Java高並發與多線程(二)—–線程的實現方式
今天,我們開始Java高並發與多線程的第二篇,線程的實現方式。
通常來講,線程有三種基礎實現方式,一種是繼承Thread類,一種是實現Runnable接口,還有一種是實現Callable接口,當然,如果我們鋪開,擴展一下,會有很多種實現方式,但是歸根溯源,其實都是這幾種實現方式的衍生和變種。
我們依次來講。
【第一種 · 繼承Thread】
繼承Thread之後,要實現父類的run方法,然後在起線程的時候,調用其start方法。
1 public class DemoThreadDemoThread extends Thread {
2 public void run() {
3 System.out.println("我執行了一次!");
4 }
5
6 public static void main(String[] args) throws InterruptedException {
7 for (int i = 0; i < 3; i++) {
8 Thread thread = new DemoThreadDemoThread();
9 thread.start();
10 Thread.sleep(3000);
11 }
12 }
13 }
這裡,有些同學對start方法和run方法的作用理解有點問題,解釋一下:
|
start()方法被用來啟動新創建的線程,在start()內部調用了run()方法。 當你調用run()方法的時候,其實就和調用一個普通的方法沒有區別。 |
【第二種 · 實現Runnable接口】
第二種方法,是實現Runnable接口的run方法,在起線程的時候,如下,new一個Thread類,然後把類當做參數傳進去。
1 public class DemoThreadDemoRunnable implements Runnable { 2 public void run() { 3 System.out.println("我執行了一次!"); 4 } 5 6 public static void main(String[] args) throws InterruptedException { 7 for (int i = 0; i < 3; i++) { 8 Thread thread = new Thread(new DemoThreadDemoRunnable()); 9 thread.start(); 10 Thread.sleep(3000); 11 } 12 } 13 }
- 兩種基礎實現方式的選擇
這兩種方法看起來其實差不多,但是平時使用的時候我們如何做選擇呢?
一般而言,我們選擇Runnable會好一點;
首先,我們從代碼的架構考慮。
實際上,Runnable 里只有一個 run() 方法,它定義了需要執行的內容,在這種情況下,實現了 Runnable 與 Thread 類的解耦,Thread 類負責線程啟動和屬性設置等內容,權責分明。
第二點就是在某些情況下可以提高性能。
使用繼承 Thread 類方式,每次執行一次任務,都需要新建一個獨立的線程,執行完任務後線程走到生命周期的盡頭被銷毀,如果還想執行這個任務,就必須再新建一個繼承了 Thread 類的類,如果此時執行的內容比較少,比如只是在 run() 方法里簡單打印一行文字,那麼它所帶來的開銷並不大,相比於整個線程從開始創建到執行完畢被銷毀,這一系列的操作比 run() 方法打印文字本身帶來的開銷要大得多。
如果我們使用實現 Runnable 接口的方式,就可以把任務直接傳入線程池,使用一些固定的線程來完成任務,不需要每次新建銷毀線程,大大降低了性能開銷。
第三點好處在於可以繼承其他父類。
Java 語言不支持雙繼承,如果我們的類一旦繼承了 Thread 類,那麼它後續就沒有辦法再繼承其他的類,這樣一來,如果未來這個類需要繼承其他類實現一些功能上的拓展,它就沒有辦法做到了,相當於限制了代碼未來的可拓展性。
- 為什麼說Runnable和Thread其實是同一種創建線程的方法?
