超有用的linux筆記
名詞解釋
根目錄說明
tree -L 1
.
├── bin -> usr/bin # 英語binary的縮寫,表示」二進制文件「,bin目錄包含了會被所有用戶使用的可執行程序
├── boot # 英語boot表示」啟動「,boot目錄包含與Linux啟動密切相關的文件
├── dev # 英語device的縮寫, 表示」設備「,包含外設,它裏面的子目錄,每一個對應一個外設
├── etc # etc目錄包含系統的配置文件,按照原始Unix的說法,這下面都是一堆零零碎碎的東西,就叫etc好了,是歷史遺留問題
├── home # 英語home表示」家「,用戶的私人目錄,在home目錄中,我們放置私人的文件
├── lib -> usr/lib # 英語library的縮寫,表示」庫「,目錄包含被程序所調用的庫文件,以.so結尾的文件
├── lib64 -> usr/lib64
├── media # 英語media表示」媒體「,可移動的外設(USB盤,SD卡,DVD,光盤等)插入電腦時可以讓我們通過media的子目錄來訪問這些外設的內容
├── mnt # mnt是英語mount的縮寫,表示」掛載「,有點類似media目錄,但一般用於臨時掛載一些裝置
├── opt # 英語 optional application software package的縮寫,表示」可選的軟件包「,用於安裝多數第三方軟件和插件
├── proc
├── root
├── run
├── sbin -> usr/sbin # 英語system binary的縮寫, 表示」系統二進制文件「 ,包含系統級的重要可執行程序
├── srv # 英語service的縮寫,表示」服務「,包含一些網絡服務啟動之後所需要取用的數據
├── sys
├── tmp # 英語temporary的縮寫,表示」臨時的「,普通用戶和程序存放臨時文件的地方
├── usr # 是英語Unix Software Resource的縮寫,表示」Unix操作系統軟件資源「,目錄里安裝了大部分用戶需要調用的程序
└── var # 英語variable的縮寫,表示」動態的,可變的「,var通常包含程序的數據,比如log(日誌)文件,記錄電腦了發生了什麼事
掛載
所謂的掛載就是利用一個目錄當成進入點,將磁盤分區的數據放置在該目錄下;也就是說進入該目錄就可以讀取該分區的意思。這個操作我們稱為掛載,那個進入點的目錄我們稱為掛載點。
shell
當談到命令時,我們實際上指的是shell。shell是一個接收由鍵盤輸入的命令,並將其傳遞給操作系統來執行的程序。幾乎所有的Linux發行版都提供shell程序,該程序來自於稱之為bash的GNU項目。bash是Bourne Again Shell的首字母縮寫,Bourne Again Shell基於這樣一個事實,即bash是sh的增強版本,而sh是最初的UNIX shell程序,由Steve Bourne編寫。
終端
當使用圖形用戶界面時,需要另一種叫做終端仿真器(terminal emulator)的程序與shell進行交互。如果我們仔細查看桌面菜單,那麼很可能會找到一個款終端仿真器。在KDE環境下使用的是konsole,而在GNOME環境下使用的是gonme-terminal,但在桌面菜單上很可能將它們簡單地統稱為終端。在Linux系統中,還有許多其他的終端仿真器可以使用,但是它們基本上都做同樣的事情:讓用戶訪問shell。
硬件相關
修改主機名
查看當前主機名
hostname
臨時修改主機名:
hostname new_name(新主機名)
上面的修改方式屬於臨時修改,系統重啟後失效,如果想要永久性修改主機名,那麼就需要修改配置文件
- 在CentOS6中,需要修改
/etc/sysconfig/network文件 - 在CentOS7中,需要修改
/etc/hostname文件
查看CentOS版本
cat /etc/redhat-release
查看CPU總核數
# 表示一顆CPU四核
grep processor /proc/cpuinfo |wc -l
grep -c processor /proc/cpuinfo
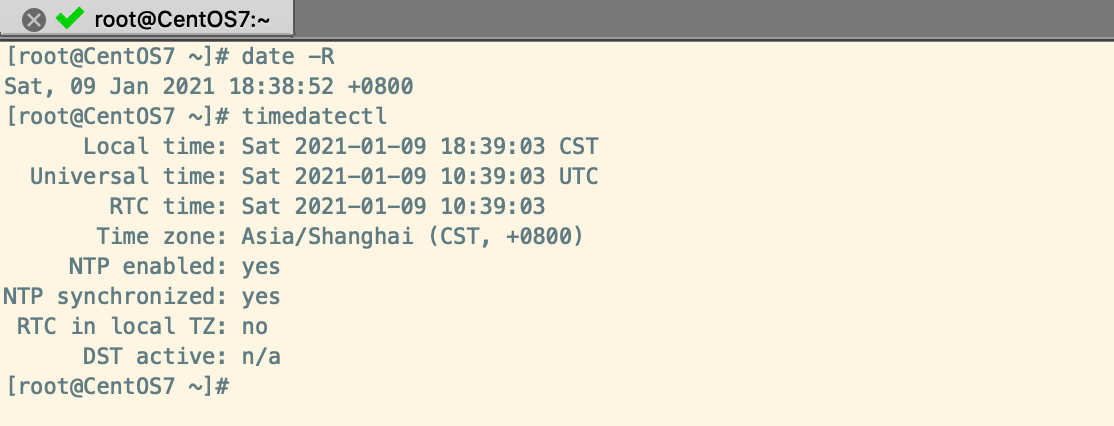
校正CentOS7時間
GPS系統中有兩種時間區分,UTC就0時區的時間,CST為本地時間,如北京為早上八點(東八區),UTC時間比北京時晚八小時;
CST:Central Standard Time,UTC+8:00 中央標準時間
UTC:Universal Time Coordinated 世界協調時間
# 安裝ntp軟件包
sudo yum -y install ntp
# 設置ntp開機自啟
systemctl enable ntpd.service
# 啟動ntp服務
sudo service ntpd.service restart
如果需要配置CTS時間,需要創建如下軟鏈接
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
如果需要配置UTC時間,需要創建如下軟鏈接
ln -sf /usr/share/zoneinfo/Universal /etc/localtime
修改文件最大打開數
linux修改文件最大打開數量的方法,默認情況下是1024的。
我們可以使用 ulimit -n命令查看

如果我們想臨時修改,可以使用 ulimit -n 數量來修改,不過系統重啟後修改會丟失

如果想永久修改,需要修改/etc/security/limits.conf文件

修改系統端口最大監聽隊列的長度
在linux中,/proc/sys/net/core/somaxconn這個參數,定義了系統中每一個端口最大的監聽隊列的長度,這是個全局的參數,默認值為128。
somaxconn限制了接收新 TCP 連接偵聽隊列的大小。對於一個經常處理新連接的高負載 web服務環境來說,默認的 128 太小了。大多數環境這個值建議增加到 1024 或者更多。 服務進程會自己限制偵聽隊列的大小(例如 sendmail(8) 或者 Apache),常常在它們的配置文件中有設置隊列大小的選項。大的偵聽隊列對防止拒絕服務 DoS 攻擊也會有所幫助。
vim /etc/sysctl.conf
# 添加
net.core.somaxconn = 1024
然後執行sysctl -p使配置生效。
修改內核內存分配策略
overcommit_memory是一個內核對內存分配的一種策略。 具體可見/proc/sys/vm/overcommit_memory下的值
overcommit_memory取值又三種分別為0,1,2
- overcommit_memory=0,表示內核將檢查是否有足夠的可用內存供應用進程使用;如果有足夠的可用內存,內存申請允許;否則,內存申請失敗,並把錯誤返回給應用進程。
- overcommit_memory=1,表示內核允許分配所有的物理內存,而不管當前的內存狀態如何。
- overcommit_memory=2, 表示內核允許分配超過所有物理內存和交換空間總和的內存。
當我們啟動redis服務時,會報警告,翻譯為【「警告超限」內存設置為0!在內存不足的情況下,後台保存可能會失敗。若要解決此問題,請將「vm.overcommit_memory=1」添加到/etc/sysctl.conf,然後重新啟動或運行命令「sysctl vm.overcommit_memory=1」以使其生效。】
vim /etc/sysctl.conf
# 添加
vm.overcommit_memory = 1
然後執行sysctl -p使配置生效。
vim編輯器
基本上vi共分為3種模式,分別是一般命令模式、編輯模式與命令行模式。
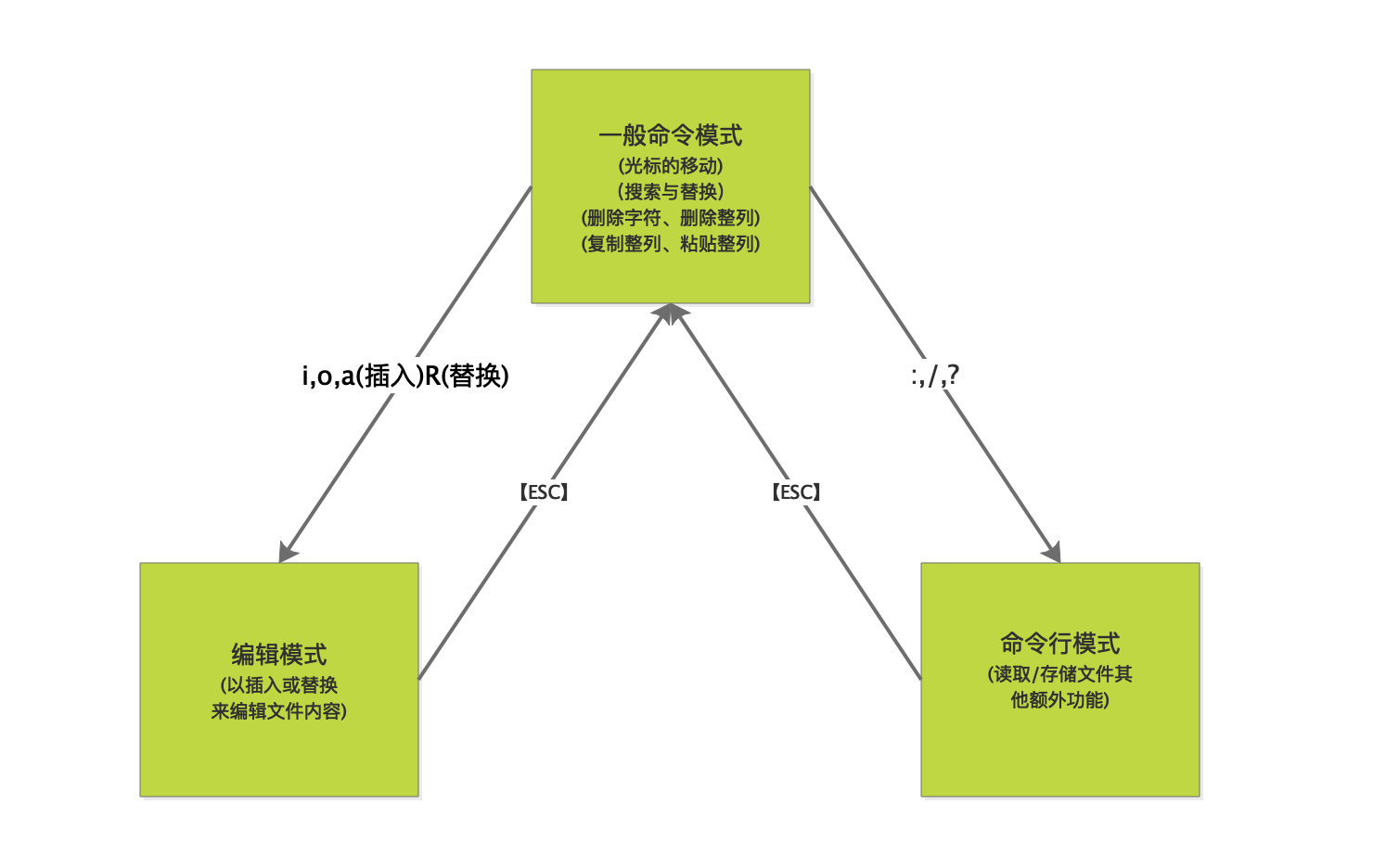
一般命令模式(command mode)
以vi打開一個文件就直接進入一般命令模式了(這是默認的模式,也成為一般模式)。在這個模式中,你可以使用【上下左右】按鍵來移動光標,你可以使用【刪除字符】或【刪除整行】來處理文件內容,也可以使用【複製、粘貼】來處理你的文件內容。
編輯模式(insert mode)
在一般命令模式中可以進行刪除、複製、粘貼等的操作,但是卻無法編輯文件的內容。要等到你按下【i、I、o、O、a、A、r、R】等任何一個字母之後才會進入編輯模式。注意了,通常在Linux中,按下這些按鍵時,在界面的左下方會出現【INSERT】或【REPLACE】的字樣,此時才可以進行編輯,而如果要回到一般命令模式時,則必須要按下【Esc】這個按鍵即可退出編輯模式。
命令行模式(command-line mode)
在一般模式當中,輸入【😕?】三個中的任何一個按鈕,就可以將光標移動到最下面的一行。在這個模式當中,可以提供你【查找數據】的操作,而讀取、保存、批量字符替換、退出vi、顯示行號等的操作則是在此模式中完成。
一般命令模式可與編輯模式及命令行模式切換,但編輯模式與命令行模式之間不可互相切換。
常用vim命令:
插入命令:
| 命令 | 說明 |
|---|---|
i |
