Redis基礎篇(二)高性能IO模型
我們經常聽到說Redis是單線程的,也會有疑問:為什麼單線程的Redis能那麼快?
這裡要明白一點:Redis是單線程,主要是指Redis的網絡IO和鍵值對讀寫是由一個線程來完成的,這也是Redis對外提供鍵值存儲服務的主要流程。但Redis的其他功能,比如持久化、異步刪除、集群數據同步等,都是由額外的線程執行的。
我們知道多線程能夠提升並發性能,那為什麼Redis會採用單線程,而非多線程?為什麼單線程能那麼快?
下面我們就來學習一下Redis採用單線程的原因。
為什麼採用單線程?
使用多線程,雖然可以增加系統吞吐率,或是增加系統擴展性,但同樣會產生開銷。
Redis的數據是在內存里的,是共享的,如果使用多線程就會引發共享資源的競爭,需要引入互斥鎖來解決,使得並行變串行。最終系統吞吐率並沒有隨着線程的增加而增加。
另外,多線程開發需要精細的設計,會增加系統的複雜度,降低代碼的易調試性和可維護性。為了避免這些問題,Redis採用單線程模式。
單線程Redis為什麼那麼快?
通常來說,單線程的處理能力比多線程要差很多,那Redis卻能使用單線程模型達到每秒數十萬級別的處理能力,這是為什麼呢?
一方面,Redis大多數操作是在內存上完成的,並且採用高效的數據結構,例如哈希表和跳錶。另一方面,Redis採用了多路復用機制,使其在網絡IO操作中能並發處理大量的客戶端請求,實現高吞吐率。
在學習多路復用機制前,我們要弄明白網絡操作的基於IO模型和潛在的阻塞點。
基本IO模型與阻塞點
以Get請求為例,為了處理一個Get請求:
- 需要監聽客戶端請求(bind/listen)
- 和客戶端建立連接(accept)
- 從socket中讀取請求(recv)
- 解析客戶端發送請求(parse)
- 根據請求類型讀取鍵值數據(get)
- 最後給客戶端返回結果,即向socket中寫回數據(send)。