首先,我們可以去看看Thread的源碼,我們可以看到:

其實Thread類也是實現了Runnable接口,以下是Thread的run方法:

其中的target指的就是你是實現了Runnable接口的類:
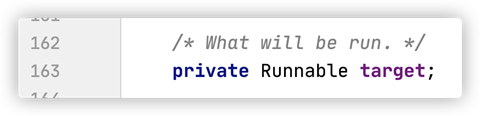
Thread被new出來之後,調用Thread的start方法,會調用其run方法,然後其實執行的就是Runnable接口的run方法(實現後的方法)。
所以,當你繼承了Thread之後,你實現的run方法其實還是Runnable接口的run方法,
因此,其實無返回值線程的實現方式只有一種,那就是實現Runnable接口的run方法,然後調用Thread的start方法,start方法內部會調用你寫的run方法,完成代碼邏輯。
【第三種 · 實現Callable接口】
第 3 種線程創建方式是通過有返回值的 Callable 創建線程。
Callable接口實際上是屬於Executor框架中的功能類,之後的部分會詳細講述Executor框架。
Callable和Runnable可以認為是兄弟關係,Callable的call()方法類似於Runnable接口中run()方法,都定義任務要完成的工作,實現這兩個接口時要分別重寫這兩個方法;
主要的不同之處是call()方法是有返回值的,運行Callable任務可以拿到一個Future對象,表示異步計算的結果。
我們通過Future對象可以了解任務執行情況,可取消任務的執行,還可獲取執行結果。
代碼示例如下:
1 public class DemoThreadDemoCallable implements Callable<Integer> { 2 3 private volatile static int count = 0; 4 5 public Integer call() { 6 System.out.println("我是callable,我執行了一次"); 7 return count++; 8 } 9 10 public static void main(String[] args) throws InterruptedException, ExecutionException { 11 List<FutureTask<Integer>> taskList = new ArrayList<FutureTask<Integer>>(); 12 13 for (int i = 0; i < 3; i++) { 14 FutureTask<Integer> futureTask = new FutureTask<Integer>(new DemoThreadDemoCallable()); 15 taskList.add(futureTask); 16 } 17 18 for (FutureTask<Integer> task : taskList) { 19 Thread.sleep(1000); 20 new Thread(task).start(); 21 } 22 23 // 一般這個時候是做一些別的事情 24 Thread.sleep(3000); 25 for (FutureTask<Integer> task : taskList) { 26 if (task.isDone()) { 27 System.out.printf("我是第%s次執行的!\n", task.get()); 28 } 29 } 30 } 31 }
執行結果如下:
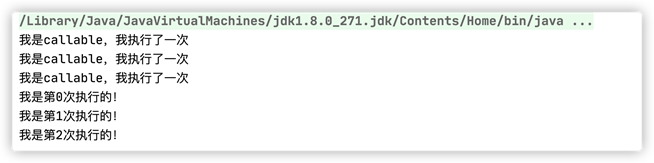
|
其中,count 使用volatile 修飾了一下,關於volatile 關鍵字,之後會再次講到,這裡先不說。 |
當然了,我們一般情況下,都會使用線程池來進行Callable的調用,如下代碼所示。