當前位置插入 |
I |
行首插入 |
a |
當前位置後插入 |
A |
行尾插入 |
o |
下一新行插入 |
O |
上一新行插入 |
s |
刪除光標所在的字符,當前位置插入 |
S |
刪除光標所在行,當前行插入 |
移動光標:
| 命令 | 說明 |
|---|---|
h |
光標左移 |
j |
光標下移 |
k |
光標上移 |
l |
光標右移 |
^ |
光標移動到行首 |
$ |
光標移動到行尾 |
gg |
光標移動到文件首行 |
G |
光標移動到文件尾行 |
ngg |
n為數字,移動到這個文件的第n行 |
nG |
n為數字,移動到這個文件的第n行 |
查找與替換:
| 命令 | 說明 |
|---|---|
/word |
向光標之下尋找一個名稱為word的字符串。例如要在文件內查找itbsl這個字符串,就輸入/itbsl即可(常用) |
?word |
向光標之上尋找一個字符名稱為word的字符串 |
n |
這個n是英文按鍵,代表【重複前一個查找的操作】。舉例來說,如果剛剛我們執行/itbsl去向下查找itbsl這個字符串,則按下n後,會向下繼續查找下一個名稱為itbsl的字符串,如果是執行?itbsl的話,那麼按下n則會向上繼續查找名稱為itbsl的字符串 |
N |
這個N是英文按鍵,與n剛好相反,為【反向】進行前一個查找操作,例如/itbsl後,按下N則表示【向上】查找itbsl |
:n1,n2s/word1/word2/g |
n1與n2為數字,在第n1與n2行之間尋找word1這個字符串,並將該字符串替換為word2,舉例來說,在100到200行之間查找itbsl並替換為ITBSL,則 :100,200s/itbsl/ITBSL/g(常用) |
:1,$s/word1/word2/g |
從第一行到最後一行尋找word1字符串,並將該字符串替換為word2(常用) |
:1,$s/word1/word2/gc |
從第一行到最後一行尋找word1字符串,並將該字符串替換為word2,且在替換前顯示提示字符給用戶確認(confirm)是否需要替換(常用) |
刪除、複製與粘貼:
| 命令 | 說明 |
|---|---|
x與X |
在一行當中,x為向後刪除一個字符(相當於[del]按鍵),X為向前刪除一個字符(相當於[Backspace]即退格鍵)(常用) |
nx |
n為數字,連續向後刪除n個字符。舉例來說,我要連續刪除10個字符,【10x】 |
dd |
刪除(剪切)光標所在的那一整行(常用) |
ndd |
n為數字,刪除(剪切)光標所在的向下n行,例如20dd則是刪除(剪切)20行(常用) |
d1G |
刪除(剪切)光標所在到第一行的所有數據 |
dG |
刪除(剪切)光標所在到最後一行的所有數據 |
d$ |
刪除(剪切)光標所在處,到該行的最後一個字符 |
d0 |
刪除(剪切)光標所在處,到該行的最前面的一個字符 |
yy |
複製光標所在的那一行(常用) |
nyy |
n為數字,複製光標所在的向下n行,例如20yy則是複製20行(常用) |
y1G |
複製光標所在行到第一行的所有數據 |
yG |
複製光標所在行到最後一樣的所有數據 |
y0 |
複製光標所在的那個字符到該行行首的所有數據 |
y$ |
複製光標所在的那個字符到該行行尾的所有數據 |
yw |
拷貝一個單詞 |
nyw |
拷貝n個單詞(n表示數字) |
p |
後置粘貼 |
P |
前置粘貼 |
保存:
| 命令 | 說明 |
|---|---|
:w |
直接保存 |
:w file |
保存成新文件 |
退出:
| 命令 | 說明 |
|---|---|
:q |
退出 |
強制執行:
| 命令 | 說明 |
|---|---|
:wq! |
強制保存退出 |
:q! |
強制退出 |
顯示行號:
| 命令 | 說明 |
|---|---|
:set nu |
顯示行號 |
配置系統:
- 全局配置
/etc/virc - 用戶級別
~/vimrc
vim搜索
| 命令 | 說明 |
|---|---|
/字符串 |
比如搜索user,輸入/user |
按下回車之後,可以看到vim已經把光標移動到該字符處和高亮了匹配的字符串
查看下一個匹配,按下n(小寫n)
跳轉到上一個匹配,按下N(大寫N)
搜索後,我們打開別的文件,發現也被高亮了,怎麼關閉高亮?
命令模式下,輸入:nohlsearch 也可以:set nohlsearch; 當然,可以簡寫,noh或者 set noh。
Linux文件操作
實用快捷鍵
Ctrl+L:清理終端的內容,就是清屏的作用。同clear命令
Ctrl+D:給終端傳遞EOF(End Of File,文件結束符)
Shift+PgUp:用於向上滾屏,與鼠標的滾輪向上滾屏是一個效果
Shift+PgDn:用於向下滾屏,與鼠標的滾輪向下滾屏是一個效果
Ctrl+A:光標跳到一行命令的開頭。Home鍵有相同的效果
Ctr+E:光標跳到一行命令的結尾。End鍵具有相同的效果
Ctrl+U:刪除所有光標左側的命令字符
Ctrl+K:刪除所有在光標右側的命令字符
Ctrl+W:刪除光標左側的一個」單詞「
Ctrl+Y:粘貼,用Ctrl+U,Ctrl+K
locate:快速查找
locate命令用於定位要查找的文件,而且此命令很快,」locate「是英語」定位「的意思
用法:
終端會列出所有包含了search_content的文件和目錄
locate search_content
在使用locate命令查找文件時,大家可能會遇到這樣的問題
我剛創建的文件,為什麼用locate命令查找不到呢?
這正好是locate命令的缺陷,locate命令不會對你實際的整個硬盤進行查找,而是在文件的數據庫里查找記錄,locate命令的原理如下圖所示
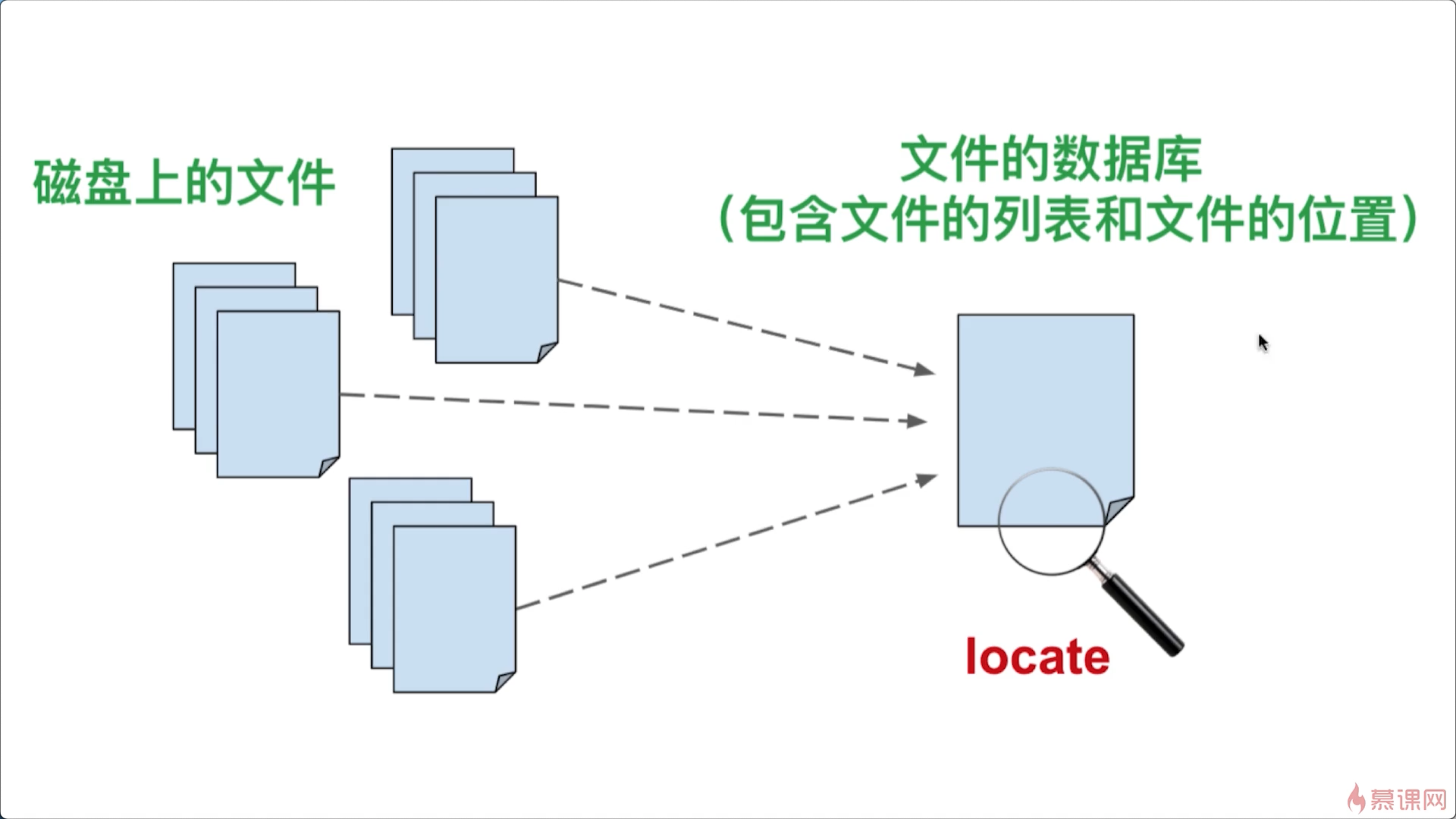
對於剛創建不就的文件,因為它們還沒有被收錄進文件數據庫,因此locate命令就找不到其索引,自然就不會反悔任何結果
linux系統一般每天會更新一次文件數據庫,因此,只要你隔24小時再用locate查找,應該就能找到你剛創建的文件了,但是,你可能不想等這麼久,因此也提供了updatedb命令強制系統立即更新文件數據庫,updatedb命令只能由root用戶執行,這個命令執行需要一點時間,一旦執行成功,就可以使用locate命令查找剛剛創建的文件了,locate命令會列出所有在文件數據庫中找到的內容,有時候結果太多了,太繁雜了,而且locate命令還不能找到一天之內創建的文件,所以系統提供了另一個查找的命令find
find:深入查找
find命令是查找文件的利器,find是英語」找到「的意思,而且它可以讓我們對每個找到的文件做後續的操作,與locate命令不同,find命令不會在文件數據庫中查找文件的記錄,而是遍歷你的實際硬盤
用法:
# 與locate命令不同的是,find命令只會查找完全符合名字的文件
find 查找目錄(默認當前目錄) -name "文件名"
# 不過也可以用通配符 *來匹配多個名稱
# 在/var/log目錄下查找以syslog開頭的文件
find /var/log -name "syslog*"
# 根據文件大小查找
# 查找/var/log中大小超過10M的文件
# -size:size指定查找文件的大小(M兆,K千位元組,G千兆位元組)
find /var/log -size +10M
# 查找小於50M的
find /var/log -size -50M
# 查找等於20M的
find /var/log -size 20M
# 根據文件最近訪問時間查找
# -atime參數:atime是access和time的縮寫,表示訪問時間
# -atime參數後面緊跟的-7表示7天之內,減號的作用表示小於
find /var/log -name "*.txt" -atime -7
# 僅查找目錄或文件
# -type d:只查找目錄類型。d是directory的首字母,表示」目錄「
# -type f:只查找文件類型。f是file的首字母,表示「文件」
# 如果不用-type參數指定類型,那麼find命令默認是查找目錄和文件
find /var/log -name "file" -type d
# 刪除查找到的文件
# -delete參數:
find /var/log -name "*.jpg" -delete
# 調用命令
# -exec參數:使用-exec參數,可以後接一個命令,對每個查找到的文件進行操作
# exec是execute的縮寫,是英語「執行」的意思
# 假如要將/var/log目錄下的所有查找到的txt文件的訪問權限都改為600
find /var/log -name "*.txt" -exec chmod 600 {}\;
# 你可以將-exec參數換成-ok參數,用法一樣,只不過-ok參數會對每一個查找到的文件都確認提示
ls:列出文件和目錄
ls是list的縮寫,是英語「列出」的意思,用於列出文件和目錄
ls -a:列出所有的目錄和文件,包括隱藏的,包含.和..
ls -A:列出所有的目錄和文件,包括隱藏的,不包含.和..
