全網最牛X的!!! MySQL兩階段提交串講
一、吹個牛
面試官的一句:「了解MySQL的兩階段提交嗎?」 不知道問涼了多少人!
這篇文章白日夢就和大家分享什麼是MySQL的兩階提交到底是怎麼回事!不管你原來曉不曉得兩階段提交,相信我!這篇文章中你一定能get到新的知識!
在說兩階段提交之前,白日夢用了大量的篇幅再講undo-log、redo-log、binlog。
先了解它們,才能更好的理解什麼是兩階段提交,如果你如果還沒有看,推薦你去翻一翻前面的文章。
二、事務及它的特性
在說兩階段提交事物之前,我們先來說說事務。
一般當我們的功能函數中有批量的增刪改時,我們會添加一個事物包裹這一系列的操作,要麼這一組操作全部執行成功,只要有一條SQL執行失敗了我們就全部回滾。相信你一定聽說過這個比較經典的轉賬的Case。有一定工作經驗的同學都知道,這麼做其實是保護我們的數據庫中不出現臟數據。整體數據會變的可控。
對MySQL來說你可以通過下面的命令顯示的開啟、提交、回滾事務
# 開啟事務
begin;
# 或者下面這條命令
start transaction;
# 提交
commit;
# 回滾
rollback;
但是日常開發中大家普遍使用編程語言操作數據庫。比如Java、Golang… 在使用這種具體編程語言持久層的框架時,它們一般都支持事務操作,比如:在Spring中你可以對一個方法添加註解@Transctional顯示的開啟事務。Golang的beego中也提供了讓你可以顯示的開啟事務的函數。
有一點不太好的地方是:大家在享受這種編程框架帶來的便利的同時,它也屏蔽了你對MySQL事務認知。讓人們懶得去往細了看事務
你可以往看我下面這個很簡單的Case。
我有一張數據表
CREATE TABLE `test_backup` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
然後我往這個表中insert幾條數據
mysql> insert into test_backup values(1,'tom');
mysql> insert into test_backup values(2,'jerry');
mysql> insert into test_backup values(1,'herry');
再去查看binlog。
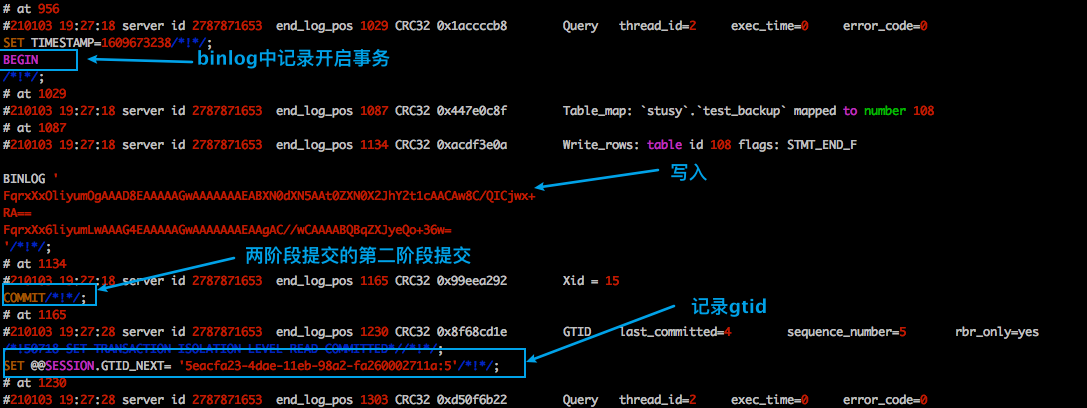
你會不會詫異?我上面明明沒有顯示的添加begin、commit命令,但是MySQL實際執行我的SQL時,竟然為我添加上了!
