MySQL 集群知識點整理
隨着項目架構的不斷擴大,單台 MySQL 已經不能滿足需要了,所以需要搭建集群將前來的請求進行分流處理。博客主要根據丁奇老師的專欄<<MySQL實戰45講>>學習的總結。
架構
MySQL的集群和 Redis 集群類似,都是默認為master 庫,可以設置為從庫,主庫負責處理寫請求,從庫處理讀請求。一般將從庫設置為 read-only,也就是將這個參數設為 true。這樣既避免了在主從切換、測試時從庫的誤操作導致主從不一致,同時也可以通過這個屬性來判斷當前庫是什麼角色。
種類
1、按 master 數量來看,架構可以分為兩種。
第一種是明確的主備關係,這種使用的不多,因為在主備切換時會比較耗時。
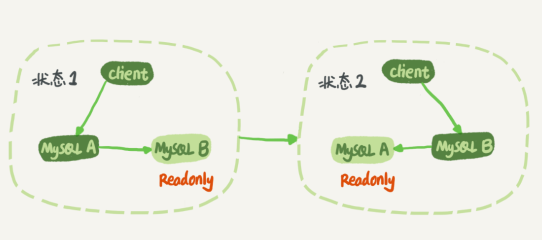
第二種是有多個master,master 之間互為主備關係,只不過保留一個處理寫操作,其他的設置 readonly=true,只處理讀請求。這種架構在切換時比較方便、快捷。
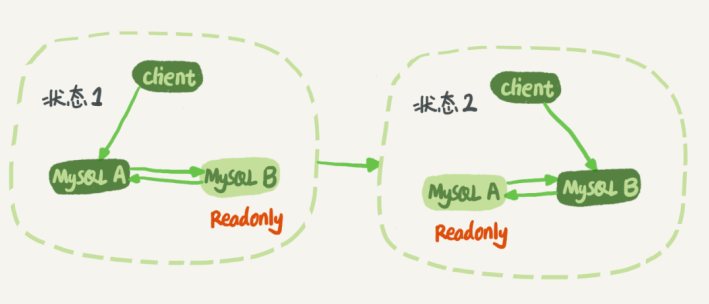
2、按是否代理的角度來看,也可以分為兩種。
第一種是不使用代理。這種方式的好處是架構簡單、執行快、排錯快。缺點是在主備切換、庫遷移時需要改變後台數據庫連接信息。
第二種是使用代理。這樣做的好處是後端不需要關注數據庫操作的細節,連接維護、後台信息維護都是由 proxy 完成的。但缺點也很明顯,這樣的架構比較複雜,配置、維護起來比較吃力,且 proxy 必須是高可用的。

搭建
1、配置master:
1)打開配置文件(默認在/usr/my.cnf),主要配置的參數:
server-id:當前庫的 id
log-bin:binlog 存儲位置
read-only:是否只讀。1代表只讀,0代表讀寫。
binlog-ignore-db:不保存操作到binlog 的數據庫,可以設為 mysql
然後重啟:service mysql restart ;
2)創建同步數據的賬戶,並授權:
grant replication slave on *.* to ‘用戶名’@”ip地址’ identified by ‘密碼’ ;
flush privilages;
3)查看 master 狀態:show master status。得到 Position 值(日誌最新寫入點)。
2、配置 slave:
1)打開配置文件my.cnf,配置參數 server-id 、log-bin、read-only。然後重啟。
2)配置從庫與主庫的關聯:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password MASTER_LOG_FILE=$master_log_name MASTER_LOG_POS=$master_log_pos
MASTER_HOST、MASTER_PORT、MASTER_USER 和 MASTER_PASSWORD 四個參數,分別代表了主庫 A』的 IP、端口、用戶名和密碼。最後兩個參數 MASTER_LOG_FILE 和 MASTER_LOG_POS 表示,要從主庫的 master_log_name 文件的 master_log_pos 這個位置的日誌繼續同步。而這個值就是前面讀取的 Position 值。
上面這種是5.6之前通過位點來實現同步的,其存在很多不足,比如這個位點在主庫切換時需要重新去獲取,並且在新的主庫啟動後從庫可能會導致操作重複執行導致拋出異常,所以在5.6引入了 GTID來替換位點,解決了這個問題。具體在下文會解釋。這裡先說一下使用 GTID 來完成主備連接。
1)首先要在主從庫上都設置參數:SET GLOBAL ENFORCE_GTID_CONSISTENCY = ‘ON’; SET GLOBAL GTID_MODE = ‘ON’; 如果要永久有效,在配置文件 my.cnf 中配置 gtid-mode=ON enforce-gtid-consistency=1 。