ls -l:列出一個顯示文件和目錄的詳細信息的列表
ls -lh:h是human readable的縮寫,表示「適合人類閱讀的」
ls -lt:t是time的縮寫,表示時間,按文件最近一次修改時間排序
du:顯示目錄包含的文件大小
du是英語disk usage的縮寫,表示「磁盤使用/佔用」,du命令可以讓我們知道文件和目錄所佔的空間大小
相比ls -l命令,du命令統計的才是真正的文件大小
du命令會深入遍歷每個目錄的子目錄,統計所有文件的大小
du -h:以適合人類閱讀的方式展示
默認情況下,du命令只顯示目錄的大小,如果加上-a參數,則會顯示目錄和文件的大小
du -s:只顯示統計大小
du -sh:顯示統計大小(以適合人類閱讀的方式)
cat:顯示文件內容
cat命令可以一次性在終端中顯示文件的所有內容,cat是concatenate的縮寫,表示「連接/串聯」
cat -n:顯示文件內容時帶上行號
適合文件內容比較少的文件如果文件比較大,更適合用less命令
less:顯示文件內容
和cat命令最大的區別:less會一頁一頁的顯示文件內容,還有一個more命令,more是「更多」,less是「更少」
more命令和less命令功能類似,more沒有less那麼強大,比如more命令不能往後翻頁,只能往前
less命令中最基本最常用的快捷鍵
空格鍵:文件內容讀取下一個終端屏幕的行數,相當於前進一個屏幕(頁),與鍵盤上的PageDown(下一頁)效果一樣
回車鍵:讀取下一行文件內容,也就是前進一行
d鍵:前進半頁(半個屏幕)
b鍵:後退一頁。與鍵盤上的PageUp(上一頁)效果一樣
y鍵:後退一行。與鍵盤上的向上效果是一樣的
u鍵:後退半頁(半個屏幕)
q鍵:停止讀取文件,終止less命令
=鍵:顯示你在文件的什麼位置,會顯示當前頁面的內容是文件中第幾行到第幾行,整個文件所含行數,所含字符數
h鍵:顯示幫助文檔。按q鍵退出幫助文檔
/:進入搜索模式,在斜杠後面輸入你要搜索的文件,按下回車鍵,就會把所有符合的結果都標識出來,要在搜索所得結果中跳轉,可以按n鍵,跳到下一個符合項目,按N鍵跳到上一個符合項目
head:顯示文件的開頭
head在英語中是「頭部」的意思,顧名思義,這個命令用於顯示文件的開頭,默認情況下,head會顯示文件的頭10行
head -n 數字:指定顯示的行數
tail:顯示文件的結尾
tail在英語中是「尾部」的意思,顧名思義,這個命令用於顯示文件的結尾,默認情況下,tail會顯示文件結尾的最後10行內容
tail -n 數字:指定顯示的行數
tail命令還可以配合-f參數來實時追蹤文件的更新,可以用快捷鍵Ctrl+c來終止tail -f命令
默認地,tail -f會每過1秒檢查一下文件是否有新內容
可以指定間隔檢查的秒數,用-s參數:tail -f -s 4 文件名
touch:創建一個空白文件
touch命令其實一開始的設計初衷是修改文件的時間戳,就是可以修改文件的創建時間或修改時間,讓電腦以為文件是在那個時候被創建或修改的
如果touch命令後面跟着的文件名是不存在的文件,它會創建一個
mkdir:創建一個目錄
mkdir命令就是用於創建一個目錄的,mkdir是mk和dir的縮寫。mk是make的縮寫,表示創建
索要創建的目錄的名字里有空格怎麼辦呢?加上引號
還可以用-p參數來遞歸創建目錄結構:mkdir -p one/two/three
cp:拷貝文件或目錄
cp是英語copy的縮寫,表示「拷貝」,cp命令不僅可以拷貝單個文件,還可以拷貝多個文件,也可以拷貝目錄
拷貝目錄,只要在cp命令之後加上-r或者-R參數,r大寫和小寫作用是一樣的,都表示recursive,也就是遞歸的,拷貝的時候,目錄中的所有內容(子目錄和文件)都會被拷貝
使用通配符*:cp*.txt folder表示把當前目錄下所有以.txt結尾的文件都拷貝到folder目錄中,cp ha* folder表示把當前目錄所有以ha開頭的文件都拷貝到folder目錄中
rm:刪除文件和目錄
rm是英語remove的縮寫,表示「移除」,這個命令就是用來刪除東西的
rm -i:向用戶確認是否刪除,保險起見,用rm命令刪除文件時,可以加上-i參數,這樣對於每個要刪除的文件,終端都會詢問我們是否確定刪除
rm -f:慎用,不會詢問是否刪除,強制刪除
rm -rf:遞歸刪除,千萬不要做 rm -rf /*或 rm -rf /
ln:創建鏈接
ln是link的縮寫,在英語中表示「鏈接」,ln命令用於在文件之間創建鏈接(快捷方式)
在Linux下鏈接有兩種類型:
- Physical link:物理鏈接或硬鏈接
- Symbolic link:符號鏈接或軟鏈接
在linux中,文件在硬盤上的存儲分兩部分:文件名和文件內容,文件名的列表是存儲在硬盤的其它地方的,和文件內容分開存放,方便linux管理
其實每個文件有三部分:文件名、權限和文件內容,我們這裡簡化地將文件分為兩部分:文件名和文件內容
每個文件的文件內容被分配到一個標號號碼,就是inode,因此每個文件名都綁定到它的文件內容(用inode標識)
硬鏈接
用法:
ln file1 file2
如果我們刪除了file1,那麼對file2沒什麼影響,刪除file2對file1也沒有什麼影響,我們可以理解為用rm命令就是斷開了文件名和文件內容之間的那根線,
對於硬鏈接來說,刪除任意一方的文件,共同指向的文件內容並不會從硬盤上被刪除
硬鏈接原理:使鏈接的兩個文件共享同樣文件內容,就是同樣的inode,一旦兩個文件之間有了硬鏈接,那麼修改其中一個文件,修改的是相同的一塊內容,只不過我們可以用兩個文件名來獲取到文件內容
硬鏈接缺陷:只能創建指向文件的硬鏈接,不能創建指向目錄的(通過一些參數的修改,也可以創建指向目錄的硬鏈接,但是比較複雜),軟鏈接可以指向文件或目錄,對於目錄,一般都是用軟鏈接
可以用ls -i命令查看一下(-i參數可以顯示文件的inode)
軟連接
軟鏈接才真正像我們在windows下的快捷方式,原理很相似
用法:
ln -s file1 file2
創建硬鏈接時ln不帶任何參數,創建軟連接需要加上-s參數
軟鏈接的特點:如果我們刪除了file2,沒什麼大不了的,file1不會受到影響,如果刪除file1,file2會變成「死鏈接」,因為指向的文件不見了
grep:篩選數據
grep是Globally search a Regular Expression and Print的縮寫,意思是「全局搜索一個正則表達式,並且打印」,grep的功能簡單說是在文件中查找關鍵字,並顯示關鍵字所在的行
用法:
grep 搜索內容 要被搜索的文件
# -i參數:忽略大小寫,默認情況下,grep命令是區分大小寫的,i是英語ignore的縮寫,表示「忽略」
grep -i
# -n參數:顯示行號,-n參數的作用很簡單,就是顯示搜索到的文本所在的行,n是英語number的縮寫,表示「數字,編號」
grep -n
# 示例
grep -n search_content /etc/profile
# -v參數:只顯示文本不在的行,v是invert的縮寫,表示「顛倒,倒置」
grep -v
# 示例
grep -v search_content /etc/profile
# -r參數:在所有子目錄和子文件中查找
grep -r
# 示例
grep -r "hello world" /folder
# 正則查找
# ^匹配行首
grep -E ^path /etc/profle
# 包含Path和path的會被搜索到
grep -E [Pp]ath /etc/profile
# 包含a-zA-Z之間任意字母的都可以被搜索到
grep -E [a-zA-Z] /etc/profile
# 在CentOS中,不加-E也是可以的
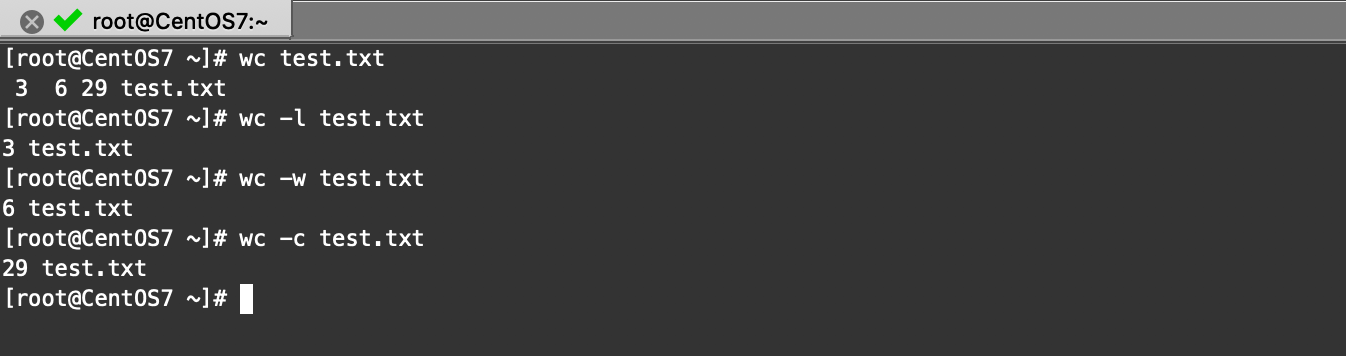
wc:文件統計
wc是word count的縮寫,不僅可以用來統計單詞數目,還可以用來統計行數、字符數、位元組數等
用法:
# wc命令顯示的三個數字分別是 行數 單詞數 位元組數 文件名
wc 文件名
# -l參數:統計行數,l是英語「line」的縮寫,表示「行」
wc -l test.txt
# -w參數:統計單詞數,w是「word」的縮寫,表示「單詞」
wc -w test.txt
# -c參數:統計位元組數,c是「character」的縮寫,表示「字符」
wc -c text.txt
示例:
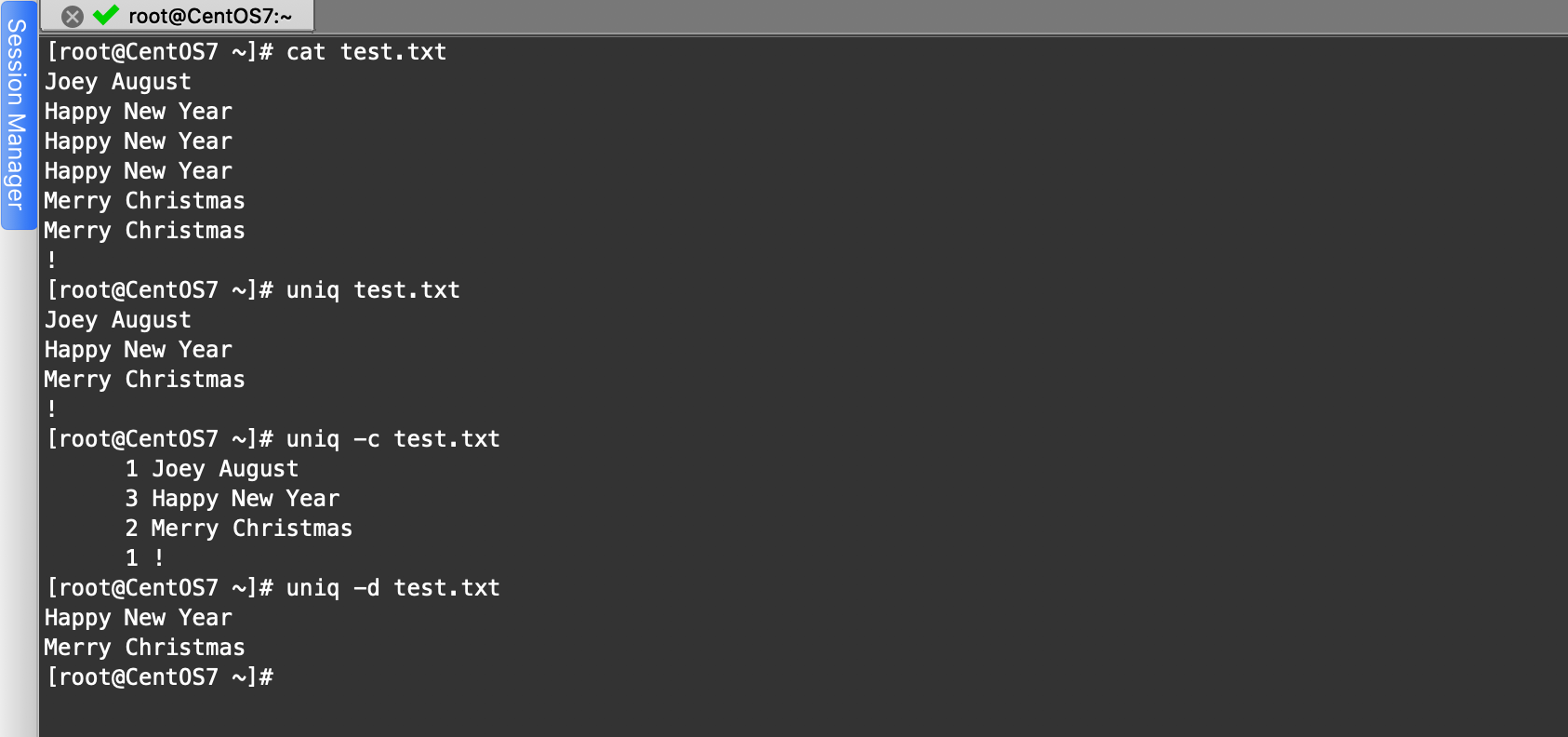
uniq:刪除文件中的重複內容
uniq是英語unique的縮寫,表示「獨一無二的」,unique命令有點「呆」,只能將連續的重複行變為一行
用法:
uniq 文件名
# -c參數:統計重複的行數,c是統計count的縮寫,表示「統計,計數」
uniq -c test.txt
# -d參數:只顯示重複的行的值,d是duplicated的縮寫,表示「重複的」
uniq -d test
示例:
scp:網間拷貝
scp是Secure Copy的縮寫,表示」安全拷貝「,scp可以使我們通過網絡,把文件從一台電腦拷貝到另一台電腦
scp是基於SSH(Secure Shell)的原理來運作的,SSH會在兩台通過網絡連接的電腦之間創建一條安全通信的通道,scp就利用這條管道安全地拷貝文件
用法:
# source_file表示源文件,destination_file就是目標文件
# 這兩個文件都可以用如下方式來表示 user@ip:file_name
# []以及括號內的內容可以省略,默認是22端口,和SSH一樣
scp [-P 端口號] source_file destination_file
