knn算法,識別簡單驗證碼圖片
- 2019 年 11 月 27 日
- 筆記
引言:為什麼學習這個呢?
這個算是機器學習,最入門的一點東東
這裡介紹兩種方法:
1.直接調用第三方庫進行識別,缺點:存在部分圖片無法識別
2.使用knn算法進行對圖片的處理,以及運算進行識別
聲明:本文均在pycharm上進行編輯操作,並本文所寫代碼均是python3進行編寫,如果不能正常運行本文內的代碼,請自己調試環境
另本文所識別的驗證碼類型為如下圖片:

先介紹第一種比較簡單的操作:
1.環境準備:
安裝如下第三方庫
from selenium import webdriver from PIL import Image import pytesseract
2.環境介紹
selenium 環境模仿鼠標點動,以及賬號密碼傳遞,等等
pytesseract 識別圖片中字符借用的第三方庫
PIL 對圖片的一些處理的第三方庫
3.具體實現
driver.find_element_by_xpath('地址').click()
點擊網頁中xpath為括號內的位置
driver.find_element_by_xpath('地址').send_keys(傳遞信息)
傳遞相應數據到xpath為括號內的相應位置
ele=driver.find_element_by_xpath('地址') ele.screenshot('圖片名,以及格式')
找到xpath為括號內的地址,並截取相應位置圖片
4.圖片處理
在獲取相應驗證碼圖片後,往往圖片為彩圖,或者存在噪點,為了減少模型的複雜度,以及減少模型的訓練強度,同時增加識別率,很有必要對圖片進行預處理,使其對機器識別更友好。
具體步驟如下:
1.讀取原始素材
2.將彩圖轉化為黑白圖
3.去噪點
4.1二值化圖片
圖像二值化( Image Binarization)就是將圖像上的像素點的灰度值設置為0或255,也就是將整個圖像呈現出明顯的黑白效果的過程。——來自百度百科
1.RGB彩圖轉為灰度圖
2.將灰度圖轉化為二值圖,即設定二值化閾值,轉化為01圖
image = Image.open('a.png') image = image.convert('L') #轉化為灰度圖 threshold = 127 #設定的二值化閾值 table = [] #table是設定的一個表,下面的for循環可以理解為一個規則,小於閾值的,就設定為0,大於閾值的,就設定為1 for i in range(256): if i < threshold: table.append(0) else: table.append(1) image = image.point(table,'1') #對灰度圖進行二值化處理,按照table的規則(也就是上面的for循環)
如下圖:
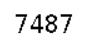
2.去除噪點
在轉化為二值圖片後,就需要清除噪點。本文選擇的素材比較簡單,大部分噪點也是最簡單的那種 孤立點,所以可以通過檢測這些孤立點就能移除大量的噪點。
關於如何去除更複雜的噪點甚至干擾線和色塊,有比較成熟的算法: 洪水填充法 Flood Fill ,後面有興趣的時間可以繼續研究一下。
轉載自 https://www.cnblogs.com/beer/p/5672678.htm
5.直接藉助selenium和pytesseract實現
result = pytesseract.image_to_string(image) # 讀取裏面的內容
輸出result,就是圖片的結果.
上述方法的精確度,嗯……..
我沒經過專業的測試,但是點着試試,試了二三十次,有那麼五六次是錯誤的
所以呢為了提高模型的精確度,下面介紹knn算法
knn:從訓練樣本集中選擇k個與測試樣本「距離」最近的樣本,這k個樣本中出現頻率最高的類別即作為測試樣本的類別。
- KNN是屬於有監督學習(因為訓練集中每個數據都存在人工設置的標籤——即類別)
- 那是如何進行分類的呢?其實是用數據之間的歐氏距離來衡量它們的相似程度,距離越短,表示兩個數據越相似。
5.建立樣本集—圖片分割
既然是樣本集,那麼肯定要有樣本呀,找相應網站,提交請求,爬取完事,在這不寫這個了
而樣本集的建立,可以數格子,沒錯就是數格子
打開ps,圖片放大到最大,然後數格子,額,這個方法有點low,在線ps:https://www.uupoop.com/
找到左上點,右下點,間距,然後循環切割,保存
from PIL import Image def cut_image(image): box_list = [] # (left, upper, right, lower) for i in range(0, 4): box = (5+i*12+1,5,14+i*12,19+1) box_list.append(box) image_list = [image.crop(box) for box in box_list] return image_list # 保存 def save_images(image_list): index = 1 for image in image_list: image.save(str(index) + '.png', 'PNG') index += 1 if __name__ == '__main__': file_path = "地址" # 圖片保存的地址 image = Image.open(file_path) image_list = cut_image(image) save_images(image_list)
效果圖:

