關於mask層
- 2020 年 12 月 23 日
- AI
看attention的時候很多例子都是基於nlp的,而nlp中常常會用到mask的概念,這裡總結一下。
「讓Keras更酷一些!」:層中層與mask – 科學空間|Scientific Spaces
下文摘自上述的文章:
雖說RNN可以處理不定長的序列,因為句子的長短常常是不一的,但是真正應用到工程層面,我們還是需要使用padding進行補0使得所有的input都保持一樣的長度。
這裡用簡單的向量來描述padding的原理。假設有一個長度為5的向量:

經過padding變成長度為8:

當你將這個長度為8的向量輸入到模型中時,模型並不知道你這個向量究竟是「長度為8的向量」還是「長度為5的向量,填充了3個無意義的0」。為了表示出哪些是有意義的,哪些是padding的,我們還需要一個mask向量(矩陣):

這是一個0/1向量(矩陣),用1表示有意義的部分,用0表示無意義的padding部分。
所謂mask,就是x和m的運算,來排除padding帶來的效應。比如我們要求x的均值,本來期望的結果是:

但是由於向量已經經過padding,直接算的話就得到:
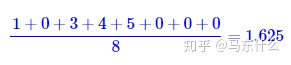
會帶來偏差。更嚴重的是,對於同一個輸入,每次padding的零的數目可能是不固定的,因此同一個樣本每次可能得到不同的均值,這是很不合理的。有了mask向量m之後,我們可以重寫求均值的運算:

這裡的⊗是逐位對應相乘的意思。這樣一來,分子只對非padding部分求和,分母則是對非padding部分計數,不管你padding多少個零,最終算出來的結果都是一樣的。
如果要求xx的最大值呢?我們有max([1,0,3,4,5])=max([1,0,3,4,5,0,0,0])=5,似乎不用排除padding效應了?在這個例子中是這樣,但還有可能是:

經過padding後變成了

如果直接對padding後的x求max,那麼得到的是0,而0不在原來的範圍內。這時候解決的方法是:讓padding部分足夠小,以至於max(幾乎)不可能取到padding部分,比如

正常來說,神經網絡的輸入輸出的數量級不會很大,所以經過x−(1−m)×10**10後,padding部分在−10**10這個數量級中,可以保證取max的話不會取到padding部分了。
處理softmax的padding也是如此。在Attention或者指針網絡時,我們就有可能遇到對變長的向量做softmax,如果直接對padding後的向量做softmax,那麼padding部分也會平攤一部分概率,導致實際有意義的部分概率之和都不等於1了。解決辦法跟max時一樣,讓padding部分足夠小足夠小,使得e**x足夠接近於0,以至於可以忽略:

上面幾個算子的mask處理算是比較特殊的,其餘運算的mask處理(除了雙向RNN),基本上只需要輸出
x⊗m
就行了,也就是讓padding部分保持為0。