rsync:同步備份
rsync是remote synchronize的縮寫,remote表示」遠程「,synchronize表示」同步「
因此rsync命令主要用於」遠程同步文件「,如果系統沒有rsync命令,可以安裝
sudo yum install rsync
rsync可以使我們同步兩個目錄,不管這兩個目錄位於同一台電腦還是不同的電腦(用網絡連接)
rsync應該是最change用於」增量備份「的命令了,增量備份(incremental backup)是備份的一種類型,指在一次全備份或上一次增量備份後
用法:
# 將images目錄下的所有文件備份到backups目錄下
rsync -arv images/ backups/
# -a:保留文件的所有信息,包括權限、修改日期等
# -r:遞歸調用。表示子目錄下的所有文件都包括
# -v:冗餘模式。輸出詳細操作信息,v是verbose的縮寫,是」冗餘「的意思
# 默認地,rsync在同步時並不會刪除目標目錄的文件
# 例如,你的源目錄(被同步目錄)中刪除了一個文件,但是rsync同步時,它不會刪除同步目錄中的相同文件
rsync -arv --delete images/ [email protected]:backups/
你可以自己配置rsync,使得它從指定目錄(可以是多個目錄)備份到指定IP地址的目錄下,而且可以指定哪些類型文件是要備份的,哪些類型不要備份,然後把這一長串命令同意用shell腳本來寫成一個文件(例如取名叫backup),使之可執行(用chmod + x命令),再把這個文件的路徑添加到PATH環境變量中
用戶群組系統
sudo -i:切換到root身份
sudo 是英語Substitute User DO的縮寫,substitute是」替換,代替、替身「的意思,user是」用戶「的意思,do是」做「的意思,連在一起就是」替換用戶來執行…「的意思
終端會提示你輸入密碼,至少第一次會要求輸入密碼,此密碼是你個人的密碼。
useradd:添加新用戶
user是英語」用戶「的意思,add是英語」添加「的意思
useradd用於添加用戶。用法:命令後接要創建的用戶名
用法:
useradd joey
passwd:設置/修改密碼
passwd是password這個英語單詞的縮寫,表示」密碼「
用法:
passwd joey
userdel:刪除用戶
單單用userdel命令,不加參數的話,只會刪除用戶,但是不會刪除在/home目錄中的用戶家目錄
如果想要連次用戶的家目錄頁一併刪除的話,可以加上-r或-remove這個參數
用法:
userdel -r joey
userdel -remove joey
groupadd:創建群組
groupadd是group和add的縮寫,group是英語」群組「的意思,add是英語」添加「的意思
groupadd命令用於添加一個新的群組
用法:
groupadd 組名
# 示例:
groupadd friends
usermod:修改用戶
usermod是user和modify的縮寫,user是用於」用戶「的意思,modify是」修改「的意思
usermod命令用於修改用戶的賬戶
用法:
usermod
# -l參數:對用戶重命名,/home中的家目錄名不改變,需要手動修改
# -g參數:修改用戶所在群組
# 將joey的所屬於組改為friends
usermod -g friends joey
# -G參數:將一個用戶添加到多個群組,群組名之間用逗號分隔,而且沒有空格
usermod -G group1,group2,group3
# -a參數:追加,如果想不離開原先的群組,又想加入新的群組,可以在-G的基礎上加上-a參數
usermod -aG group4,group5
groups:查看用戶所屬組
用groups(」群組「)命令可以獲知一個用戶屬於哪個(些)群組
groups joey
groupdel:刪除群組
groupdel是group和delete的縮寫,group是英語」群組「的意思,delete是英語」刪除「的意思
groupdel命令用於刪除一個已存在的群組
groupdel group1
chown:改變文件的所有者
chown命令用於改變文件的所有者,需要root身份才能運行。chown是change和owner的縮寫。
用法:
chown 用戶 文件
# chown也可以改變文件的群組
chown 用戶:組 文件
# -R參數:遞歸修改文件所有者,只能是大寫,小寫不起作用,使得被修改的目錄的所有子目錄和文件都改變所有者
chown -R 用戶 目錄
chgrp:改變文件的群組
chgrp是change和group的縮寫,用戶改變文件的群組
用法:
chgrp 群組名 文件名
chomod:修改訪問權限
linux系統里,每個文件和目錄都有一列權限樹形,訪問權限知名了誰有讀/寫/執行的權利,chmod命令不需要是root用戶才能運行,只要你是此文件所有者,就可以使用chmod來修改文件的訪問權限
chmod是change和mode的縮寫,change是英語」改變「的意思,mode是」模式「的意思
chmod命令用於修改文件的各種訪問權限
linux系統對每種權限(r,w和x)分配了對應的數字
| 權限 | 數字 |
|---|---|
r |
4 |
w |
2 |
x |
1 |
要合併這些權限,就需要做簡單的加法了。
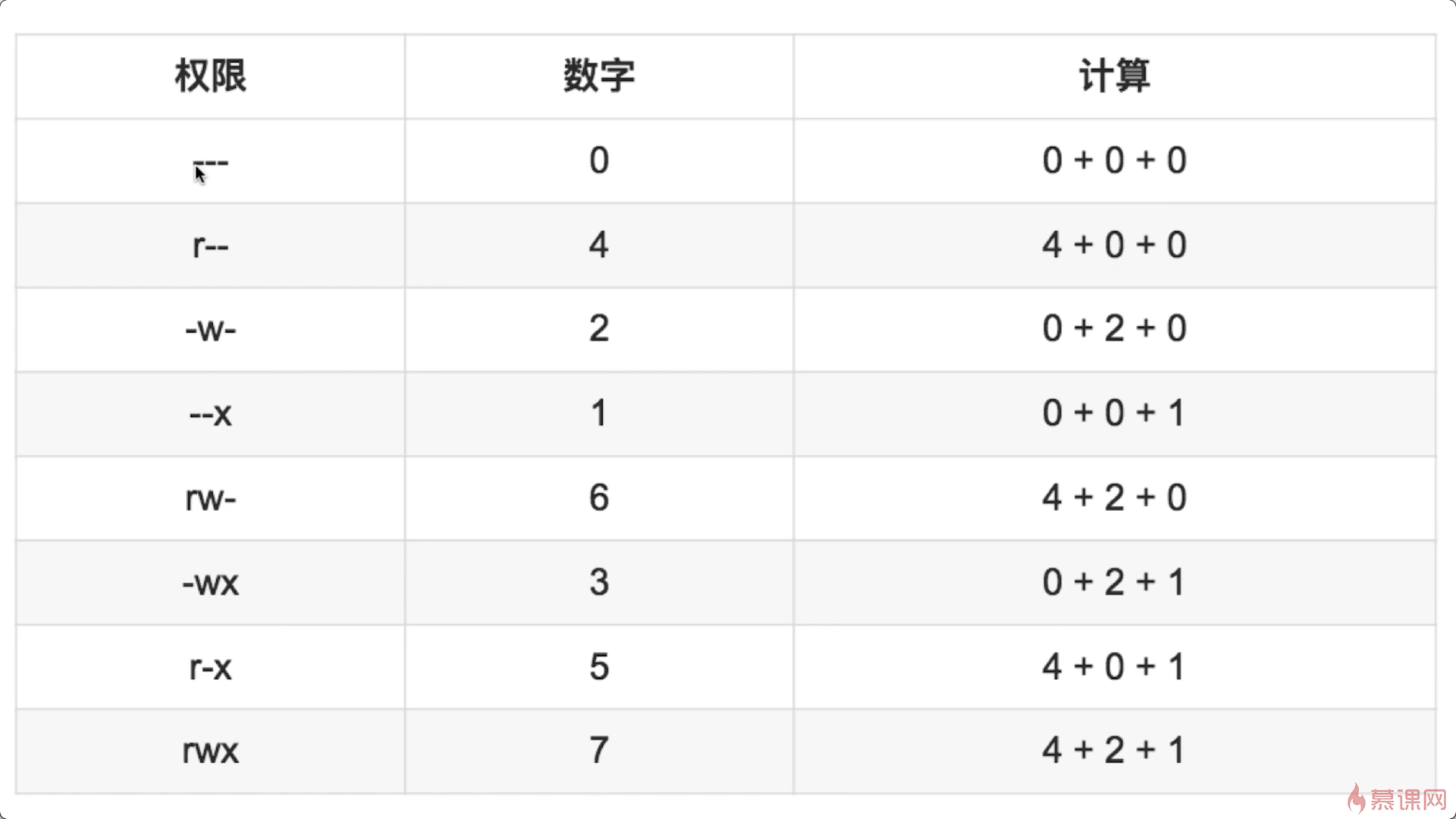
訪問權限有三組(所有者的權限,群組的權限,其它用戶的權限)
用法:
# text.txt的所屬用戶有讀寫權限,所屬組和其它用戶沒有任何權限
chmod 600 text.txt
# -R參數:遞歸地修改訪問權限
# chmod 配合 -R參數可以遞歸地修改文件訪問權限
chmod -R 700 /home/joey
除了用戶,可以用另一種方式來分配文件的訪問權限:用字母
u:user的縮寫,表示所有者
g:group的縮寫,表示群組用戶
o:other的縮寫,表示其它用戶
a:all的縮寫,表示所有用戶
+:加號,表示添加權限
–:減號,表示減去權限
–:等號,表示分配權限
示例:
chmod u+rx file 文件file的所有者增加讀和運行的權限
chmod g+r file 文件file的群組用戶增加讀的權限
chmod o-r file 文件file的其它用戶移除讀的權限
chmod g+r o-r file 文件file的群組用戶增加讀的權限,其它用戶移除讀的權限
chmod u=rwx,g=r,o=- file 文件file的所有者分配讀、寫、執行的權限,群組分配讀的權限,其它用戶沒有任何權限
軟件管理
軟件倉庫
在Red Hat一族裡,軟件包的後綴是.rpm,rpm是Red Hat Package Manager的縮寫,表示」紅帽軟件包管理器「,CentOS作為Red Hat一族的一員,也是用的.rpm的軟件包
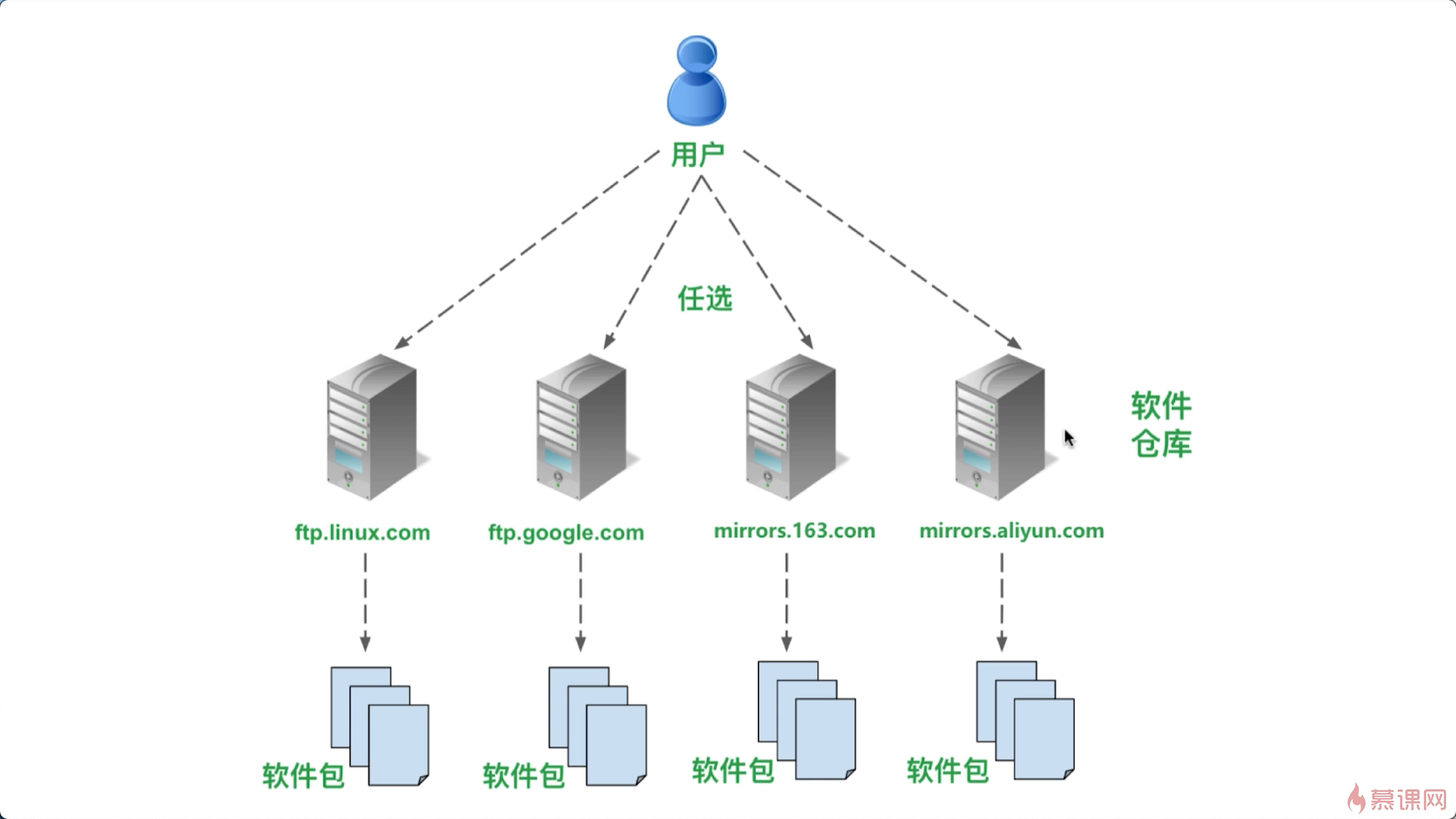
用默認的官方版本是最好的,但是會比較卡,所以我們要學習如何切換軟件倉庫,CentOS系統使用的軟件倉庫的列表是記錄在一個文件中,要編輯的那個包含軟件倉庫的列表的文件是/etc/yum.repos.d/CentOS-Base.repo,這個文件時系統文件,只能被root用戶修改
修改CentOS7默認yum源為mirros.aliyun.com
# 1.備份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
# 2.下載新的CentOS-Base.repo 到 /etc/yum.repos.d/
wget -O /etc/yum.repos.d/CentOS-Base.repo //mirrors.aliyun.com/repo/Centos-7.repo
# 3.運行 yum makecache 生成緩存
yum makecache
wget:下載文件
wget可以使我們直接從終端控制台下載文件,只需要給出文件的HTTP或FTP地址
用法:
wget addr
# -c參數:繼續一個中斷的下載,c是英語continue的縮寫,表示」繼續「
wget -c //www.php.net/distributions/php-7.4.14.tar.gz
# -O參數:重命名(大寫字母O)
wget -c //www.php.net/distributions/php-7.4.14.tar.gz -O php.tar.gz
# -o參數:保存輸出日誌(小寫字母o)
wget -c //www.php.net/distributions/php-7.4.14.tar.gz -O php.tar.gz -o wget.log
yum:包管理工具
yum是CentOS中的默認包管理工具
# 搜索軟件包
sudo yum search
# 安裝軟件包
sudo yum install
# 刪除軟件包
sudo yum remove
# 本地的.rpm軟件包,可以用rpm命令來安裝
sudo rpm -ivh xxx.rpm # 用於安裝
sudo rpm -e 包名 # 用於卸載
# 本地的.rpm軟件包,也可以用yum命令來安裝
sudo yum localinstall xxx.rpm # 用於安裝
sudo yum remove 包名 # 用於卸載
進程和系統監測
w:都有誰,在做什麼?
