淺談sql索引
索引是什麼
假如你手上有一個你公司的客戶表,老闆說找什麼客戶你就得幫他找出來。
客戶不多的時候,你拿着手指一行一行滑,費不了多少時間就能找到。
後來公司做大了,客戶越來越多,好幾頁的客戶,你發現,一行一行滑真的好累啊,最主要找慢了還得挨老闆叼。
他媽的,吃力不討好。
那咋辦?
我相信這麼聰明的你不會坐以待斃的。
你可能會自己做一些記錄,比如拿個小本本寫上,
28歲的客戶在第一頁
29歲的客戶在第二頁
或者
姓張的客戶在第二頁
姓李的客戶在第三頁和第四頁
當然這些要根據那張客戶表的實際情況來。
這樣子,下次老闆叫你找29歲的客戶,你就一下子翻到第二頁,一下子就找到了,輕鬆又漂亮地解決了問題。
這麼機智地解決了問題,當上ceo,迎娶白富美就指日可待了。
好了,美好故事到此就結束了。
真實的情況是怎麼樣的呢?
真實的情況就是數據庫就是故事中的你,你就是故事中的老闆,故事中的小本本,就是咱們今天要講的索引。
索引的特點
那麼從這個故事中可以看出索引有什麼特點呢?
為了提高查找效率而建立
如果你不給數據庫加索引的話,多數情況下,它就真的是一行行找,效率極低。
數據量少的時候不需要索引
但數據量少的時候,也沒必要建索引,你想想啊,數據量少的時候,你一下子就找到了,速度比你去翻小本本時間可能還要快點,就不要浪費一個小本本了。
MySQL的索引本質也是一張表的,建立索引也需要相應的空間。
索引是建立在表的數據上的
上面的故事裏我也說了,小本本的內容要根據你表裡的實際情況來的。
這樣的話,如果建立了索引,就要注意兩個點:
-
不要實際刪除數據。
假如你有批客戶鬧掰了,你一生氣,把客戶表中那一整頁都撕了。
那你下次按照【31歲的客戶在第20頁】這個規則去找,但是前面的就被你撕了,現在31歲的客戶就提前了幾頁,你數到第20頁,發現找不到,人都傻了。
MySQL也是這樣的,如果刪除數據,會導致按照索引查找的數據不會在原先的位置上。 -
頻繁更新的字段不要建立索引。
假設用戶的年齡天天變,那最好也不要記在小本本上了,否則你每天都要去更新小本本,今天是【31歲的客戶在第20頁】,明天就要改成【32歲的客戶在第20頁】了。
MySQL也是這樣的,如果建立索引的字段頻繁更新,這樣便會導致之前建立的索引需要頻繁更新。
MySQL索引分類
人家MySQL建立索引的方式比我們記小本本的方式要聰明有效率地多了。
你可以看到我上面做小本本的方式都是根據表中的某一列來的,比如
【31歲的客戶在第20頁】這個是根據客戶的年齡這一列來做的;
【姓李的客戶在第三頁和第四頁】這個使用客戶的名字這一列來做的。
在MySQL中,我們也只是需要告訴MySQL用哪些列來做索引即可,然後接下來的事他就會自己做。
咱們建立的索引呢,根據使用列的情況不同,可以分類如下:
-
單值索引:即一個索引只包含單個列。一個表可以有多個單列索引。
-
唯一索引:索引列的值必須唯一,但允許有空值。
-
複合索引:即一個索引包含多個列。
假如現在有一個people表,內有字段id(主鍵不需要做索引),name,age,phone_number(電話號碼)那麼:
- 單值索引:可以單獨用name或age做一個索引,任何一個字段都可以。這樣的索引可以做多個。
- 唯一索引:和單值索引一樣,但做索引的該字段必須唯一,比如你確定people表中phone_number的值唯一的話,那麼便可以在上面建立唯一索引。
