HBase的架構設計為什麼這麼厲害!
老劉是一名即將找工作的研二學生,寫博客一方面是複習總結大數據開發的知識點,一方面是希望能夠幫助和自己一樣自學編程的夥伴。由於老劉是自學大數據開發,博客中肯定會存在一些不足,還希望大家能夠批評指正,讓我們一起進步!
今天為大家帶來的內容是HBase的架構設計,講講HBase的架構設計為什麼這麼牛?本文內容不會很長,全是老劉總結的精華,大家不可錯過!

1 背景
我們要提前知道兩個問題,這兩個問題的解決也恰好回答了HBase的架構設計為什麼這麼牛!
第一個問題是HBase作為一個分佈式數據庫,它是如何確保在海量數據中,做到低延時的隨機讀寫的呢?
第二個問題是Hbase是如何確保在分佈式架構中,保證數據安全的呢?
2 第一個問題解答
確保在海量數據中,低延時的隨機讀寫,HBase真的花了很多心思,做了很多設計,下面讓老劉給大家好好說一說!
2.1 內存+磁盤
這個設計在眾多框架中都存在,這樣做的好處是在數據安全性和數據操作效率之間做了一個權衡,既追求數據安全,也追求數據操作效率。
2.2 內存數據良好的數據結構
HBase為了確保數據操作有更高的效率,也為了保證內存中的數據刷寫出來形成有序的文件,這句話是什麼意思?什麼是數據操作更加高效?
即內存文件為了保證插入刪除數據等操作高效,數據有序,所以用到了ConcurentSkipListMap的數據結構!
2.3 範圍分區+排序
海量數據做查詢一般採用什麼方法?
最粗暴的方式就是暴力掃描,但大家一般都不採用,道理都懂!所以我們一般會採用先排序,再範圍分區+分段掃描的辦法。那海量數據為了能夠讓數據有序,在採用插入數據過程中,怎麼做到數據有序的呢?
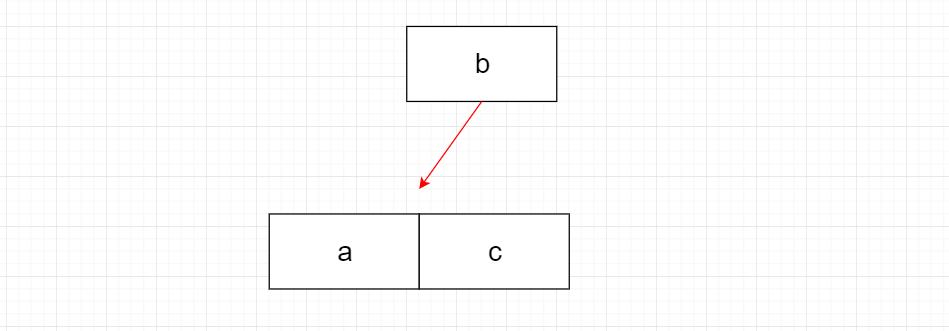
根據上圖,老劉來解釋下其中的道理,a先來c隨後,最後b也來了,但我們如何做到把b放在a和c之間呢?
先把數據放在內存裏面,a和c已經相鄰,現在b來了,要保證abc這樣的順序,其實很容易做到,我們可以利用數組或鏈表,把c往後面挪,再把b插入進來,但內存有限,就需要每隔一段時間,把內存中數據寫入到磁盤文件,磁盤裡的文件就是有序,這樣就能方便以後快速定位!