user:當前登錄的用戶
From:登錄IP
load average:負載,後面的三個數表示1分鐘、5分鐘、15分鐘之內的平均負載

ps:進程的靜態列表
ps是Process Status的縮寫,process是英語「進程」的意思,status是「狀態」的意思
ps命令用戶顯示當前系統中的進程,ps命令顯示的進程列表不會隨着時間而更新,是靜態的
用法:
# 列出所有的進程
ps -ef
# 以喬木裝列出所有進程
ps -efH
# 列出某個用戶運行的進程
ps -u 用戶名
# 通過CPU和內存使用來過濾進程
ps -aux | less
# 根據CPU使用率來降序排序
ps -aux --sort -pcpu | less
# 根據內存使用率來降序排序
ps -aux --sort -pmem | less
# 以樹形結構顯示進程,和pstree效果類似
ps -axjf
top:進程的動態列表
q:退出top
h:顯示幫助文檔,也就是哪些按鍵可以使用,按下任意鍵返回,按q回到top命令的主界面
B:大寫的B,加粗某些信息
f/F:在進程列表中添加或刪除某些列
u:依照用戶來過濾顯示
k:結束某個進程
s:改變刷新頁面的時間,默認地,頁面每隔3秒刷新一次
netstat:網絡統計
netstat命令很好記,它由兩部分組成:net和stat,net是network的縮寫,表示」網絡「,stat是statistics的縮寫,表示」統計「
# 查看命令執行的二進制文件在哪兒
which netstat
# 查看這個二進制屬於哪個rpm包
rpm -qf /usr/bin/netstat
netstat -i:列出電腦的所有網絡接口的一些統計信息
RX是receive(表示」接收「)的縮寫
TX是transmit(表示」發送「)的縮寫

- MTU:Maximum Transmission Unit的縮寫,表示」最大傳輸單元「,指一種通信協議的某一層上能通過的最大數據包大小(單位是位元組)
- RX-OK:在此接口接收的包中正確的包數,」OK「表示」沒問題的,好的「
- RX-ERR:在此接口接收的包中錯誤的包數,」ERR「是error的縮寫,表示」錯誤「
- RX-DRP:在此接口接收的包中丟棄的包數,」DRP「是drop的縮寫,表示」丟棄「
- RX-OVR:在此接口接收的包中,由於過速而丟失的包數,」OVR「是over的縮寫, 表示」結束「
- 類似的,TX-OK、TX-ERR、TX-DRP、TX-OVR表示在此接口發送的包中對應的包數
# 列出所有開啟的連接
netstat -uta
# -u:顯示UDP連接
# -t:顯示TCP連接
# -a:不論連接狀態如何,都顯示
# 列出狀態是LISTEN的統計信息
netstat -lt
# 列出總結性的統計信息
netstat -s
#-s:s是summary的縮寫,表示」總結「
kill:殺死進程
有時候,系統會突然卡住。這在Linux中也是會發生的,在Linux中停止進程有幾種方法
kill是英語「殺死」的意思,有點「小暴力」
kill命令後接需要結束的進程號,也就是之前我們看到的PID,可以通過ps命令或top命令來獲知進程的PID
用法:
kill PID
# 殺死一個進程
kill 1024
# 殺死多個進程 進程號之間用空格隔開
kill 1024 2048
# kill -9 表示立即強制結束進程
kill -9 1024
註:Ctrl+C:停止終端中正在運行的進程,Ctrl+C可以比較有好地中止終端中正在運行的程序(進程)
&:在後台運行進程
讓一個進程在厚愛運行有幾種方法
很簡單的一種:在你要運行的命令最後加上&這個符號
示例:
cp file.txt file-copy.txt &
sudo find / -name "*log" &
sudo find / -name "*log" > output_find &
sudo find / -name "*log" > output_find 2>&1 &
nohup:使進程與終端分離
&符號雖然常用,但卻有一個不可忽視的缺點,就是後台進程與終端相關聯,一旦終端關閉或者用戶登出,進程就自動結束,想讓進程在以上情況下繼續在後台運行
需要用到nohup命名,當用戶註銷(logout)或者網絡斷開時,終端會收到HUP(hangup的縮寫,」掛斷「的意思)信號從而關閉所有子進程,終端被關閉時也會關閉其子進程,可以使用nohup命令使命令不受HUP信號影響
man nohup
nohup cp file.txt file-copy.txt
場景:我現在需要跑腳本批量處理一些數據,但是我又不想盯着控制台看這個腳本的輸出結果,想把這些輸出結果記錄到一個日誌文件裏面
方案:可以使用 Linux 的 nohup 命令,把進程掛起,後台執行
用法:
nohup XXXXXX.sh >> /runtime/deletedata.log &
運行結果(這個數字是進程號):
[1] 13120
有時候可能會報一個提示:
nohup: ignoring input and redirecting stderr to stdout
這個影響不大,不用緊張,也可以加多一個 2>&1 就不會出現這個問題
用法:
nohup XXXXXX.sh >> /runtime/deletedata.log 2>&1 &
TIPS:命令最後面的 & 符號是切換到後台去跑,退出終端也不會退出任務進程
運行這個命令之後呢,會輸出一個進程號,類似上面的輸出,可以使用 top 命令查看運行中的進程,也可以用 ps -aux 查看進程
想要終止這個進程的話只能殺死這個進程,使用 kill 指令處理
kill -9 進程號
TIPS:如果進程掛不起來,可能是端口被佔用了,自行排查處理便可
killall:結束多個進程
同一個程序運行時可能啟動多個進程,一個更快捷的命令是:killall,all是英語「全部」的意思
killall命令就是用於結束全部要結束的進程,不同於kill命令,killall命令後接程序名,而不是PID
host:查看域名對應IP
用法:
host www.baidu.com
whois:了解有關域名的信息
sudo yum install whois
whois www.baidu.com
halt:關機
需要以root身份才能關閉系統
sudo halt
reboot:重啟系統
需要以root身份才能重啟系統
sudo reboot
poweroff:關機
poweroff命令也可以用於關機,直接運行即可關機,不需要root身份:poweroff
iproute2對決net-tools
如今很多系統管理員依然通過組合使用諸如ifconfig、route、arp和netstat等命令行工具(統稱為net-tools)來配置網絡功能,解決網絡故障。net-tools起源於BSD的TCP/IP工具箱,後來成為老版本Linux內核中配置網絡功能的工具。但自2001年起,Linux社區已經對其停止維護。同時,一些Linux發行版比如Arch Linux和CentOS/RHEL 7則已經完全拋棄了net-tools,只支持iproute2。
作為網絡配置工具的一份子,iproute2的出現旨在從功能上取代net-tools。net-tools通過procfs(/proc)和ioctl系統調用去訪問和改變內核網絡配置,而iproute2則通過netlink套接字接口與內核通訊。拋開性能而言,iproute2的用戶接口比net-tools顯得更加直觀。比如,各種網絡資源(如link、IP地址、路由和隧道等)均使用合適的對象抽象去定義,使得用戶可使用一致的語法去管理不同的對象。更重要的是,到目前為止,iproute2仍處在持續開發中。
如果你仍在使用net-tools,而且尤其需要跟上新版Linux內核中的最新最重要的網絡特性的話,那麼是時候轉到iproute2的陣營了。原因就在於使用iproute2可以做很多net-tools無法做到的事情。
對於那些想要轉到使用iproute2的用戶,有必要了解下面有關net-tools和iproute2的眾多對比。
顯示所有已連接的網絡接口
使用net-tools:
ifconfig -a
使用iproute2:
ip link show
激活或停用網絡接口
使用這些命令來激活或停用某個指定的網絡接口。
使用net-tools:
sudo ifconfig eth1 up
sudo ifocnfig eth1 down
使用iproute2:
sudo ip link set down eth1
sudo ip link set up eth1
為網絡接口分配IPv4地址
使用這些命令配置網絡接口的IPv4地址。
使用net-tools:
sudo ifconfig eth1 10.0.0.1/24
使用iproute2:
sudo ip addr add 10.0.0.1/24 dev eth1
值得注意的是,可以使用iproute2給同一個接口分配多個IP地址,ifconfig則無法這麼做。使用ifconfig的變通方案是使用IP別名。
sudo ip addr add 10.0.0.1/24 broadcast 10.0.0.255 dev eth1
sudo ip addr add 10.0.0.2/24 broadcast 10.0.0.255 dev eth1
sudo ip addr add 10.0.0.3/24 broadcast 10.0.0.255 dev eth1
移除網絡接口的IPv4地址
就IP地址的移除而言,除了給接口分配全0地址外,net-tools沒有提供任何合適的方法來移除網絡接口的IPv4地址。相反,iproute2則能很好地完全。
使用net-tools:
sudo ifconfig eth1 0
使用iproute2:
sudo ip addr del 10.0.0.1/24 dev eth1
顯示網絡接口的IPv4地址
按照如下操作可查看某個指定網絡接口的IPv4地址。
使用net-tools:
ifconfig eth1
使用iproute2:
ip addr show dev eth1
同樣,如果接口分配了多個IP地址,iproute2會顯示出所有地址,而net-tools只能顯示一個IP地址。
為網絡接口分配IPv6地址
使用這些命令為網絡接口添加IPv6地址。net-tools和iproute2都允許用戶為一個接口添加多個IPv6地址。
使用net-tools:
sudo ifconfig eth1 inet6 add 2002:0db5:0:f102::1/64
sudo ifconfig eth1 inet6 add 2003:0db5:0:f102::1/64
使用iproute2:
sudo ip -6 addr add 2002:0db5:0:f102::1/64 dev eth1
sudo ip -6 addr add 2003:0db5:0:f102::1/64 dev eth1
顯示網絡接口的IPv6地址
按照如下操作可顯示某個指定網絡接口的IPv6地址。net-tools和iproute2都可以顯示出所有已分配的IPv6地址。
使用net-tools:
ifconfig eth1
使用iproute2:
ip -6 addr show dev eth1
移除網絡設備的IPv6地址
使用這些命令可移除接口中不必要的IPv6地址。
使用net-tools:
sudo ifconfig eth1 inet6 del 2002:0db5:0:f102::1/64
使用iproute2:
sudo ip -6 addr del 2002:0db5:0:f102::1/64 dev eth1
改變網絡接口的MAC地址
使用下面的命令可篡改網絡接口的MAC地址,請注意在更改MAC地址前,需要停用接口。
使用net-tools:
sudo ifconfig eth1 hw ether 08:00:27:75:2a:66
使用iproute2:
sudo ip link set dev eth1 address 08:00:27:75:2a:67
查看IP路由表
net-tools中有兩個選擇來顯示內核的IP路由表:route和netstat。在iproute2中,使用命令ip route。
使用net-tools:
route -n
netstat -rn
使用iproute2:
ip route show
添加和修改默認路由
這裡的命令用來添加或修改內核IP路由表中的默認路由規則。請注意在net-tools中可通過添加新的默認路由、刪除舊的默認路由來實現修改默認路由。在iproute2使用ip route命令來代替。
使用net-tools:
sudo route add default gw 192.168.1.2 eth0
sudo route del default gw 192.168.1.1 eth0
使用iproute2:
sudo ip route add default via 192.168.1.2 dev eth0
sudo ip route replace default via 192.168.1.2 dev eth0
添加和移除靜態路由
使用下面命令添加或移除一個靜態路由。
使用net-tools:
sudo route add -net 172.16.32.0/24 gw 192.168.1.1 dev eth0
sudo route del -net 172.16.32.0/24
使用iproute2:
sudo ip route add 172.16.32.0/24 via 192.168.1.1 dev eth0
sudo ip route del 172.16.32.0/24
查看套接字統計信息
這裡的命令用來查看套接字統計信息(比如活躍或監聽狀態的TCP/UDP套接字)。
使用net-tools:
netstat
netstat -l
使用iproute2:
ss
ss -l
查看ARP表
使用這些命令顯示內核的ARP表。
使用net-tools:
arp -an
使用iproute2:
ip neigh
添加或刪除靜態ARP項
按照如下操作在本地ARP表中添加或刪除一個靜態ARP項。
使用net-tools:
sudo arp -s 192.168.1.100 00:0c:29:c0:5a:ef
sudo arp -d 192.168.1.100
使用iproute2:
sudo ip neigh add 192.168.1.100 lladdr 00:0c:29:c0:5a:ef dev eth0
sudo ip neigh del 192.168.1.100 dev eth0
添加、刪除或查看多播地址
使用下面的命令配置或查看網絡接口上的多播地址。
使用net-tools:
sudo ipmaddr add 33:44:00:00:00:01 dev eth0
sudo ipmaddr del 33:44:00:00:00:01 dev eth0
ipmaddr show dev eth0
netstat -g
使用iproute2:
sudo ip maddr add 33:44:00:00:00:01 dev eth0
sudo ip maddr del 33:44:00:00:00:01 dev eth0
ip maddr list dev eth0
計劃任務(crontab)
在我們使用CentOS系統的過程中,我們會發現系統常常會主動的執行一些任務,這些任務到底是誰在設置工作的呢?如果你想要讓自己設計的備份程序可以自動地在系統下面執行,而不需要手動地啟動它,又該如何設置?這些計劃型的任務可能又分為【單一】任務與【循環】任務,在系統內有時哪些服務在負責?還有還有,如果你想要每年在老婆的生日前一天就發出一封郵件提醒自己不要忘記,可以辦得到嘛?嘿嘿!這些種種要如何處理,接來下我們就來了解了解。
什麼是計劃任務
每個人或多或少都有一些約會或是工作,有的工作是例行性的,例如每年一次的加薪、每個月一次的工作報告、每周一次的午餐彙報、每天需要的打卡等。有的工作則是臨時發生的,例如剛好總公司有高管來訪,需要你準備演講器材等。在生活上也有此類例行或臨時發生的事,例如每年愛人的生日、每天起床的時間等,要有突發性的電子產品大降價(真希望天天都有)等。
那麼Linux的例行性工作是如何實現的呢?咱們的Linux計劃任務是通過crontab與at這兩個東西完成的。這兩個工具有啥異同?就讓我們先來看看。
Linux計劃任務的種類: at、cron
從上面的說明當中,我們可以很清楚地發現兩種計劃任務的方式。
- 一種是例行性的,就是每隔一定的周期要來辦的事項。
- 一種是突發性的,就是這次做完以後就沒有的那一種。
那麼在Linux下面如何處理這兩個功能?那就得使用at與crontab這兩個好東西。
at: at是個可以支持處理僅執行一次就結束的命令,不過要執行at時,必須要有atd這個服務的支持才行。在某些新版的Linux發行版中,atd可能默認並沒有啟動,那麼at這個命令就會失效,不過我們的CentOS默認是啟動的。crontab: crontab這個命令所設置的任務將會循環地一直執行下去,可循環的時間為分鐘、小時、每周、每月或每年等。crontab除了可以使用命令執行外,亦可編輯/etc/crontab來支持,至於讓crontab可以生效的服務則是crond。
下面我們來談一談Linux的系統到底在做什麼事情,怎麼有若干計劃任務在執行呢?然後再回來談一談at與crontab這兩個好東西。
僅執行一次的計劃任務
首先,我們先來談一談單一計劃任務的運行,那就是at這個命令的運行。
atd的啟動方式
要使用單一計劃任務時,我們的Linux系統上班必須要有負責這類計劃任務的服務,那就是atd這個服務。不過並非所有的Linux發行版都默認啟動,所以,某些時刻我們必須要手動將它啟動才行。啟動的方法很簡單,就是這樣:
systemctl restart atd # 重新啟動atd這個服務
systemctl enable atd # 讓這個服務開機就自動啟動
systemctl status atd # 查看一下atd目前的狀態
at的運行方式
既然是計劃任務,那麼應該會有產生任務的方式,並且將這些任務排進計劃列表中。OK!那麼產生任務的方式是怎麼執行的呢?事實上,我們使用at這個命令來產生所要運行的任務,並將這個任務一文本文件的方式寫入/var/spool/at/目錄內,該任務便能等待atd這個服務的使用與執行了,就這麼簡單。
不過,並不是所有的人都可以執行at計劃任務。為什麼?因為安全的原因,很多主機被所謂的【劫持】後,最常發現的就是它們的系統當中多了很多的駭客(Cracker)程序,這些程序非常可能使用計劃任務來執行或搜集系統信息,並定時地返回給駭客團體。所以,除非是你認可的賬號。否則先不要讓它們使用at目錄。那怎麼實現對at的管控呢?
我么可以利用/etc/at.allow與/etc/at.deny這兩個文件來實現對at的使用限制。加上這兩個文件後,at的工作情況其實是這樣的:
- 先尋找/etc/at.allow這個文件,寫在這個文件中的用戶才能使用at,沒有在這個文件中的用戶則不能使用at(即使沒有寫在at.deny當中)。
- 如果/etc/at.allow不存在,就查找/etc/at.deny這個文件,寫在這個at.deny中的用戶則不能使用at,而沒有寫在這個at.deny文件中的用戶,就可以使用at。
- 如果兩個文件都不存在,那麼只有root可以使用at這個命令。
通過這個說明,我們知道/etc/at.allow是管理較為嚴格的方式,而/etc/at.deny則較為鬆散(因為賬號沒有在該文件中,就能夠執行at了)。在一般的Linux發行版當中,由於假設系統上的所有用戶都是可信任的,因此系統通常會保留一個空的/etc/at.deny文件,允許所有人使用at命令(您可以自行檢查一下該文件)。不過,萬一你不希望某些用戶使用at的話,將那個用戶的賬號寫入/etc/at.deny即可,一個賬號寫一行。
循環執行的計劃任務
相對於at是僅執行一次的任務,循環執行的計劃任務則是由cron(crond)這個系統服務來控制的。剛剛談過Linux系統上面原本就有非常多的例行性計劃任務,因此這個系統服務默認啟動的。另外,由於用戶自己也可可以執行計劃任務,所以,Linux也提供用戶控制計劃任務的命令(crontab)。下面我們分別來聊一聊。
用戶的設置
用戶想要建立循環型計劃任務時,使用的是crontab這個命令。不過,為了避免安全性的問題,與at同樣的,我們可以限制使用crontab的用戶賬號。可以使用的配置文件有:
/etc/cron.allow
將可以使用crontab的賬號寫入其中,不在這個文件內的用戶則不可使用crontab。/etc/cron.deny
將不可以使用的crontab的賬號寫入其中,未記錄到這個文件當中的用戶,就可以使用crontab。
與at很像。同樣的,以優先級來說,/etc/cron.allow比/etc/cron.deny要優先。而判斷上面,這兩個文件只選擇一個來限制而已。因此,建議你只要保留一個即可,免得影響自己在設置上面的判斷。一般來說,系統默認保留/etc/cron.deny,你可以將不想讓它執行crontab的那個用戶寫入/etc/cron.deny當中,一個賬號一行。
當用戶使用crontab這個命令來建立計劃任務之後,該項任務就會被記錄到/var/spool/cron中,而且是以賬號來作為根據判斷。舉例來說,kevin使用crontab後,它的任務會被記錄到/var/spool/cron/kevin中。但請注意,不要使用vi直接編輯該文件,因為可能由於輸入語法錯誤,會導致無法執行cron。另外,cron執行的每一項任務都會被記錄到/var/log/cron這個日誌文件中,所以,如果你的Linux不知道是否被植入了木馬時,也可以查找一下/var/log/cron這個日誌文件。
好了,那麼我們就來聊一聊crontab的語法。
crontab [-u username] [-l|-e|-r]
選項與參數:
-u : 只有root才能執行這個任務,亦即幫其他使用者建立/刪除crontab計劃任務。
-e : 編輯crontab的任務內容
-l : 查看crontab的任務內容
-r : 刪除所有的crontab的任務內容,若僅要刪除一項,請用-e去編輯。
範例一:用kevin的身份在每天的12:00發信給自己。
crontab -e
# 此時會進入vi的編輯器界面讓您編輯任務,注意到,每項任務都是一行。
0 12 * * * mail -s "at 12:00" kevin # /home/kevin/.bashrc
#分 時 日 月 周 【命令串】
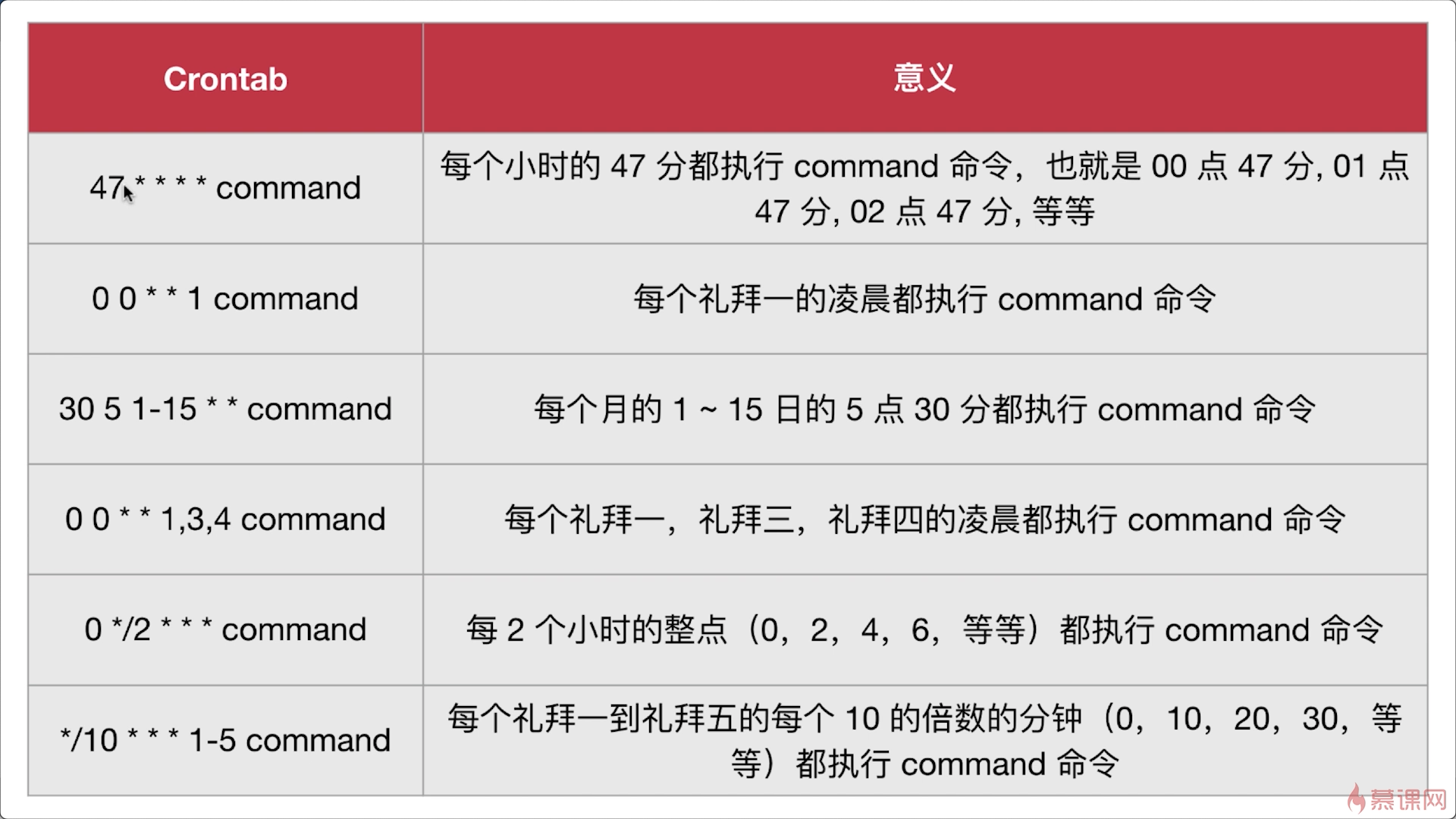
默認情況下,任何用戶只要不被列入/etc/cron.deny當中,那麼它就可以直接執行【crontab -e】去編輯自己的例行性命令。整個過程就如同上面提到的,會進入vi的編輯器界面,然後以一個任務一行來編輯,編輯完畢之後輸入【:wq】並存儲後退出vi即可。而每項任務(每行)的格式都具有六個字段,這六個字段的意義為:
| 代表意義 | 分鐘 | 小時 | 日期 | 月份 | 周 | 命令 |
|---|---|---|---|---|---|---|
| 數字範圍 | 0~59 | 0~23 | 1~31 | 1~12 | 0~7 | 需要執行的命令 |
比較有趣的是那個【周】,周的數字為0或7時,都代表【星期天】的意思。另外,還有下面這些特殊字符:
| 特殊字符 | 代表意義 |
|---|---|
| *(星號) | 代表任何時刻都接受的意思。舉例來說,範例一內那個日、月、周都是*,就代表着【不論何月、何日的星期幾的12:00都執行後續命令】的意思 |
| ,(逗號) | 代表分隔時段的意思。舉例來說,如果要執行的任務是3:00與6:00時,就會是: 0 3,6 * * * command 時間參數還是有五欄,不過第二欄是3,6,代表3與6都適合 |
| -(減號) | 代表一段時間範圍內,舉例來說,8點到12點之間的每小時的20分都執行一項任務: 20 8-12 * * * command 仔細看到第二欄變成8-12,代表8、9、10、11、12都適用的意思 |
| /n(斜線) | 那個n代表數字,亦即【每隔n單位間隔】的意思,例如沒5分鐘執行一次,則: /5 * * * * command 很簡單吧!用/5來搭配,也可以寫成0-59/5,相同意思 |
我們就來搭配幾個例子練習看看。
1.假如你的女朋友生日是5月2日,你想要在5月1日的23:59發一封信給她,這封信的內容已經寫在/home/kevin/lover.txt內了,該如何執行?