2)配置從庫與主庫的關聯:
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1 。
最後開啟同步:start slave;
原理

內部執行圖:
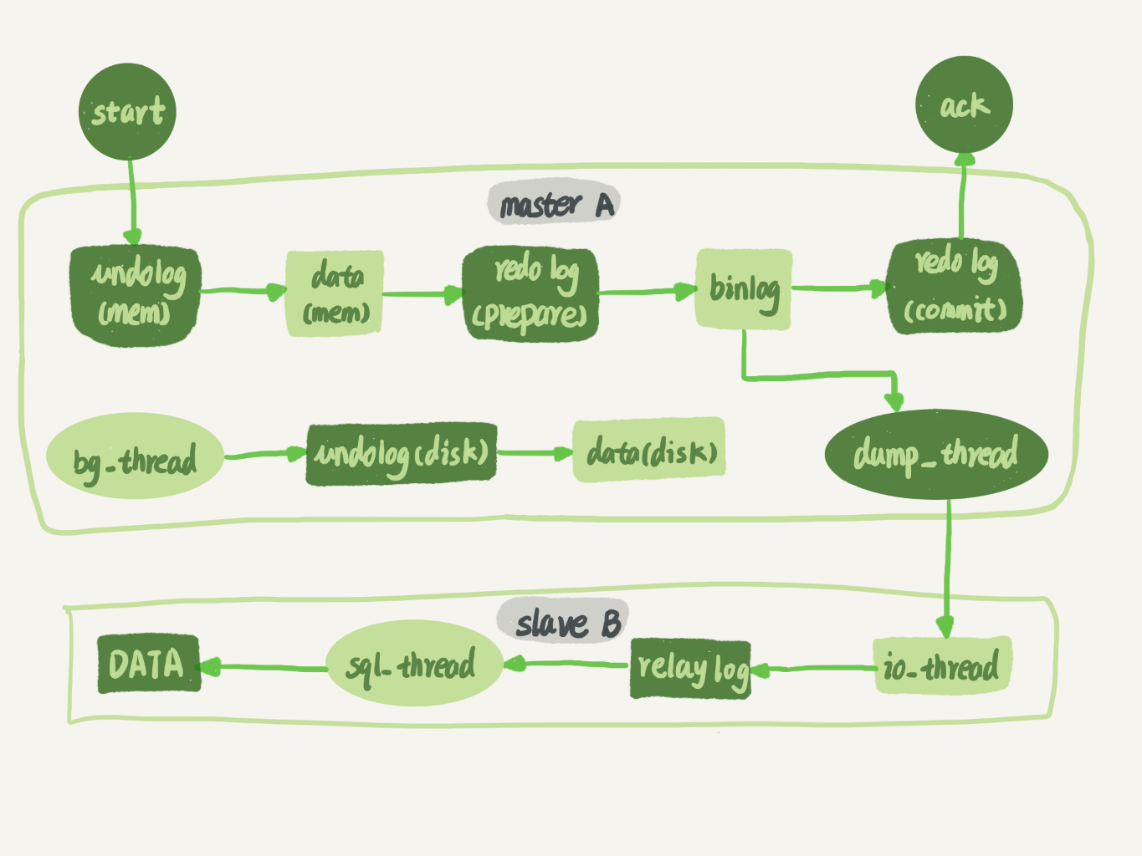
1、在備庫 B 上通過 change master 命令,設置主庫 A 的 IP、端口、用戶名、密碼,以及要從哪個位置開始請求 binlog,這個位置包含文件名和日誌偏移量。
2、在備庫 B 上執行 start slave 命令,這時候備庫會啟動兩個線程,就是圖中的 io_thread 和 sql_thread。其中 io_thread 負責與主庫建立連接。
3、主庫 A 校驗完用戶名、密碼後,開始按照備庫 B 傳過來的位置,從本地讀取 binlog(先從page cache中讀取,沒有再讀取磁盤),發給 B。
4、備庫 B 拿到 binlog 後,寫到本地文件,稱為中轉日誌(relay log)。
5、sql_thread 讀取中轉日誌,解析出日誌里的命令,並執行。
循環複製
這裡從庫可以將從主庫傳來的更新的數據也進行持久化記錄在本地的 binlog 中,通過將參數 log_slave_updates 設為 on 來開啟這個功能。但是這樣可能會發生循環複製。
更新操作的 binlog 的執行機制:某個庫處理了寫操作,那麼它就會將這個寫操作相關的 binlog 發送給其他與其關聯的庫,這個 binlog 上會記錄當前庫的 server-id,其他庫收到 binlog 後會判斷 server-id 是否是當前庫的 server-id,如果不是就應用到庫中並記錄到 binlog(這裡記錄不會改變原有的接收到的數據,也就不是修改 server-id),然後再重複將寫操作的 binlog 發送給其他庫。
發生循環複製的場景:
1、主庫執行寫操作後,修改了當前庫的 server-id。因為修改了server-id,所以主庫在受到從庫發送回來的日誌後還會繼續執行,執行完後還會重複發給從庫,造成循環。
解決:這種只能提前規定庫的 server-id 在運行時不能修改。
2、三節點中某個節點執行寫操作後將寫操作傳給其他兩個節點後另外兩個節點發生了循環複製。
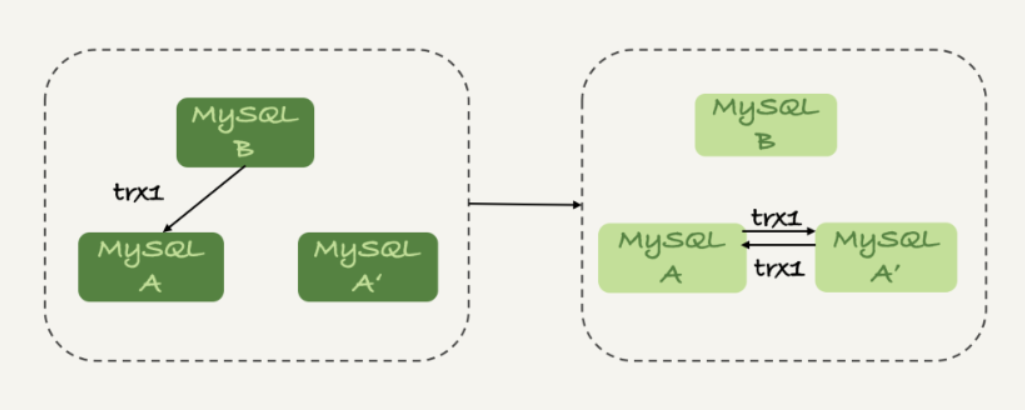
解決:先停止日誌的發送,一段時間後再改回來。
stop slave; CHANGE MASTER TO IGNORE_SERVER_IDS=(server_id_of_B); start slave;
主從切換
主從切換指的就是主庫與備庫身份的切換。
切換策略
可靠性優先策略(優先)
可靠性優先策略是將數據的可靠性設為優先進行切換的策略。其核心就是先關閉主庫A對寫請求的處理,然後等待備庫的數據延遲變為0,也就是備庫B讀取完從主庫A傳來的所有操作日誌且全部落盤。這時再將備庫B設為新的主庫B。
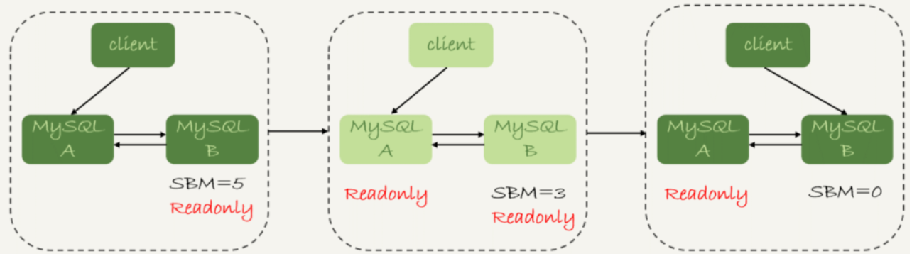
1、判斷備庫 B 現在的 seconds_behind_master(通過 show slave status 查看),如果小於某個值(比如 5 秒)繼續下一步,否則持續重試這一步;
2、把主庫 A 改成只讀狀態,即把 readonly 設置為 true;
3、判斷備庫 B 的 seconds_behind_master 的值,直到這個值變成 0 為止;(最耗時)
4、把備庫 B 改成可讀寫狀態,也就是把 readonly 設置為 false;
5、把業務請求切到備庫 B。
因為是可靠性優先,所以用這種方式切換後讀取的數據是可以保證準確性的。缺點是因為在開始需要等待備庫B與主庫A的延遲變為0後 B庫才可以設為主庫,而在這等待的過程中前來的寫請求是無法被處理的,全部會被阻塞,如果並發的寫操作很多,那麼就會很影響系統的響應性能。
可用性優先策略
