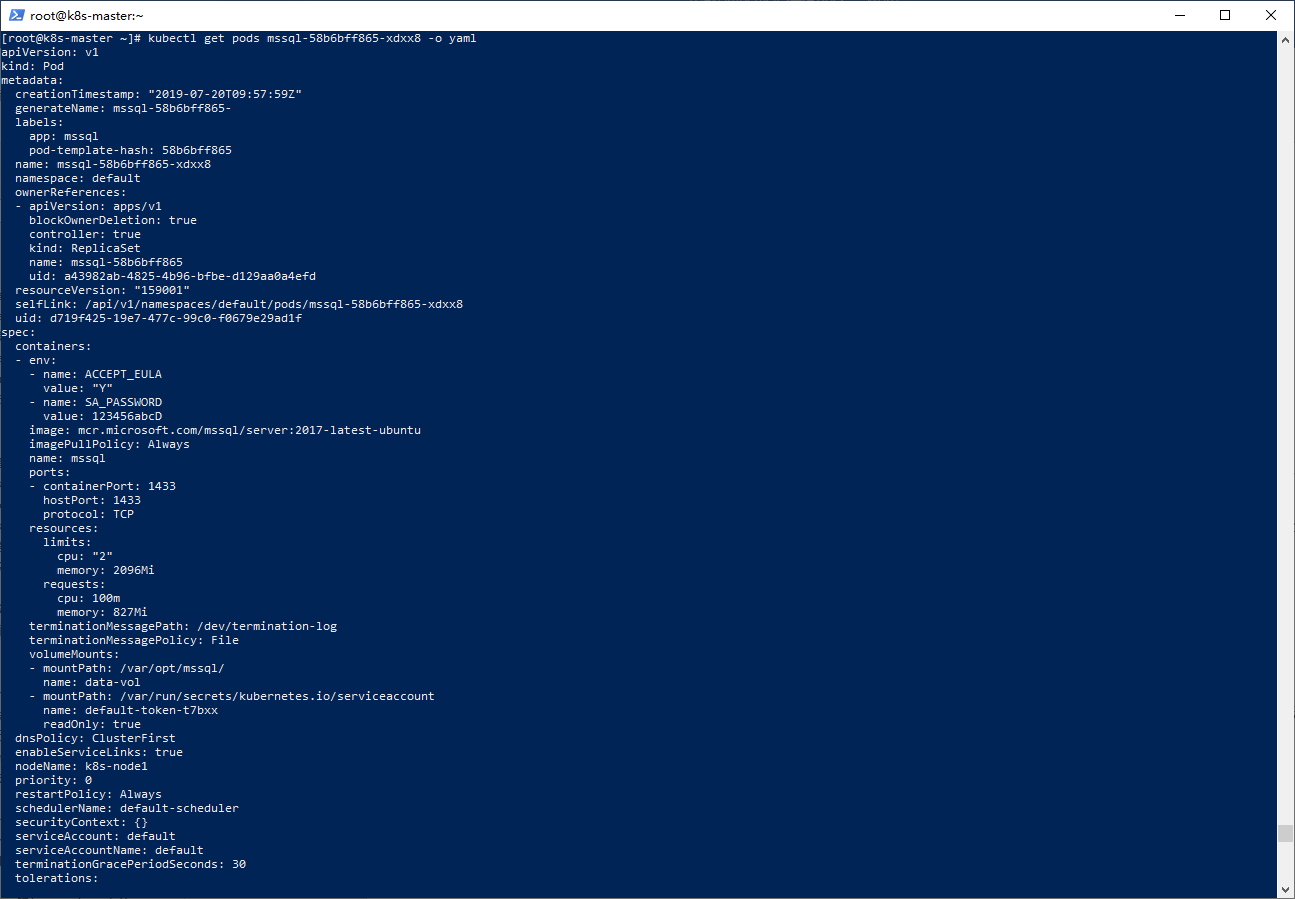

-
yaml奴家看不慣,想看JSON版的:
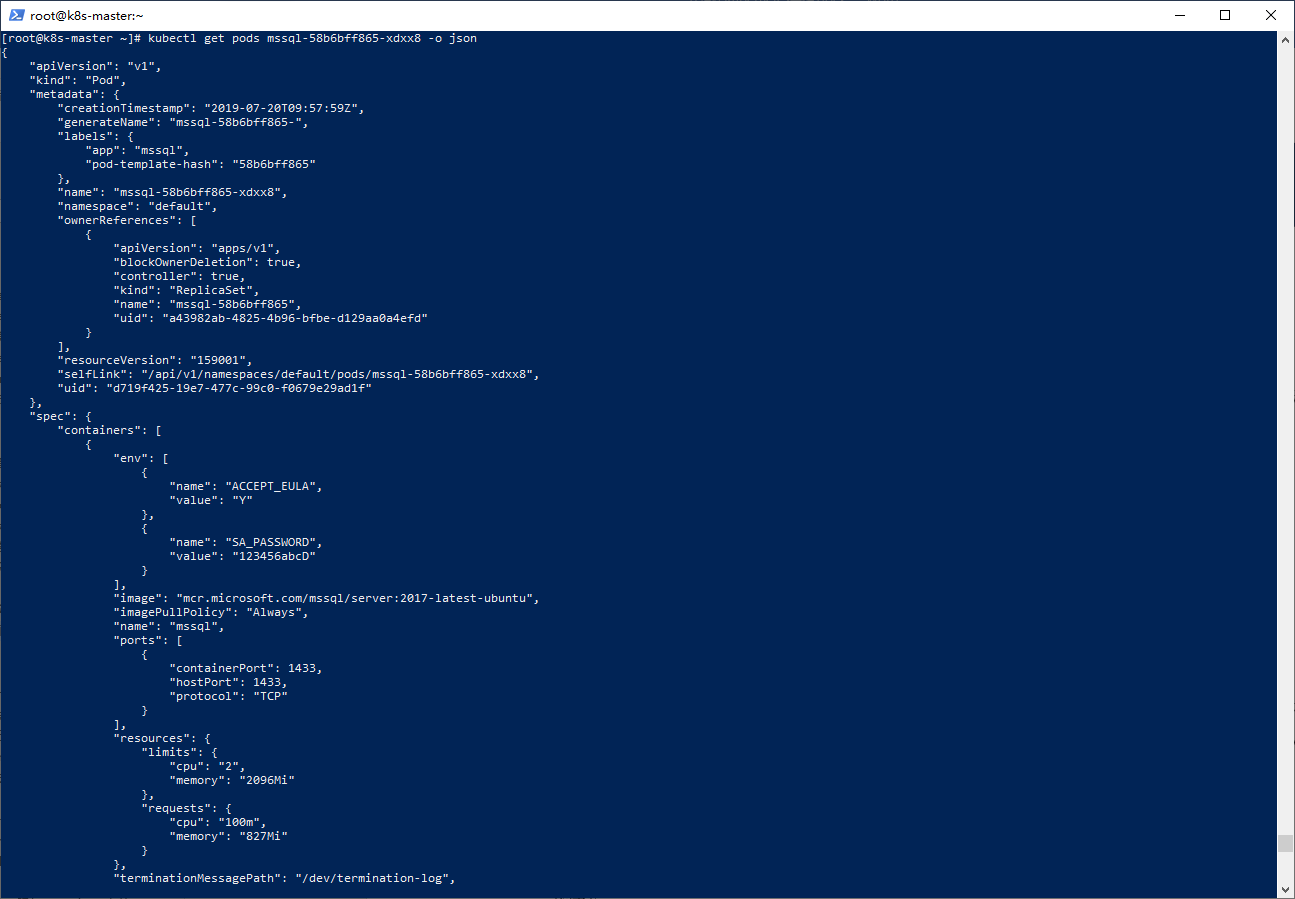
-
想看所有的:
kubectl get pods -o json
-
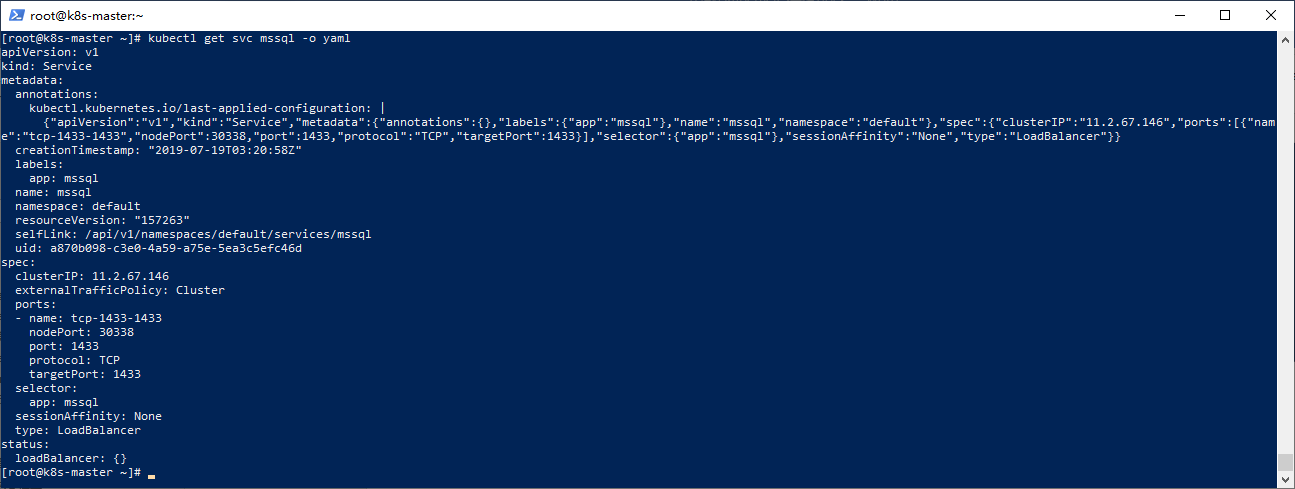
查看服務配置
kubectl get svc mssql -o yaml

-
查看部署(deployment)配置
kubectl get deployments mssql -o yaml


注意:“-o”用得好,再也不用擔心yaml不會寫了。
容器調測
有時候光看日誌還沒發給出具體診斷,可能得動刀子或者進行進一步檢查調測才能論證我們的猜想。筆者推薦使用以下方案:
使用“kubectl exec”進入運行中的容器進行調測
我們可以使用“kubectl exec”進入運行中的容器進行調測。這個命令和“docker exec”很類似,具體語法如下所示:
kubectl exec (POD | TYPE/NAME) [-c CONTAINER] [flags] -- COMMAND [args...] [options]
主要的參數說明如下表所示:
|
參數 |
說明 |
|
-c, –container |
指定容器名稱 |
|
-i, –stdin |
啟用標準輸入 |
|
–tty , -t |
分配偽TTY(終端設備) |
接下來我們結合示例說明:
-
進入容器查看配置
kubectl exec mssql-58b6bff865-xdxx8 -- cat /etc/resolv.conf


-
進入容器分配終端並將標準輸入流轉到bash
kubectl exec mssql-58b6bff865-xdxx8 -it bash


如上圖所示,我們進入MSSQL數據庫的容器之後,使用sqlcmd工具執行了一個查詢。這塊操作如有疑問,請參閱數據庫容器化一節。
使用kubectl-debug工具調測容器
kubectl-debug 是一個簡單的開源的kubectl 插件, 可以幫助我們便捷地進行 Kubernetes 上的 Pod 排障診斷,背後做的事情很簡單: 在運行中的 Pod 上額外起一個新容器, 並將新容器加入到目標容器的 pid, network, user以及 ipc namespace中, 這時我們就可以在新容器中直接用 netstat, tcpdump 這些熟悉的工具來診斷和解決問題了, 而舊容器可以保持最小化, 不需要預裝任何額外的排障工具.