答:直接執行crontab -e之後,編輯成為:
59 23 1 5 * mail kiki < /home/kevin/lover.txt
那樣的話,每年kiki都會受到你的這封信。(當然,信的內容就要每年變一變。)
2.假如每五分鐘需要執行/home/kevin/test.sh一次,又該如何?
答:同樣使用crontab -e進入編輯:
*/5 * * * * /home/kevin/test.sh
3.假如你每星期六都與朋友有約,那麼想要每個星期五下午4:30告訴你朋友不要忘記星期六的約會,則:
答:還是crontab -e。
30 16 * * 5 [email protected] < /home/kevin/friend.txt
真的很簡單吧!呵呵!那麼,該如何查詢用戶目前的crontab內容呢?我們可以這樣來看看:
crontab -l
# 注意,若僅要刪除一項任務的話,必須用crontab -e去編輯,如果刪除全部任務,才使用crontab -r。
看到了嗎?如果使用crontab -r,那麼再用crontab -l查看時發現【整個內容會不見了】,所以請注意,【如果只是要刪除某個crontab的任務選項,那麼請使用crontab -e來重新編輯即可】,如果使用-r的參數,是會將所有的crontab數據內容都刪除掉的,千萬注意了。
壓縮與解壓縮
在Linux下面有相當多的壓縮命令可以運行,這些壓縮命令可以讓我們更方便地從網絡上面下載容量較大的文件。此外,我們知道在Linux下面,擴展名沒有什麼特殊的意義。 不過,針對這些壓縮命令所產生的壓縮文件,為了方便記憶,還是會有一些特殊的命名方式,就讓我們來看看吧!
文件壓縮
什麼是文件壓縮呢?我們稍微談一談它的原理,目前我們使用的計算機系統中都是使用所謂的位元組單位來計量。不過,事實上,計算機最小的計量單位應該是bit才對,此外,我們也知道 1位元組=8比特(1Byte=8bit),但是如果今天我們只是記錄一個數字,即1這個數字,它會如何記錄?假設一個位元組可以看成下面的模樣:
由於 1Byte=8bit,所以每個位元組當中會有8個空格,而每個空格只可以是0、1
由於我們記錄的數字是1,考慮計算機所謂的二進制,如此一來,1會在最右邊佔據1個位,而其他的7個位將會自動地被填上0.如下圖所示

你看看,其實在這樣的例子中,那7個位應該是空的才對。不過,為了要滿足目前我們的操作系統數據的讀寫,所以就會將該數據轉為位元組的形式來記錄。而一些聰明的計算機工程師就利用一些複雜的計算方式,將這些沒有使用到的空間【丟】出來,以讓文件佔用的空間變小,這就是壓縮的技術。
另一種壓縮技術也很有趣,它是將重複的數據進行統計記錄。舉例來說,如果你的數據為【111······】共有100個1時,那麼壓縮技術會記錄為【100個1】而不是真的有100個1的位存在。這樣也能夠精簡文件記錄的容量,非常有趣吧!
簡單地說,你可以將它想成,其實文件裏面有相當多的空間存在,並不是完全填滿的,而壓縮技術就是將這些空間填滿,以讓整個文件佔用的容量下降。不過,這些壓縮過的文件並無法直接被我們的操作系統所使用,因此,若要使用這些被壓縮過的文件數據,則必須將它還原回未壓縮前的模樣,那就是所謂的解壓縮。而至於壓縮後與壓縮的文件所佔用的磁盤空間大小,就可以被稱為是壓縮比。
這個壓縮與解壓縮的操作有什麼好處呢?
1.最大的好處就是壓縮過的文件容量變小了,所以你的硬盤無形之中就可以容納更多的數據。
2.此外,在一些網絡數據的傳輸中,也會由於數據量的降低,好讓網絡帶寬可以用來做更多的工作,而不是老卡在一些大型文件傳輸上面。
Linux系統常見壓縮命令
在Linux的環境中,壓縮文件的擴展名大多是: *.tar、*.tar.gz、*.gz、*.Z、*.bz2、*.xz。為什麼會有這樣的擴展名?不是說Linux的擴展名沒有什麼作用嗎?
這是因為Linux支持的壓縮命令非常多,且不同的命令所用的壓縮技術並不相同,當然彼此之間可能就無法互通/解壓縮文件。所以,當你下載到某個文件時,自然就需要知道該文件是由哪種壓縮命令所製作出來的,好用來對照對照着解壓縮,也就是說,雖然Linux文件的屬性基本上是與文件名沒有絕對關係的,但是為了幫助我們人類小小的腦袋,所以適當的擴展名還是必要的,下面我們就列出幾個常見的壓縮文件擴展名:
*.gz gzip程序壓縮的文件
*.bz2 bzip2程序壓縮的文件
*.xz xz程序壓縮的文件
*.zip zip程序壓縮的文件
*.Z compress程序壓縮的文件
*.tar tar程序打包的文件,並沒有壓縮過
*.tar.gz tar程序打包的文件,並且經過gzip的壓縮
*.tar.bz2 tar程序打包的文件,並且經過bzip2的壓縮
*.tar.xz tar程序打包的文件,並且經過xz的壓縮
Linux常見的壓縮命令就是gzip、bzip2以及最新的xz,至於compress已經不流行了。為了支持windows常見的zip,其實Linux也早就有zip命令了。gzip是由GNU計劃所開發出來的壓縮命令,該命令支持已經替換了compress。後台GNU又開發出了bzip2及xz這幾個壓縮比更好的壓縮命令。不過,這些命令通常僅能針對一個文件來壓縮與解壓縮,如此一來,每次壓縮與解壓縮都要一大堆文件,豈不煩人?此時,這個所謂的【打包軟件,tar】就顯得很重要。
這個tar可以將很多文件打包成一個文件,甚至是目錄也可以這麼玩。不過,單純的tar功能僅僅是打包而已,即將很多文件結合為一個文件,事實上,它並沒有提供壓縮的功能,後台,GNU計劃中,將整個tar與壓縮的功能結合在一起,如此一來,提供用戶更方便且更強大的壓縮與打包功能,下面我們就來談一談這些在Linux下面基本的壓縮命令。
gzip
gzip可以說是應用最廣的壓縮命令了,目前gzip可以解開compress、zip和gzip等軟件所壓縮的文件,至於gzip所建立的壓縮文件為*.gz,讓我們來看看這個命令的語法:
gzip [-cdtvn] 文件名
選項與參數:
-c: 將壓縮的數據輸出到屏幕上,可通過數據流重定向來處理;
-d: 解壓縮的參數;
-t: 可以用來檢驗一個壓縮文件的一致性,看看文件有無錯誤;
-v: 可以顯示出原文件/壓縮文件的壓縮比等信息;
-n: n為數字的意思,代表壓縮等級,-1最快,但壓縮比最差,-9最慢,但是壓縮比最好,默認是-6
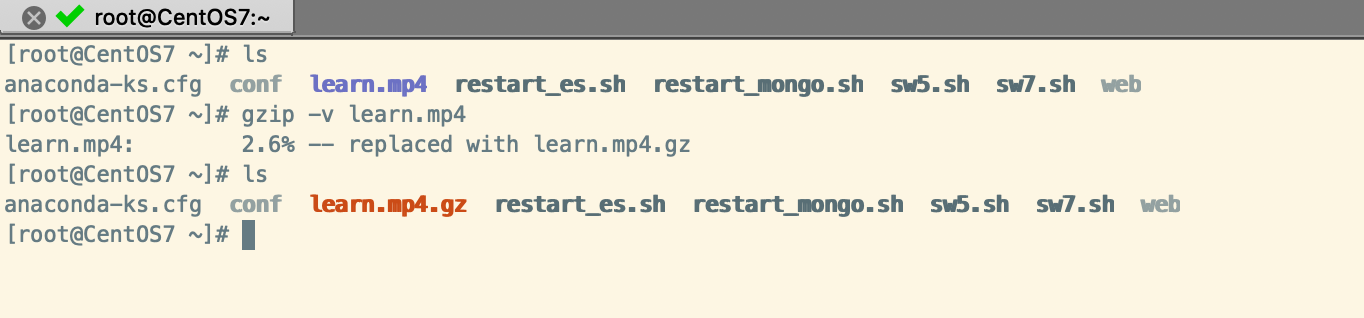
示例1:壓縮文件(gzip -v 文件名)
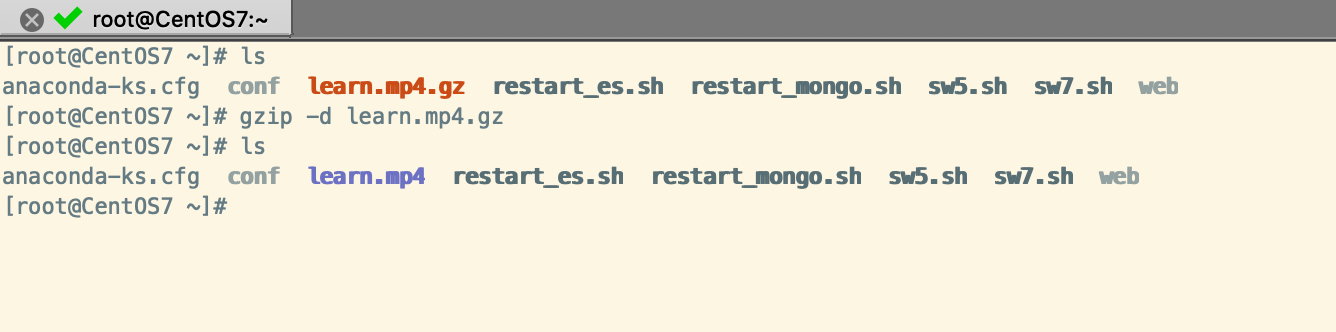
示例2:解壓縮文件(gzip -d 文件名)
示例3:按照指定壓縮比壓縮(gzip -9 文件名)


示例4:查看壓縮文件的內容(zcat 文件名)

示例5:壓縮為指定文件名(gzip -c 文件名 > 指定文件名)

當你使用gzip進行壓縮時,在默認的狀態下原本的文件會被壓縮成為.gz後綴的文件,源文件就不存在了,這點與一般習慣使用Windows做壓縮的朋友所熟悉的情況不同,要注意。cat/more/less可以使用不同的方式來讀取純文本文件,那麼zcat/zmore/zless則可以對應於cat/more/less的方式來讀取純文件文件被壓縮後的壓縮文件。
bzip2
若說gzip是為了替換compress並提供更好的壓縮比而成立的,那麼bzip2則是為了替換gzip並提供更加的壓縮比而來。bzip2真是很不錯的東西,這玩意的壓縮比竟然比gzip還要好,至於bzip2的用法幾乎與gzip相同,看看下面的用法吧!
