大數據實戰-電信客服-重點記錄
寫在前面的話
最近不是一直在學習大數據框架和引用嘛(我是按照尚硅谷B站視頻先學習過一遍路線,以後找准方向研究),除了自己手動利用Kafka和HDFS寫一個簡單的分佈式文件傳輸(分佈式課程開放性實驗,剛好用上了所學的來練練手)以外,還學習這個學習路線一個項目,電信客服實戰。在這個項目裏面還是學習到了不少內容,包括Java上不足的很多地方、Java工程開發上的要求和少數框架的複習。不排除自己太菜,啥都不知道,認為一些常見的東西不常見的情況(哭
鑒於網上有很多類似的內容,這裡我只是將我學習和復code的過程中,學習到的知識和遇到問題的解決方案寫下,以作記錄和回顧。
1.我的手敲代碼,2.老師源碼,含數據和筆記(提取碼:pfbv)
聲明一下,沒有任何廣告意思,這種渠道是很容易找到並且也很多的,我只是恰好學習了這個,並且我覺得還不錯(求生欲極強
電信客服
介紹
項目主要是模擬電信中的信息部門,從生產環境中獲取通話信息數據,根據業務需求存儲和分析數據。
業務需求
統計每天、每月以及每年的每個人的通話次數及時長。
項目架構
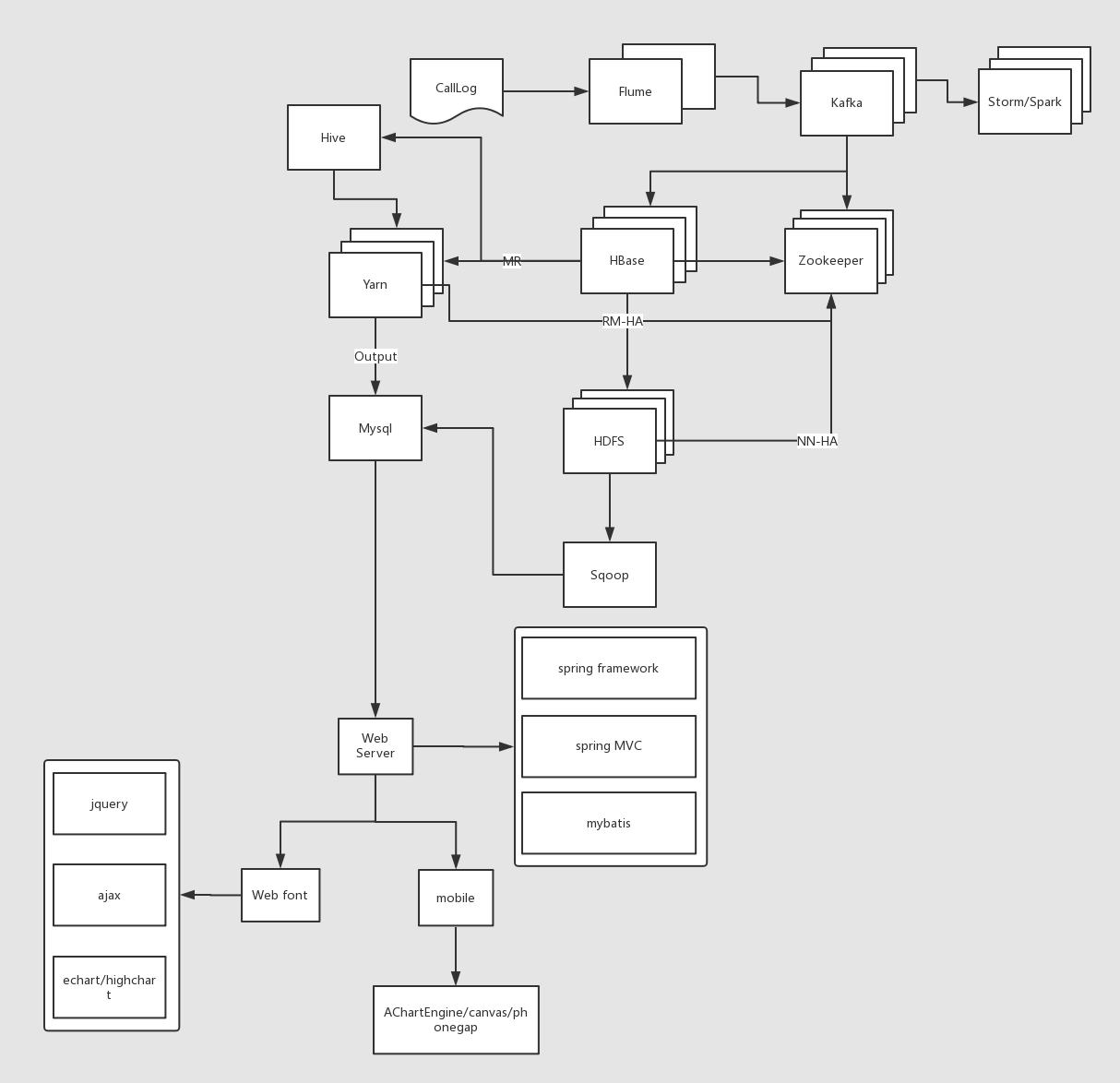
代碼流程
編寫代碼的流程分為四步:①數據生產,②數據消費,③數據分析,④數據展示。我在學習過程中,沒有學習數據展示部分。
數據生產
主要任務是利用contact.log(聯繫人文件)的數據,生成不同聯繫人之間通話記錄的流程。
這個Part,老師有句話我覺得很在理,「大數據開發人員雖然不管數據怎麼來的,怎麼出去的,但是必須知道和了解這個過程才能按照需求code」。腦海中閃過中間件
面向接口編程 – 項目第一步
在以前的編程學習過程中,總是一股腦兒的猛寫代碼,雖然我自認為我在我們宿舍已經是模塊化思想最為嚴重的了,但是從未接觸到面向接口編程。這學期也學習了軟件工程,(雖然我們學得很水),這門課雖然不是在教我們寫代碼,但卻是教我們如何正確的做項目和寫代碼(暈。
面向接口編程也是如此,在這個項目中,了解了我們的數據來源和需求後,第一步要做的是弄清楚需要的對象和需要的功能,即接口,在共同的模塊中確定好接口和接口的方法簽名,接下來才是對接口模塊的實現和實現業務。
在這個項目中,建立了一個ct-common模塊作為公共模塊,簡單介紹幾個:
| 接口或抽象類 | 描述 |
|---|---|
| Val | 一般數據都需要的實現的接口,只包括名稱意義上的獲取值value()方法 |
| DataIn | 數據輸入接口,功能有設置輸入路徑,讀取數據,故存在setPath()和read()方法 |
| Producer | 數據生產者接口,功能有獲取輸入信息,設置生產輸出和生產,故存在setIn()和和setOut()和produce()方法 |
下圖是ct-common的代碼結構:

封裝對象 – 提高擴展性
這個思想其實我在之前的編碼過程中就有點領悟了,之所以在這裡提出,是因為在這個跟進過程中,更加體會到Java編碼就是各種對象組合調用的含義。或許是老師項目拉得太快,讓我感覺自己太菜,skrskr
我之前編碼過程中,也會不停的封裝對象,但一般都是那些很明顯的功能集成對象,更別說是對數據進行封裝成數據集成對象了。換句話說,就是我之前封裝的對象都是含有一定動作的(除了getter&setter)。但是對於一些對象之間傳遞的數據,如果每次都傳相同的數據並且數量>1的話,最好的是封裝成對象,提高擴展性。在業務需要增添一個數據傳遞的情況下,封裝數據對象只需要更改對象的屬性和對象的構成,否則每個傳遞的地方(語句)都需要增添傳遞的數據變量。
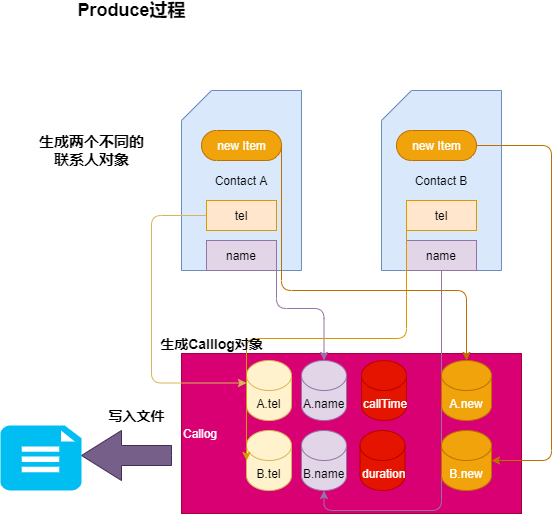
下面用一張圖表示,在該項目中封裝Calllog和Contact對象的效果:
如果不封裝對象,如果聯繫人對象裏面在加入一個new item(比如性別),那麼幾乎所有的地方都需要修改;反之,只需要在Contact類中增添new item屬性和在Calllog中增添A.new&B.new屬性,以及修改構造方法就可以了,同時在Producer過程中,沒有增添和修改過多代碼。
