索引原理和優勢
- 2020 年 12 月 31 日
- 筆記
1.定義:
在關係數據庫中,索引是一種單獨的、物理的對數據庫表中一列或多列的值進行排序的一種存儲結構,它是某個表中一列或若干列值的集合和相應的指向表中物理標識這些值的數據頁的邏輯指針清單。索引的作用相當於圖書的目錄,可以根據目錄中的頁碼快速找到所需的內容。
2.原理:
不同的數據庫,不同的存儲引擎其索引的原理也不盡相同。這裡只了解下MySQL的索引原理。不過,在了解索引之前我們需要先了解什麼是磁盤IO,局部預讀,二叉樹。
磁盤IO:很簡單,我們知道數據庫表裡的數據最終會持久化到磁盤裏面,當我們讀取數據的時候就需要從磁盤裏面讀取,每一次讀取就稱為一次磁盤IO。
局部預讀:也稱為局部預讀原理,指的是當我們讀取一個數據的時候,該數據所在位置的相鄰數據也很快會被訪問到。
基於這兩個,我們就能了解下面的這句話;每一次讀取數據都會將其相鄰的數據也讀取出來,存放到數據庫內存緩存中,這個數據塊稱為「頁」,也就是說,每一次磁盤IO讀取到一頁數據,頁的大小和操作系統有關,一般是4K或8K或16K。這也是我們經常聽到的,頁是其磁盤管理的最小單位。
二分法查找二叉樹:二叉樹分為很多種,平衡二叉樹,完全二叉樹等,這裡的二叉樹是基於二分法查找的,二分法簡單來講就是一串數據,提起中間的數據作為根節點將數據分為左右兩邊,左邊的數據再取中間的為節點提起來將其分為左右兩邊,右邊一樣,以此類推形成一棵倒着的樹,是為二叉樹。但這種樹要有一個要求就是數據必須是有序的,這也是我們一般要求聚集索引最好選用自增字段的原因。如圖;
1)MySQL:
MySQL存儲引擎分為兩種:MyISAM和InnoDB。
InnoDB:InnoDB存儲引擎一般分為以下幾種索引:B+樹索引,全文索引和哈希索引。其中哈希索引是自適應的,人為無法干預。B+樹索引就是我們一般通常所說的索引,B+樹索引的構造類似於二叉樹,注意,是類似,因為B+樹是從平衡二叉樹演化而來的,但B+樹不是一個二叉樹。這裡可能有人就不太明白了,要想明白這句話,首先得了解二分法和二叉樹。我們插入一段二叉樹得的解釋。
二分查找法:也稱折半查找法,基本方法就是,將一組數據有序排列,採用跳躍方式查找到這組數據中心點的位置,如果要找的數據小於中心點位置的數據,就在中心點左邊(也就是小於中心點數據的一邊)再次跳躍到這部分數據的中心位置比較,以此類推直到找到所要找的數據。這種方法的思路大概就是通過折半不斷縮小數據範圍。例如:
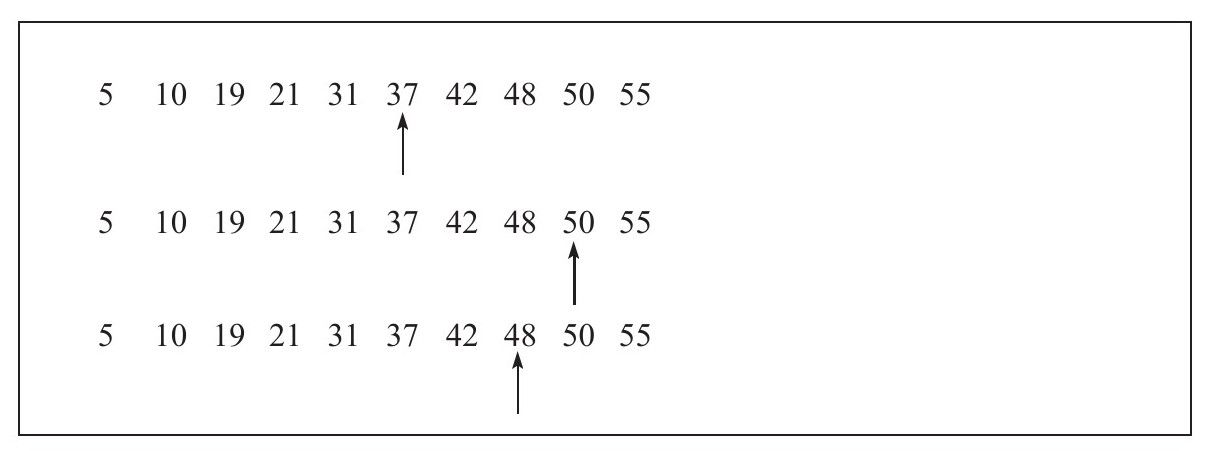
如有5、10、19、21、31、37、42、48、50、52這10個數,現要從這10個數中查找48這條記錄,其查找過程如圖所示。先找到這組數據中心位置37,判斷要找的48大於37就到37的右邊繼續二分定位到50,再判斷48小於50,直到找到48.