2.4 跳錶Topo結構
這是什麼意思呢?其實說的是HBase的尋址方式。
HBase的尋址方式分兩種,一種是0.96版本之前,一種是0.96版本之後。
在HBase-0.96版本以前,HBase有兩個特殊的表,分別是-ROOT-表和.META.表,其中-ROOT-的位置存儲在ZooKeeper中,-ROOT-本身存儲了.META. Table的RegionInfo信息 。尋址方式的流程如下:
- Client請求ZooKeeper獲得-ROOT-所在的RegionServer地址。
- Client請求-ROOT-所在的RS地址,獲取.META.表的地址,Client會將-ROOT-的相關信息cache下來,以便下一次快速訪問。
- Client請求.META.表的RegionServer地址,獲取訪問數據所在RegionServer的地址,Client會將.META.的相關信息cache下來,以便下一次快速訪問。
- Client請求訪問數據所在RegionServer的地址,獲取對應的數據。
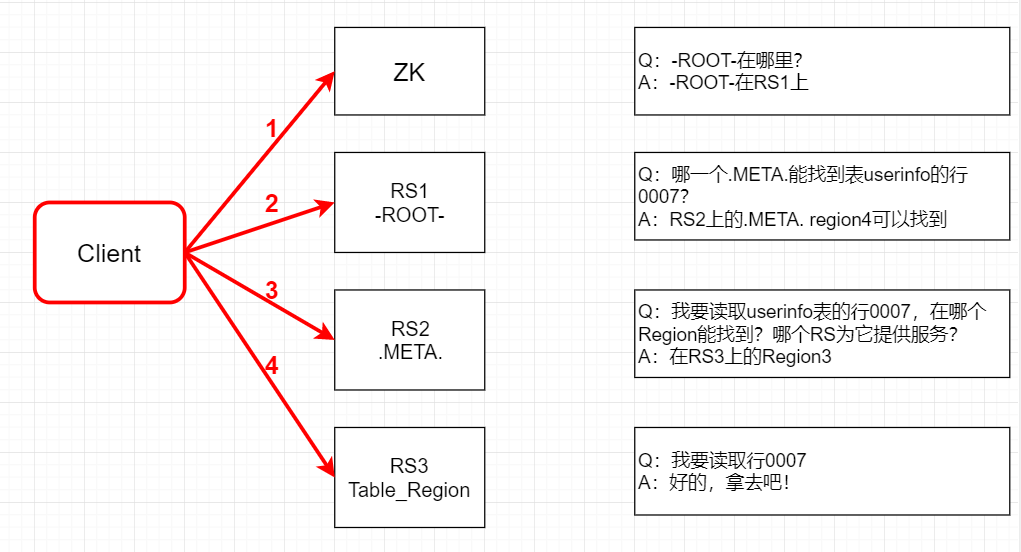
我們可以看出,用戶需要3次請求才能知道用戶表真正的位置,這在一定程度上帶來性能的下降。在0.96之前使用3層設計的主要原因是考慮到元數據可能需要很大。
那0.96版本之後的尋址流程如下:
- Client請求ZooKeeper獲取.META.所在的RegionServer的地址。
- Client請求.META.所在的RegionServer獲取訪問數據所在的RegionServer地址,Client會
將.META.的相關信息cache下來,以便下一次快速訪問。 - Client請求數據所在的RegionServer,獲取所需要的數據。
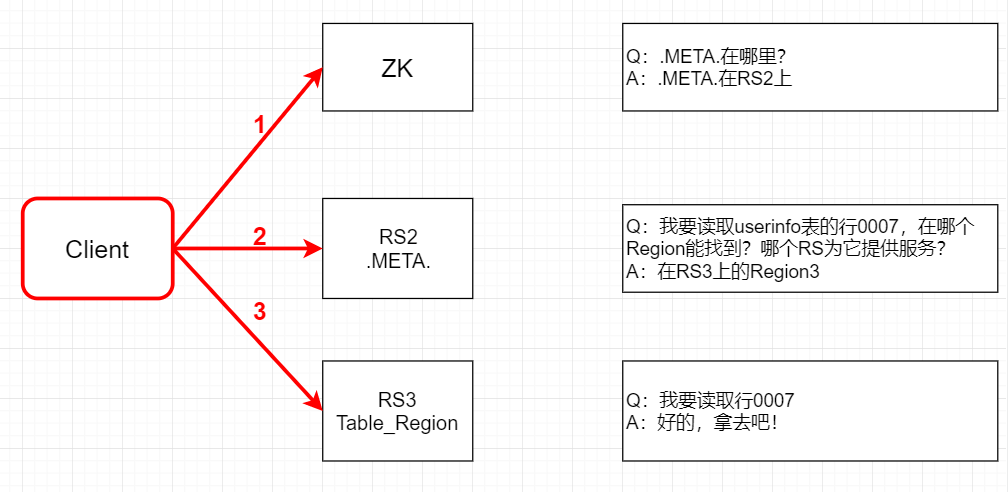
去掉-ROOT-的原因主要就是HBase-1.x以後,默認每個region的最大大小為10G,之前是128M,現在就發現2層的結構已經滿足集群的需求了,性能也相對提高了。
講完Region尋址方式,回到正題跳錶Topo結構,就拿0.96版本之前的講,跳錶有三層,第一層是user table,第二層是meta table,第三層是root table,那為什麼要設計這樣的跳錶呢?