GitHub地址:https://github.com/aylei/kubectl-debug
安裝腳本如下(CentOS 7):
export PLUGIN_VERSION=0.1.1 # linux x86_64,下載文件 curl -Lo kubectl-debug.tar.gz https://github.com/aylei/kubectl-debug/releases/download/v${PLUGIN_VERSION}/kubectl-debug_${PLUGIN_VERSION}_linux_amd64.tar.gz #解壓 tar -zxvf kubectl-debug.tar.gz kubectl-debug #移動到用戶的可執行文件目錄 sudo mv kubectl-debug /usr/local/bin/
為了調試更快更方便,我們還需安裝debug-agent DaemonSet,安裝命令如下:
kubectl apply -f https://raw.githubusercontent.com/aylei/kubectl-debug/master/scripts/agent_daemonset.yml
使用起來非常簡單,以下是常用的使用示例:
# 輸出幫助命令 kubectl debug -h # 啟動Debug kubectl debug (POD | NAME) # 假如 Pod 處於 CrashLookBackoff 狀態無法連接, 可以複製一個完全相同的 Pod 來進行診斷 kubectl debug (POD | NAME) --fork # 假如 Node 沒有公網 IP 或無法直接訪問(防火牆等原因), 請使用 port-forward 模式 kubectl debug (POD | NAME) --port-forward --daemonset-ns=kube-system --daemonset-name=debug-agent
接下來,我們使用該工具調試一個已有Pod,如下所示:
kubectl debug teamcity-5997d4fc7f-ldt8w
執行該命令後,會自動拉取相關鏡像並創建容器開啟tty並進入容器內部,並且自帶一些常用工具。這裡我們使用nslookup命令來測試Pod內的外網域名(比如xin-lai.com)解析:


如上圖所示,這樣就不用每次為了調測網絡問題、應用問題而且安裝各種工具了,費時費力不說,有時候網絡不通就比較傷了。
對症下藥
根據“聽診”步驟,我們需要獲得具體的情報才能對症下藥。比如Pod為啥沒有調度,是資源(CPU、內存等)不足,還是所有節點均不滿足調度要求(比如指定了“nodeName”要求Pod強制調度到某個節點,而該節點宕機)。只有知道了具體原因,我們才能針對情況進行調整和處理,直到解決問題。
一般來說,大家遇到的Pod問題比較多,這裡筆者做個經驗總結。
-
Pod一直處於Pending狀態,經診斷為資源不足
Pending一般情況下表示這個pod沒有被調度到一個節點上。通常這是因為資源不足引起的。
解決方案有:
-
添加工作節點
-
移除部分Pod以釋放資源
-
降低當前Pod的資源限制
-
Pod一直處於Waiting狀態,經診斷為鏡像拉取失敗
如果一個pod卡在Waiting狀態,則表示這個pod已經調試到節點上,但是沒有運行起來。
解決方案有:
-
檢查網絡問題,如果是網絡問題,則保障網絡通暢,可以考慮使用代理或國際網絡(部分域名在國內網絡無法訪問,比如“k8s.gcr.io”)
-
如果是拉取超時,可以考慮使用鏡像加速器(比如使用阿里雲或騰訊雲提供的鏡像加速地址),也可以考慮適當調整超時時間
-
嘗試使用docker pull <image>來驗證鏡像是否可以正常拉取
-
Pod一直處於CrashLoopBackOff狀態,經檢查為健康檢查啟動超時而退出
CrashLoopBackOff 狀態說明容器曾經啟動了,但又異常退出了。通常此Pod的重啟次數是大於0的。
解決方案有:
-
重試設置合適的健康檢查閾值
-
優化容器性能,提高啟動速度
-
關閉健康檢查