下圖顯示了這一過程,其中,bind/listen、accept、recv、parse和send屬於網絡IO處理,而get屬性鍵值數據操作。
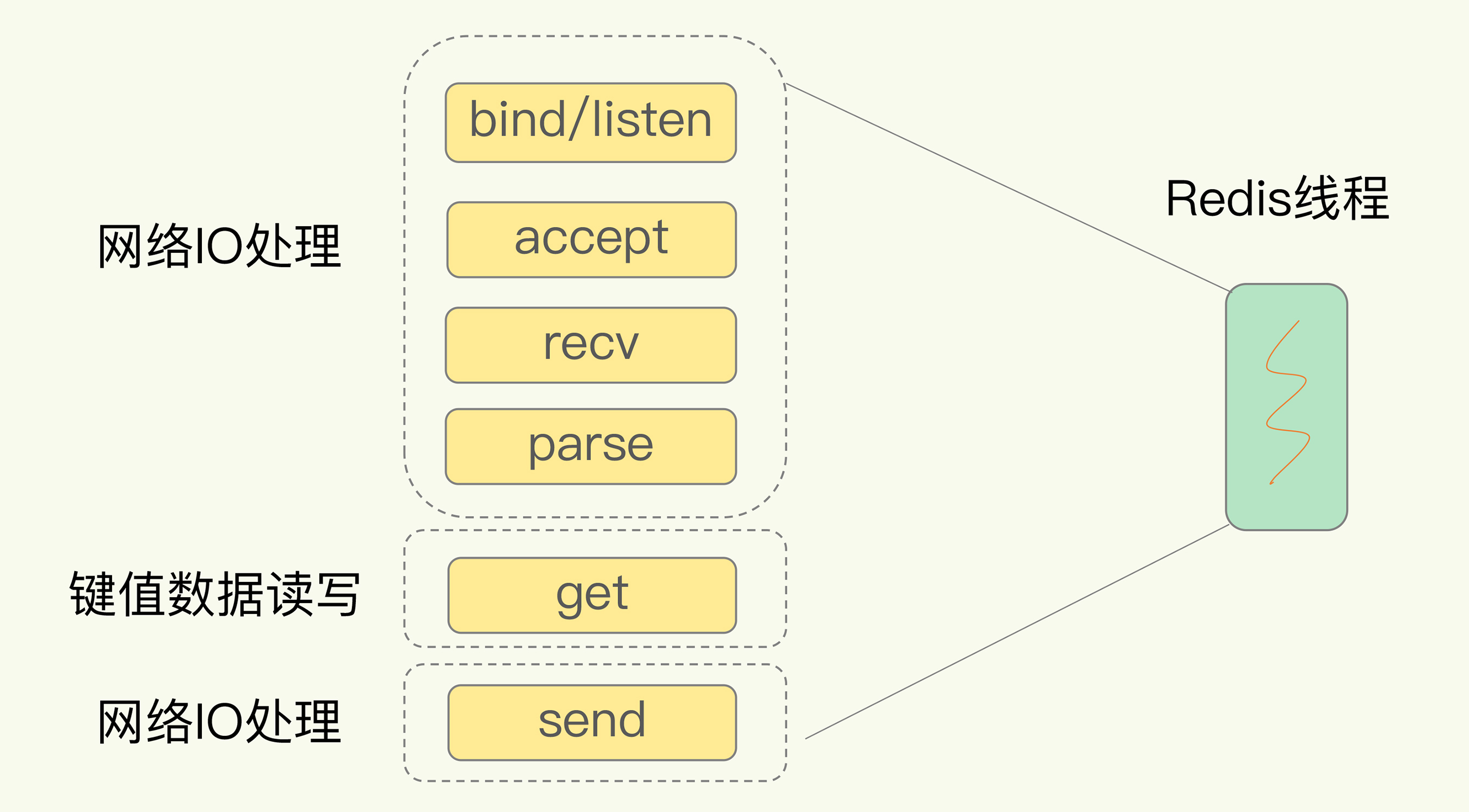
但是在這裡的網絡IO操作中,有潛在的阻塞點,分別是accept()和recv()。
- 當Redis監聽到一個客戶端有連接請求,但一直未能成功建立起連接時,會阻塞在accept()
- 當Redis通過recv()從一個客戶端讀取數據時,如果數據一直沒有到達,Redis也會一直阻塞在recv()
這就導致Redis整個線程阻塞,無法處理其他客戶端請求,效率很低。不過,幸運的是,socket網絡模型本身支持非阻塞模式。
非阻塞模式
Socket網絡模型可以設置非阻塞模式。

這樣能保證Redis線程既不會像基本IO模型中一直在阻塞點等待,也不會導致Redis無法處理實際到達的連接請求或數據。
下面就到多路復用機制登場了。
基於多路復用的高性能I/O模型
Linux的IO多路復用機制是指一個線程處理多個IO流,也就是select/epoll機制。
在Redis運行單線程下,該機制允許內核中,同時存在多個監聽套接字和已連接套接字。
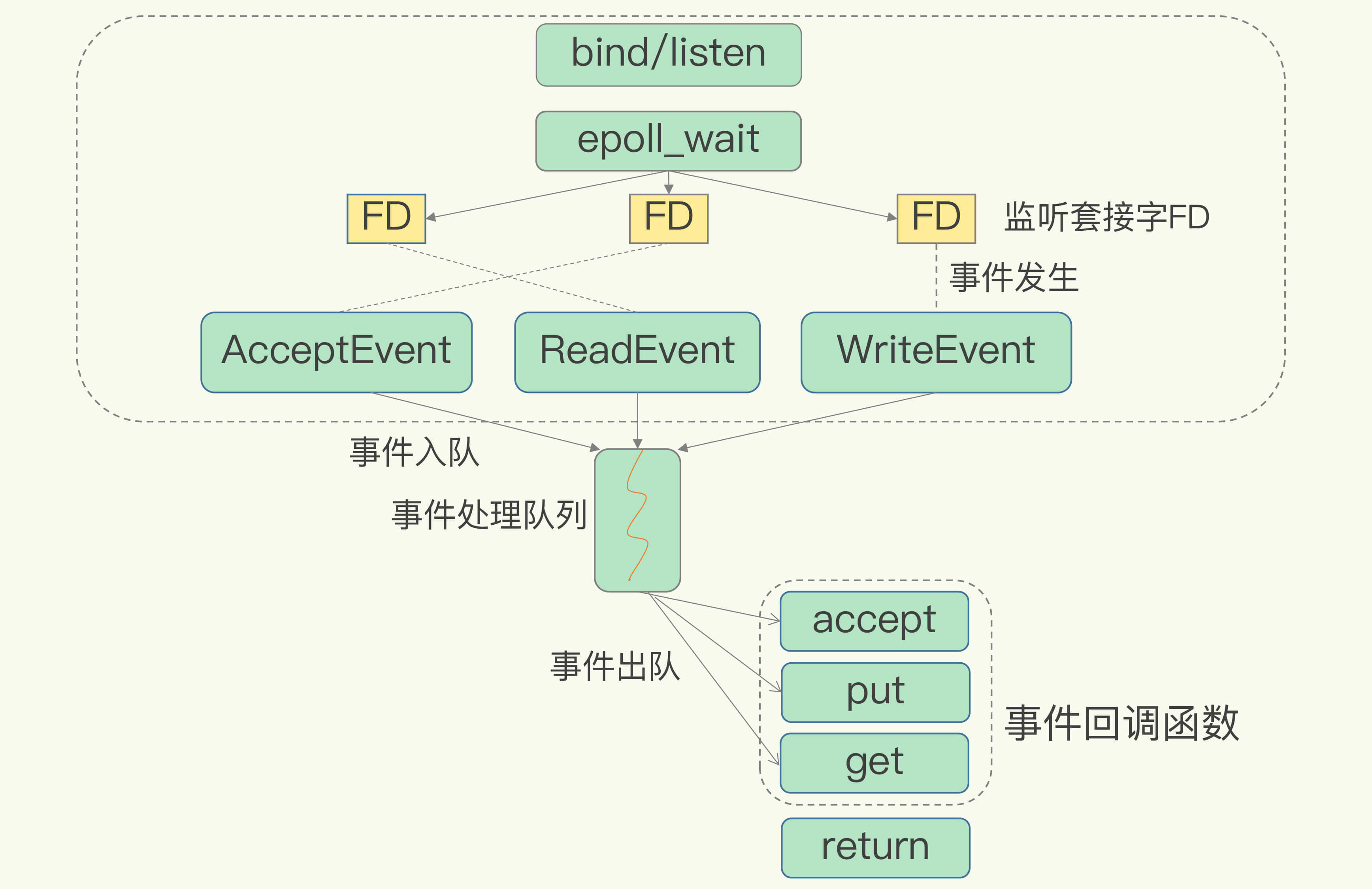
為了在請求到達時能通知到Redis線程,select/epoll提供了基於事件的回調機制,即針對不同事件的發生,調用相應的處理函數。
回調機制的工作流程:
- select/epoll一旦臨聽到FD上有請求到達,就會觸發相應的事件,並放進一個事件隊列中。
- Redis單線程對事件隊列進行處理即可,無需一直輪詢是否有請求發生,避免CPU資源浪費。
因為Redis一直在對事件隊列進行處理,所以能及時響應客戶端請求,提升Redis的響應性能。
不過,需要注意的是,在不同的操作系統上,多路復用機制也是適用的。