原因很簡單:跟大家分享一個參數如下:

一般大家的線上庫都會將這個參數置為ON,你的SQL會自動的開啟一個事物,並且MySQL會自動的幫你把它提交。
也就是說: 當這個參數為ON時,你使用的DAO持久層框架發送給數據庫的SQL其實都會被放在一個事物中執行,然後這個事物被自動提交,而我們對這個過程是無感知的。 具體一點,比如你使用某框架的@Transctional註解,或者在golang中可以像下面的方式獲得一個事物:
db := mysql.Client
ops := &sql.TxOptions{
Isolation: 0,
ReadOnly: false,
}
tx, err := db.BeginTx(ctx, ops)
// todo with tx
然後你所有的操作都放在這個事物中執行。
這時你使用的持久層框架肯定會向MySQL發送一條命令:`begin;`或者是`start transcation;`來保證你這一組SQL中執行一條SQL後,開啟的事物不會被MySQL自動幫你提交了。
其實還是推薦將這個參數設置成ON的,當然你也可以像下面這樣將它關閉
mysql> set autocommit = 0;
但是關閉它之後,MySQL不會幫你自動提交事物,全靠研發同學自己來維護就容易會出現長事物,在內存中產生一個極其長的undo log鏈條。壞處多多。
todo 關於長事物,你可以看白日夢的這篇筆記:
三、簡單看下兩階段提交的流程
了解了什麼是事物,再來看下什麼是兩階段提交。其實所謂的兩階段就是把一個事物分成兩個階段來提交。就像下圖這樣。
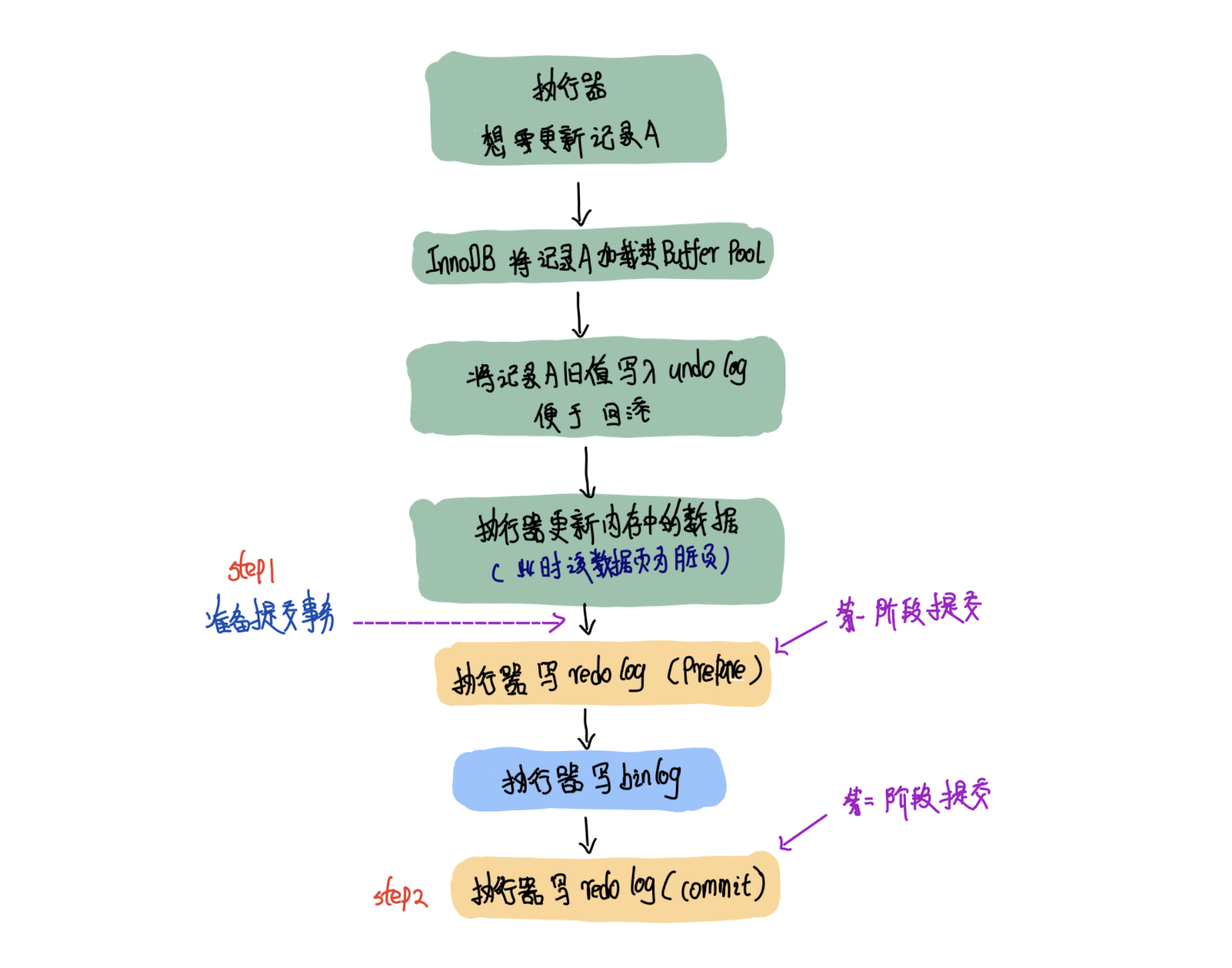
上圖為兩階段提交的時序圖。
你可以粗略的觀察一下上圖,MySQL想要準備事務的時候會先寫redolog、binlog分成兩個階段。
兩階段提交的第一階段 (prepare階段):寫rodo-log 並將其標記為prepare狀態。
緊接着寫binlog
兩階段提交的第二階段(commit階段):寫bin-log 並將其標記為commit狀態。
不了解這些日誌是什麼有啥用也沒關係,你可以先去看我之前的系列文章。
四、兩階段寫日誌用意?