數據生產總結
在這個Part中主要還是熟悉任務就可以完成,沒遇到什麼問題。如果不用上述的tricks那這不就是一個讀入文件和寫入文件的代碼嘛(我一main方法就能搞定),但是用了之後感覺就明顯不同,更加工程化,邏輯感更強。
數據消費
主要操作是利用Flume和Kafka將收集不斷生產的數據,並且將數據插入到HBase中。
新概念
主要是學到了一些新的知識,還有知識的簡單運用,我並沒有深究這些新概念(估計得學到頭禿)。
-
類加載器:類加載器是負責將可能是網絡上、也可能是磁盤上的class文件加載到內存中。並為其生成對應的java.lang.class對象。
有三種類加載器,分別按照順序是啟動類加載器BootstrapClassLoader、擴展類加載器Extension ClassLoader和系統類加載器App ClassLoader。還存在一種雙親委派模型,簡單的意思就是說當一個類加載器收到加載請求時,首先會向上層(父)類加載器發出加載請求。並且每一個類加載器都是如此,所以每個類加載器的請求都會被傳遞到最頂層的類加載器中,一開始我覺得很麻煩,不過這確實可以避免類的重複加載。
在電信客服的項目中,類加載器被用於加載resource文件夾的配置文件。Properties prop = new Properties(); // 利用類加載器獲取配置文件 prop.load(Thread.currentThread().getContextClassLoader().getResourceAsStream("consumer.properties")); -
ThreadLocal:這是一個線程內維護的存儲變量數組。舉個簡單的比方,在Java運行的時候有多個線程,存在一個Map<K,V>,K就是每個線程的Id,V則是每個線程內存儲的數據變量。
這是多線程相同的變量的訪問衝突問題解決方法之一,是通過給每個線程單獨一份存儲空間(犧牲空間)來解決訪問衝突;而熟悉的Synchronized通過等待(犧牲時間)來解決訪問衝突。同時ThreadLocal還具有線程隔離的作用,即A線程不能訪問B線程的V。
在電信客服的項目中,ThreadLocal被用來持久化Connection和Admin連接。因為在HBase的DDL和DML操作中,不同的操作都需要用到連接,所以將其和該線程進行綁定,加快獲取的連接的速度和減少內存佔用。當然也可以直接new 幾個對象,最後統一關閉。// 通過ThreadLocal保證同一個線程中可以不重複創建連接和Admin。 private ThreadLocal<Connection> connHolder = new ThreadLocal<Connection>(); private ThreadLocal<Admin> adminHolder = new ThreadLocal<Admin>(); private Connection getConnection() throws IOException { Connection conn = connHolder.get(); if (conn == null) { Configuration conf = HBaseConfiguration.create(); conn = ConnectionFactory.createConnection(conf); connHolder.set(conn); } return conn; } private Admin getAdmin() throws IOException { Admin admin = adminHolder.get(); if (admin == null) { getConnection(); admin = connHolder.get().getAdmin(); adminHolder.set(admin); } return admin; }分區鍵和RowKey的設計