- 複合索引:可以用(name,age)或(age,phone_number)或(name,age,phone_number)做一個索引。
建議:建立複合索引,且一個表不要超過5個索引。
基本語法
-
創建(如果加上UNIQUE則創建唯一索引):
CREATE [UNIQUE] INDEX indexName ON mytable(columnname(length));
或
ALTER mytable ADD [UNIQUE] INDEX[indexName] ON (columnname(length)); -
刪除:
DROP INDEX [indexName] ON mytable; -
查看:
SHOW INDEX FROM table\G
MySQL索引結構
就是上面的索引建立好後,這事雖然不用我們管,但也可以了解一下,MySQL是按照什麼樣的策略去查找數據的呢。
有幾種結構,下面講的是比較常用的BTree結構。
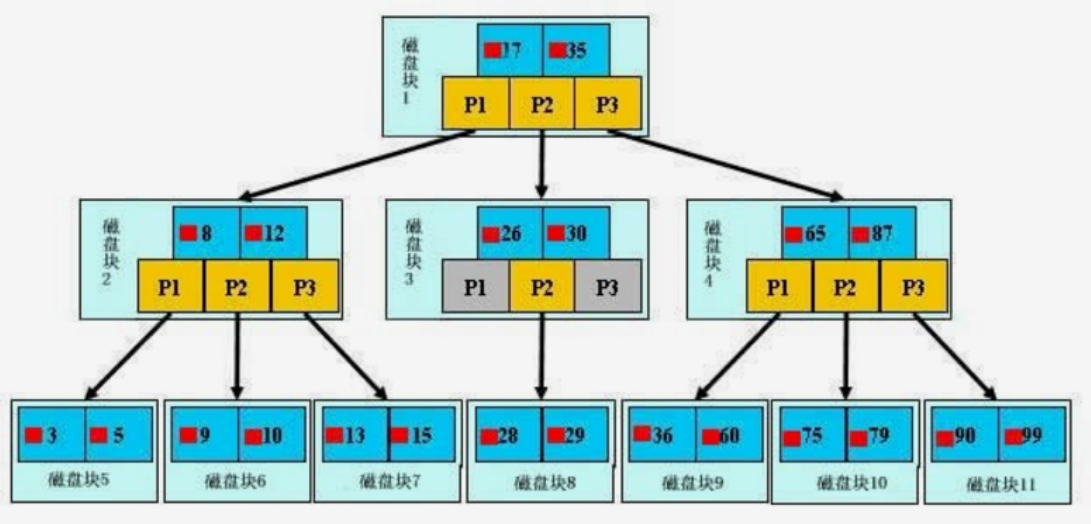
-
圖片介紹:
如圖一顆B+樹,淺藍色表示磁盤塊,每個磁盤塊包括幾個數據項(深藍色)和指針(黃色)。
如磁盤塊1包括數據項17和35,包含指針P1、P2、P3;P1表示小於17的磁盤塊,P2表示在17-35之間的磁盤塊,P3表示大於35的磁盤塊。
真實的數據只存在於葉子節點,非葉子節點不存儲真實數據,只存儲指引搜索方向的數據項。
如17、35並不真實存在數據表中。
-
查找過程(以上圖查找數據項29):
首先把磁盤塊1由磁盤加載到內存,此時發生一次IO;在內存中用二分查找確定29在17和35之間,鎖定磁盤塊1的P2指針,因為內存時間非常短(相比磁盤的IO)可以忽略不計。
將磁盤塊1的P2指向的磁盤塊3由磁盤加載到內存,發生第二次IO;確定29在26和30之間,指向磁盤塊3的P2指針。
將磁盤塊3的P2指針指向的磁盤塊8加載到內存,發生第三次IO,同時內存中做二分查找找到29。
查詢結束,總計三次IO。
-
真實的情況是:3層的B+樹可以表示上百萬的數據,如果上百萬的數據查找只需要3次IO,性能提高將是巨大的,如果沒有索引,每個數據項都要發生一次IO,那麼總共需要上百萬次IO。
-
總結:減少IO次數可以減少查詢時間,提高性能,那麼怎麼減少IO次數?
答案:增加樹的廣度而非深度。B+樹的葉子節點可以多。
建立索引的時機
哪些情況需要創建索引
- 主鍵自動建立唯一索引
- 頻繁作為查詢條件的字段應該創建索引
- 查詢中與其他表關聯的字段,外鍵關係建立索引
- 頻繁更新的字段不適合創建索引 — 因為每次更新不只更新記錄還會更新索引
- Where里用不到的字段的不創建索引
- 單鍵/組合索引的選擇問題 — 在高並發下傾向創建組合索引
- 查詢中排序的字段 — 排序字段若通過索引去訪問將大大提高排序速度
- 查詢中統計或者分組字段
哪些情況不需要創建索引
- 表記錄太少 — mysql300w左右就可以考慮建索引了
- 經常增刪改的表 — 因為索引要跟着更新
- 數據重複且分佈平均的表字段 — 可以用(該字段不同的數據的數量)/(該字段總的數據量),值越接近1,說明不怎麼重複,越有建索引的價值。


