TR2021_0000偶發數據庫連接異常問題排查
【問題描述】
數據庫連接異常是很難排查的一類問題。因為它牽涉到應用端,網絡層和服務器端。任何一個組件異常,都會導致數據庫連接失敗。開發遇到數據庫連接不上的問題,都會第一時間找DBA來協助查看,DBA除了需要懂得數據庫以外,還需要對應用,對網絡有所了解,知道在哪裡看應用程序的日誌,以及看網絡交換機性能指標,才能清晰的定位問題。下面是一個數據庫偶發連接不上的例子:
| 步驟 | 分析 |
|---|---|
| S(主觀) | 某應用程序,有40台左右應用服務器,時不時的會報數據庫連接異常。報錯後迅速自愈。報錯內容為: Communications link failure. The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server. 報錯頻率大概每天有四五次左右。應用是新上的。 |
| O(客觀) | MySQL版本為5.7.23, 服務端操作系統版本為7.6.1810. 瞬間有20多台應用服務器都報這個錯誤。馬上自愈。應用部署在同城兩個機房,每個機房都有報錯。每天總會出現四五次。 |
| A(評估) | 同時有20多台應用服務器報錯,而且分佈在兩個機房。問題應該出在服務端。 |
| P(計劃) | 建議在服務端抓網絡包,進一步定位問題。並進一步查看服務端的性能計數器。 |
【問題分析】
通過問題的初步評估,故障應該是出現在服務端,也有可能是服務端的網絡。我們隨之查看了服務端MySQL的各項性能指標,在故障期間,性能指標都是正常的。在服務器端單邊抓包,抓到的內容如下:
| 時間戳 | 源 | 目標 | Info |
|---|---|---|---|
| 2021-01-08 17:15:05.667331 | 應用 | DB | 48184 -> 3309 [SYN] |
| 2021-01-08 17:15:06.717752 | 應用 | DB | [TCP Retransmission] 48144 -> 3309 [SYN] |
| 2021-01-08 17:15:06.717762 | DB | 應用 | 3309 -> 48184 [SYN, ACK] |
| 2021-01-08 17:15:06.719101 | 應用 | DB | 48144 -> 3309 [RST] |
上述網絡包解讀如下:
- 17:15:05.66 應用服務器(端口號48184)向DB服務器(端口號3309) 發送一個SYN請求。
- 過了1.05秒左右,應用服務器再次向DB服務器發送SYN請求
- 在17:15:06.71的時候,DB服務器響應了客戶端的請求,發送了確認包ACK
- 在17:15:06.71的時候,應用服務器發送了連接重置的請求,要求中止連接。
從上述的特徵來看,連接重置是客戶端發起的。但這個情有可原,因為DB端超過1.05秒還沒有響應客戶端的SYN請求,客戶端不耐煩,直接中止了連接。而這個1.05秒,恰好是開發在客戶端的Tomcat JDBC connect Timeout連接超時設定。所以問題進一步縮小到服務端的TCP/IP連接層面。
我們用下面的命令,來監控服務端丟包情況:
# netstat -s | egrep "listen|LISTEN"
5268 times the listen queue of a socket overflowed
5268 SYNs to LISTEN sockets dropped
發現確實在服務端丟包,而且出現的頻率和客戶端報錯的時間吻合。每次應用程序報錯,服務端的drop數也會隨之增加。
對於Linux服務器端,server端建連過程需要兩個隊列,一個是SYN queue,一個是accept queue。前者叫半開連接(或者半連接)隊列,後者叫全連接隊列。從服務器角度看,建立TCP連接的過程如下圖:
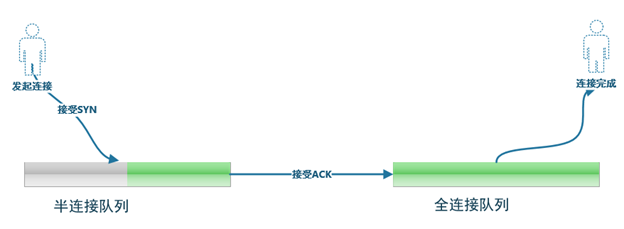
SYNs to LISTEN sockets dropped的丟包類型,說明在半連接隊列出現了問題。
分析發現,該實例部署的DB數量比較多,且對應的應用服務器數量也比較多,應用會有短時間創建大量連接的情況,導致半連接隊列溢出。半連接隊列的大小取決於linux的參數tcp_max_syn_backlog、somaxconn和應用程序調用Listen方法時的backlog參數。
關於tcp_max_syn_backlog、somaxconn與半連接隊列的分析,網上的資料非常多,這裡不展開細節分析,我們可以簡單地認為:
全連接隊列長度 = min(somaxconn, backlog)
半連接隊列長度 = min(應用調用Listen的backlog,somaxconn,tcp_max_syn_backlog)
我們可以用下面的命令,來監控全連接的隊列大小,發現值為128,可以說明我們somaxconn值或者mysqld的backlog設置比較小,從而導致半連接隊列也比較小。
#ss -ntlp | more