分區鍵的設計一般是機器數量。rowKey的設計基於表的分區數,並且滿足長度原則(10~100KB即可,最好是8的倍數)、唯一性原則和散列性原則(負載均衡,防止出現數據熱點)
分區鍵
本項目中共6個分區,故分區號為”0|”、”1|”、”2|”、”3|”、”4|”。舉一個例子,3****的第二位無論是任何數字都會小於”|”(第二大的字符),所以”2|”<“3****”<“3|”,故分到第四個分區。
RowKey
設計好了分區鍵後,rowKey的設計主要是根據業務需求哪些數據需要聚集在一起方便查詢,那就利用那些數據設計數據的分區號。
數據含有主叫用戶(13312341234)、被叫用戶(14443214321)、通話日期(20181010)和通話時長(0123)。業務要求我們將經常需要統計一個用戶在某一月內的通話記錄,即主叫用戶和通話日期中的年月是關鍵數據。根據這些數據計算分區號,保證同一用戶在同一月的通話記錄在HBase上是緊鄰的(還有一個前提要求是rowkey還必須是分,分區號+主叫用戶+通話日期+others,否則在一個分區上還是有可能是亂的)。下面是計算分區號的代碼:/** * 計算得到一條數據的分區編號 * * @param tel 數據的主叫電話 * @param date 數據的通話日期 * @return regionNum 分區編號 */ protected int genRegionNum(String tel, String date) { // 獲取電話號碼的隨機部分 String userCode = tel.substring(tel.length() - 4); // 獲取年月 String yearMonth = date.substring(0, 6); // 哈希 int userCodeHash = userCode.hashCode(); int yearMonthHash = yearMonth.hashCode(); // crc 循環冗餘校驗 int crc = Math.abs(userCodeHash ^ yearMonthHash); // 取余,保證分區號在分區鍵範圍內 int regionNum = crc & ValueConstants.REGION_NUMS; return regionNum; }查詢方法
例子:查詢13312341234用戶在201810的通話記錄
startKey <- genRegionNum(“13312341234″,”201810″)+”_”+”13312341234″+”_”+”201810”
endKey <- genRegionNum(“13312341234″,”201810″)+”_”+”13312341234″+”_”+”201810″+”|”
協處理器
引入的原因
電信客服中通常需要計算兩個客戶之間親密度,計算的數據來源於兩者的通話記錄。舉個例子,計算A和B的親密度,那麼需要A和B之間的通話記錄,特別注意的是不僅需要A call B的記錄,還需要B call A的記錄。
- 第一,最無腦的方法是啥也不做
(憨憨,在查詢的時候通過scan中的filter對rowkey進行過濾查詢,這樣子每次都需要查詢全表,速度過慢。 - 第二,最直觀的方法是接收到Kafka的一條數據後,插入兩條數據,主叫用戶和被叫用戶換個位置第二次插入HBase,同時加上一個標誌位Flag,標識第一個電話號碼(HBase中的列稱為call1)是否是主叫用戶。
- 第三,顯然一條數據是重複了兩次,那麼在查詢的時候(無關親密度)出現兩次,即影響查詢速度。所以優化的方法是將重複的數據單獨新建一個列族,在查詢的時候只需要在一個列族中查詢。即減少了數據量,畢竟HBase針對錶的存儲是一個個store進行存儲的。
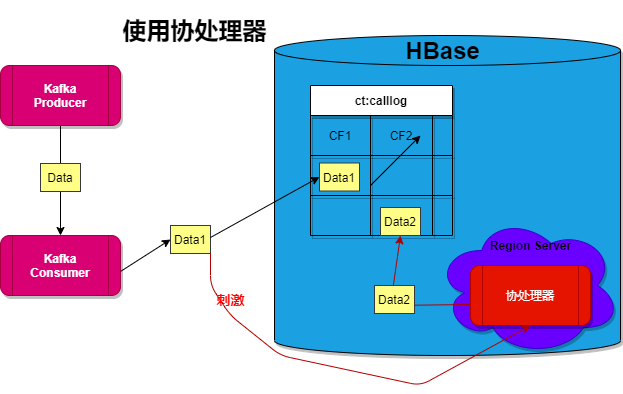
- 第四,這樣子擴展性太低,要是需要重複幾十次,那編碼效率和插入效率也太低了,故在HBase中引入了協處理器。相當於MySQL中的觸發器,協處理器部署在RegionServer上。