你有沒有想過這樣一件事,binlog默認都是不開啟的狀態!
也就是說,如果你根本不需要binlog帶給你的特性(比如數據備份恢復、搭建MySQL主從集群),那你根本就用不着讓MySQL寫binlog,也用不着什麼兩階段提交。
只用一個redolog就夠了。無論你的數據庫如何crash,redolog中記錄的內容總能讓你MySQL內存中的數據恢復成crash之前的狀態。
所以說,兩階段提交的主要用意是:為了保證redolog和binlog數據的安全一致性。只有在這兩個日誌文件邏輯上高度一致了。你才能放心的使用redolog幫你將數據庫中的狀態恢復成crash之前的狀態,使用binlog實現數據備份、恢復、以及主從複製。而兩階段提交的機制可以保證這兩個日誌文件的邏輯是高度一致的。沒有錯誤、沒有衝突。
當然,兩階段提交能做到足夠的安全還需要你合理的設置redolog和binlog的fsync的時機,而這塊知識點所涉及到的參數前幾篇文章已經說過。如果不記得,可以去看下。
五、加餐:sync_binlog = 1 問題
如果你看懂了我下面說的這些話,能幫你更好的理解兩階段提交哦!純乾貨!
白日夢在前面的分享binlog的文章中有跟大家提到過一個參數sync_binlog=1。這個參數控制binlog的落盤時機,並且白日夢也知道你們公司線上數據庫的該參數一定被設置成了1。
我在那篇binlog文章之前,就計劃好寫這篇文章了。白日夢的MySQL在動筆之前已經列好了大綱,從簡單到複雜,從0到1開始更新,歡迎小夥伴們關注我,持續更新中~
Notice!!! 這個參數為1時,表示當事物提交時會將binlog落盤。