bzip2 [-cdkzvn] 文件名
選項與參數:
-c: 將壓縮的數據輸出到屏幕上,可通過數據流重定向來處理;
-d: 解壓縮的參數;
-k: 保留原始文件,而不是刪除原始文件;
-z: 壓縮的參數(默認值,可以不加);
-v: 可以顯示出原文件/壓縮文件的壓縮比等信息;
-n: n為數字的意思,代表壓縮等級,-1最快,但壓縮比最差,-9最慢,但是壓縮比最好,默認是-6
示例:
bzip2 -v 待壓縮文件名
bzip2 -d 壓縮後的文件名
bzip2 -9 -c 待壓縮的文件名 > 自定義壓縮文件名
xz
雖然bzip2已經具有很棒的壓縮比,不過顯然某些自由軟件開發者還不滿足,因此後來還推出了xz這個壓縮比更高的軟件。這個軟件的用法也跟gzip/bzip2幾乎一模一樣,那我們就來看一看。
xz [-cdtlkn] 文件名
選項與參數:
-c: 將壓縮的數據輸出到屏幕上,可通過數據流重定向來處理;
-d: 解壓縮的參數;
-k: 保留原始文件,而不是刪除原始文件;
-l: 列出壓縮文件的相關信息;
-t: 測試壓縮文件的完整性,看看有沒有錯誤;
-z: 壓縮的參數(默認值,可以不加);
-n: n為數字的意思,代表壓縮等級,-1最快,但壓縮比最差,-9最慢,但是壓縮比最好,默認是-6
示例:
xz -v 待壓縮的文件名
xz -l 壓縮後的文件名
xz -d 壓縮後的文件名
xz -k 待壓縮的文件名
打包命令
前面談到的命令大多僅能針對單一文件來進行壓縮,雖然gzip、bzip2、xz也能夠針對目錄來進行壓縮,不過,這幾個命令對目錄的壓縮指的是將目錄內的所有文件【分別】進行壓縮的操作。而不像在Windows的系統,可以使用類似WinRAR這一類的壓縮軟件來將好多數據包成一個文件的樣式。
這種將多個文件或目錄包成一個大文件的命令功能,我們可以稱它是一種打包命令,那Linux有沒有這種打包命令?有,那就是大名鼎鼎的tar,tar可以將多個目錄或文件打包成一個大文件,同時還可以通過gzip、bzip2、xz的支持,將該文件同時進行壓縮。更有趣的是,由於tar的使用太廣泛了,目前Windows的WinRAR也支持.tar.gz文件名的解壓縮。
tar
tar的選項與參數特別多,我們只講幾個常用的選項,更多選項您可以自行man tar查詢。
tar [-z|-j|-J] [cv] [-f 待建立的新文件名] filename... <== 打包與壓縮。
tar [-z|-j|-J] [cv] [-f 既有的tar文件名] <== 查看文件名
tar [-z|-j|-J] [xv] [-f 既有的tar文件名] <== 解壓縮
選項與參數:
-c: 建立打包文件,可搭配-v來查看過程中被打包的文件名(filename);
-t: 查看打包文件的內容含有那些文件名,重點在查看【文件名】;
-x: 解包或解壓縮功能,可以搭配-C(大寫)在特定目錄解壓,特別留意的是,-c、-t、-x不可同時出現在一串命令行中;
-z: 通過gzip的支持進行壓縮/解壓縮: 此時文件名最好為*.tar.gz;
-j: 通過bzip2的支持進行壓縮/解壓縮:此時文件名最好為*.tar.bz2;
-J: 通過xz的支持進行壓縮/解壓縮: 此時文件名最好為 *.tar.xz,特別留意,-z、-j、-J不可以同時出現在一串命令行中;
-v: 在壓縮/解壓縮的過程中,將正在處理的文件名顯示出來;
-f filename: -f後面要立刻接要被處理的文件名,建議-f單獨寫一個選項(比較不會忘記)。
-C 目錄: 這個選項用在解壓縮,若要在特定目錄解壓縮,可以使用這個選項
-p(小寫): 保留備份數據的原本權限與屬性,常用於備份(-c)重要的配置文件;
-P(大寫): 保留絕對路徑,亦即允許備份數據中含有根目錄存在之意
其實最簡單的使用tar就只要記住下面的命令即可:
- 壓縮: tar -zcv -f filename.tar.gz 要被壓縮的文件或目錄名稱;
- 查詢: tar -ztv -f filename.tar.gz
- 解壓縮: tar -zxv -f filename.tar.gz -C 欲解壓縮的目錄
示例:
tar -zcvf 文件名.tar.gz 文件名(目錄)
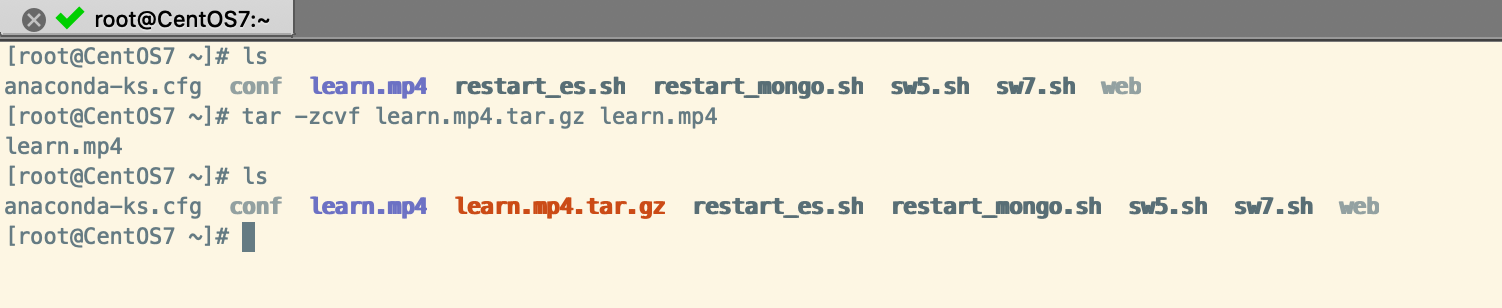
tar -ztvf 文件名.tar.gz

tar -zxvf 文件名.tar.gz

源代碼與Tarball
本文主要是為了讓你了解如何將開發源代碼的程序設計、加入庫的原理、通過編譯而成為可以執行的二進制程序,最後該執行文件可被我們使用的一連串過程。
開放源代碼:就是程序代碼,寫給人類看的程序語言,但機器並不認識,所以無法執行;編譯器:將程序轉譯成為機器看得懂的語言,就類似翻譯者的角色;可執行文件:經過編譯器變成的二進制程序,機器看得懂所以可以執行。
什麼是make與configure
事實上,使用類似 gcc的編譯器來進行編譯的過程並不簡單,因為一個軟件並不會僅有一個程序文件,而是有一堆程序代碼文件。所以除了每個主程序與子程序均需要寫上一條編譯過程的命令外,還需要寫上最終的鏈接程序。程序代碼短的時候還好,如果是類似WWW服務器軟件(例如Apache),或是類似內核的源代碼,動輒數百MB的數據量,編譯命令會寫到瘋掉,這個時候,我們就可以使用make這個命令的相關功能來進行編譯過程的簡化。
當執行make時,make會在當前的目錄查找Makefile(or makefile)這個文本文件,而Makefile裏面則記錄了源代碼如何編譯的詳細信息。make會自動地判別源代碼是否經過變動了,而自動更新執行文件,是軟件工程師相當好用的一個輔助工具。
什麼是Tarball的軟件
所謂的Tarball文件,其實就是將軟件的所有源代碼文件先以tar打包,然後再以壓縮技術來壓縮,通常最常見的就是以gzip來壓縮。因為利用了tar與gzip的功能,所以Tarball文件一般的擴展名就會寫成*.tar.gz或是簡寫為*.tgz,不過,近來由於bzip2與xz的壓縮率較佳,所以Tarball漸漸地以bzip2及xz的壓縮技術來替換gzip,因此文件名也會變成*.tar.bz2、*.tar.xz之類的。所以說Tarball是一個軟件包,你將它解壓縮之後,裏面的文件通常就會有:
- 源代碼文件;
- 檢測程序文件(可能是configure或config等文件);
- 本軟件的簡易說明與安裝說明(INSTALL或README)。
其中最重要的是那個 INSTALL 或是 README 這兩個文件,通常你只要能夠參考這兩個文件,Tarball軟件的安裝是很簡單的。
Tarball安裝的基本步驟
以Tarball方式發佈的軟件是需要重新編譯可執行的二進制程序。而Tarball是以tar這個命令來打包與壓縮的文件,所以,當然就需要先將Tarball解壓縮,然後到源代碼所在的目錄下進行makefile的建立,再以make來進行編譯與安裝的操作。所以整個安裝的基礎操作大多是這樣的:
- 獲取原始文件:將tarball文件在/usr/local/src目錄下解壓縮;
- 獲取步驟流程:進入新建立的目錄下面,去查看INSTALL與README等相關文件內容(很重要的步驟);
- 依賴屬性軟件安裝:根據INSTALL/README的內容查看並安裝好一些依賴的軟件(非必要);
- 建立makefile:以自動檢測程序(configure或config)檢測操作環境,並建立Makefile這個文件;
- 編譯:用make這個程序,並使用該目錄下的Makefile作為它的參數配置文件,來進行make(編譯或其它)的操作;
- 安裝:以make這個程序,並以Makefile這個參數配置文件,根據install這個目錄(target)的指定來安裝到正確的路徑。
注意到上面的第二個步驟,通常每個軟件在發佈的時候,都會附上名為INSTALL或是README的說明文件,這些說明文件請【確實詳細地】閱讀過一遍,通常這些文件會記錄這個軟件的安裝要求、軟件的工作項目與軟件的安裝參數設置及技巧等,只要仔細讀完這些文件,基本上,要安裝好Tarball的文件,都不會有什麼大問題。
至於makefile在製作出來之後,裏面會有相當多的目標(target),最常見的就是install與clean,通常【make clean】代表着將目標文件清除,【make】則是將源代碼進行進行編譯而已。注意,編譯完成的可執行文件與相關的配置文件還在源代碼所在的目錄當中。因此,最後要進行【make install】來將編譯完成的所有東西都安裝到正確的路徑中,這樣就可以使用該軟件。
ok,我們下面大概提一下大部分的Tarball軟件安裝的命令執行方式:
- ./configure
這個步驟就是建立Makefile這個文件。通常程序開發者會寫一個腳本來檢查你的Linux系統、相關的軟件屬性等,這個步驟相當的重要,因為未來你的安裝信息都是在這一步驟內完成的。另外,這個步驟的相關信息應該要參考一下該目錄下的README或INSTALL相關的文件。 - make clean
make會讀取Makefile中關於clean的工作。這個步驟不一定會有,但是希望執行一下,因為它可以移除目標文件。因為誰也不確定源代碼裏面到底有沒有包含上次編譯過的目標文件(*.o)存在,所以當然還是清楚一下比較妥當,至少等一下新編譯出來的執行文件我們可以確定是自己的機器所編譯完成的嘛! - make
make會根據Makefile當中的默認設置進行編譯的操作。編譯的操作主要是使用gcc來將源代碼編譯成為可以被執行的目標文件,但是這些目標文件通常還需要鏈接一些函數庫之類後,才能產生一個完整的執行文件。使用make就是要將源代碼編譯成為可以被執行的文件,而這個可執行文件會放置在目前所在的目錄之下,尚未被安裝到預定安裝的目錄中。 - make install
通常這就是最後的安裝步驟了,make會根據Makefile這個文件裏面關於install的選項,將上一個步驟所編譯完成的內容安裝到預定的目錄中,從而完成安裝。
請注意,上面的步驟是一步一步來進行的,而其中只要一個步驟無法成功,那麼後續的步驟就完全沒有辦法進行,因此,要確定每個步驟都是成功的才可以。舉個例子來說,萬一今天你在./configure就不成功了,那麼就表示Makefile無法被建立起來,要知道,後面的步驟都是根據Makefile來進行的,既然無法建立Makefile,後的步驟當然無法成功。
另外,如果在make無法成功的話,那就表示源文件無法被編譯成可執行文件,那麼make install主要是將編譯完成的文件放置到文件系統中,既然都沒有可用的執行文件了,怎麼進行安裝?所以,要每一個步驟都正確無誤才能往下繼續做。此外,如果安裝成功,並且是安裝在獨立的一個目錄中,例如在/usr/local/packages這個目錄中,那麼你就必須手動將這個軟件的man page寫入到/etc/man_db.conf中。
Tarball安裝建議
為什麼Tarball要在/usr/local/src裏面解壓縮?,基本上,在默認的情況下,原本的Linux發行版發佈安裝的軟件大多是在/usr裏面,而用戶自行安裝的軟件則建議放置在/usr/local裏面,這是考慮到管理用戶所安裝軟件的便利性。
為什麼?我們知道幾乎每個軟件都會提供聯機幫助的服務,那就是info與man的功能。在默認的情況下,man會去查找/usr/local/man裏面的說明文件,因此,如果我們將軟件安裝在/usr/local下面的話,那麼自然安裝完成之後,該軟件的說明文件就可以被找到了。所以,通常我們會建議大家將自己安裝的軟件放置在/usr/local下,至於源代碼(Tarball)則建議防止在/usr/local/src(src為source的縮寫)下面。
但是,如果將軟件直接安裝在/usr/local下,由於/usr/local原本就默認就有/etc、/bin、/lib、/man,所以安裝其它軟件產生的一些文件也會在上述幾個目錄裏面,因此,如果你都安裝在這個目錄下的話,那麼未來再想要升級或刪除的時候,就會比較難以查找文件的來源。所以建議如果你的軟件名是software,建議安裝在/usr/local/softwsare目錄下,這樣單一軟件的文件都在同一個目錄下,那麼刪除該軟件就簡單的多了,只要將該目錄刪除即可視為該軟件已經被刪除。
由於Tarball在升級與安裝上面具有這些特色,亦即Tarball在反安裝上面具有比較高的難度(如果你沒有好好規劃的話),所以,為了方便Tarball的管理,通常鳥哥會這樣建議用戶:
- 最好將Tarball的原始數據解壓到/usr/local/src當中;
- 安裝時,最好安裝到/usr/local這個默認路徑下;
- 考慮到未來的反安裝步驟,最好可以將每個軟件單獨安裝在/usr/local下面;
- 為安裝到單獨目錄的軟件的man page加入man path查找:
如果你安裝的軟件放置到/usr/local/software/,那麼在man page查找的設置中,可能就要在/etc/man_db.conf內的40~50行左右處,寫入如下的一行:
MANPATH_MAP /usr/local/software/bin /usr/local/software/man
這樣才可以使用man來查詢該軟件的在線文件。