二叉樹:
B+樹是通過二叉查找樹,再由平衡二叉樹,B樹演化而來。二叉查找樹是一種經典的數據結構,如圖:
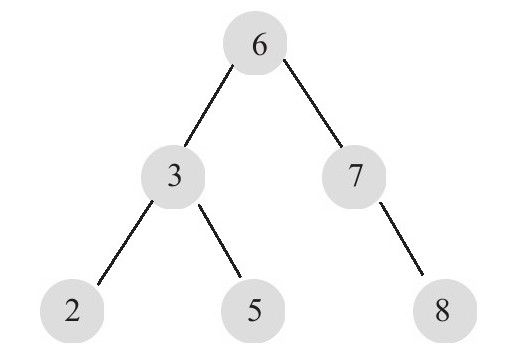
圖中的數字代表每個結點的鍵值,在二叉查找樹中,左子樹的鍵值總是小於根鍵值,右子樹的鍵值總是大於根鍵值。
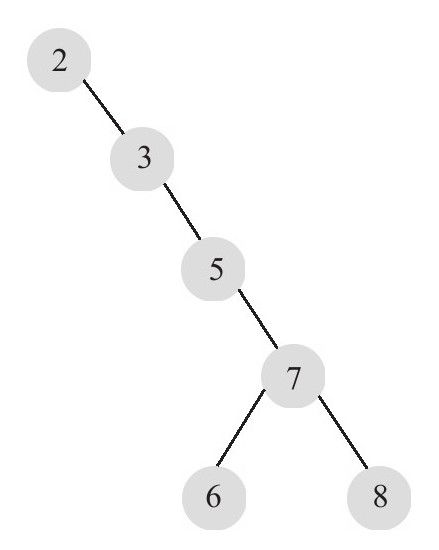
當然,二叉樹可以任意構造,不一定非要求根節點一定是中心位置的鍵值,也可以這樣如下圖,它同樣滿足二叉樹的定義,右子樹鍵值大於根鍵值。但是顯然,這樣構造的二叉樹查找的時候效率就很低了,為了最大性能的構造一棵二叉樹,平衡二叉樹(也稱AVL樹)應運而生!!