可用性優先策略是將上面可靠性優先策略步驟里的4,5提前到最開始執行,這樣就不會出現寫操作被阻塞的情況了,保證了可用性。但是這樣帶來的缺點是很嚴重的。可用性優先策略執行過程會根據 binlog 格式的不同有所不同。
1、mixed 格式
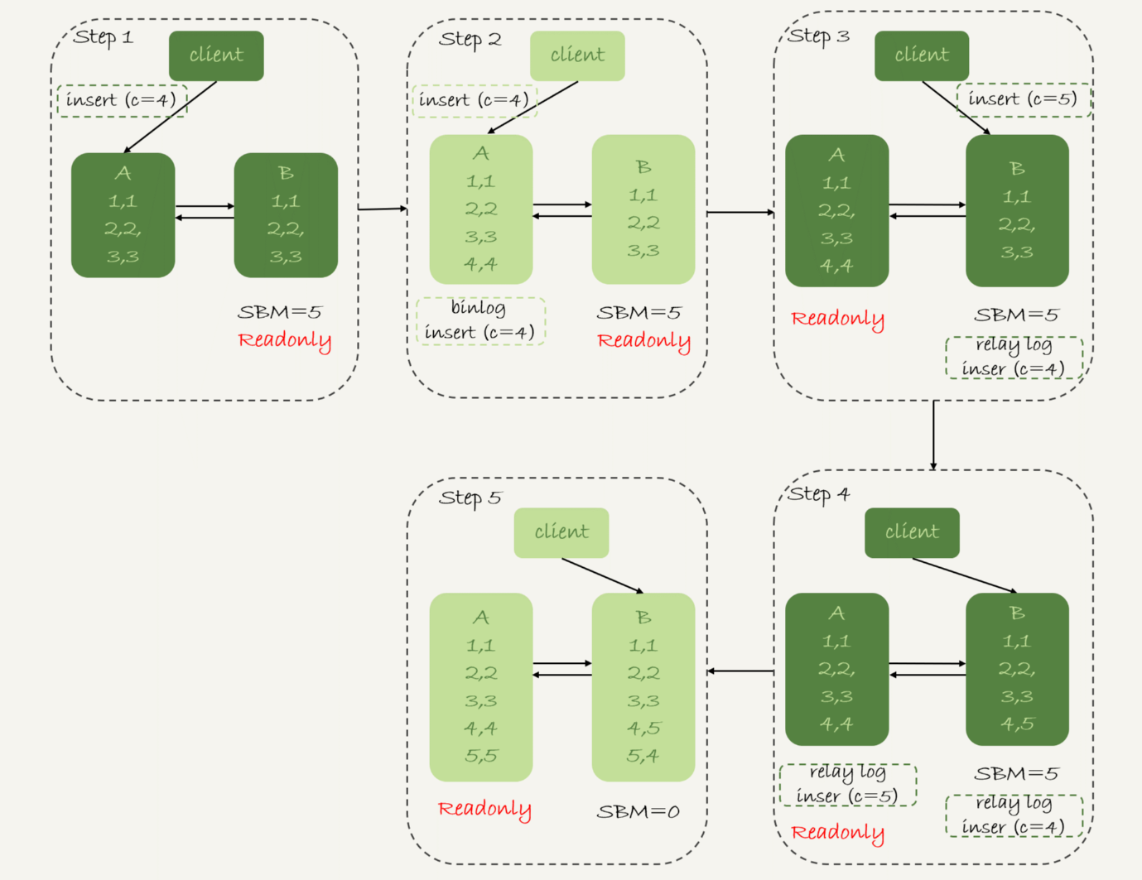
主鍵是自增的。執行過程:
1、步驟 2 中,主庫 A 執行完 insert 語句,插入了一行數據(4,4),之後開始進行主備切換。
2、步驟 3 中,由於主備之間有 5 秒的延遲,所以備庫 B 還沒來得及應用「插入 c=4」這個中轉日誌,就開始接收客戶端「插入 c=5」的命令。
3、步驟 4 中,備庫 B 插入了一行數據(4,5),並且把這個 binlog 發給主庫 A。
4、步驟 5 中,備庫 B 執行「插入 c=4」這個中轉日誌,插入了一行數據(5,4)。而直接在備庫 B 執行的「插入 c=5」這個語句,傳到主庫 A,就插入了一行新數據(5,5)。
最終導致主從數據不一致,同時在查詢相應數據時會返回錯誤的數據,並且還無法被發現,這是非常致命的。
2、Row 格式
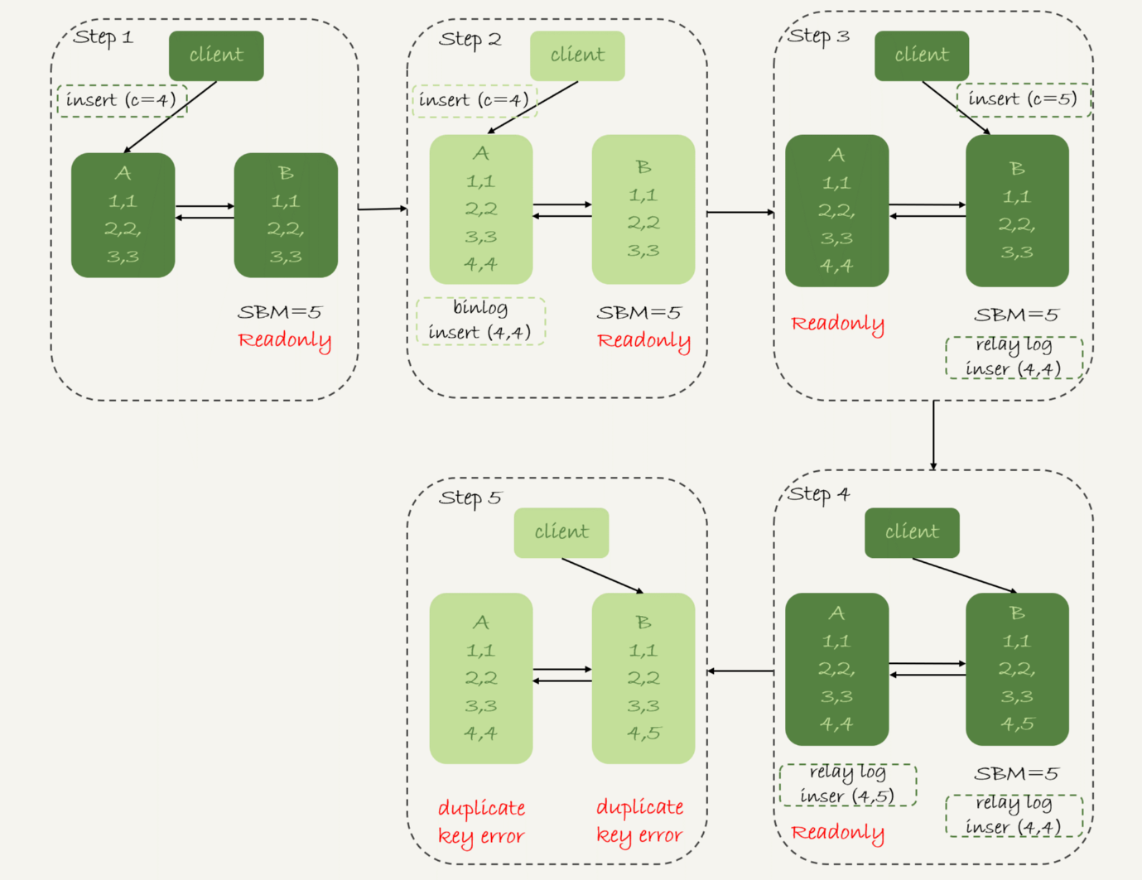
在使用 row 格式的 binlog 進行日誌記錄,那麼記錄的是完整的操作數據,所以不會出現上面出現的情況,並且在發生這種異常時會拋出異常提示。
總結
因為可用性優先策略很容易造成數據不一致,所以 一般使用的都是可靠性優先策略,但是因為可靠性策略在等待備庫趕上主庫時寫操作會被阻塞,所以主從延遲就決定了 MySQL 的可用性。主從延遲越低,主庫在異常宕機後,從機就越快趕上主庫的數據,更快恢復。
主從同步方式
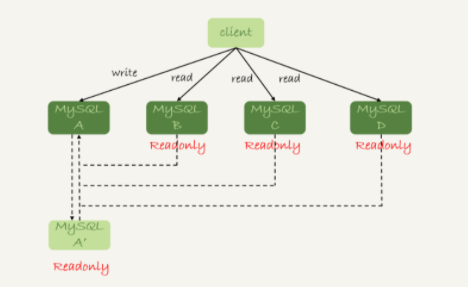
這裡以一主多從的架構為例說明。
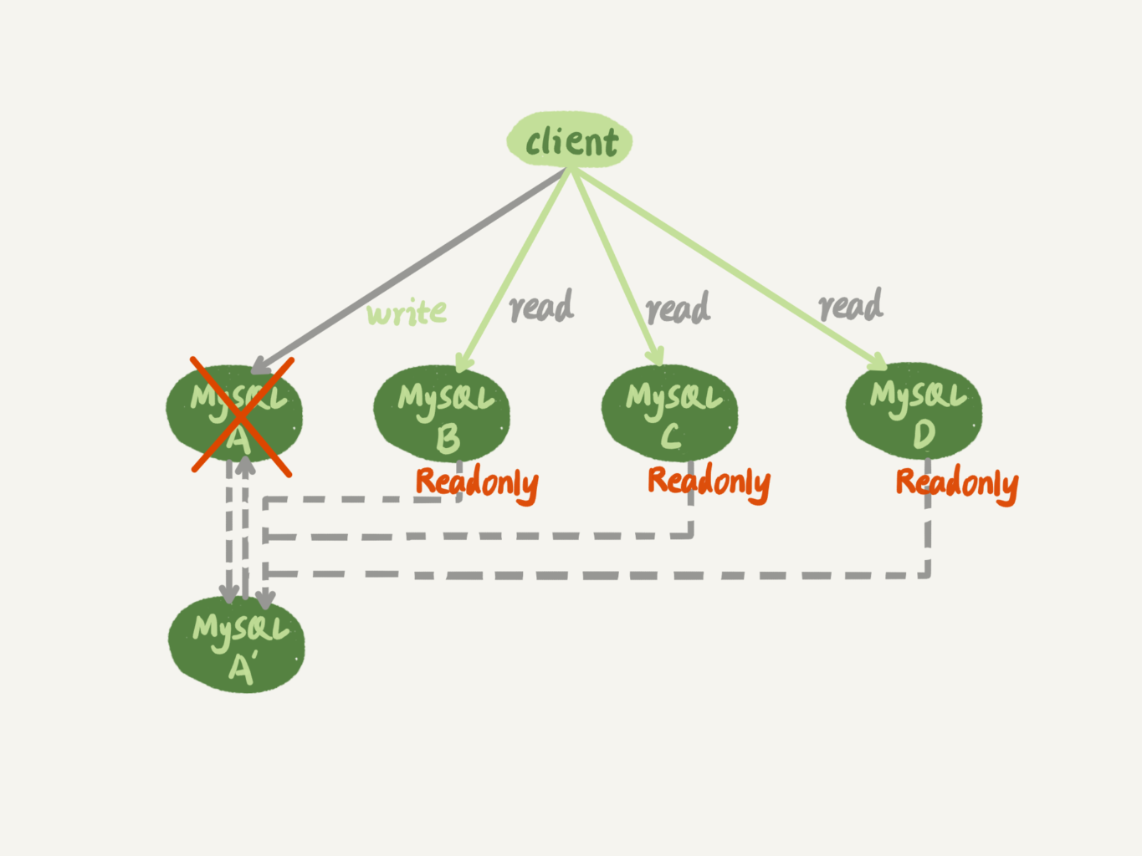
假設原本 A 是主機,A’ 和 A 互為主備關係,只不過 A’ read-only 設為 true,B、C、D都是A的從庫。這時A突然宕機,那麼想要將 A’ 設為新的主機,並且將 B、C、D 的從屬關係變為 A’。
通過日誌的同步位點(傳統方式)
在上面搭建時在配置從庫與主庫的關聯時說到有兩種方式,第一種就是通過日誌位點來確定從庫開始接收日誌的起始點,這種方式在初始配置時可以直接查看並賦值,但是如果中間主機宕機或者主動切換時就比較麻煩了。所以此時需要做的是:
1、等待新主庫 A』把中轉日誌(relay log)全部同步完成;
2、在 A』上執行 show master status 命令,得到當前 A』上最新的 File 和 Position;
3、取原主庫 A 故障的時刻 T;
4、用 mysqlbinlog 工具解析 A』的 File,得到 T 時刻的位點。mysqlbinlog File –stop-datetime=T –start-datetime=T
![]()
得到 123,將這個值作為位點來設置B、C、D 的從屬關係。
位點不準確:通過上面方法得到的值並一定是準確的,如果主庫 A 在宕機前剛執行了一條insert事務,並且將此事務發給了 A『、B,傳完後立刻宕機,那麼 A’、B 都已經同步了這一行 insert 事務,這時將 A’ 作為主機啟動,然後在將 B 的從屬關係改成 A’ 時把 Position 還寫成讀取到的 insert 事務那一行,那麼就會重複執行,如果格式是 row 的話就會拋出異常(statement 就會造成主從不一致)。
如果是拋出異常,就會斷開與主庫的連接,所以需要我們去處理,恢復連接。
解決方式:
1、拋出異常後跳過。
跳過:set global sql_slave_skip_counter=1;
開啟從庫:start slave;
2、跳過指定的錯誤(不推薦)。
上面重複執行遇到的錯誤主要是兩種:1062,插入數據時唯一鍵不唯一;1032,刪除數據時找不到行。