1 public class DemoThreadDemoCallablePool { 2 public static void main(String[] args) { 3 ExecutorService threadPool = Executors.newSingleThreadExecutor(); 4 Future<Integer> future = threadPool.submit(new DemoThreadDemoCallable()); 5 try { 6 System.out.println(future.get()); 7 } catch (Exception e) { 8 System.err.print(e.getMessage()); 9 } finally { 10 threadPool.shutdown(); 11 } 12 } 13 }
- Callable和Runnable的區別
最後,我們來看看Callable和Runnable的區別:
-
- Callable規定的方法是call(),而Runnable規定的方法是run()
- Callable的任務執行後可返回值,而Runnable的任務是不能返回值的(運行Callable任務可拿到一個Future對象, Future表示異步計算的結果)
- call()方法可拋出異常,而run()方法是不能拋出異常的
【三種創建線程的基礎方式圖示】
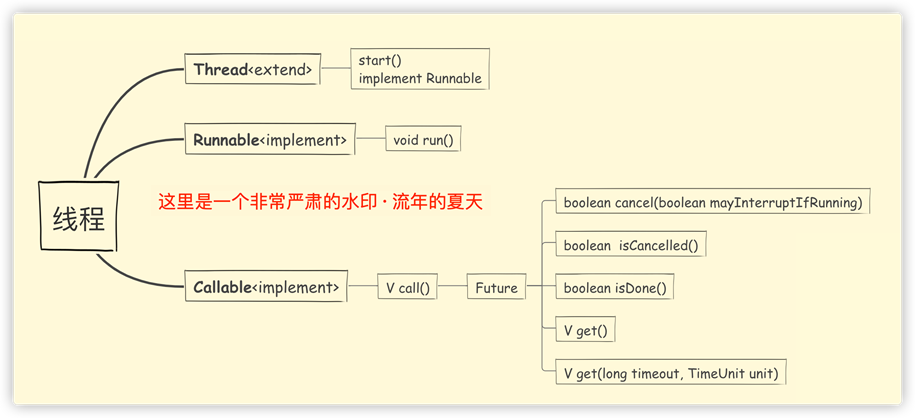
通過圖示基本上可以看得很清楚,Callable是需要Future接口的實現類搭配使用的;
Future接口一共有5個方法:
-
- boolean cancel(boolean mayInterruptIfRunning)
用於取消任務,如果取消任務成功則返回true,如果取消任務失敗則返回false。
參數mayInterruptIfRunning表示是否允許取消正在執行卻沒有執行完畢的任務,如果設置true,則表示可以取消正在執行過程中的任務。
如果任務已經完成,此方法返回false,即取消已經完成的任務會返回false;
如果任務正在執行,若mayInterruptIfRunning設置為true,則返回true,若mayInterruptIfRunning設置為false,則返回false;
如果任務還沒有執行,則無論mayInterruptIfRunning為true還是false,肯定返回true。
-
- boolean isCancelled()
如果在Callable任務正常完成前被取消,返回True
-
- boolean isDone()
若Callable任務完成,返回True
-
- V get() throws InterruptedException, ExecutionException
返回Callable里call()方法的返回值,調用這個方法會導致程序阻塞,必須等到子線程結束後才會得到返回值
-
- V get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException
用來獲取執行結果,如果在指定時間內,還沒獲取到結果,就直接返回null
事實上,FutureTask是Future接口唯一一個實現類。(只看了1.7和1.8,後面的版本沒有check)
【JVM線程模型】
在上一節的時候我們講了線程的生命周期和狀態,其實每一個線程,從創建到銷毀,都佔用了大量的CPU和內存,但是真正執行任務鎖佔用的資源可能並沒有很多,可能只能佔用到裏面很少的一部分。
在java裏面,使用線程執行異步任務的時候,如果每次都創建一個新的線程,那麼系統資源會大量被佔用,服務器會一直處於超高負荷的運算,最終很容易就會造成系統崩潰。
從jdk1.5開始,java將工作單元和執行機制分離,工作單元主要包括Runnable和Callable,執行機制就是Executor框架。