現在你用15s中的時間,思考一下,藍色句子中說的事物提交時會將binlog落盤,這個提交時,是下圖中的step1時刻呢?還是step2時刻呢?
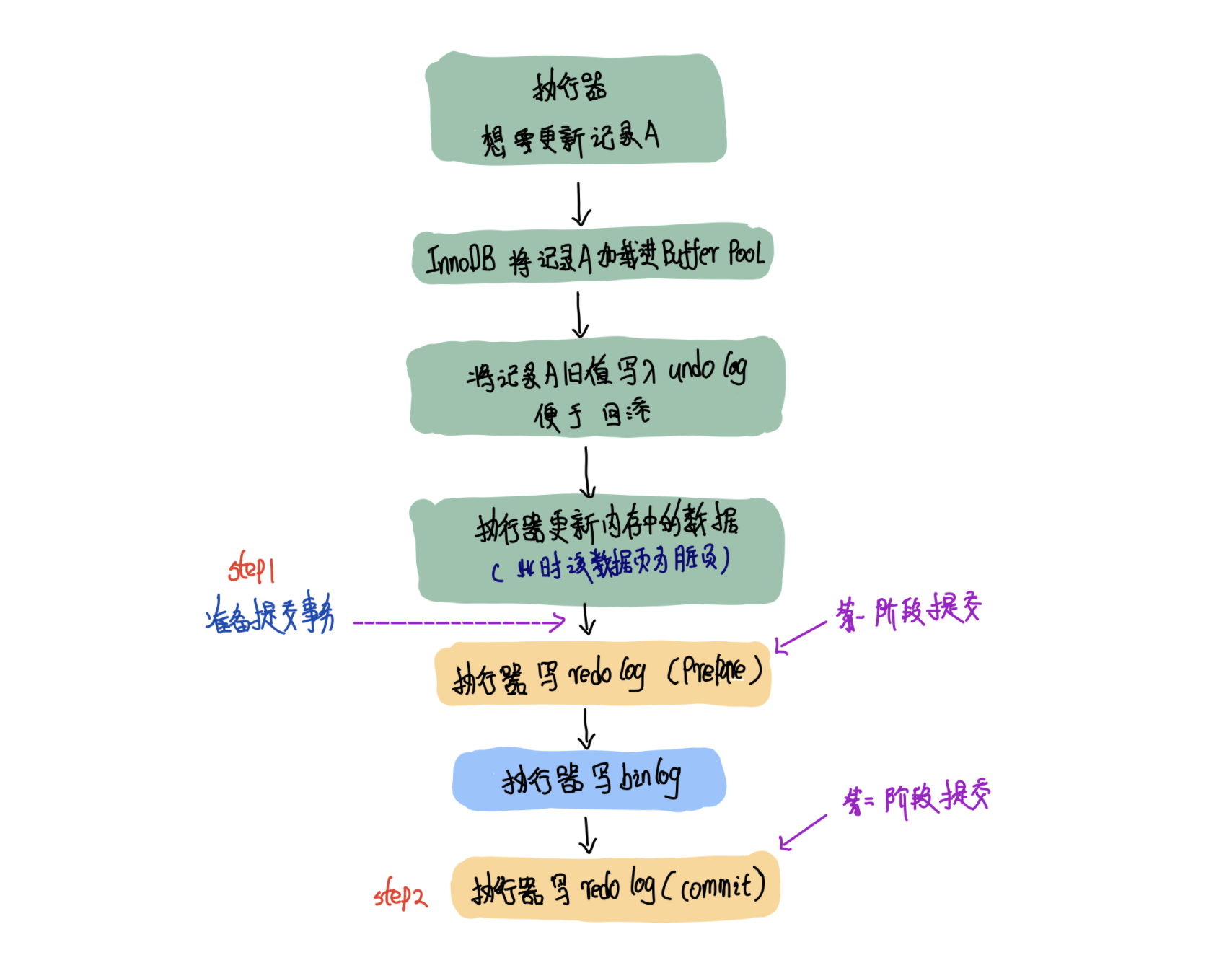
答案是:step1時刻!
知道這個知識點很重要,下面我來描述這樣一個場景。
假如要執行一條update語句,那你肯定知道,先寫redolog(便於後續對update事務的回滾)。然後你的update邏輯將Buffer Pool中的緩存頁修改成了臟頁。
當你準備提交事物時(也就是step1階段),會寫redolog,並將其標記為prepare階段。然後再寫binlog,並將binlog落盤。
然後發生了意外,MySQL宕機了。
那我問你,當你重啟MySQL後,update對BufferPool中做出的修改是會被回滾還是會被提交呢?
答案是:會根據redolog將修改後的recovery出來,然後提交。
那為什麼會這樣做呢?
其實總的來說,不論mysql什麼時刻crash,最終是commit還是rollback完全取決於MySQL能不能判斷出binlog和redolog在邏輯上是否達成了一致。只要邏輯上達成了一致就可以commit,否則只能rollback。
比如還是上面描述的場景,binlog已經寫了,但是MySQL最終選擇了回滾。那代表你的binlog比BufferPool(或者Disk)中的真實數據多出一條更新,日後你用這份binlog做數據恢復,是不是結果一定是錯誤的?
六、如何判斷binlog和redolog是否達成了一致
這個知識點可是純乾貨!