所以可以將 slave_skip_errors 設為 “1032、1062″。
通過這種方式如果後端傳來的請求也會造成這樣的錯誤則也會被跳過,所以可能會引起後端無法收到反饋。這種方式只適用於無法確定同步點且確定到從庫恢復這段時間不會有 1032、1062 的事務,並且在一段時間後還需要將這個參數修改回去。
通過GTID(推薦)
是什麼:GTID 是 MySQL5.6 引入的概念,表示的是全局事務ID,是一個事務的唯一標識,由兩部分組成,格式是:
官方文檔是:GTID=source_id:transaction_id
便於理解可以看作:GTID=server_uuid:gno
server_uuid 是一個實例第一次啟動時自動生成的,是一個全局唯一的值;
gno 是一個整數,初始值是 1,每次提交事務的時候分配給這個事務,並加 1。
transaction_id 是事務id,但是事務回滾的話,這個值也會自增。
使用:數據庫在啟動時加上參數 gtid_mode=on 和 enforce_gtid_consistency=on 來開啟 GTID,如果要永久有效,在配置文件 my.cnf 中配置 gtid-mode=ON enforce-gtid-consistency=1 。
在主機A 宕機後,改變從庫 B、C、D 的 slave 關係時使用
CHANGE MASTER TO MASTER_HOST=$host_name MASTER_PORT=$port MASTER_USER=$user_name MASTER_PASSWORD=$password master_auto_position=1
切換原理:
1、將實例A’的 GTID 集合記為 set_a,實例B 的 GTID 集合記為 set_b。那麼執行邏輯如下:
2、實例 B 指定主庫 A』,基於主備協議建立連接。
3、實例 B 把 set_b 發給主庫 A』。
4、實例 A』算出 set_a 與 set_b 的差集,也就是所有存在於 set_a,但是不存在於 set_b 的 GTID 的集合,判斷 A』本地是否包含了這個差集需要的所有 binlog 事務。
a. 如果不包含,表示 A』已經把實例 B 需要的 binlog 給刪掉了,直接返回錯誤;
b. 如果確認全部包含,A』從自己的 binlog 文件裏面,找出第一個不在 set_b 的事務,發給 B;
5、之後就從這個事務開始,往後讀文件,按順序取 binlog 發給 B 去執行。
GTID生成方式:
1、gtid_next=automatic。
使用默認值,會使用默認分配的 server_uuid:gno 分配給這個事務。
在記錄 binlog 時會自動先記錄一行 SET @@SESSION.GTID_NEXT=『server_uuid:gno』;
來表示將這個事務的 GTID加入集合,從庫執行時也會先檢查
2、gtid_next =’指定的值’
通過 set gtid_next = ‘指定的值’,然後就會檢查GTID集合是否已存在這個值,如果存在下一個事務就會跳過。
例子:
庫X
CREATE TABLE `t` ( `id` int(11) NOT NULL, `c` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB; insert into t values(1,1);
記錄操作在binlog相關的 GTID如下:
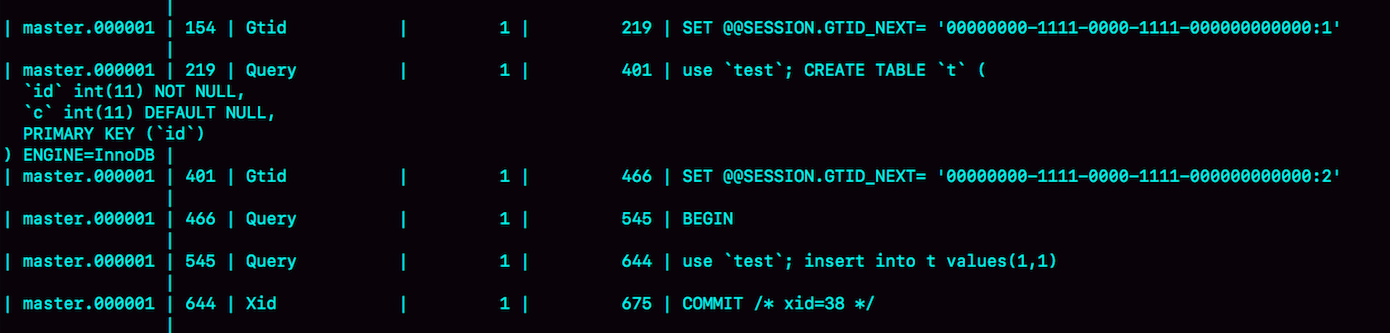
可以看到 insert 操作對應的 GTID 是 ‘00000000-1111-0000-1111-000000000000:2’。此時將其設為Y的從庫,在主庫Y上執行 insert into t values(1,1),這條語句在實例 Y 上的 GTID 是 「aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10」;那麼如何避免從庫X發生異常?