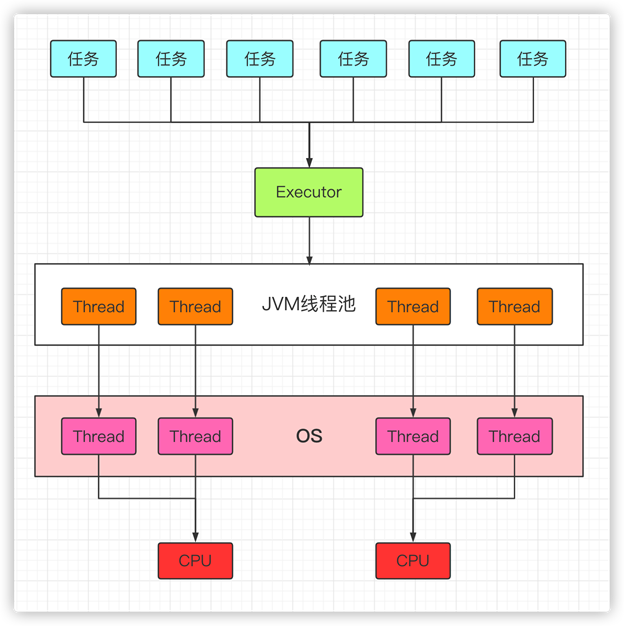
在HotSpot VM的線程模型中,Java線程會被一對一的映射成本地操作系統線程。(Java線程創建的時候,操作系統裏面會對應創建一個線程,Java線程被銷毀,操作系統中的線程也被銷毀)
在應用層,Java多線程程序會將整個應用分解成多個任務,然後運行的時候,會使用Executor將這些任務分配給固定的一些線程去分別執行,而底層操作系統內核會將這些線程映射到硬件處理器上,調用CPU進行執行。
類似下圖:
【Executor框架】
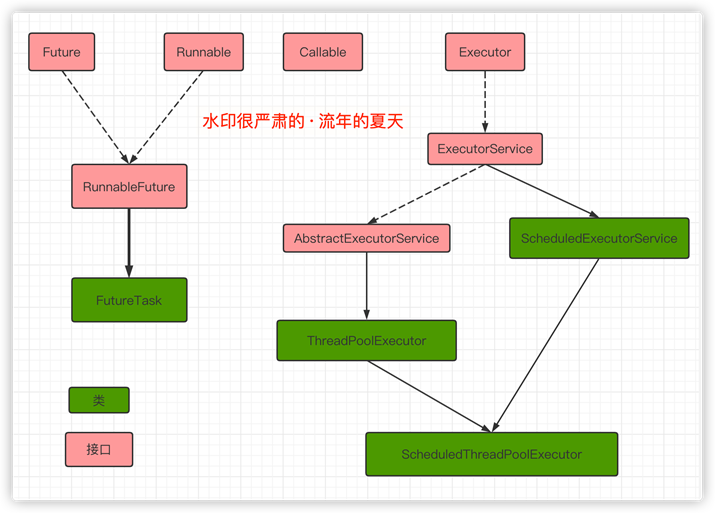
以上,是Executor框架結構圖解。
Executor框架包括3大部分:
-
- 任務
也就是工作單元,包括被執行任務需要實現的接口(Runnable/Callable)
-
- 任務的執行
把任務分派給多個線程的執行機制,包括Executor接口及繼承自Executor接口的ExecutorService接口。
-
- 異步計算的結果
包括Future接口及實現了Future接口的FutureTask類。
-
- Executor
Executor框架的基礎,將任務的提交和執行分離開。
-
- TreadPoolExecutor
線程池的核心實現類,用來執行被提交的任務。
通常使用Executors創建,一共有三種類型的ThreadPoolExecutor:
-
-
- SingleThreadExecutor(單線程)
- FixedThreadPool(限制當前線程數量)
- CachedThreadPool(大小無界的線程池)
-
-
- ScheduledThreadPoolExecutor
實現類,可以在一個給定的延遲時間後,運行命令,或者定期執行。
通常也是由Executor創建,一共有兩種類型的ScheduledThreadPoolExecutor。
-
-
- ScheduledThreadPoolExecutor(包含多個線程,周期性執行)
- SingleThreadScheduledExecutor(只包含一個線程)
-
-
- Future
異步計算的結果。
這裡在很多時候返回的是一個FutureTask的對象,但是並不是必須是FutureTask,只要是Future的實現類即可。
【TreadPoolExecutor】
之前已經說過,TreadPoolExecutor是線程池的核心實現類,所有線程池的底層實現都依靠它的構造函數:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
我們可以依次解釋一下:
- corePoolSize
核心線程數,也叫常駐線程數,線程池裡從創建之後會一直存在的線程數量。
- maximumPoolSize
最大線程數,線程池中最多存在的線程數量。
- keepAliveTime
空閑線程的存活時間,一個線程執行完任務之後,等待多久會被線程池回收。
- unit
keepAliveTime參數的單位
- workQueue
線程隊列(一般為阻塞隊列)
- threadFactory
線程工廠,用於創建線程
- handler
拒絕策略,由於達到線程邊界和隊列容量而阻止執行時使用的處理程序。
其實,線程池不能算作一種創建線程的方式,為什麼呢?
|
對於線程池而言,本質上是通過線程工廠創建線程的。 默認採用 DefaultThreadFactory ,它會給線程池創建的線程設置一些默認值,比如:線程的名字、是否是守護線程,以及線程的優先級等。
|
關於線程池的詳細概念內容,可先參考我的另外一篇博客:線程池略略觀,後面也會再說。
關於線程的主要創建方式,大概就是以上這些,下一篇,會講線程的基本屬性和主要方法。