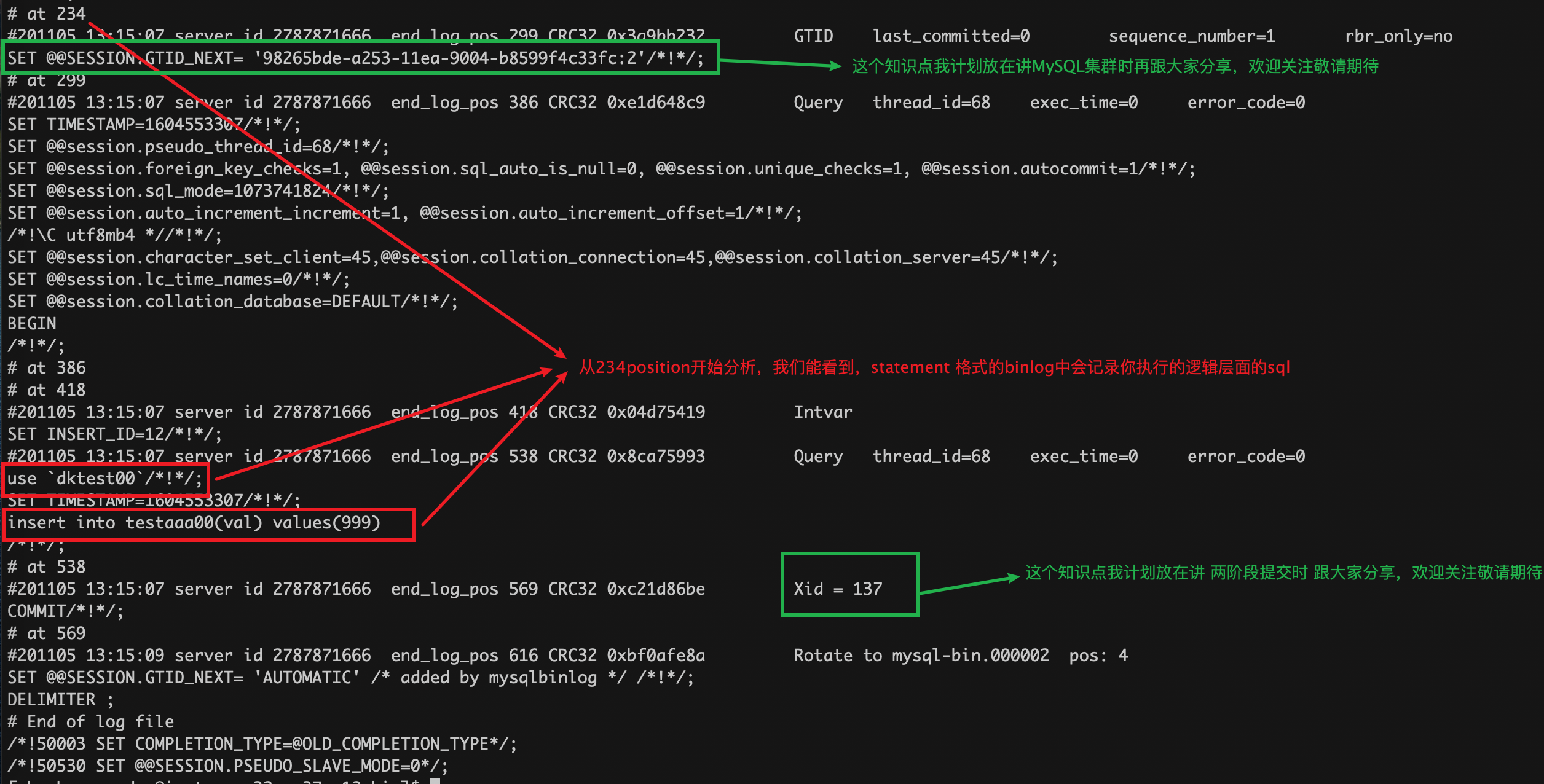
當MySQL寫完redolog並將它標記為prepare狀態時,並且會在redolog中記錄一個XID,它全局唯一的標識着這個事務。而當你設置`sync_binlog=1`時,做完了上面第一階段寫redolog後,mysql就會對應binlog並且會直接將其刷新到磁盤中。
下圖就是磁盤上的row格式的binlog記錄。binlog結束的位置上也有一個XID。
只要這個XID和redolog中記錄的XID是一致的,MySQL就會認為binlog和redolog邏輯上一致。就上面的場景來說就會commit,而如果僅僅是rodolog中記錄了XID,binlog中沒有,MySQL就會RollBack
七、兩階段提交設計的初衷 – 分佈式事務
其實兩階段提交更多的被使用在分佈式事務的場景。
我用大白話描述一個這樣的場景,大家自行腦補一下:
MySQL單機本來是支持事務的,但是這裡所謂的分佈式事務實際上指的是跨數據庫、跨集群的事務。比如說你公司的業務太火爆了,每天都產生大量的數據,這些數據不僅單表存不下,甚至單庫都存不下了(已經達到了服務器硬件存儲的瓶頸)
那你怎麼辦?是不是只能將單庫拆分成多庫?