答:從庫(應該)執行下面的操作
set gtid_next='aaaaaaaa-cccc-dddd-eeee-ffffffffffff:10'; begin; commit; set gtid_next=automatic; start slave;
這裡是執行一個空事務,作用是向從庫的 GTID集合中添加主庫這條記錄的GTID,從庫在和主庫比較時就會自動跳過這條操作的事務
優點:將原本通過日誌位點來匹配的方式簡化了,對使用人員非常友好。
問題:如果一個新的從庫接上主庫,但是需要的 binlog 已經沒了,要怎麼做?(對應上面切換原理4.a 的情況)
答:1、如果業務允許主從不一致的情況,那麼可以在主庫上先執行 show global variables like 『gtid_purged』,得到主庫已經刪除的 GTID 集合,假設是 gtid_purged1;然後先在從庫上執行 reset master,再執行 set global gtid_purged =『gtid_purged1』;最後執行 start slave,就會從主庫現存的 binlog 開始同步。binlog 缺失的那一部分,數據在從庫上就可能會有丟失,造成主從不一致。
2、如果需要主從數據一致的話,最好還是通過重新搭建從庫來做。
3、如果有其他的從庫保留有全量的 binlog 的話,可以把新的從庫先接到這個保留了全量 binlog 的從庫,追上日誌以後,如果有需要,再接回主庫。
4、如果 binlog 有備份的情況,可以先在從庫上應用缺失的 binlog,然後再執行 start slave。
主備延遲(MySQL的可用性)
在上面的我們說到一般項目使用的都是可靠性優先策略,所以 MySQL 的可用性就決定於主從延遲。
主備延遲的來源
1、備庫所在的機器性能比主庫所在的機器性能差。也就是從庫 binlog 落盤的速度比主庫 binlog 寫操作慢,主從延遲越來越高。
2、備庫壓力大。解決:1)使用一主多從架構 2)通過 binlog 輸出到外部系統,比如 Hadoop 這類系統,讓外部系統提供統計類查詢的能力。
3、大事務在從庫執行的時間比較長,導致數據更新的延遲變長。 解決:1)如果長事務的操作比較多,嘗試將事務拆分成多個事務 2)如果是大表 DDL 語句,可以使用開源項目 gh-ost 進行調節。
4、備庫的並行複製能力比較差。MySQL 的並行複製能力是比較重要的。
MySQL的並行複製
回顧一下操作執行在主備庫中的流程圖:
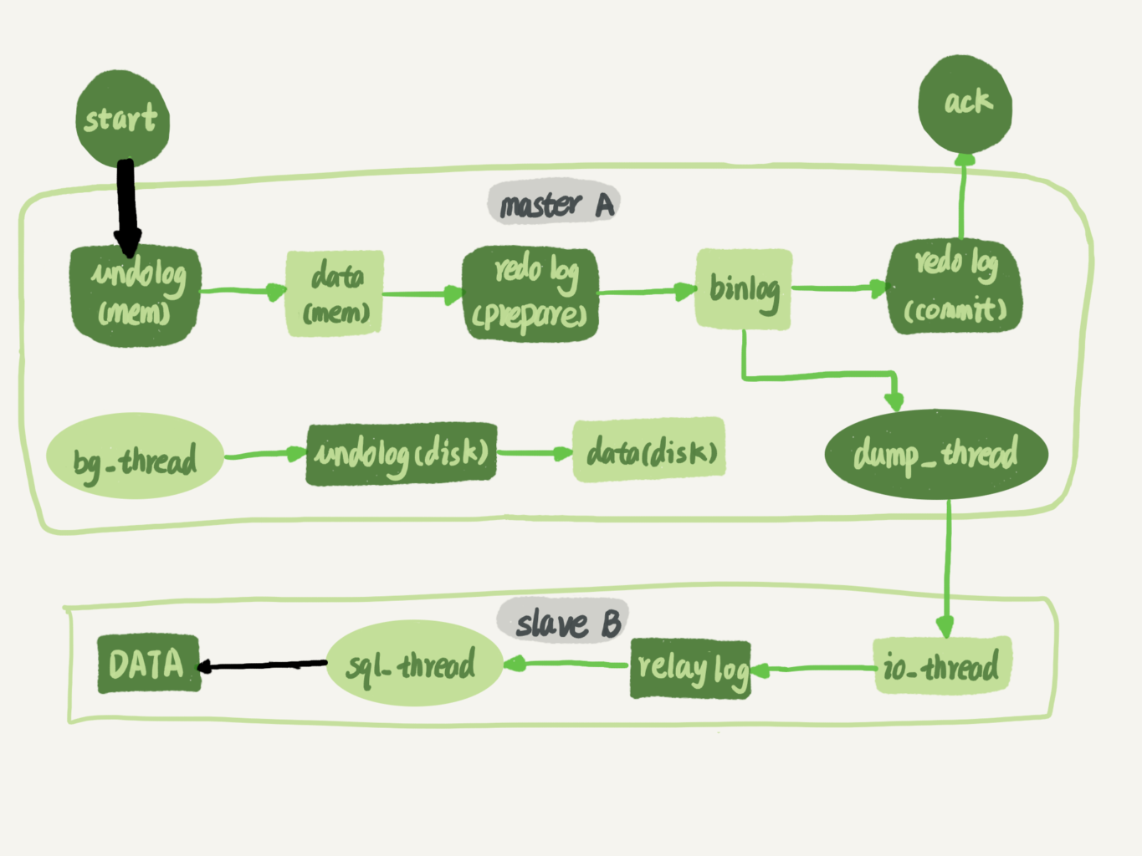
黑箭頭代表主備的並行複製能力,主庫上處理的是寫操作,因為 InnoDB 支持行鎖,再搭配數據庫的多線程,吞吐量很高。而備庫中讀取傳來解析日誌的 sql_thread 是單線程,而在備庫中落盤的過程也是經歷了從單線程到多線程的過程。在5.6之前,備庫將主庫傳來的日誌落盤都是單線程,所以就是圖中的細黑箭頭。
在5.6開始,備庫的落盤就變成了多線程,執行圖就變成下面這種:
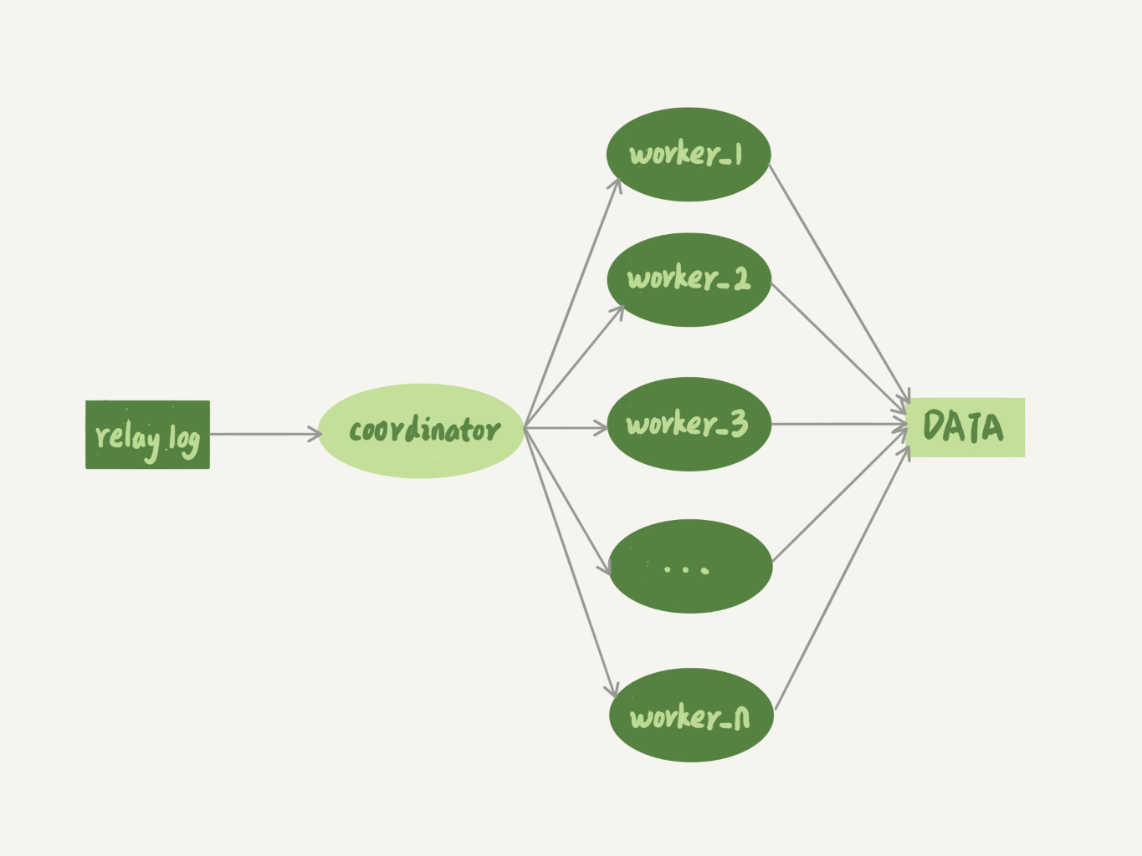
coordinator 就是原來的 sql_thread, 不過現在它不再直接更新數據了,只負責讀取中轉日誌和分發事務。真正更新日誌的,變成了 worker 線程。
work 線程數配置:slave_parallel_workers。這個值設置為 8~16 之間最好(32 核物理機的情況),畢竟備庫還有可能要提供讀查詢,不能把 CPU 都吃光了。
coordinator 分發滿足的基本條件:
1、更新同一行的事務必須分發給同一個worker線程
2、同一個事務的所有操作必須分給同一個worker線程
coordinator 分發規則:
1、如果跟所有 worker 都不衝突,coordinator 線程就會把這個事務分配給最空閑的 woker;
2、如果跟多於一個 worker 衝突,coordinator 線程就進入等待狀態,直到和這個事務存在衝突關係的 worker 只剩下 1 個;
3、如果只跟一個 worker 衝突,coordinator 線程就會把這個事務分配給這個存在衝突關係的 worker。
1、5.6 按庫並行複製
思路:每個 worker 線程內部維護一個 hash 表,key 是 “庫名”,value 表示這個線程內有多少事務即將或正在執行這個庫。某個事務在被分配時,會根據 coordinator 分發規則來進行。