上面方法有點low
所以可以,通過圖片黑色或白色的圖片的連續性,來進行尋找左上點和右下點來確定一個矩形範圍,即切割的圖片的位置,循環切割保存
def cut_image(image): """ 字符切割,根據黑色的連續性,當某一列出現黑色為標誌,當黑色消失為結束點 :param image: 完整的驗證碼圖片 :return images: 切割好的圖片列表 """ # inletter代表當前列是否出現黑點 inletter = False # foundletter為False時,未找到字符開始位置;否則,已找到字符開始位置 foundletter = False # 記錄所有字符的開始點和結束點 letters = [] start = 0 end = 0 for x in range(image.size[0]): for y in range(image.size[1]): # 當前像素點的狀態(0黑色或1白色) pix = image.getpixel((x,y)) # 出現黑色點時證明有字符出現 if pix == 0: inletter = True # 當前列出現黑色點,且未找到字符開始位置,則找當前列為字符開始位置 if foundletter == False and inletter ==True: foundletter = True start = x # 當前列為全白,且已有字符開始位置,則該字符結束,記錄字符的範圍 if foundletter == True and inletter == False: end = x letters.append((start,end)) foundletter = False inletter = False images = [] # 利用letter的信息切割驗證碼,得到單個字符 for letter in letters: img = image.crop((letter[0],0,letter[1],image.size[1])) #img.save(str(letter[0])+'.jpeg')#展示切割效果 images.append(img) return images
上面代碼只寫出連續黑的情況,所以在部分要進行修改
6.建立樣本集—分組
將爬取的樣本重複上述操作進行圖片處理和切割
將切割好的圖片,建立文件夾進行分組
7.識別
具體操作步驟如下: 1.預處理圖片
2.將圖片轉化
3.cos求解相似度
1.預處理圖片
上面的樣本切割出是單獨的數字,那麼在識別的時候,要對圖片進行處理以及切割,具體操作參考上面的介紹.
2.將圖片轉換
在將圖片切割後,是一個圖片的形式顯示,這樣不便於計算,所以將其轉化為矢量,將二維形式轉化為一維形式
def buildvector(image): """ 圖片轉換成矢量,將二維的圖片轉為一維 :param image: :return: """ result = {} count = 0 for i in image.getdata(): result[count] = i count += 1 return result
3.cos值求解相似度
求解方程:

即目標值與其中一個樣本值的相似度.
m表示該樣本組的數量,數組c表示目標圖片,數組d表示樣本組中的每一張圖片
另外在此所用的目標圖片和樣本圖片,均已經一維化處理
計算完目標圖片與所有樣本集後進行排序,去相似度最高即為目標圖片所示數字
class CaptchaRecognize: def __init__(self): self.letters = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9'] self.loadSet() def loadSet(self): """ 將icon中預先準備好的圖片,以向量的形式讀出 ps: icon中圖片為驗證碼切割完成後,人工標記的訓練集 如果需要增加,只需把切割後的圖片放到其所表示的文件夾下即可 :return: """ self.imgset = [] for letter in self.letters: temp = [] # 打開icon下的各個文件,icon文件下是一些已切割的字符圖片 for img in os.listdir('./icon/%s'%(letter)): # 將圖片轉成一維向量,放入temp列表中 temp.append(buildvector(Image.open('./icon/%s/%s'%(letter,img)))) # 標籤與對應圖片轉換成的向量,以字典形式存到imgset 如:letter為1,temp就是1文件夾下圖片的向量 self.imgset.append({letter:temp}) def magnitude(self,concordance): """ 利用公式求計算矢量大小,詳細公式見README.md :param concordance: :return: """ total = 0 for word, count in concordance.items(): # count 為向量各個單位的值 total += count ** 2 return math.sqrt(total) def relation(self, concordance1, concordance2): """ 計算矢量之間的 cos 值,詳細公式見README.md :param concordance1: :param concordance2: :return: """ relevance = 0 topvalue = 0 # 遍歷concordance1向量,word 當前位置的索引,count為值 for word, count in concordance1.items(): # 當concordance2有word才繼續,防止索引超限 if word in concordance2: #print(type(topvalue), topvalue, count, concordance2[word]) topvalue += count * concordance2[word] #time.sleep(10) return topvalue / (self.magnitude(concordance1) * self.magnitude(concordance2)) def recognise(self,image): """ 識別驗證碼 :param image: 驗證碼圖片 :return result: 返回驗證碼的值 """ # 二值化,將圖片按灰度轉為01矩陣 image = convert_image(image) # 對完整的驗證碼進行切割,得到字符圖片 images = cut_image(image) vectors = [] for img in images: vectors.append(buildvector(img)) # 將字符圖片轉一維向量,如[0,1,0,1,1,....] result = [] for vector in vectors: guess=[] # 讓字符圖片和訓練集中的 0-9 逐一比對 for image in self.imgset: for letter,temp in image.items(): relevance=0 num=0 # 遍歷一個標籤下的所有圖片 for img in temp: # 計算相似度 relevance+=self.relation(vector,img) print (vector,img) num+=1 # 求出相似度平均值 relevance=relevance/num guess.append((relevance,letter)) # 對cos值進行排序,cos值代表相識度 guess.sort(reverse=True) result.append(guess[0]) #取最相似的letter,作為該字符圖片的值 return result
8.主函數調用
if __name__ == '__main__': imageRecognize=CaptchaRecognize() # 設置圖片路徑 image = Image.open('3.png') # print(image.mode) result = imageRecognize.recognise(image) string = [''.join(item[1]) for item in result] print(result)
9.總結
本文主要是識別簡單的驗證碼圖片,要根據具體情況進行修改,主要提供一個框架,如果所給圖片呈不規則顯示,可能無法識別,這個算是機器學習簡單的入門,對於以上僅為個人看法,如果有別的看法,歡迎私聊!!!
原創文章,轉載請註明: 轉載自URl-team
本文鏈接地址: knn算法,識別簡單驗證碼圖片
No related posts.