協處理器的設計
就好比MySQL中的觸發器一樣,MySQL的觸發器有針對update、insert和delete的,還有before和after等等,協處理器也有類似的對應函數。比如,在本項目中,需要的是再插入一條數據後,協處理器被觸發插入另外一條「重複數據」,所以複寫的方法是postPut。
設計具體邏輯是:根據插入的Put獲得插入的數據信息,然後判斷插入的標誌位Flag是不是1,如果是1,則插入另外一條重複數據。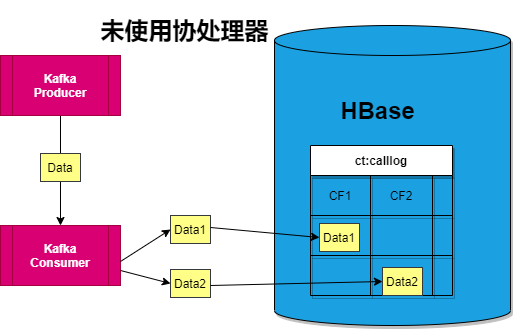
下面是代碼:
public class InsertCalleeCoprocessor extends BaseRegionObserver { /** * 這是HBase上的協處理器方法,在一次Put之後接下來的動作 * * @param e * @param put * @param edit * @param durability * @throws IOException */ @Override public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException { // 1. 獲取表對象 Table table = e.getEnvironment().getTable(TableName.valueOf(Names.TABLE.getValue())); // 2. 構造Put // 在rowKey中存在很多數據信息,這一點就不具備普適性 String values = Bytes.toString(put.getRow()); String[] split = values.split("_"); String call1 = split[1]; String call2 = split[2]; String callTime = split[3]; String duration = split[4]; String flag = split[5]; // 在協處理器中也發生了Put操作,但是此時的Put不引發協處理器再次響應 // 必須得關閉表連接 if ("0".equals(flag)) { table.close(); return; } CoprocessorDao dao = new CoprocessorDao(); String rowKey = dao.genRegionNums(call2, callTime) + "_" + call2 + "_" + call1 + "_" + callTime + "_" + duration + "_" + "0"; Put calleePut = new Put(Bytes.toBytes(rowKey)); calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("call1"), Bytes.toBytes(call2)); calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("call2"), Bytes.toBytes(call1)); calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("callTime"), Bytes.toBytes(callTime)); calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("duration"), Bytes.toBytes(duration)); calleePut.addColumn(Bytes.toBytes(Names.CF_CALLEE.getValue()), Bytes.toBytes("flag"), Bytes.toBytes("0")); // 3. 插入Put table.put(calleePut); // 4. 關閉資源,否則內存會溢出 table.close(); } private class CoprocessorDao extends BaseDao { public int genRegionNums(String tel, String date) { return super.genRegionNum(tel, date); } } } - 第一,最無腦的方法是啥也不做