例子:假設有一個事務T,會操作庫 db1、db3,那麼 coordinator 會先判斷 worker_1 線程,發現存在操作 db1 的事務,所以換下一個;
緊接着發現 worker_2 也存在操作 db3 的事務,所以就會進入阻塞等待。如果後面 worker_2 中操作 db3的事務執行完畢,value變為0,那麼 coordinator 就會識別到,只剩 worker_1 與事務 T 有衝突,那麼就將 T 分配給 worker_1。
優點:1)在分析構造 hash 時非常快 2)對 binlog 的格式沒有要求(不會發生主從不一致)
缺點:並發度不高,如果操作都集中在某一個庫,那麼執行就和使用單線程一樣。
2、mariaDB 並行複製策略
雖然不是 MySQL 的策略,但是因為它的思想對 MySQL 後續版本有啟迪作用,所以這裡也說一下。
思路:因為有 ” 組提交 ” 機制(不知道組提交可以查看 組提交),位於一組提交的事務是可以並行複製的。一組提交的事務一定不會存在操作同一行記錄的操作,這是因為主庫執行寫操作時,如果存在處理同一行記錄的兩個事務,那麼其中一個一定會被行鎖所阻塞,” 被阻塞 ” 的事務也就無法與 ” 阻塞 ” 事務一同提交了。執行過程就如下:
1、在一組裏面一起提交的事務,有一個相同的 commit_id,下一組就是 commit_id+1;
2、commit_id 直接寫到 binlog 裏面;
3、傳到備庫應用的時候,相同 commit_id 的事務分發到多個 worker 執行;
4、這一組全部執行完成後,coordinator 再去取下一批。
缺點:1)雖然是隨着主庫執行順序來執行的,但是效率並沒有主庫高。
主庫在前一組事務提交寫盤的同時下一組事務已經在執行了,而備庫上需要上一組事務完全落盤後才可以開始下一組事務的執行。
主庫:

備庫:
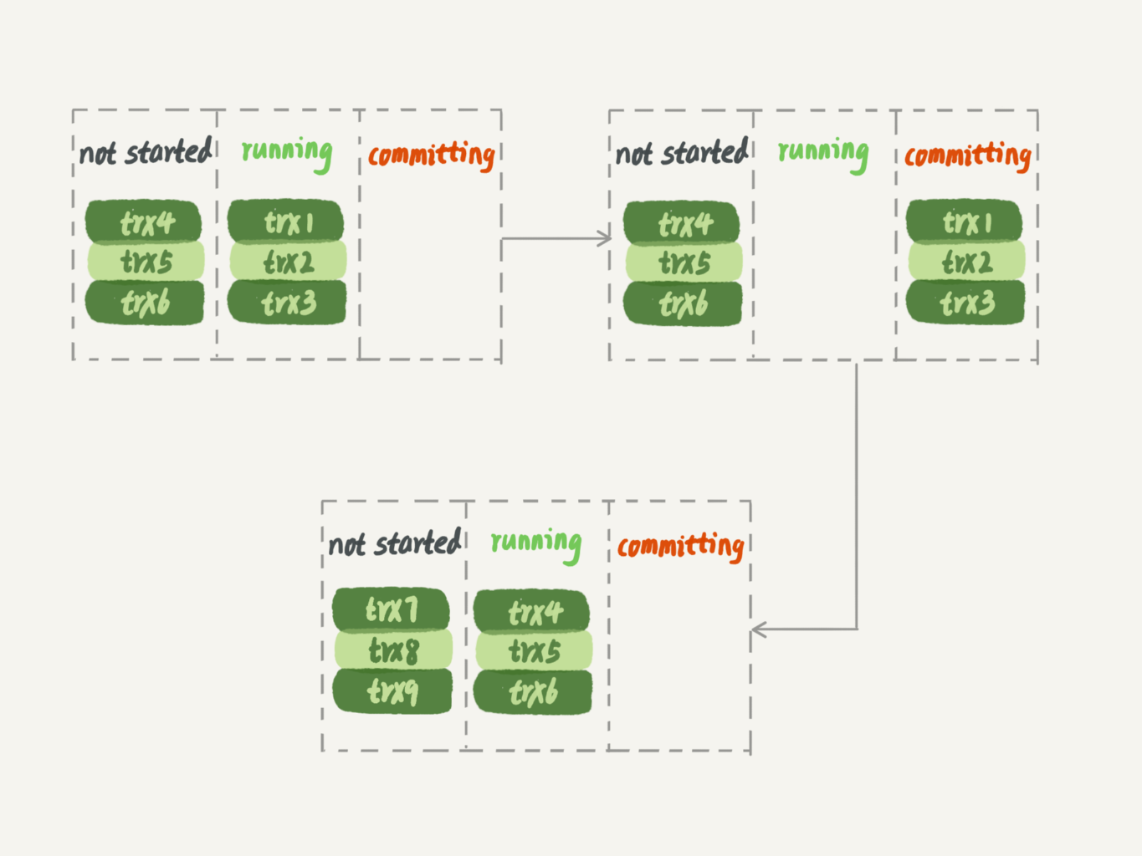
2)如果一組中的一個事務是大事務,那麼其他兩個事務執行完還需要等待這個事務執行完才能開始下一組事務的開始
4、5.7 結合了mariaDB 的思想
MySQL 在5.7 版本融合了 mariaDB 的思想並進行了一些改進。
思想:模式分成兩種,通過參數 slave-parallel-type 設置。
1)配置為 DATABASE。保持5.6 的策略,按庫執行
2)配置為 LOGICAL_CLOCK。和 mariaDB 的組提交來執行,只不過進行一些變化。在 mariaDB 中是在上一組事務完全 commit 後,也就是在三步提交中這一組事務全部到達 redo log commit 階段後才能進行下一組事務的執行;而在這個版本中則將下一組事務執行的時間提前到 redo log prepare ,只要全部到達 redo log prepare 階段就可以執行下一組事務了。這個原因也很簡單,到達 redo log prepare 階段說明事務已經執行完成。
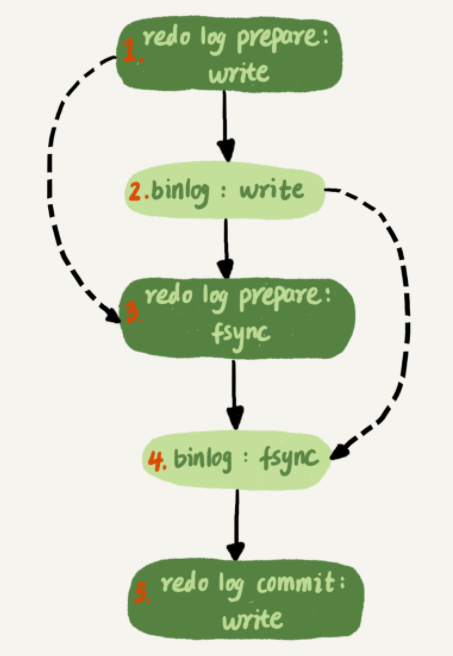
參數配置:binlog_group_commit_sync_delay、 binlog_group_commit_sync_no_delay_count 。這兩個參數作用的都是在 binlog 完成 write 後到 fsync 的過程。分別表示 binlog 延遲多少微秒後才調 fsync、binlog 累積多少次以後才調用 fsync。通過這兩個參數可以將更多的事務添加到一個組中,使備庫的並發度更高。
5、5.7.22 提出了按行並行複製
在這個版本中拋棄了按庫並行的思想。並且引入了按行並行。
思想:分為三種。通過參數 binlog-transaction-dependency-tracking 配置。
1)COMMIT_ORDER。還是上個版本中的按事務組來執行。
2)WRITESET(重要)。按行並行複製。對於事務涉及更新的每一行,計算這一行的 hash 值,組成集合 writeset。如果兩個事務沒有操作相同的行,那麼他們就可以並行執行。 hash 值的計算是” 庫名+表名+索引名+值 “,這裡的索引指的是所有的唯一索引,值表示索引對應的值。
優勢:
Ⅰ、writeset 是在主庫生成後直接寫入到 binlog 裏面的,這樣在備庫執行的時候,不需要解析 binlog 內容(event 里的行數據),節省了很多計算量;