假設有一張表的數據特別大,一台服務器存不下來,就需要把這張表拆分成好幾個部分(例如4個部分)。如果這張表再進行拆分的時候老早已經排好順序,那拆分出來的數據應該是一段一段的,每一段就包含了這一段的所有數據。
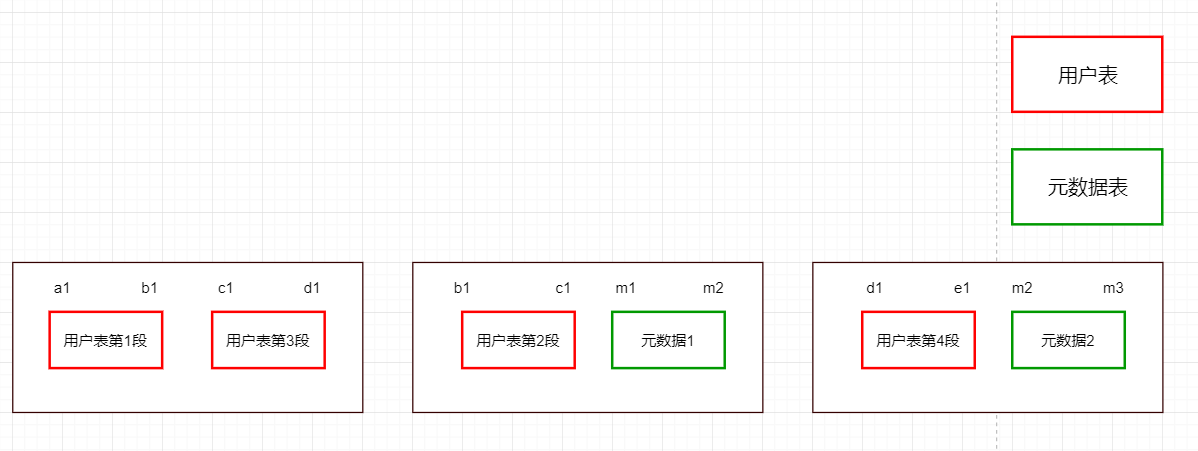
那客戶端現在來查詢數據,過來掃描數據,那它到底掃描哪一台服務器呢?我們不確定,可能每台服務器都要掃描一遍,這樣做導致效率很差!
我們可以先去找一個中間機構去確認要找的數據在這4段中的哪一段,創建一個元數據表meta存真正數據的Region位置,先去找meta表。當元數據表變得特別大,也會切分多個段放在RegionServer中,這個時候就會提供一個ROOT表來確定meta表的位置。
這就形成了一種層級關係,從ROOT表跳到meta表跳到具體RegionServer。
形成跳錶Topo結構降低了掃描次數,原來需要n次或4次掃描,現在變為1次掃描,性能得到提高,並且可以管理非常多的數據。
如何理解可以管理非常多的數據?
hbase1.0之前,每個Region默認大小是128M,每條元數據為1KB,那它就能存儲1千多個元數據,那3層結構就會存儲幾千萬上億的記錄。hbase1.0之後,每個Region默認大小是10G,兩層結構能夠存儲的數據也足夠大,滿足集群需求。
2.5 讀緩存+寫緩存
內存分讀緩存和寫緩存,把經常查詢的數據放在讀緩存,可以提升效率。寫緩存怎麼掃描文件速率最高?就是利用內存+磁盤的方式,先把數據放在內存排序後,再把數據寫入到磁盤中,這樣磁盤裡的文件就是有序的了,接着對磁盤文件二分查找,效率變高。
3 第二個問題解答
為了確保在分佈式架構中,數據的安全,HBase怎麼做?
3.1 內存+磁盤
HBase採用了內存+磁盤存儲的方式,這樣做的好處是在數據安全性和數據操作效率之間做了一個權衡,既追求數據安全,也追求數據操作效率。
3.2 WAL機制
WAL意為Write Ahead Log,類似MySQL中的binlog,用來做災難恢復之用。HBase為了防止數據寫入緩存之後不會因RegionServer進程發生異常導致數據丟失,在寫入緩存之前會首先將數據順序寫入到HLog(WAL)中。如果不幸一旦發生RegionServer宕機或者其他異常,這種設計可以從HLog中進行日誌回放進行數據補救,保證數據不丟失。HBase故障恢復的最大看點就在於如何通過HLog回放補救丟失數據。
4 總結
好啦,HBase的架構設計大致聊得差不多了,老劉主要給大家講了講為什麼HBase的架構設計這麼牛。儘管當前水平可能不及各位大佬,但老劉還是希望能夠變得更加優秀,能夠幫助更多自學編程的夥伴。
如果有相關問題,請聯繫公眾號:努力的老劉。如果覺得幫到了您,不妨點贊關注支持一波!