需要注意的問題:
- 編完協處理器代碼後需要修改創建表的數據,在添加的表描述器上添加編寫的協處理器類全路徑,並且將打包發給集群,記住分發。
- 判斷標誌位是否為1,為1才被觸發,因為協處理器觸發發送的「重複」數據也會被協處理器自身感應到。
- 在協處理器上面插入數據後,要關閉表的連接,否則內存會溢出。
遇到的問題和解決方案
- 在老師給的代碼,在執行過程中,發現slave1和slave2中RegionServer掛掉了,然後我手動啟動並且查看HBase中的數據,觀察到數據存在並且無誤,然後在master:16010上觀察所有的分區都在master的RegionServer上,正常。
但是為什麼會我的掛掉呢,明明虛擬機的配置是一樣的,果斷查看日誌發現out of memory,內存溢出了,心念一轉怕不是代碼有問題。果不其然,在代碼中,先是打開的table連接,然後進行標誌位的判斷,如果為1發送數據後關閉連接,但是在標誌位為0的時候沒有關閉連接,所以內存才會溢出,修改完事兒! - 這裡就是笨逼(沒錯,就是我)犯下的錯誤,我在修改完後打包上傳……怎麼出錯了,我幾乎整了半天才發現我居然沒分發!!!分發後就可以看到較好的效果。這就完了?我講講最後我是怎麼發現沒分發,沒分發的過程中slave1和slave2的RegionServer總是掛掉,並且還是內存出錯(所以我才懵,當時我覺得是我的機子不行,
換機子,所以直接kill slave1和slave2的RegionServer在開始執行,得到了和之前相同的結果,但是內存的問題我應該是解決了的,所以那隻可能是代碼的問題了。下載下來一看,不一樣,我懂了,Nicer,這就賞自己兩嘴巴子!(哭
當然,這也是一次記憶深刻的debug!!!
總結
這個流程是我學習最多的流程,除了複習這個大數據框架的API,更多的是對我的Java有了更多的拓展。除了上述提到的,還有一些註解,泛型和泛型的PECS原則等等。另外就是學習怎麼一步步排除錯誤和尋找自己的(低級)錯誤的方法了,這種DeBug的方式對於我來說很新鮮。
數據分析
同時利用redis緩存數據,利用MapReduce將HBase中的數據提取到MySQL中。
DeBug分析
出現的問題:MapReduce任務執行成功,但是MySQL中未插入數據,同時查看MapReduce8088端口,看不到日誌,顯示no log for container available。
問題分析:
1.觀察MapReduce的任務,發現Reduce的確是正確輸出了位元組,但是MySQL沒有插入數據,那隻能可能是編寫的OutputFormat出現了問題。
2.no log for container available, 在網上查閱資料提示有可能是內存不足的問題。
3.查看MapReduce的Reduce任務,發現是在nodemanager是在slave1上運行,而slave1隻分配了2G內存。
4.kill slave1和slave2的nodemanager,只運行master的nodemanager,因為master我分配了4G內存。
5.查看日誌成功,尋找錯誤。
6.發現是MySQL語句出現了語法錯誤????????(離譜,就**離譜)
7.修改MySQL語句,任務成功執行。
總結
這是我的一個學習上手的大數據項目,雖然簡單但是也學習不少。做這個項目的時候是考試周,也算是忙裡偷閒完成了!主要是這個項目和我們小隊準備參加的服創大賽的項目很類似,也算是提前練練手,熟悉下基本的流程。不過我們小隊的項目最好還是得上Spark和好的機器(虛擬機老拉跨,所以繼續學習!!!