Ⅱ、不需要把整個事務的 binlog 都掃一遍才能決定分發到哪個 worker,更省內存;
Ⅲ、由於備庫的分發策略不依賴於 binlog 內容,所以 binlog 是 statement 格式也是可以的。
不足:對於「表上沒主鍵」和「外鍵約束」的場景,WRITESET 策略也是沒法並行的,也會暫時退化為單線程模型。
3)WRITESET_SESSION。在按行並行的基礎上,對主庫同一個線程先後事務的執行順序,在備庫執行時也需要保證。
問題:單線程添加很多記錄,在從庫追主庫的過程中,binlog-transaction-dependency-tracking 應該選用什麼參數?
答:由於主庫是單線程壓力模式,所以每個事務的 commit_id 都不同,那麼設置為 COMMIT_ORDER 模式的話,從庫也只能單線程執行。同樣地,由於 WRITESET_SESSION 模式要求在備庫應用日誌的時候,同一個線程的日誌必須與主庫上執行的先後順序相同,也會導致主庫單線程壓力模式下退化成單線程複製。所以,應該將 binlog-transaction-dependency-tracking 設置為 WRITESET。
主備延遲問題
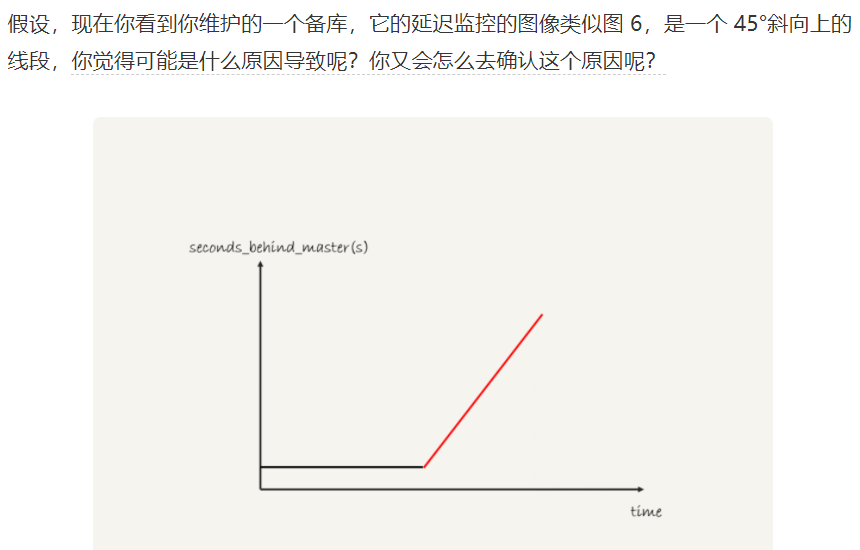
原因:因為 seconds_behind_master 是備庫以當前系統時間減去執行事務開始寫入時間得出的。
1、主庫執行了大事務(大表DDL、一個事務操作很多行)
2、備庫起了一個長事務,如
begin; select * from t limit 1;
然後就不動了,這時候主庫執行了一個DDL操作,添加一個字段,那麼就會被堵住。
解決過期讀
” 過期讀 ” 指的是在主庫操作某行記錄後,立刻進行查詢,那麼查詢會被從庫所執行,這樣主庫上的 binlog 還未更新到從庫上,所以讀請求返回的結果還是修改前的記錄。下面是幾種解決 ” 過期讀 ” 的方式。
1、強制走主庫(使用最多,準確)
思想:對於必須要拿到最新值的請求,強制發送給主庫執行;對於可以讀到舊數據的請求,發送給從庫執行。
總結:實現簡單,對於必須拿最新值的請求的數量不多的場景可以使用。但是在數量多的場景使用這種方式會使主庫的壓力變大,演變成單庫模式。
2、Sleep(不準確)
思想:在從庫執行前,先 sleep 一下,類似執行一條 sleep(1) 的命令。類似的業務實現比如在淘寶購買成功後並不是直接跳轉到訂單頁面,而是跳轉到 ” 購買成功 ” 的提示頁面,如果想查看這個訂單,需要點擊查看訂單,這就給了從庫來同步主庫的時間。
不足:1)因為總會延遲,如果主從延遲只有0.5秒也需要經過這個時間才能得到數據。 2)如果是大事務,應用到從庫所要的時間比較長,那麼還是會發生 ” 過期讀 “。
3、寫請求在主從無延遲後再返回(不太準確)
思想
實現主備無延遲主要有四種方案。
1)查看 seconds_behind_master 是否已經等於0。seconds_behind_master 單位是秒,精度不夠,所以用於檢驗準確性不是很高。
2)對比位點,比較 binlog 日誌讀取的位點。相比於第一種準確一些。通過 show slave status 查看當前從庫的相關參數;通過 show master status 查看主機的相關參數。
Master_Log_File 和 Read_Master_Log_Pos,表示的是讀到的主庫的最新位點;
Relay_Master_Log_File 和 Exec_Master_Log_Pos,表示的是備庫執行的最新位點。
如果 Master_Log_File 和 Relay_Master_Log_File、Read_Master_Log_Pos 和 Exec_Master_Log_Pos 這兩組值完全相同,就表示接收到的日誌已經同步完成。
3)對比當前備庫和所有備庫已經執行的 GTID 集合。相比於第一種準確一些。
Auto_Position=1 ,表示這對主備關係使用了 GTID 協議。
Retrieved_Gtid_Set,是備庫收到的所有日誌的 GTID 集合;
Executed_Gtid_Set,是備庫所有已經執行完成的 GTID 集合。
如果這兩個集合相同,也表示備庫接收到的日誌都已經同步完成。
問題:2)、3)為什麼會不準確?