那你拆分成多庫就會面臨這樣一個新的問題。假設Tom給Jerry轉賬,但是由於你拆分了數據庫,原本在同庫同表上的Tom和Jerry的信息,被你拆分進A庫a表和B庫b表。那你再發起轉賬邏輯時,萬一失敗了。如何回滾保證數據的安全?這就是分佈式事務的要解決的問題。
通常各大公司都有自己的支持分佈式事務中間件,中間件的作用本質上就是處理好各個數據庫節點之間兩階段提交的問題。
簡單來說:就是中間件要協調各個數據節點。
第一階段:中間件告訴各數據庫節點,讓它們開啟XA事務,然後判斷所有數據庫節點是否已經處於prepare狀態
第二階段:中間件判斷事務提交還是回滾的階段。如果所有節點都prepare那就統一提交。但凡出現一個失敗的節點,統一回滾。
這裡只是稍微提及一下:兩階段提交和分佈式事務的淵源。
白日夢後續計劃還會有文章中進一步跟大家詳細的分享分佈式事務話題。
八、再看MySQL兩階段寫日誌
那我們再將思路拉回到MySQL兩階段寫日誌的話題。
其實說到這裡,你大概也能直接想到,其實上一篇文章中的兩階段提交,表面上其實就是兩階段寫入日誌。
通過我前面的描述,你也一定知道了兩份日誌文件邏輯對齊的標記是有一份相同的XID。
就是這種兩階段的機制保證了兩個日誌(在分佈式事務中就是多個數據節點)在邏輯上能達到一致的效果。
九、留一個彩蛋
如果你仔細想一下,上面第三部分在分享 sync_binlog=1 加餐時,我所描述的示例場景其實是適用於單機MySQL的簡單場景。
其實這個場景還能再複雜一些!
串聯MySQL集群、將同步、半同步、異步的主從複製關係以及這裡的兩階段提交、日誌的落盤時機、幽靈事務!結合成一個場景效果會更好。
但是我將它放在《為研發同學定製的面試指南》排期的後半部分也就是MySQL集群部分。讓我們從易到難過度過去! 歡迎關注白日夢。
十、推薦閱讀(公眾號首發,歡迎關注白日夢)
- MySQL的修仙之路,圖文談談如何學MySQL、如何進階!(已發佈)
- 面前突擊!33道數據庫高頻面試題,你值得擁有!(已發佈)
- 大家常說的基數是什麼?(已發佈)
- 講講什麼是慢查!如何監控?如何排查?(已發佈)
- 對NotNull字段插入Null值有啥現象?(已發佈)
- 能談談 date、datetime、time、timestamp、year的區別嗎?(已發佈)
- 了解數據庫的查詢緩存和BufferPool嗎?談談看!(已發佈)
- 你知道數據庫緩衝池中的LRU-List嗎?(已發佈)
- 談談數據庫緩衝池中的Free-List?(已發佈)
- 談談數據庫緩衝池中的Flush-List?(已發佈)
- 了解臟頁刷回磁盤的時機嗎?(已發佈)
- 用十一張圖講清楚,當你CRUD時BufferPool中發生了什麼!以及BufferPool的優化!(已發佈)
- 聽說過表空間沒?什麼是表空間?什麼是數據表?(已發佈)
- 談談MySQL的:數據區、數據段、數據頁、數據頁究竟長什麼樣?了解數據頁分裂嗎?談談看!(已發佈)
- 談談MySQL的行記錄是什麼?長啥樣?(已發佈)
- 了解MySQL的行溢出機制嗎?(已發佈)
- 說說fsync這個系統調用吧! (已發佈)
- 簡述undo log、truncate、以及undo log如何幫你回滾事物! (已發佈)
- 我勸!這位年輕人不講MVCC,耗子尾汁! (已發佈)
- MySQL的崩潰恢復到底是怎麼回事? (已發佈)
- MySQL的binlog有啥用?誰寫的?在哪裡?怎麼配置 (已發佈)
- MySQL的bin log的寫入機制 (已發佈)
- 刪庫後!除了跑路還能幹什麼?(已發佈)