平衡二叉樹:首先滿足查找二叉樹,其次還需要滿足任何節點的兩個子樹的最大高度最大差為1,這樣一棵樹的性能是比較高的,但還不是最好的,最好性能的樹應該是最優二叉樹,但是世上哪得雙全法,最優二叉樹要求較高,需要大量的操作,因此,我們使用平衡二叉樹就足夠滿足我們了。
平衡二叉樹的查詢速度還是很快的,但是建立和維護一棵平衡二叉樹的代價也是很大的,通常需要1次或多次左旋和右旋來得到插入或更新後的樹的平衡,每一次數據的變化都意味着平衡二叉樹的變動。如圖,假如要插入一個值為9的節點,我們需要做的變動如下:

這裡通過一次左旋就可以將樹維護到平衡狀態,但是有的情況要複雜一些,比如:
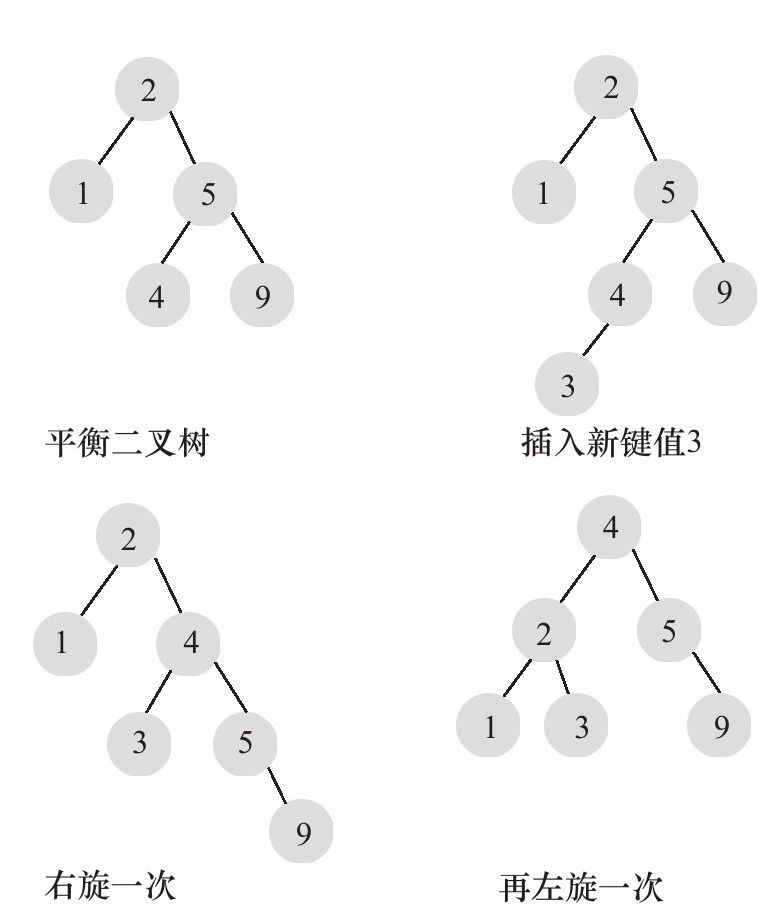
可以看到,每次數據的增刪改都會引起二叉樹的變動,因此維護一顆平衡樹是需要開銷的,不過平衡二叉樹一般用於內存結構對象中,因此維護的開銷相對較小。
最後重點來了,B+樹!!!
B+樹:B+樹是由B樹和索引順序訪問法(ISAM:MySQL最初存儲引擎MyISAM的數據結構結構)演化而來。B+樹的定義在任何一本數據結構書中都能找到,其定義十分複雜,在這裡列出來只會讓讀者感到更加困惑。這裡,我來精簡地對B+樹做個介紹:B+樹是為磁盤或其他直接存取輔助設備設計的一種平衡查找樹。在B+樹中,所有記錄節點都是按鍵值的大小順序存放在同一層的葉子節點上,由各葉子節點指針進行連接。先來看一個B+樹,其高度為2,每頁可存放4條記錄,扇出(fan out)為5,如圖:
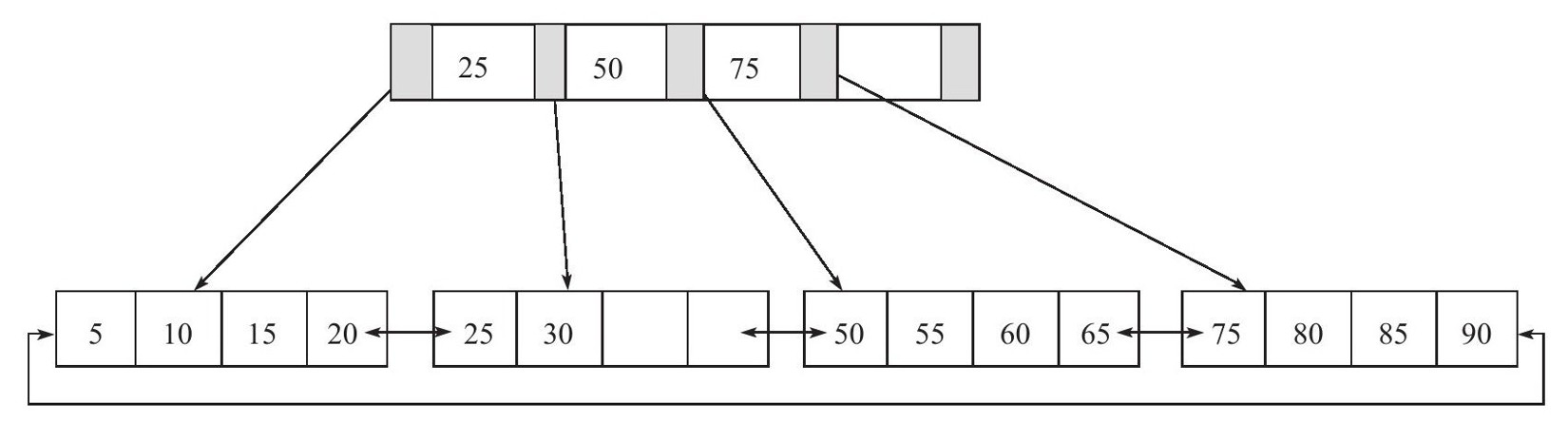
從圖可以看出,所有記錄都在葉子節點上,並且是順序存放的,如果用戶從最左邊的葉子節點開始順序遍歷,可以得到所有鍵值的順序排序:5、10、15、20、25、30、50、55、60、65、75、80、85、90。
B+樹索引:本質就是B+樹在數據庫中的實現,可分為集聚索引和非聚集索引,不管是哪種都是基於B+樹高度平衡的,葉子節點存放着所有數據,不同的是,聚索引存放的是一整行的信息。
聚集索引:在InnoDB中,存儲引擎表就是索引組織表,即表中數據按照主鍵順序存放。而聚集索引就是按照每張表的主鍵構造的一棵B+樹,同時葉子節點存放着整張表得行記錄數據。也將聚集索引的葉子節點稱為數據頁。由於實際的數據頁只能按照一棵B+樹進行排序,因此每張表只能有一個聚集索引。可以這樣理解,找到索引就找到了數據。B+樹如下圖:
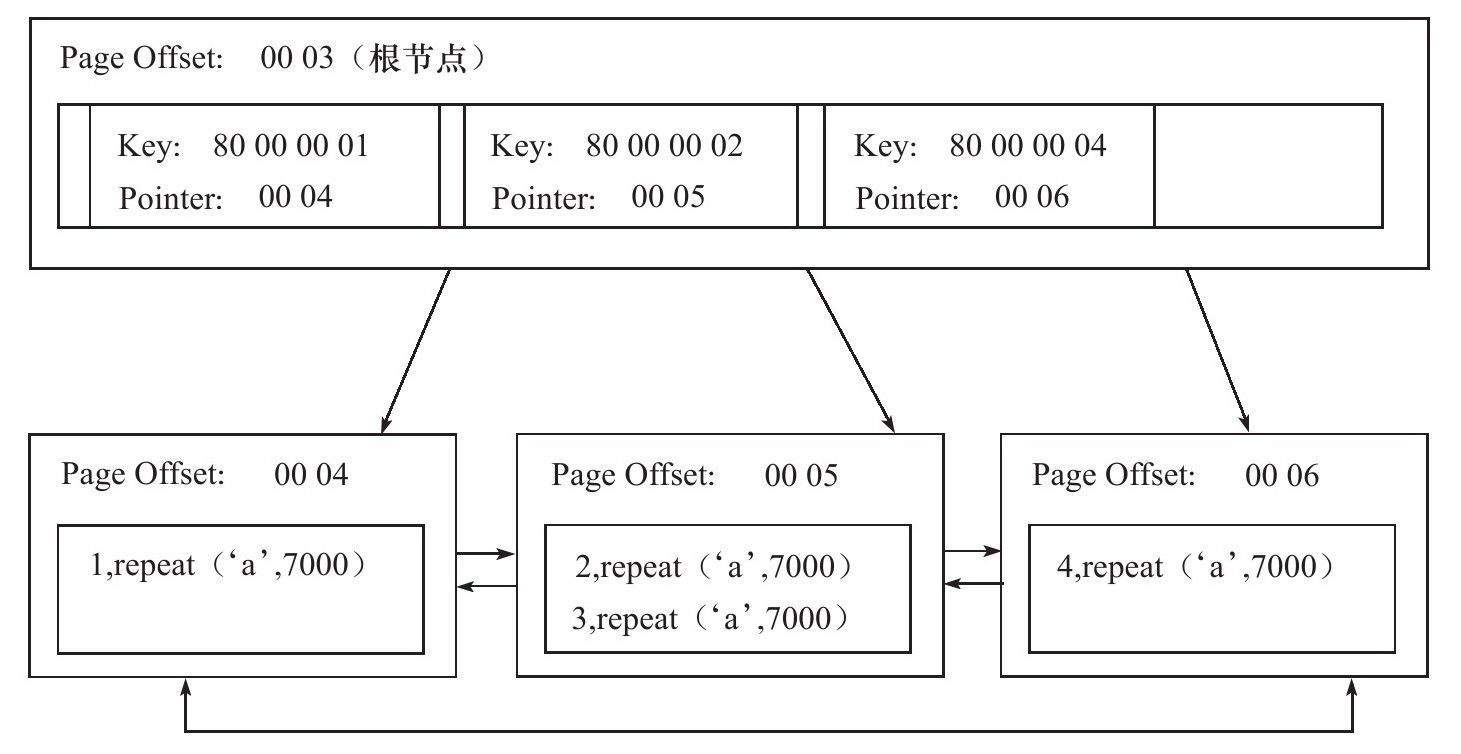
有些文檔會說聚集索引是按照順序物理地存儲數據,但這是不準確的。在《MySQL技術內幕》里有介紹到,個人也比較認可這個:如果真的按照特定的物理順序存放,那麼維護成本相當之高,對於一些非自增主鍵的更新的處理代價非常大。聚集索引是邏輯上連續的,首先,數據頁是通過雙向鏈表進行維護的,頁按照主鍵的順序排序,並且每頁得記錄也是按照雙向鏈表維護的,物理存儲上也可以不按照主鍵存儲,如果已經按照物理順序排序了那麼雙向鏈表顯得多餘了。