答:一個事務的執行順序如下:
Ⅰ、主庫執行完成,寫入 binlog,並反饋給客戶端;
Ⅱ、binlog 被從主庫發送給備庫,備庫收到;
Ⅲ、在備庫執行 binlog 完成。
如果在1、2之間判斷就會以為是最新的,沒有問題,直接進行操作,導致 ” 過期讀 “。
4)使用 semi-sync(搭配2、3)。semi-sync 是半同步複製(emi-sync replication),而2、3 是異步複製,也就是在主庫寫完 binlog 後就會發送消息給客戶端。而執行過程如下:
Ⅰ、事務提交的時候,主庫把 binlog 發給從庫;
Ⅱ、從庫收到 binlog 以後,發回給主庫一個 ack,表示收到了;
Ⅲ、主庫收到這個 ack 以後,才能給客戶端返回「事務完成」的確認。
通過 semi-sync 可以解決2、3出現的問題,同時在主庫異常斷電時也可以避免主庫在寫完 binlog 還未將 binlog 發送給從庫就宕機,導致從庫未收到 binlog 導致主庫重啟後主從不一致。
缺點
1)只適用於一主一從。因為這個模式的執行過程是主庫收到 ACK 確認後立刻就會反饋給請求發送方信息,如果是一主多從,那麼任何一台從機返回的 ACK 都會使主庫立刻返回反饋信息給請求,這樣如果再次發送讀該數據的請求,並且請求被分配到還未同步的從庫,那麼又會發生 “過期讀”。
2)在持續延遲的情況下,可能出現過度等待的問題。

如果按2,3判斷,直到狀態4都無法執行讀操作,而實際上在狀態2就可以讀了。
4、先在一段時間內嘗試在從庫上執行,如果沒有同步再在主庫上執行(準確)
這種方式有兩種實現方案。
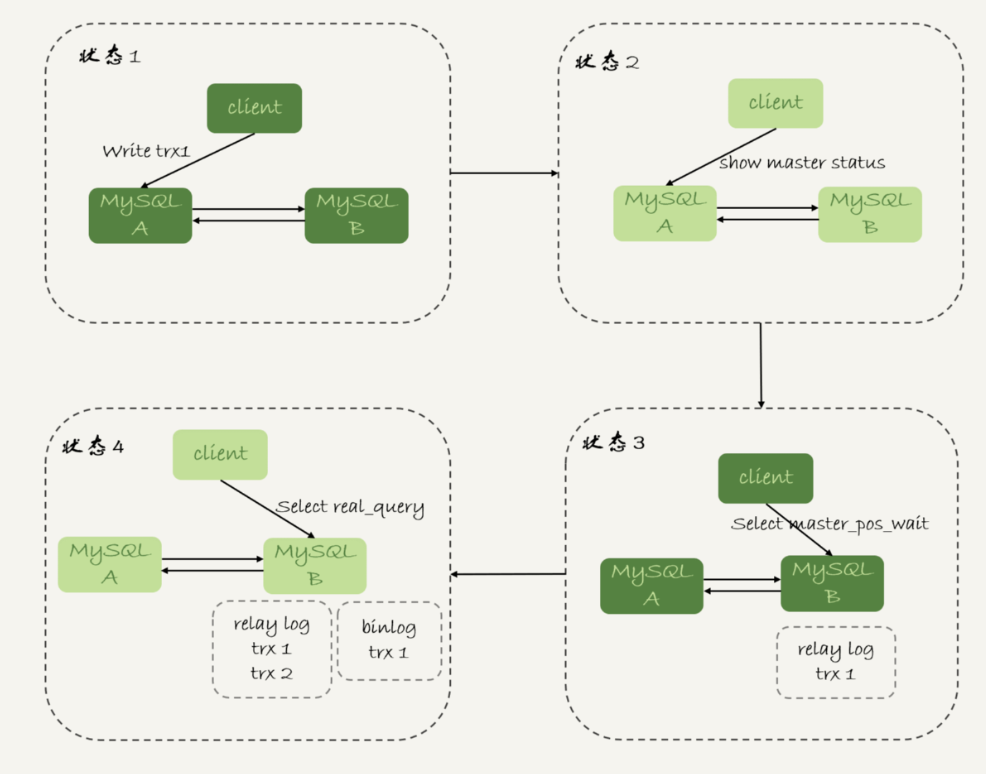
1)等主庫位點方案
原理:
實現主要通過命令:select master_pos_wait(file, pos, timeout); 特點如下:
Ⅰ、它是在從庫執行的;
Ⅱ、參數 file 和 pos 指的是主庫上的文件名和位置;
Ⅲ、timeout 可選,設置為正整數 N 表示這個函數最多等待 N 秒。
Ⅳ:返回值:一、正常返回的結果是一個正整數 M,表示從命令開始執行,到應用完 file 和 pos 表示的 binlog 位置,執行了多少事務。
二、如果執行期間,備庫同步線程發生異常,則返回 NULL;
三、如果等待超過 N 秒,就返回 -1;
四、如果剛開始執行的時候,就發現已經執行過這個位置了,則返回 0。
執行邏輯:
假設客戶端接收的延遲為1秒,那麼執行邏輯就如下:
Ⅰ、trx1 事務更新完成後,馬上執行 show master status 得到當前主庫執行到的 File 和 Position;
Ⅱ、選定一個從庫執行查詢語句;
Ⅲ、在從庫上執行 select master_pos_wait(File, Position, 1);
Ⅳ、如果返回值是 >=0 的正整數,則在這個從庫執行查詢語句;
Ⅴ、否則,到主庫執行查詢語句。
2)GTID 方案
原理:
主要通過命令: select wait_for_executed_gtid_set(gtid_set, timeout);
語句作用:等待,直到這個庫執行的事務中包含傳入的 gtid_set,返回0;超時返回1。
執行邏輯:
還是假設客戶端接收的延遲為1秒,執行邏輯如下:
Ⅰ、trx1 事務更新完成後,從返回包直接獲取這個事務的 GTID,記為 gtid1;
Ⅱ、選定一個從庫執行查詢語句;
Ⅲ、在從庫上執行 select wait_for_executed_gtid_set(gtid1, 1);
Ⅳ、如果返回值是 0,則在這個從庫執行查詢語句;
Ⅴ、否則,到主庫執行查詢語句。

在上面的第Ⅰ步中,trx1 事務更新完成後,從返回包直接獲取這個事務的 GTID。我們只需要將參數 session_track_gtids 設置為 OWN_GTID,然後通過 API 接口 mysql_session_track_get_first 從返回包解析出 GTID 的值即可。
問題:假設你的系統採用了我們文中介紹的最後一個方案,也就是等 GTID 的方案,現在你要對主庫的一張大表做 DDL,可能會出現什麼情況呢?為了避免這種情況,你會怎麼做呢?
答:假設,這條語句在主庫上要執行 10 分鐘,提交後傳到備庫就要 10 分鐘(典型的大事務)。那麼,在主庫 DDL 之後再提交的事務的 GTID,去備庫查的時候,就會等 10 分鐘才出現。這樣,這個讀寫分離機制在這 10 分鐘之內都會超時,然後走主庫。
這種預期內的操作,應該在業務低峰期的時候,確保主庫能夠支持所有業務查詢,然後把讀請求都切到主庫,再在主庫上做 DDL。等備庫延遲追上以後,再把讀請求切回備庫。
這個思考題主要是想關注大事務對等位點方案的影響。當然了,使用 gh-ost 方案來解決這個問題也是不錯的選擇。
優點:相比於使用位點的方案,減少了一次在主庫上的查詢操作。
缺點:使用前提是開啟了 GTID,使用場景沒有使用位點廣泛。