拓展
在「Redis基本IO模型」圖中,有哪些潛在的性能瓶頸?
Redis單線程處理IO請求性能瓶頸主要包括2個方面:
1、任意一個請求在server中一旦發生耗時,都會影響整個server的性能 也就是說後面的請求都要等前面這個耗時請求處理完成,自己才能被處理到。
耗時的操作包括:
- 操作bigkey:寫入一個bigkey在分配內存時需要消耗更多的時間,同樣,刪除bigkey釋放內存同樣會產生耗時
- 使用複雜度過高的命令:例如SORT/SUNION/ZUNIONSTORE,或者O(N)命令,但是N很大,例如lrange key 0 -1一次查詢全量數據
- 大量key集中過期:Redis的過期機制也是在主線程中執行的,大量key集中過期會導致處理一個請求時,耗時都在刪除過期key,耗時變長
- 淘汰策略:溜達策略也是在主線程執行的,當內存超過Redis內存上限後,每次寫入都需要淘汰一些key,也會 造成耗時變長。
- AOF刷盤開啟always機制:每次寫入都需要把這個操作刷到磁盤,寫磁盤的速度遠比寫內存慢,會拖慢Redis的性能
- 主從全量同步生成RDB:雖然採用fork子進程生成數據快照,但fork這一瞬間也是會阻塞整個線程的,實例越大,阻塞時間越久
解決辦法:
- 需要業務人員去規避
- Redis在4.0推出了lazy-free機制,把bigkey釋放內存的耗時操作放在了異步線程中執行,降低對主線程的影響
2、並發量非常大時,單線程讀寫客戶端IO數據存在性能瓶頸,雖然採用IO多路復用機制,但是讀寫客戶端數據依舊是同步IO,只能單線程依次讀取客戶端的數據,無法利用到CPU多核。
解決辦法:
- Redis在6.0推出了多線程,可以在高並發場景下利用CPU多核多線程讀寫客戶端數據,進一步提升server性能
- 當然,只針對客戶端的讀寫是並行的,每個命令的真正操作依舊是單線程的