非聚集索引:也叫輔助索引,葉子節點並不包含行記錄的全部數據,葉子節點除了包含鍵值外,還有一個書籤,這個書籤只是告訴你哪裡可以找到你要的數據,哪裡呢?聚集索引裏面去找吧。因此,整個輔助索引查找過程是這樣的:先在輔助索引得B+樹上找到對應索引得書籤,在根據書籤信息(對應的聚集索引樹的鍵值)去聚集索引的B+樹上找到對應的葉子節點數據。
MyISAM:這是MySQL最早提供的引擎,也是B+樹。我們知道一般來講索引分為聚集索引和非聚集索引,在MyISAM中,這兩個原理差不多一樣,都是葉子節點存放地址信息,即數據所在的行列信息,再根據行列信息找到數據。不同的是非聚集索引的鍵值允許重複。
稍微提一下SQL server索引,他的索引是基於B樹的。B樹設計之初的目的很簡單就是為了減少磁盤掃描的次數,也就是減少IO操作,避免全盤掃描。沒有聚集索引的表數據會以堆的結構無序存放。
B樹和B+樹的區別在於索引節點,B樹的索引節點裏面除了鍵值和指針為還有數據,但B+樹只有鍵值和指針,他的數據再葉子節點中,並且B+樹的葉子節點是一個雙向鏈表,查找範圍非常快。那麼為什麼B+樹會比B樹好呢,除了上面提到的快速查找外,還有一個原因是頁的容量大小是固定有限的,B+樹的索引節點頁不存放數據,可以容納更多的索引值。那麼相對應的B+樹的深度就會較淺,查找更快。