LISTEN 0 128 :::3309 :::*
對於這次的案例,我們先調大了linux操作系統的兩個參數。
#echo 'net.ipv4.tcp_max_syn_backlog=65535' >> /etc/sysctl.conf
#echo 'net.core.somaxconn=65535' >> /etc/sysctl.conf
#sysctl –p
接下來,我們分析下mysqld調用Listen方法時,backlog相關的代碼。
MYSQLD在啟動時會調用network_init的方法,會傳入back_log參數,代碼如下:
static bool network_init(void)
{
if (opt_bootstrap)
return false;
set_ports();
if (!opt_disable_networking || unix_sock_name != "")
{
std::string const bind_addr_str(my_bind_addr_str ? my_bind_addr_str : "");
Mysqld_socket_listener *mysqld_socket_listener=
new (std::nothrow) Mysqld_socket_listener(bind_addr_str,
mysqld_port, back_log,
mysqld_port_timeout,
unix_sock_name);
if (mysqld_socket_listener == NULL)
return true;
mysqld_socket_acceptor=
new (std::nothrow) Connection_acceptor(mysqld_socket_listener);
}
創建出mysqld_socket_listener對象後,傳遞給Connection_acceptor後,最終會調用操作系統的Listen方法,代碼如下:
static inline int inline_mysql_socket_listen
(
MYSQL_SOCKET mysql_socket, int backlog)
{
int result;
if (mysql_socket.m_psi != NULL)
{
/* Instrumentation start */
PSI_socket_locker *locker;
PSI_socket_locker_state state;
locker= PSI_SOCKET_CALL(start_socket_wait)
(&state, mysql_socket.m_psi, PSI_SOCKET_CONNECT, (size_t)0, src_file, src_line);
/* Instrumented code */
result= listen(mysql_socket.fd, backlog);
對於back_log值的確定,mysql有2種處理方式。
一種是情況默認情況,會設置50 + (max_connections / 5)且不超過900。具體的代碼如下:
int init_common_variables()
{
umask(((~my_umask) & 0666));
my_decimal_set_zero(&decimal_zero); // set decimal_zero constant;
tzset(); // Set tzname
/* Fix back_log */
if (back_log == 0 && (back_log= 50 + max_connections / 5) > 900)
back_log= 900;
}
另外一種情況,也可以手動設置mysqld的啟動參數。
static Sys_var_ulong Sys_back_log(
"back_log", "The number of outstanding connection requests "
"MySQL can have. This comes into play when the main MySQL thread "
"gets very many connection requests in a very short time",
READ_ONLY GLOBAL_VAR(back_log), CMD_LINE(REQUIRED_ARG),
VALID_RANGE(0, 65535), DEFAULT(0), BLOCK_SIZE(1));
為了保持服務器配置的統一化,我們這次調整了mysqld的啟動back-log=2048,調整完成後,重啟mysql服務,觀察了2天,再未發生半連接丟包的問題。
【問題總結】
全連接隊列、半連接隊列溢出這種問題很容易發生,但可能報錯具有偶然性,很容易被忽視,linux版本的不斷進化,TCP的設計也越來越複雜,作為一名合格的DBA,也需要對網絡有所了解,才能更好地定位和處理日常的運維問題。


